6月27日~30日(米国時間)の4日間に渡り、米サンフランシスコにおいてDatabricks主催の年次カンファレンス「Data + AI Summit 2022」が行われました。世界はいまだパンデミックのさなかにありますが、米国では2022年に入ってからテック系のリアルイベントの開催が増えており、かつて「Spark Summit」と呼ばれていたDatabricksによるこのカンファレンスも、5,000名を超える参加者を現地の会場に集めています。
3年ぶりにリアルイベントとして開催された「Data + AI Summit 2022」には5000名を超える参加者が米サンフランシスコのモスコーンセンターにに集まった
Databricksといえば“ Sparkの会社” とイメージする人も少なくないと思いますが、現在のDatabricksはApache Sparkのほかにも、ストレージレイヤの「Delta Lake」 、データガバナンスの「Unity Catalog」 、MLOpsの「MLflow」など数多くのポートフォリオを抱えており、レッドオーシャン化しつつあるCDW(クラウドデータウェアハウス)市場の有力プレイヤーとして存在感を強めています。同社にとっても久しぶりの大規模なリアルイベントとなった本カンファレンスでは、これらのポートフォリオに関連した数多くのアップデートが発表され、また、AdobeやAkamaiによる大規模事例やTableauなどパートナー企業によるソリューションが多数紹介されるなど、CDWの世界で強力なエコシステムを構築していることがうかがえました。
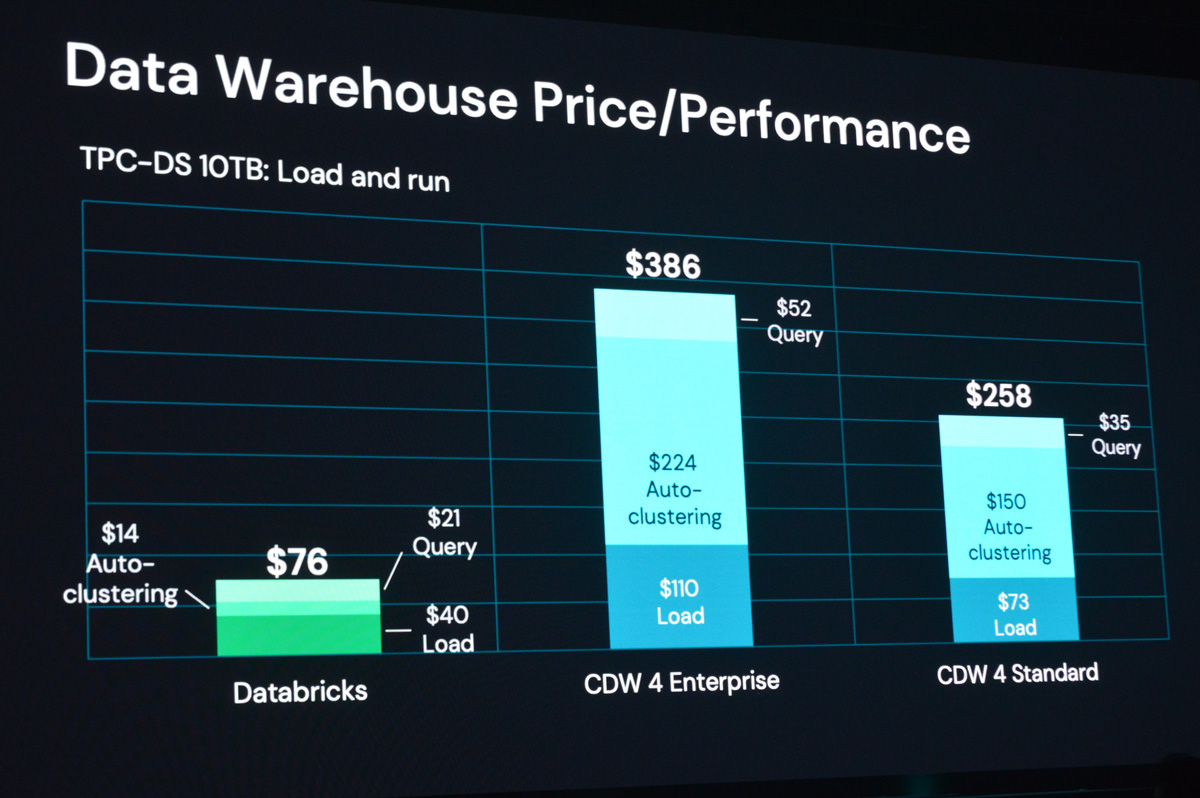
DatabricksはSnowflake、Dremioなどともに拡大しつつあるCDW市場における有力プレイヤー。とくにSnowflakeを最大の競合として見ており、キーノートではTCP-DS(ビッグデータ基盤の性能を示すベンチマーク)の結果を表示しながら、コストパフォーマンスで大きく差を付けている点を強調していた(左がDatabricks、右の2つはそれぞれSnowflakeのEnterprise/Standard)
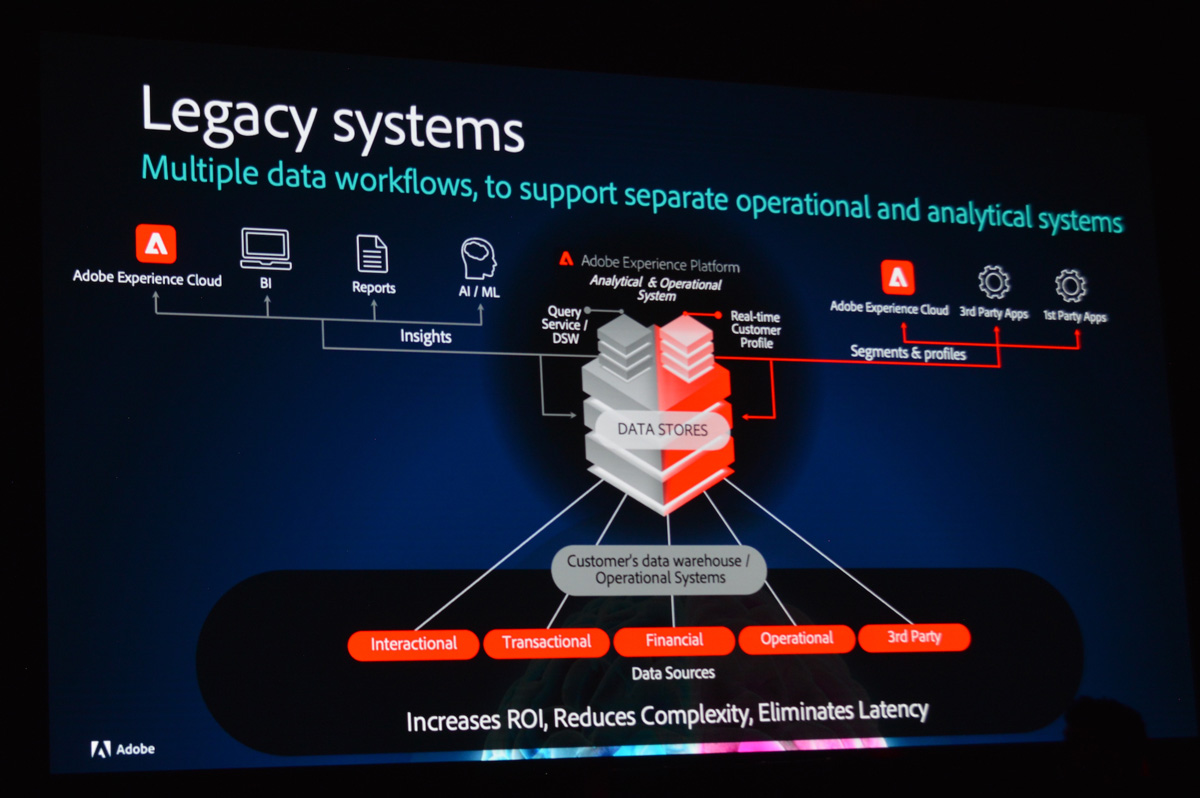
オープニングキーノートではAdobe Systemsからヘルスケア業界向けの「Adobe Experience Cloud」のデータ基盤にDatabricksを採用した事例が紹介、規制の厳しい業界を対象にしたプロジェクトにもかわわらず、レガシーシステムからモダンな統合データ基盤への移行に短期間で成功したという
本稿ではカンファレンスで発表されたアップデートの中から、Databricksがその“ レイクハウス(Lakehouse)” 戦略の要に位置づけているストレージレイヤ「Delta Lake」にフォーカスし、Delta Lakeによってレイクハウス、そしてデータ分析のあり方がどう変わっていくのか、現地での取材をもとにその展望を示したいと想います。
DatabricksにとってDelta Lakeは「データレイクのファウンデーション(基盤)」という位置づけ
Databricksのレイクハウス戦略
Delta Lakeの解説の前に、Databricksが展開する“ レイクハウスプラットフォーム” 戦略について触れておきます。Databricksは、多くの企業がデータウェアハウスとデータレイクという、2つの異なるデータプラットフォームを別々に運用している課題にフォーカスし、同社が提唱するレイクハウスプラットフォームでこれらを統合しようとしています。
企業はなぜ、手間とコストをかけてデータウェアハウスとデータレイクをわざわざ併用しているのか、その理由をDatabricksのアリ・ゴディシ(Ali Ghodsi)CEOは、「 BIのためのデータウェアハウス」と「AIのためのデータレイク」がそれぞれ異なる役割を果たしており、また、プラットフォーム間での互換性に欠けるため、データを統合して扱うことが難しいと説明しています。
「Data + AI Summit 2022」キーノートに登壇したDatabricks アリ・ゴディシ CEO
クラウドが登場する前から長い間使われてきたデータウェアハウスは、集計された構造化データを対象に、SQLをインタフェースとしたクエリ分析に長けており、とくにビジネスユーザが頻繁に利用するBIレポーティングにおいては非常にすぐれたパフォーマンスと精度を発揮します。しかしデータウェアハウスでは2010年代から急激に増えてきた非構造化データの扱いが難しく、また、マシンラーニングやデータサイエンスへのアクセスが用意されていない、データウェアハウスの構築自体にコストと時間がかかるといった課題がありました。トラディショナルなデータウェアハウスはもともとオンプレミスを前提にシステムが構築されているため、オブジェクト(クラウド)ストレージへのデータ移行やデータ統合が難しいというボトルネックも依然として存在します。
一方、2010年ごろからビッグデータブームとともに登場した“ データレイク” は、構造化データだけでなく半構造化データや非構造化データも含めた生データをそのままのかたちで格納できる点が既存のデータウェアハウスと大きく異なります。大量のデータを加工せずに格納するので、ダッシュボードやリアルタイム分析、ストリーミングデータ分析、マシンラーニングなどさまざまな分析用途に柔軟に対応することができ、さらにリポジトリとしてAmazon S3など安価でスケールしやすいオブジェクトストレージを利用できることも大きなメリットでした。
しかし、ある意味“ どんなデータでも無制限に入れられる” データレイクはともすればカオス化しやすく、データレイクどころか“ データスワンプ(swamp: 沼地)” になってしまったケースも多く見られます。また、データレイクに格納されたデータを利用可能な状態にするには、データの移動やコピーが何度も必要になったり、データサイエンティストなどデータリテラシをもつユーザが手間をかけてデータの前処理をしたり、さらに変換のためのツールが別途必要になることもあります。加えてデータレイクは、データウェアハウスが備えているトランザクションサポートやデータ品質の担保といった機能に欠けているため、データレイクがデータウェアハウスをリプレースする存在とはならず、結果として多くの企業がデータウェアハウスとデータレイクの両方を運用する状態を続けています。
多くの企業がERPなどから集計した構造化データをもとに分析するデータウェアハウス(左)と、テキストや画像など非構造化データも対象にマシンラーニングなどを行うデータレイク(右)を別々に運用している
Databricksが提唱するレイクハウスは、この互換性のない2つのデータプラットフォームをデータレイクハウスというひとつのプラットフォームに統合し、2つのプラットフォームを抱えて運用する非効率性からユーザを解放することを掲げています。レイクハウスというキーワードはAWSやGoogle Cloudのほか、DremioなどDatabricksの競合企業も使っていますが、最初にコンセプトとして提唱されたのは2021年にマイケル・アームブラスト(Michael Armbrust)氏ら4名のDatabricks創業者が執筆した論文「Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics」 「データクラウド(Data Cloud) 」と呼んでいます。
互換性とオープンソース―レイクハウスとしてあるべき姿とは
ここで、前述した「データウェアハウスとデータレイクの互換性のなさ」を統合することについてもう少し深堀りしたいと思います。
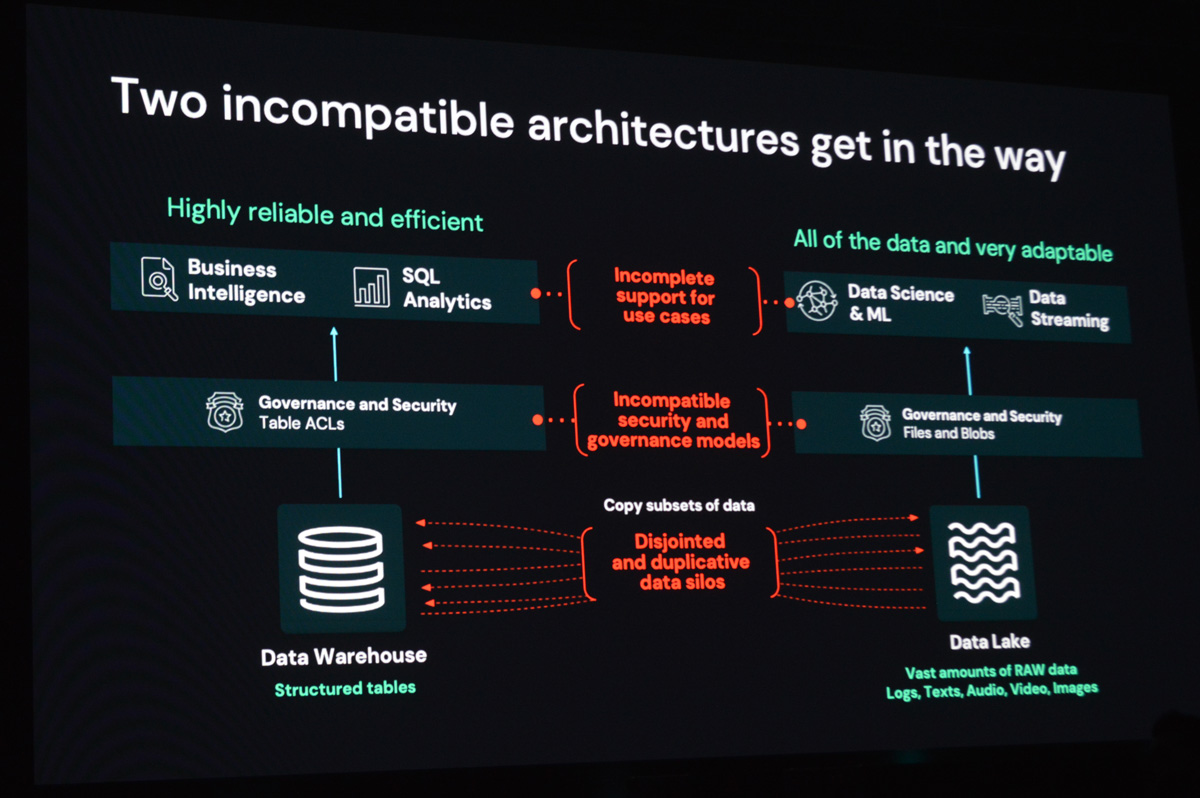
Databricksはレイクハウスを実現するために、データウェアハウスとデータレイクの各レイヤを統合する(非互換性を解消する)技術を提供しています。具体的には
ストレージ … データのタイプを問わず、またストレージ間でコピーや移動することなくアクセス可能→Delta Lake
セキュリティ&ガバナンス … データ管理のアプローチやガバナンスを統合→Unity Catalog
データアクセス … BIやMLなどあらゆる分析ワークロードの実行が可能→Databricks SQL
という3つのレイヤにおける両者の非互換性(ギャップ)の解消を目指し、その目的にひもづいた技術を提供しています。そしてDelta Lake は下位レイヤであるストレージレイヤのギャップを埋める存在としてここ1年ほど、急激に注目度が高まってきたプロダクトです。もともとDatabricks社内の開発プロジェクトでしたが、2019年にThe Linux Foundationに寄贈され、現在はオープンソース(Apache License 2.0)として開発が続けられています。
データウェアハウスとデータレイクは大きく3つのレイヤ(ストレージ/データガバナンス/セキュリティ)で互換性がない。両者の間にあるギャップを解消するためにDatabricksが提唱するのがレイクハウスプラットフォーム
オープンソースとしてDelta Lakeを開発/提供する理由についてゴディシCEOは、まず「レイクハウスが備えているべき特徴」として以下の4点を挙げています。
オープンで標準的な技術で構成されている
データウェアハウス、データエンジニアリング、データサイエンス、マシンラーニングなどあらゆる分析ワークロードに最適なアクセスを用意する
最高のパフォーマンスを実現する
マルチクラウドに対応
この最初の要素である「オープン」であることをDatabricksはあらゆるレイヤで徹底していくとゴディシCEOは強調していました。とくにストレージという下位のレイヤを扱うDelta Lakeをオープンソースで提供することで、データ共有や分析ワークロードなどより上位のレイヤでDatabricks以外の製品を導入している企業であっても、シンプルなデータパイプラインを実現しやすくなります。また、これは米国の大企業にとくに顕著な傾向ですが、大規模データを扱う企業ほどデータ基盤技術にオープンソースを使っているかどうかを厳しくチェックするため、プロプライエタリな技術で囲い込むのではなく、オープンソース化を進めていくほうがCDW市場全体で優位なポジションに立ちやすくなります。いまや基盤技術のオープンソース化は顧客企業が求める重要な条件のひとつになりつつあるのです。
Databricksのレイクハウスプラットフォームはひとつのプラットフォーム上でデータウェアハウス、データエンジニアリング、データストリーミング、データサイエンス/マシンラーニングという複数の分析ワークロードを実行可能。レイクハウスを構成する技術の要件は「シンプル」「マルチクラウド」「オープン」で、Delta Lakeはもっとも下のレイヤであるストレージを扱う基盤技術
2018年にDatabricksでリリースされたDelta Lakeは2019年にオープンソースとしてThe Linux Founation傘下のプロダクトに
データの扱いやすさと各種OSSとの親和性が強み
Delta Lakeには以下のような特徴が備わっています。
データフォーマットはApache Parquet
ACID準拠のトランザクションサポート
スケーラブルなメタデータ管理
さまざまなバージョンの過去データにアクセスできるタイムトラベル機能(データ本体と操作ログをセットで保存)
バッチ/ストリーミングの両方の入力を単一のアーキテクチャで処理
スキーマ適用によるデータの整合性の担保(スキーマエボリューション)
監査ログ
SQL、Scala/JavaのほかPython APIも利用可能
これらの特徴を見ると、無秩序にデータが放り込まれることでデータスワンプ化しやすいデータレイクのデータを、読み書き(分析)しやすい状態にする機能が数多く実装されていることがわかります。たとえばデータに対して厳格なスキーマ適用を可能にするスキーマエボリューションは、ルールに基づいて統一されたフォーマットのデータだけを使って分析できる機能として非常に高く評価されています(ルールに従っていないデータは更新を拒否できる) 。また、データウェアハウスのメリットであるACID特性の担保も、Delta Lakeであれば一貫性のあるデータの更新(楽観的ロックにもとづいた排他制御)が可能です。これは他のデータレイクプラットフォームやストレージレイヤにはあまり見られない特徴だといえます。
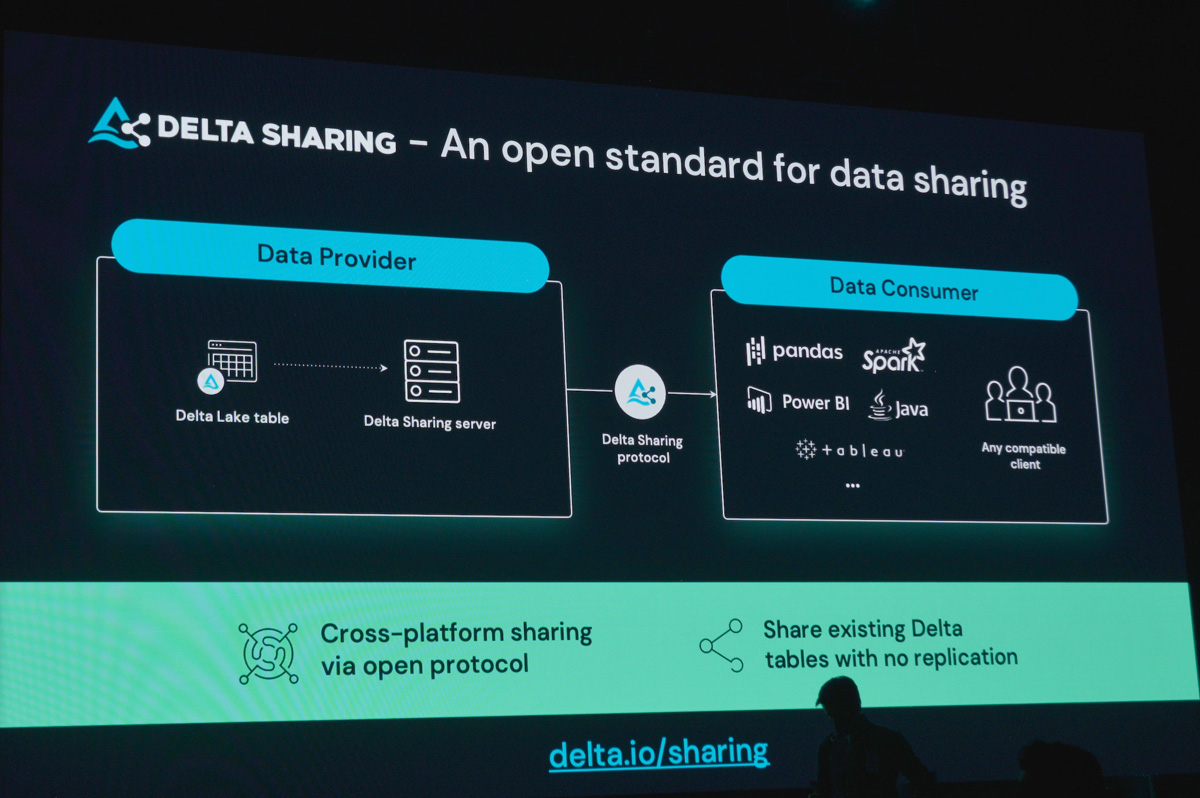
もうひとつ、Delta Lakeの大きなメリットとして挙げられるのが、Databricksが中心となって開発する「Apache Spark」や「Unitiy Catalog」と非常に親和性が高いことです。これらとシームレスに連携できることで、ETLなどにおける高速で大規模なスケーリングや、セキュアなデータ共有を高いレベルで実現できます。カンファレンスではSparkのストリーミング処理機能「Structured Streaming」を強化する「Project Lightspeed」や、Unity Catalogの一般提供開始(GA) 、Unity Catalogの機能拡張として社外を含む複数の組織間や異なるクラウドサービス間でDelta Lake上でセキュアにデータを共有するフレームワーク「Delta Sharing」のGAなども発表されました。これらの技術は今後もDelta Lakeとともに進化していくことが期待されています。
Delta Lakeと他のストレージレイヤ技術との比較。データをコピーや移動することなく、ACIDトランザクションを担保できる点が高く評価されている。また、Unity CatalogやSparkなどDatabricksのプロダクトと一緒に利用することで、データ共有や高速なクエリといったさらに多くの機能が利用可能に
Unity Catalogの機能拡張として発表された、Delta Lake上でオープンなデータ共有を実現するフレームワーク「Delta Sharing」はすでにNasdaqやShellなどペタバイト級のデータを日々扱う企業で利用されている。顧客やパートナーと多様なデータを共有するには、オープンなフレームワークの存在が欠かせない
“モダンなオープンソース企業”に求められるオープンソース戦略
レイクハウスプラットフォームを支えるストレージレイヤとして、多くの業界でユースケースが生まれているDelta Lakeですが、今後はどういう方向性に進化していくのでしょうか。カンファレンスではDelta Lakeのアップデートとして、2022年末に「Delta Lake 2.0」がリリースされることが明らかになりました。2.0ではこれまでDatabricks製品でしか利用できなかった最適化やコンパクション、カラムマッピング、CDF(Change Data Feed)といったパフォーマンス向上に関連する機能がオープンソースでも利用可能となる予定です。「 Apache Iceberg」のコンバータやデータクローンといったいくつかの機能は製品版にロックされたままですが、ゴディシCEOはこれらも遠くない将来にオープンソース化していく予定であるとしています。
Delta Lake 2.0が2022年末にリリースされることが発表された
Delta Lake 2.0では最適化やChange Data Feedなどが新たにオープンソースの機能として利用可能になる(赤い部分は2.0では利用できない機能)
Delta Lake 2.0ではパフォーマンスの改善が大きなポイント。もともとIcebergなど他のストレージレイヤよりも高速である点を強調していたが、Delta 2.0では「(Icebergよりも)1.9倍高速になる」としている
とくにユーザからの注目度が高いアップデートがストレージ最適化です。Deltaフォーマットのデータは利用していくうちにストレージ上のデータ配置が崩れやすくなり、その結果、I/O負荷が大きくなってクエリ時にデータの読み込みに時間がかかるケースが多くありました。最適化機能が実装されると、ストレージへの書き込み処理が制御され、自動的にデータ配置が最適化されるため、クエリ処理のパフォーマンスが大幅に上がることが期待されます。
実はDelta Lakeに関してはDatabricksの競合であるSnowflakeやDremio、競合プロダクトのIcebergユーザ、さらに“ オープンソース純粋主義者(purists)” たちから「Delata Lakeはオープンソースではない」と批判されてきました。その根拠は「DatabricksはDelta Lakeの機能のすべてをオープンにしているわけではなく、多くの機能をロックしている」というもので、
ある程度オープンソースのDelta Lakeを使い込んだユーザは、より多くの機能や高いパフォーマンスを得るために商用版に移行せざるを得なくなる
どの機能をオープンにするかはDatabricksしだいなので、健全で堅牢なオープンソースコミュニティが育ちにくい
といった点がとくに強く批判されています。
この批判についてゴディシCEOに聞いたところ、「 我々はオープンソース開発のルールに則っており、Delta LakeのコミュニティにはDatabricks以外のメンバーも数多く含まれていて、活発に活動している。また、我々が提供するドキュメントには、Delta Lakeで最大のパフォーマンスを獲得するには製品版が必要であることも明記している。そしてDelta Lake 2.0ではさらに多くの機能がオープンソースで使えるようになる」という反論が返ってきました。基本的な機能はオープンソースで提供するものの、より高度な機能やサポートを有償化するオープンソース企業はDatabricksのほかにも少なくなく、たとえばHashiCorpなども同様のアプローチでプロダクトを提供しています。
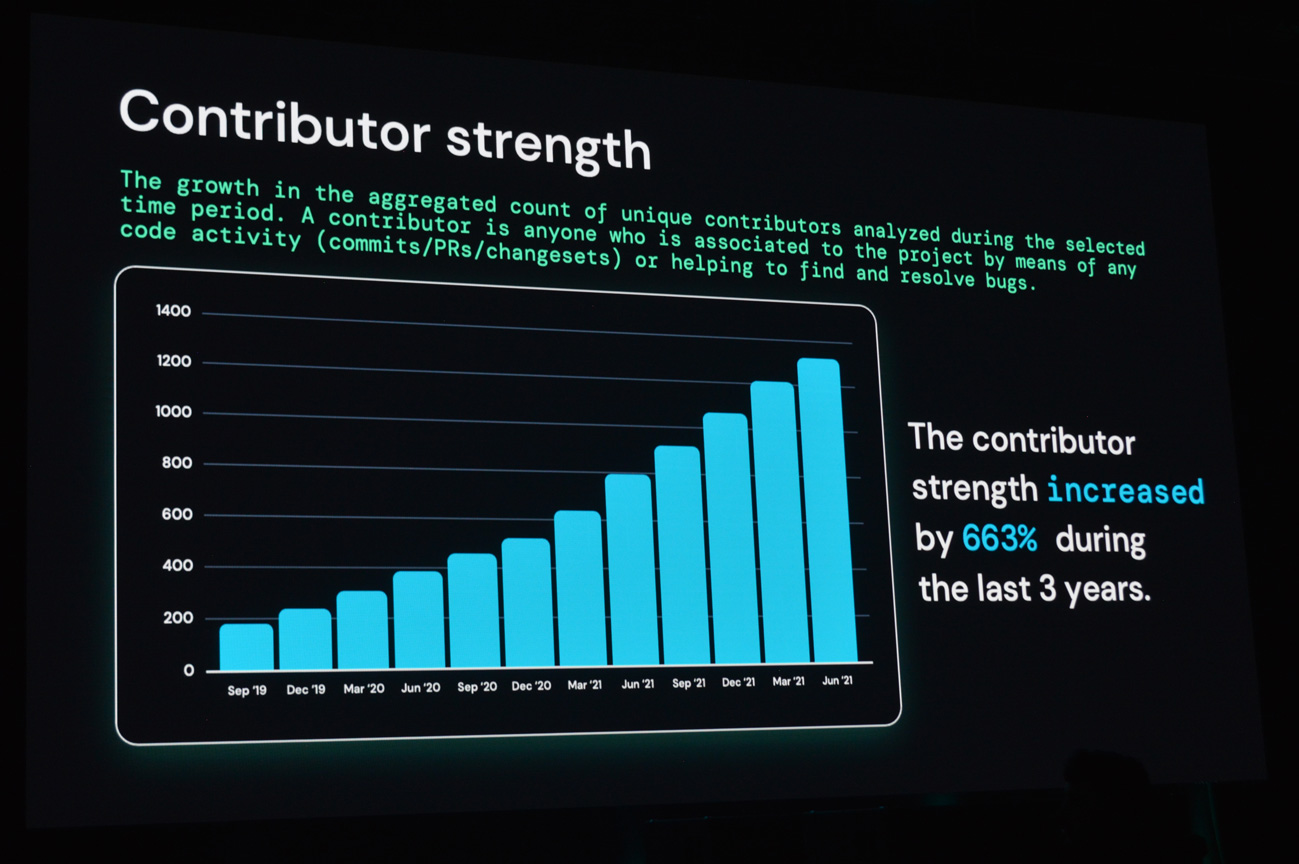
「Delta Lakeがオープンソースではない」という意見への反論のひとつとして、ゴディシCEOはコミュニティの成長、とくにコントリビュータの増加を挙げていた。Delta Lakeがリリースされてから3年でコントリビュータの数は6.6倍の約1,300人、今後もさらに増える勢いだという
Delta Lakeコミュニティに含まれる企業の一部。AppleやAdobe、Amazon、Microsoft、eBayなど、ビッグデータを扱う大企業が数多く含まれている
また、DatabricksはすでにSparkの商用サービス提供などを通してオープンソースのマネタイズに関しては実績がある企業であり、Delta Lakeやその他のプロダクトに関しても、市場のニーズを考慮しながらオープンソースとして実装していく機能のバランスを今後も図っていくようです。モダンなオープンソース企業が取りうるひとつの戦略として非常に興味深いといえます。
なぜデータを一元的に扱うためのストレージレイヤに“ Delta Lake” という名前を付けたのか ―ゴディシCEOに聞くと、「 小さなデータも漏れなく扱えるデータプラットフォームを作りたかったから」と答えてくれました。Delta Lakeの“ delta” は三角州を意味します。河川が海や湖に流れ込むとき、河口付近には河川によって運ばれた細かな砂や泥が堆積され、三角州が形成されますが、ゴディシCEOは「Sparkの開発をしながらも、データレイクに流れ込む砂粒のような細かいデータもきちんとすくい上げることのできるテクノロジが必要だとずっと感じていた」とコメントしていました。
ゴディシCEOが言うように、HadoopやSparkといったビッグデータを扱うテクノロジは、スモールデータの処理はあまり得意ではありません。しかし企業や組織ではスモールデータが数多く存在し、頻繁に変更が加えられます。小さなデータも、その小さなデータに生じたわずかな変化もすべてトラッキングできるようにすることで、ユーザはデータ管理にひもづく処理が軽減され、本来取り組むべきビジネスに集中しやすくなる - Delta Lakeというネーミングにはそういう思いが込められているそうです。
Databricksは今回のカンファレンスのテーマのひとつに「我々のデスティネーション(destination: 目的地)はレイクハウス」を掲げていました。日々世界中で増え続け、拡張し続けるデータとデータレイクの最終目的地=レイクハウスとして進化するには、その基盤となる技術のあり方がこれからも問われることになります。Sparkというデータ処理エンジンで急速に成長したDatabricksですが、2013年の創業から10年近く経った現在、データプラットフォーム企業としてより基盤固めにフォーカスしていく姿勢を見せたといえるでしょう。
「我々の目的地はレイクハウス」と語るゴディシCEO