


今回は、
おさらい
前回は、

アクセスユーザ数からコサイン関数へ
第三段階の処理フローは次の通りです。ここでもアイテムIDを具体的なアイテム名で示しています。

- ①では、
第二段階の出力結果を入力し、 そのまま出力しています - ②では、
keyであるアイテムペアでソートしてReducerに渡しています。 - ③では、
keyであるアイテムペアをアクセスしたユーザ数、 および各アイテムをアクセスしたユーザ数を使いコサイン関数を計算します。
これをMapperおよびReducerで実装します。
#!/usr/bin/perl
use strict;
while (<STDIN>) {
chomp $_;
print ( $_ . "\n" );
}Mapperは図2の①に相当します。このMapperは第二段階の出力結果をReducerにそのまま渡しているだけです。アイテムペアをkeyにしているので、
#!/usr/bin/perl
use strict;
my ($key0,$value) = ();
my ($key,$id) = ();
my $co = 0;
my $corr = 0;
my %co_count = ();
my %key_count = ();
my $key_current = "";
my @list = ();
while (<STDIN>) {
chomp $_;
#入力したデータをkey0とvalueのペアに分割する。分割するデリミタはMap関数の出力形式に合わせる。
#ここでは前出のMapperのkey及びvalueがタブ区切りで出力したので、デリミタをタブにする。
($key0,$value) = split(/\t/,$_);
#key0はアイテムペアなので、$key及び$idのアイテムに分割する。分割するデリミタは第二段階のReducerの出力形式に合わせる。
($key,$id) = split(/:/,$key0);
#key値が変わった=以前のkeyに関するデータの読み込みが終了のサインなので、以前のkeyである$key_currentに対する処理を開始する。
if ( $key ne $key_current ) {
if ($key_current ne "" && ( keys (%co_count) > 0 ) ) {
foreach $id ( sort keys %co_count ) {
#アイテムペアをアクセスしたユーザ数をダブルカウントしているので、二で割る。
$co = $co_count{$id}/2;
$corr = $co/($key_count{$key_current}*$key_count{$id});
#基準とするアイテムのID、ペアとなったアイテムID2、基準とするアイテムをアクセスしたユーザ数、両アイテムをアクセスしたユーザ数、ペアとなったアイテムをアクセスしたユーザ数、両アイテムの相関係数の順に出力
print ($key_current . "\t". $id . "\t" . $key_count{$key_current} . "\t" . $co . "\t" . $key_count{$id} . "\t" . $corr . "\n");
}
}
#比較対象となるkeyを変更する
$key_current = $key;
$corr = %key_count = %co_count = @list = ();
}
if ( $value =~ /(\d+)>(\d+)>(\d+)/ ) {
if ( $1 > 0 ) { $key_count{$key} = $1; }
$co_count{$id} += $2;
if ( $3 > 0 ) { $key_count{$id} = $3; }
}
}
#標準入力を読み終えた段階で、まだ出力していないkeyに対し、集約を行い、その結果を出力する。
if ($key_current ne "" && ( keys (%co_count) > 0 ) ) {
foreach $id ( sort keys %co_count ) {
$co = $co_count{$id}/2;
$corr = $co/($key_count{$key_current}*$key_count{$id});
print ($key_current . "\t". $id . "\t" . $key_count{$key_current} . "\t" .
$co . "\t" . $key_count{$id} . "\t" . $corr . "\n");
}
}Reducerは図2の③に相当します。主な処理はMapperの出力をマージして、
第二段階のReducerは任意の一組のアイテムのペアを順序を入れ替えものも含めて二通り
図2の例では、
Hadoop Streamingを使って計算する
コサイン関数の計算に必要なMapperおよびReducerは全て揃いました。各段階でのMapper、
| 処理の段階 | Mapper/ Reducer | 処理結果を出力 するディレクトリ |
|---|---|---|
| 第一段 | Mapper:mapper_ | gihyo |
| Reducer:reducer_ | ||
| 第二段 | Mapper:mapper_ | gihyo2 |
| Reducer:reducer_ | ||
| 第三段 | Mapper:mapper_ | gihyo3 |
| Reducer:reducer_ |
第一段階の入力データ、
hadoop dfs -rmr gihyo/;
hadoop jar /opt/hadoop/contrib/streaming/hadoop-*-streaming.jar - D mapred.task.timeo
ut=300000 -input amazon -output gihyo/ -mapper './mapper_for_gihyo_1.pl' -reducer
'./reducer_for_gihyo_1.pl' -file './mapper_for_gihyo_1.pl' -file './reducer_for_gihy
o_1.pl' -jobconf mapred.reduce.tasks=12;
hadoop dfs -rmr gihyo2/;
hadoop jar /opt/hadoop/contrib/streaming/hadoop-*-streaming.jar - D mapred.task.timeo
ut=300000 -input gihyo/ -output gihyo2/ -mapper './mapper_for_gihyo_2.pl'
-reducer './reducer_for_gihyo_2.pl' -file './mapper_for_gihyo_2.pl' -file './reducer_for_gihyo_2.pl' ?
jobconf mapred.reduce.tasks=12;
hadoop dfs -rmr gihyo3/;
hadoop jar /opt/hadoop/contrib/streaming/hadoop-*-streaming.jar - D mapred.task.timeo
ut=300000 -input gihyo2/ -output gihyo3/ -mapper './mapper_for_gihyo_3.pl'
-reducer './reducer_for_gihyo_3.pl' -file './mapper_for_gihyo_3.pl' -file './reducer_for_gihyo_3.pl' ?
jobconf mapred.reduce.tasks=12;間単にスクリプトの内容を説明します。
- hadoop jar /opt/
hadoop/ contrib/ streaming/ hadoop-*-streaming. jar は、 利用しているHadoopのバージョンに合わせて変えてください。 - -inputでMapperが読み込むデータのあるHDFSのディレクトリを指定します。
- -outputでReducerがデータを出力するHDFSのディレクトリを指定します。
- -mapperでMapperとなるスクリプトを指定します。
- -reducerでReducerとなるスクリプトを指定します。
- -fileでMapperおよびReducerとなるスクリプトファイルを指定します。
- -jobconf mapred.
reduce. tasks=12でReducerの数を指定します。この例では12としています。
この計算結果をMySQLなどのデータベース、
処理を短くできないか?
今回の目的は、
ここで、
| アイテムおよびアイテムペア | アクセスユーザ数 |
|---|---|
| ザスーラ | 3 |
| ジュマンジ | 2 |
| バトルランナー | 100 |
| はやぶさ | 1000 |
| ザスーラ:ジュマンジ | 2 |
| ザスーラ:バトルランナー | 2 |
| ザスーラ:はやぶさ | 2 |

これらの値に、
このため、
コサイン関数以外は計算できるか?
もちろん、
| 名称 | 定義 |
|---|---|
| Jaccard係数 | 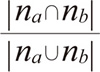
|
| Dice係数 | 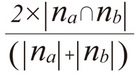
|
| Simpson係数 | 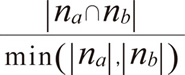
|
| Mutual Information | 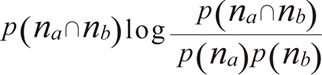
|
アイテムa, bのアイテムシーケンスをベクトルna,nbと表すと、
- na*nb
na,nbの内積。アイテムa, bを両方アクセスしたユーザの数。 - |na|,|nb|
na,nbの大きさ。それぞれアイテムa, bをアクセスしたユーザの数の平方根。 - |na ∩ nb|
アイテムa, bを両方アクセスしたユーザの数。 - |na ∪ nb|
アイテムa, bのどちらかをアクセスしたユーザの数。 - min(|na|, |nb|)
na,nbの比較。アイテムa, bをアクセスしたユーザの数のうち小さい方の数を返す。 - p(na ∩ nb), p(na), p(nb)
na ∩ nb, na, nbそれぞれの出現確率。
見ておわかりのとおり、
次回はアイテムベースのレコメンドをコンテンツベースでの実装方法を紹介します。