書籍概要
現場ですぐ使える時系列データ分析
~データサイエンティストのための基礎知識〜
- 著者
- 横内大介,
青木義充 著 - 発売日
- 更新日
概要
昨今ビッグデータという言葉をよく聞きます。ITなどの技術革新により大量のデータが日々蓄積されるようになり,
こんな方におすすめ
- 時系列データを扱う人
- データ分析をする人
サンプル
- サンプルPDFファイル1(677KB)
サポート
ダウンロード
本書で使用する演習用のRDATAファイルがダウンロードできます。
圧縮ファイルをダウンロードしていただき,
ダウンロードデータの詳細は第1章5節(CHAPTER1-5 Rによるデータ分析の準備)をご参照ください。
Rのバージョンアップに合わせてファイルを更新しました。
(2024年5月13日更新)
- ダウンロード
- 演習用データ
正誤表
本書の以下の部分に誤りがありました。ここに訂正するとともに,
(2020年9月24日最終更新)
P.121 下から2行目
| 誤 | beta1 |
|---|---|
| 正 | ar1 |
P.127 下から11行目 右辺の第1項
| 誤 | 112866 |
|---|---|
| 正 | 1.12865 |
P.128 下から7行目
| 誤 | 値1.2432 |
|---|---|
| 正 | 値1.2282 |
P.128 下から5行目
| 誤 | 1.2432という値 |
|---|---|
| 正 | 1.2282という値 |
(以下2017年2月8日更新)
P.50 表2-2
| 誤 |
|
|---|---|
| 正 |
|


P.50 コマンド
| 誤 |
|
|---|---|
| 正 |
|
P.110 本文上から6行目
![]()
| 誤 |
|
|---|---|
| 正 |
|

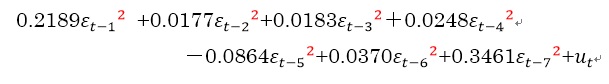
P.110 (4.1)の式の右辺
| 誤 |
|
|---|---|
| 正 |
|
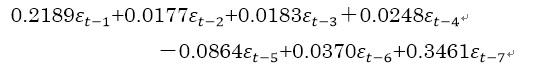

P.156 図5-6 左から13個目のデータ
| 誤 | 菱地所 |
|---|---|
| 正 | 三菱地所 |
P.159 図5-7 右から8個目のデータ
| 誤 | 菱地所 |
|---|---|
| 正 | 三菱地所 |
P.167 図5-9 右から8個目のデータ
| 誤 | 菱地所 |
|---|---|
| 正 | 三菱地所 |