9月9日、シナジーカフェ GMO Yoursにて『サーバ/インフラエンジニア養成読本 ログ収集~可視化編』出版記念!執筆者が語る大講演会! 「dots.」です。本稿では、このイベントの模様をレポートします。
司会進行はトレジャーデータの池内さんです。
池内さんが今回のイベントの経緯を話した後、本書『サーバ/インフラエンジニア養成読本 ログ収集~可視化編』 一人あたり持ち時間15分間の発表がありました。
鈴木健太氏『サービス改善はログデータ解析から』
鈴木健太氏 は本書の特集タイトルと同じ「サービス改善はログデータ解析から」というタイトルで発表しました 。
鈴木さんはVOYAGE GROUPの子会社adingoにて広告データの分析基盤構築等を行っています。どんなユーザにどんな枠で出したか、どんなキャンペーンがあるか、どんなクリエイティブを出したら効果が高かったかを分析している基盤を作っているそうです。実際のデータ分析は、サービスの質に密接に関わってきます。分析結果がどれだけ活きるかによって、配信効果が変わってくると述べました。
また、データを生成する機能部分を作るアプリケーションエンジニア、分析するエンジニアはチームとして分かれているそうです。しかしサービスの設計とデータは表裏一体です。どんなサービスを作るか、どんなデータを出すかは、結びついた話だと言います。例えば、広告のターゲティングしたい場合、どういったデータを載せるか、どういうバリエーションを出せるかなどは機能の話です。生み出されるデータはそこに結び付きつつも、別に分析しなければいけません。
データ分析の活かし方を考える上で実業務を考えてみると、「 広告案件を取ってくる」「 広告配信」「 結果分析」「 手を変える」「 再度配信」とあります。しかし、これをすべて一人で行うことはできません。各ステップでは営業、オペレータ、データアナリスト、配信エンジニアが携わっていて、これら全員のところでデータが通ります。つまり、データの分析はチームで作るものです。どういうデータをどのように使いたいかという絵を共有して、会社の人に使ってもらうことが重要だと述べました。
しかし、どういったアプローチをしていけばいいのでしょうか。それは書籍で具体的に言及しているとしつつ、チーム体制を取ってデータを解析していくのであれば、解析には「収集」「 変換」「 保存」「 分析」「 表示」「 運用」という段階を踏むと良いことを示しました。どのように実現するかは、ミドルウェアを組み合わせて構築することになります。現在は数多くのミドルウェアがあって構築の手段が多様化してきており、実際には何をしたいかに依存する話だと言います。
また、分析するシステムの構築には時間がかかるため、ログ分析導入の必要性をチームに対して説明することも合わせて考えないといけません。そのために、まずは試してみるのが良いとしました。各段階でまずは使うと良いツールとして、書籍でも解説しているFluentd、Elasticsearch、Kibanaを挙げました(運用は最初のうちはなんとかなる、とのこと) 。そうして、新鮮なログが見えるようになったり、集計・分析できるようになったりする仕組みをシンプルに作ることで、何か発見があるはずだと提案しました。
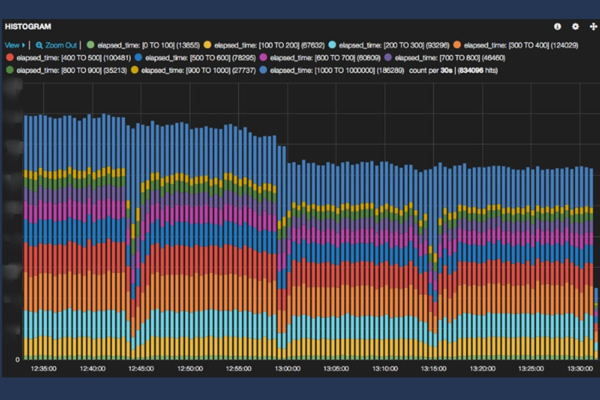
もちろん、可視化をしただけでは成果は出づらいものです。しかし、可視化について「データに含まれる事実・示唆を効率よく発見し、それを明確に伝えてくれるもの(『 データ可視化[実践]入門 』 )という言葉を引用し、最初のステップとしての可視化は良いアプローチだと指摘しました。そして、どのような事実があるかは可視化してから考えれば良いとしました。例えば、次の図はサーバ内での処理時間をKibanaで可視化したものです。これにより、ピーク時に15分ごとに処理が詰まっているのが見えることが分かったそうです。このような傾向は見てみないと分かりません。エンジニアとしてはこの点を解決したいと思うはずです。つまり、可視化により、シンプルに気づけ、発想が出てくるのが大事な点だとしました。
なぜデータ解析をするかと言えば、分析を武器にする仕組みを作ることに尽きると言います。継続的に使い、気づきを重ねる仕組みができれば、モノを作る人たちもデータを意識するようになります。営業の人とも可視化されたデータをもとにコミュニケーションを取れるようになると話しました。また、分析する人の視点からアドバイスすることも重要です。それを繰り返して、サービスに生かす文化を作ること、そしてサービスをより良くするところまでいければゴールだろうと述べました。よって、価値を長く提供できる基盤を作ることが重要だとしました。
最後に、「 データの分析はチームで作るものなので、何のためにデータ分析をするかということを決めることが大事です。ツールを使って終わらないようにしよう」と参加者に伝えました。
よしけんさん『Fluentd構成のお勧めデザインパターン』
よしけんさん (@yoshi_ken ) はリブセンスでインフラの研究開発に従事しており、著名なFluentdのプラグインの開発者でもあります。今回は、書籍で担当したFluentdについて発表しました 。書籍の第5章「逆引きFluentdプラグイン」には特に力を入れ、250個を超えるプラグインの日本語解説を行ったそうです。
最初に、Fluentdの概要を紹介しました。Fluentdを使うことで、様々なデータ入力元から、少しの手間でログデータやメッセージを収集できます。それを即座にバッファリング、フィルタ処理を行い、データを出力できます。つまり、Fluentdを使うことでログ収集のイニシャルコストを最小化できます。例えば、既存のログ収集を行っている定期バッチをFluentdに置き換えると保守が楽になるはずだと述べました。また、tailプラグインを使うことで取りこぼしのないログ収集が準リアルタイムでできること、レイテンシの改善や帯域バーストの緩和といった効果も言及しました。
次に、Fluentdの基本的な使い方を紹介しました。それはログメッセージの集約と保存することだと言います。つまり、ネットワーク周りで手間のかかるリトライ処理をすべて任せてしまうことです。利用例として、アプリログやアクセスログをFluentdに流して、集約して保存することを挙げました。また、保存先がAmazon等でもプラグインを用いれば簡単なことを説明しました。
Fluentd導入による効果として、ログ/メッセージ収集の実装や運用保守の手間が激減すること、準リアルタイムに収集されたログデータを活用できること、新鮮なデータを用いたストリーミングデータ処理が実現できることを挙げました。これにより、単位時間毎にSQL集計してくれるNorikraを用いてその結果を収集すること、Kibana等のDashboardアプリで可視化すること、リアルタイム分析によるインシデントの早期予測、不達メールアドレスのクリーニング、不正ユーザ抽出などに利用できると述べました。
Fluentdが適さない使い方も取り上げました。まず、QoS最高レベルのExactly Onceを必要とするデータ収集を挙げました。FluentdはAt Most Onceを採用しているため、1回だけ配信するという厳密なトランザクション処理を求める要件には不向きです。そのため、取りこぼしが絶対に許されない課金データの収集には向いていないそうです。また、CPUコア1つで処理できない負荷の高い処理もあまり向いていないそうです(プラグインを利用するか、分散処理のためのFluentdのクラスタ構成が必要になるとのこと) 。他にも、Fluentdのサービス再起動をともなう設定変更が日常的に派生する使い方もあまり適していないと挙げていました。よって、Fluentdは基本的に変更のないシンプルな処理をのみを担わせるべきだと言及。アプリ側が使いやすい形式に集約するところまでをFluentdで行い、その後のデータの加工についてはアプリ側が自由に行えるようにするのが良いだろうと述べました。
構成パターンについては、まずは安定運用のためにも、各ノードは単一責任(単機能)でシンプルに構成したほうが良いと説明しました。そして「シングル構成」「 汎用構成」「 応用構成」をそれぞれ紹介しました。汎用構成として考えらえる、複数のFluentdからのログ/メッセージを集約する際には、forwardプラグインを用いて一度集約し、適切な保存先に仕分ける構成にするのが良いとしました。これはElasticsearchとKibanaを組み合わせたダッシュボードを構築する時などで使えるそうです。また、応用構成の話では、演算コストのかかるフィルタ処理や、障害リスクを下げたい場合のサーバ構成について説明がありました。
最後に、「 まずは小さくFluentdを導入してみよう。手軽に遊ぶなら、ストリーミングデータプロセッサとして使っても面白いでしょう」と述べていました。
大谷純氏『Elasticsearch、もうちょっと入門』
Elasticsearchの大谷純氏 は「Elasticsearch、もうちょっと入門」というタイトルの通り、書籍では言及しなかったことを中心に発表しました 。
まずはElasticsearchについておさらいしました。Elasticsearchはそもそも検索エンジンとして作られたものです。GitHubでもElasticsearchが使われています。GitHubの画面を例に、フリーワード検索や絞り込み、ハイライト、ソート、ページング、集計、サジェストの機能を紹介しました。書籍ではKibanaのバックエンドとしてのみ紹介しているため、検索エンジンとして利用できることも覚えてほしいと伝えていました。また、特徴として、スキーマフリーであること、あまり意識せずに複数台でデータを保持できること、REST APIで操作できて結果はJSONで返ってくること、簡単に試すことができること(Javaで実装)を挙げていました。
ここで宣伝としてLogstashを紹介しました。LogstashはFluentdの代わりにログを集めることができます。機能もFluentdとだいたい同じで、入力と出力用のモジュールもたくさんあります(JRubyで実装) 。なお、Elasticsearchのサポートを購入すればその一部としてLogstashもサポートされるそうです。基本的なアーキテクチャは、Input→Filter(Logstash) →Outputです。Filterで、入力された何かデータを編集したり、サンプリングしたりする処理を設定することになります。具体的に、Logstashの簡単な例とスケールさせるためにRedisを入れた構成を示しました。
そして今回の発表では、Elasticsearch 1.0から使えるaggregationという機能を取り上げました。Kibanaでも使っている集計用のFacetは、基本的に検索結果の中にどういう単語を持ったものが何件持っているか、というのを出力できます。しかし、特定の1回の集計が対象です。これに対してaggregationを使うことで、深掘りした集計ができます。具体的には、階層的な集計や動的な集計が可能だと言及しました。ただ、現時点ではKibanaでaggregationを呼び出すことはできません。
このaggregationには大きく2種類あります。どういう単語が持ったものが何件かなど、単語をフィルタするBucketと、ドキュメントにある値の最小値を取ったり、平均値を取ったりということができるMetricです。SEKECT COUNT(color) FROM table GROUP BY colorというSQLで考えれば、BuketはGROUP BY color、MetricはCOUNT(color)を指すとしました。
その後、BucketとMetricの具体的に紹介しました。Bucketの例では、ユーザの性別、ツイートの場所や言語、ブラウザの種類を挙げました。Metricの例では、Bucket内のドキュメントの数、売上高の最大値、リクエスト処理時間の最大値を挙げました。また、価格や色、メーカー、発売日をキーとしたJSONのサンプルを取り上げ、aggregationを用いた集計例を示しました。
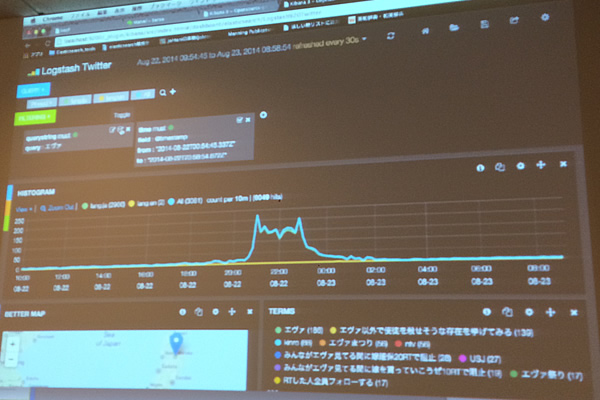
最後に、「 Elasticsearch勉強会を行っているので興味があれば、ぜひ来てほしい」と述べていました。また、Twitterの1日のデータに対してaggregationを使い、ツイートの日本語と英語の数、そして地域ごとのユーザ数を集計するデモを行いました。
道井俊介氏『KibanaではじめるDashboard』
pixivのインフラストラクチャチームに所属している道井俊介氏 は、Kibanaを使ったDashboardについて発表しました 。
pixivの開発サイクルは日に17回ほどデプロイしていて、毎週新しい機能がリリースされています。その効果検証や思いがけない変化をすぐに気づける状態を作っておこうということで、2年ほど前からデータ分析を始めたそうです。
最初にpixivにおけるデータ分析の目的について紹介しました。例えば、サービスの成長のための施策をなんでも行うグロースチームでは、その分析のためにpixiv内で実際に起こっているかを調べるためにログを使用しています。また、pixiv全体の開発を統括している開発チームでは、データ分析としてのデータの可視化を継続的デリバリーの手段であると考えています。可視化を用いて、正しく目的にそった実装が行われてるのか、予想外の効果がないのかを調べています。
Kibanaについては書籍に詳しく書いたとしつつ、特徴としては、ログを検索をするQuery、すべてのクエリに適用されるFilter、クエリの検索結果を様々な方法で表示するPanelの3つの基本的な構造で構成されていると説明しました。
そして、Dashboardの個人的な定義を紹介しました。それは、見たい数値が1画面に収まっていること、1つのデータに対して複数の面から分析できること、毎日&毎週継続して変化を見ることができることだそうです。このデータが見たいと思った時に、Dashboardが1つ決まっている状態にすること。また、インフラエンジニアや開発者がこれまでサーバに入って解析していたログデータをDashboardを通して誰もがアクセスできるような場所を作ることを目指しているそうです。
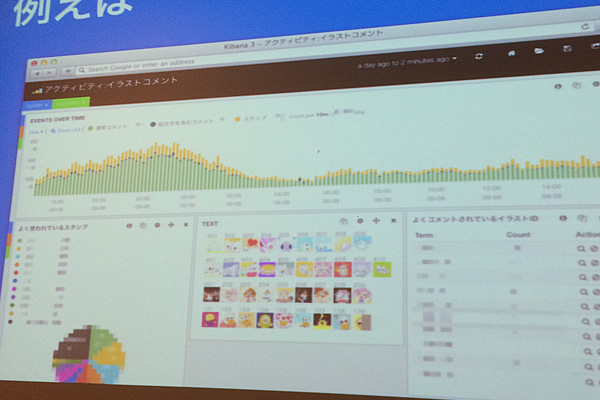
実例として、pixivで絵文字とスタンプが実装された時に使われていたDashboardを示しました。中央にスタンプが並び、どのくらいスタンプが使われたか、それによってコメントどのくらいされたかというのが、分かるように構成しました。スタンプ機能がリリースした時には毎週このDashboardを見ていたそうです。そして、スタンプの使用頻度から順番の検討や、イラストコメント数の減少がないことから他の機能に対して問題がないことを確認しました。
このようなDashboardを作るために用意するのは、適当なサーバ(SSD256GBx3, メモリ32GB) 、EFK(Elasticsearch, Fluentd, Kibana)スタック、ログファイル、空き時間です。作るのは簡単で、ログデータにはサーバに保存されているアクセスログやイベントログを使うと良いと述べました。なお、集計済みのデータはKibana上で使うのは難しいため、イベントログがあると便利だと説明しました。その際、イベントログはあらかじめ最低限の変換処理を行っておくと良いと言及。例として、IPアドレスを国情報にすること(サービスによっては地域情報も含める) 、検索時の不要なフィルタを省くためにログの出力先インデックスを振り分けておくことを挙げました。
具体的に、先ほどのコメントのDashboardを作る方法を示していきました。まずはHistgramとTableをついたものをベースにフィルタリングして、コメント関連のデータを抽出します。その際、デプロイを記録しておき、タグをつけられるようにしておくのがお勧めだそうです。そして、気になっている値を集計して表示するTerms、1週間前と比較した増減を知るためのTrends、注意事項や凡例を書くためのTextを並べたら完成です。
Dashboardを作ったら共有します。例として、シェアボタンで一時的なURLを生成してチャットとかに貼ること、きちんとできたら保存して議事録に貼っておくことを挙げました。また、毎日毎週時間を取って変化を観察するようにします。その際、チャットにリンクに貼るだけだとだんだん見てくれなくなるため、毎週のミーティング等で全員で見るようにし、変化について議論する時間を作ることが大事だとしました。これにより、改善方法やアイデア、可視化基盤へのコメントが出てくるはずだと述べました。
計算リソースが足りない、Dashboardが重いといった、Kibanaを使った可視化基盤の問題の解決のために、pixivでは Google BigQueryで集計/フィルタリングすることを始めました。Elasticsearchに入れるほかに、 Google BigQueryにも入れておいてJenkinsでクエリを投げてそれで定期的に実行する仕組みです。ただ、最初はKibanaで始めれば良いと言います。そしてKibanaが苦手なことも分かってきた時に、Kibanaのために作ったインフラを他のツールに展開することを考えようと述べました。例として、 Google BigQueryはTableauのバックエンドにできますし、JenkinsからHRForecastに投げることを挙げました。
最後に、「 空き時間にKibanaを使い始めてみると面白いことが見えてくると思います。そして可視化を始めると問題点が見えてきます。それに合わせて分析ツールを様々な方向に展開していきましょう。Fluentdをベースに組んでおくとOutputプラグインが豊富なので、どんな分析基盤にも展開できるはずです」と述べました。
(パネルディスカッション編に続く予定です……)