



お知らせ:
本記事をベースにした内容は、記事末で紹介する書籍
はじめに
寒い日が続きますが、みなさんいかがお過ごしでしょうか。本連載は
恐らくエンジニアならば、誰もが名前を知っていると言っても過言ではないスクリプト言語Pythonに、いったいどのような脆弱性があったのでしょうか。一緒に見ていきましょう!
今回の脆弱性:CVE-2020-8492
CVE-2020-8492はPythonで発見・
正規表現をおさらい
正規表現とは、端的に言えば
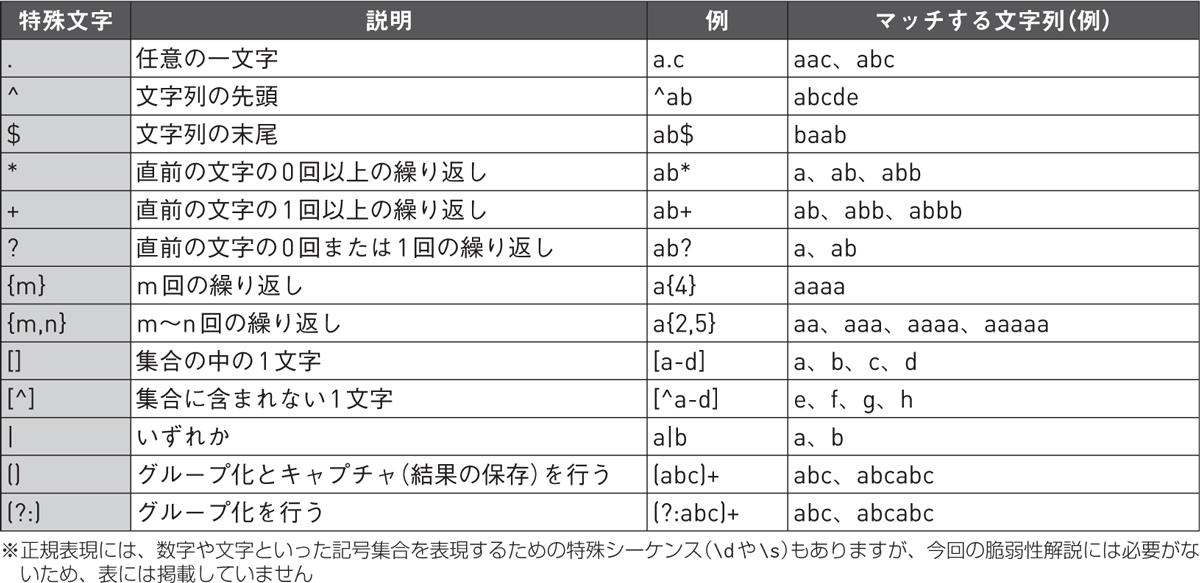
ちなみに、実は正規表現の構文にはさまざまな種類が存在します。ですが、本記事ではPythonの脆弱性を対象にしているため、Pythonで利用される正規表現の構文を用いて説明を進めていきます。
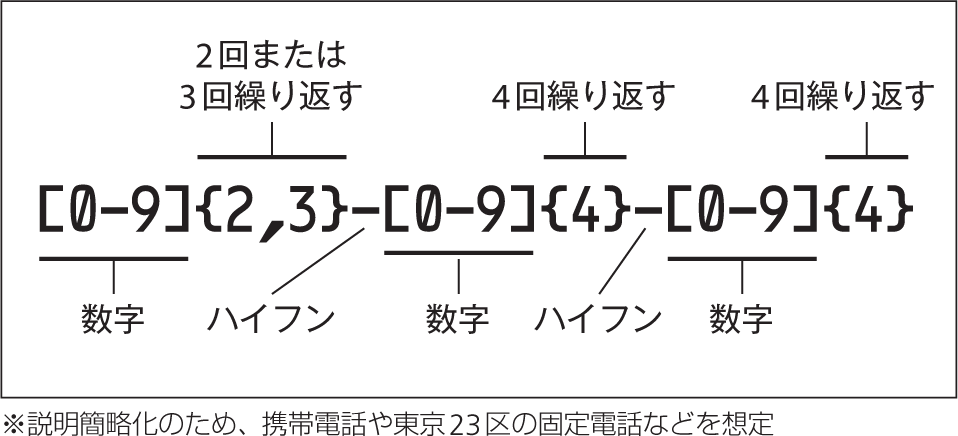
前置きが長くなりましたが、図1の正規表現について説明します。最初の[0-9]は、0から9の数字のうちの1文字を表しており、その直後に続く{2,3}は、それが2回または3回繰り返して出現する文字列のことを表現しています。
これは、電話番号の先頭番号を表す正規表現にあたり、携帯電話[0-9]{4}-[0-9]{4}となっており、これは電話番号の
正規表現を利用した文字列マッチングプログラム
正規表現に対する理解を深めるため、今度は実際のプログラム例
# -*- coding: utf-8 -*-
# reモジュールのインポート
import re
"""
1.電話番号検索するような正規表現パターンを設定し、
正規表現オブジェクトを生成
"""
# 正規表現オブジェクト名 = re.compile(正規表現パターン文字列)
rx = re.compile("[0-9]{2,3}-[0-9]{4}-[0-9]{4}")
"""
2.検索対象文字列の中から最初に正規表現にマッチする文字列を探し、
マッチオブジェクトを返す。今回は技術評論社の会社案内を検索対象文字列とする
"""
# 今回の検索対象文字列
gihyo = '''
会社情報
名称 株式会社技術評論社
代表取締役 片岡 巖
本社ビル 所在地 東京都新宿区市谷左内町21-13
設立 1969年3月
資本金 3,000万円
販売促進部電話 03-3513-6150
'''
# 検索結果 = rx.search(検索対象文字列)
mo = rx.search(gihyo)
"""
3.検索結果を表示。マッチ結果は、03-3513-6150となる
"""
print(mo.group())最初に、正規表現処理を行うための標準ライブラリであるreモジュールをインポートしています。そのあと、reモジュールで定義されているcompileを使い、図1の正規表現を正規表現オブジェクトに変換しています。
最後に、生成した正規表現オブジェクトを使い、そのメソッド呼び出しで文字列マッチングを行います。具体的にはsearchメソッドを用いて引数に受け取った検索対象文字列の中に、電話番号が出現していないかを検索します。今回の検索対象は技術評論社の会社案内文です。
本プログラムを実行した場合、技術評論社の会社案内から、販売促進部の電話番号である
以上が、正規表現を用いた文字列マッチングの簡単なプログラムの例でした。
どこに脆弱性箇所があるのか?
では、正規表現についてのおさらいができたところで、今回の脆弱性箇所を見ていきます。今回の脆弱性はPythonのurllib.
urllib.
rx = re.compile('(?:.*,)*[ \t]*([^ \t]+)[ \t]+'
realm=(["\']?)([^"\']*)\\2', re.I)
mo = AbstractBasicAuthHandler.rx.search(authreq)
HTTP/1.1 401 Authorization Required
Date: Wed, 11 May 2005 07:50:26 GMT
Server: Apache/1.3.33 (Unix)
WWW-Authenticate: Basic realm="SECRET AREA" ←★
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=iso-8859-1http_
ここまで聞く限りでは、一見問題のないプログラムのように見えます。ですが、今回の脆弱性の報告者によると、http_
from urllib.request import AbstractBasicAuthHandler
auth_handler = AbstractBasicAuthHandler()
auth_handler.http_error_auth_reqed(
'www-authenticate',
'unused',
'unused',
{
'www-authenticate': 'Basic ' + ',' * 64 +
' ' + 'foo' + ' ' + 'realm'
}
)
実際に、脆弱なバージョンのPythonでこのプログラムを実行すると、なんと1時間経ってもプログラムが終了しません。Python自身が、いわゆるサービス停止状態
脆弱性の報告者いわく、簡単に言えば、大量のカンマが含まれる文字列を第4引数
大量のカンマの部分とはリスト5の','*64のことを指し、ここで64個のカンマからなる文字列を生成しています。
そこで実際に、カンマの数を変えて実行してみた結果が表2になります。ここでは、各実行時間はtimeコマンドで取得しています。表を見ると、カンマ数が10個の場合0.
| カンマ数 | 実行時間 |
|---|---|
| 10個 | 0m0. |
| 15個 | 0m0. |
| 20個 | 0m2. |
| 25個 | 1m22. |
| 30個 | 43m55. |
では、なぜこのようなことが起きてしまうのでしょうか。具体的な脆弱性の解説に移る前に、まずはReDoSのしくみについて説明します。
ReDoSのしくみ
ReDosの脆弱性を理解するためには、そもそも正規表現によるマッチングを行う処理系である、正規表現エンジンのしくみについて知る必要があります。
正規表現エンジンの概要
正規表現エンジンとは、簡単に言えば
具体的には、正規表現の文字列を有限オートマトンに変換後、入力文字列を有限オートマトンの入力として与え、文字列中に正規表現にマッチする部分があるか否かを、有限オートマトンの状態を遷移させることで判定します。
以上の説明だけで
有限オートマトン
有限オートマトンとは簡単に言えば、与えられた一連の入力列に対して、その入力に応じて内部の状態を遷移させ、入力終了時の状態に応じて、YesかNoか
たとえば、2進数の数字の中に、0が偶数個あるかどうかを調べたいとき、有限オートマトンが利用できます。実際に、0が偶数個あるか否かを判定する有限オートマトンを状態遷移図で表したのが、図2です。
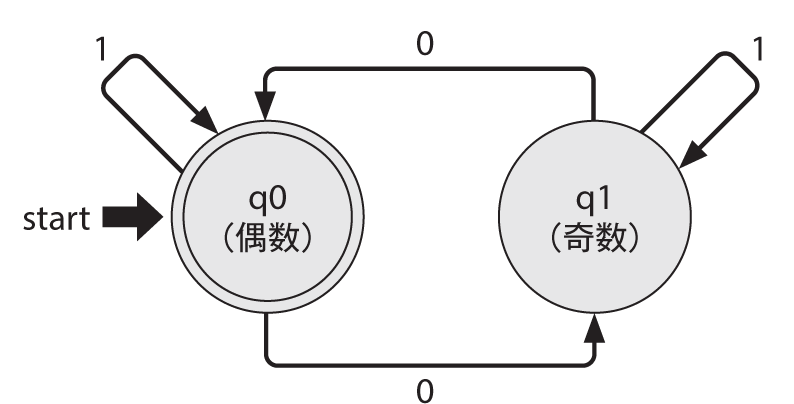
簡単に状態遷移図の読み方を説明します。各丸が各状態を表しており、そして丸の中の
たとえば入力が
まとめると、次のような遷移になります。
開始状態q0→q0→q1→q1→q0
以上、有限オートマトンの簡単な説明でした。
正規表現と非決定性有限オートマトン
有限オートマトンにもさまざまな種類があります。前述のような
プログラミング言語における正規表現エンジンが、どのような有限オートマトンで表現されるかは実装に左右されます。Pythonでは後者の非決定性有限オートマトンが利用されています。実際に、正規表現を非決定性有限オートマトンの状態遷移図で表した例を見ていきます。
たとえば、ここにa*|abという正規表現があるとします。これはaが0個以上、またはab」
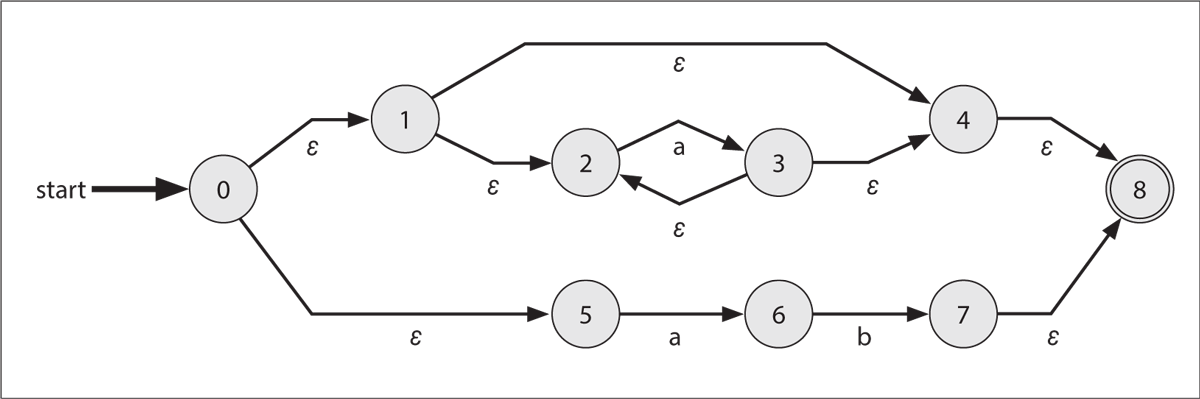
簡単に、この状態遷移図の読み方を説明します。
基本的な表記は図2に対する説明と変わりません。大きな違いとしては、遷移を示す矢印の上に
ε遷移は、言い換えれば
たとえば入力文字が空文字であった場合でも、正規表現aが0個以上」
開始状態0→1→4→8
では次に、入力文字がaaaであった場合についてです。これももちろんaが0個以上」
開始状態0→1→2→3→2→3→2→3→4→8aaaは正規表現の条件に一致)
しかしここで、aaaとabの区別はどうやってつけたのか?」aだけでは、abか否かをチェックするルートaが存在し、かつそれ以外の文字がないかをチェックするルート
バックトラッキングとReDoS
前述のような遷移先が複数存在する場合、非決定性有限オートマトンでは、実は遷移先候補をひとつひとつたどって受理か否かをチェックする
例に挙げたようなaaaの場合、遷移先となるルートの候補は2つしか存在しません。しかし、正規表現とそれに対応する入力によっては、遷移先候補が数万個となる場合もあります。そしてこのような場合、遷移先候補をひとつひとつたどって受理か否かをチェックするのには、膨大なリソースがかかってしまいます。この事象のことを、Catastrophic backtracking
ReDoSの脆弱性は、一見そんなに大した脆弱性には見えないかもしれませんが、それは大間違いです。たとえば2019年には、ReDoSの脆弱性が原因で、Cloudflare社が提供するCDNサービスが約30分ダウンし、その間世界中のWebサイト閲覧に影響が出ました。原因としては、Webアプリケーションファイアウォールに記載されていた、正規表現で定義されていた検知ルールにReDoSの脆弱性があり、それが突かれたことにより世界規模の障害につながってしまったとのことです。
実際の脆弱性箇所について
脆弱性の概要が理解できたところで、実際の脆弱性箇所の解説に移ります。リスト2のソースコードに記載された正規表現部分の内、ユーザーからの入力によっては、壊滅的なバックトラッキングが発生してしまう問題の箇所は(?:.*,)*です。この正規表現の意味を図4を用いながら説明します。最初に補足ですが、(?:)は表1に記載されているとおり、グループ化のみ行うための表現になりますが、正規表現上の動作は()と変わりません。そこで説明簡易化のため、図では?:を省略します。
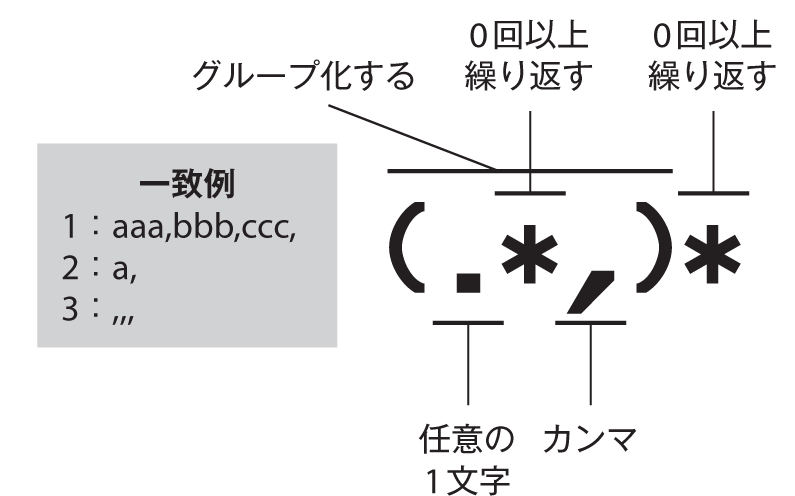
図4のとおり、この正規表現では最初に(.*,)で、任意の1文字が0回以上に加えてカンマが、グループ化されています。そして、グループ化された正規表現の外にはさらに*があり、(.*,)の文字列グループを0回以上繰り返す」aaa,bbc,ccc,」.*に入る部分はどのような文字でもかまわないので、実は,,,」
ぱっと見、この正規表現に何か問題があるようには見えません。ですが、この正規表現に対して、リスト5のような、大量のカンマが含まれる文字列を渡した場合、壊滅的なバックトラッキングが発生してしまいます。これは、状態遷移図化された正規表現
(.*,)*の正規表現の状態遷移図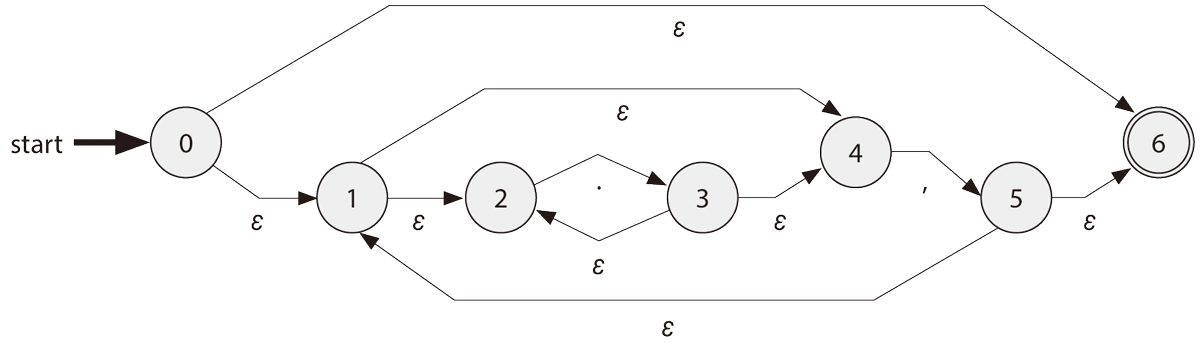
簡単に要約すると、文字列,,」.)→3→4,)→5→1と1→4,)→5→1→4,)→5→1と2つ異なるパスがあることが原因です。つまり、カンマの数が増えるごとに、ルート候補が生まれることになります。
このような場合、計算量としてはO(2n)になります。表2の実行時間でもそれは見て取れます。カンマの数をnと表した場合、2の30乗は、2の25乗の32倍にあたり、処理にかかっている時間は、カンマ30個の場合、カンマ25個の場合に比べ、ほぼ32倍
脆弱性の修正方法
では、この脆弱性が実際にどのように修正されたかを見ていきます。この脆弱性に対する修正は、2020年4月に行われました[2]。さまざまな修正が行われているのですが、脆弱性修正の肝となる、正規表現部分を取り上げて解説します
- rx = re.compile('(?:.*,)*[ \t]*([^ \t]+)[ \t]+' ←削除
- 'realm=(["\']?)([^"\']*)\\2', re.I) ←削除
+ rx = re.compile('(?:^|,)' # start of the string or ',' ←追加
+ '[ \t]*' # optional whitespaces ←追加
+ '([^ \t]+)' # scheme like "Basic" ←追加
+ '[ \t]+' # mandatory whitespaces ←追加
+ # realm=xxx ←追加
+ # realm='xxx' ←追加
+ # realm="xxx" ←追加
+ 'realm=(["\']?)([^"\']*)\\2', ←追加
+ re.I) ←追加大幅な修正がなされているように見えますが、ほとんどはコメントの追加や、文字列の分割などの表記的な変更にあたります。実際の修正箇所としては、前節において(?:.*,)*の部分だけです。具体的には、修正前は(?:.*,)*であった箇所が、修正後は(?:^|,)になっています。
修正後の正規表現の意味
最後に、本脆弱性はPythonの次のバージョンに存在します。該当するバージョンを利用している方は、最新版のPythonにアップデートすることをお勧めします。
- Python 2.
7~2. 7.17 - Python 3.
5~3. 5.9 - Python 3.
6~3. 6.10 - Python 3.
7~3. 7.6 - Python 3.
8~3. 8.1
ReDoSの脆弱性を作り込まないために
今回のような脆弱性を作り込まないために
まず、自身が書いた正規表現にReDoSの脆弱性があるか否かを簡易的にチェックするツールとしてsafe-regexがあります。また、ReDoSにつながるようなバックトラッキングをそもそも行わない正規表現ライブラリとして、Googleが開発したRE2があります。
また、プログラミング言語によっては標準で、正規表現を用いた文字列マッチングに対し、タイムアウト機能を提供しているものもあります。
RE2を利用できない場合、そういった機能を利用するもの良いでしょう。
さらに勉強したい人向け
さらに勉強したい方に向け、関連する書籍などを紹介します。まず、有限オートマトンの理論的な部分について勉強したい方には
それではみなさん、また次回お会いしましょう!