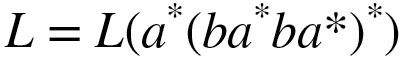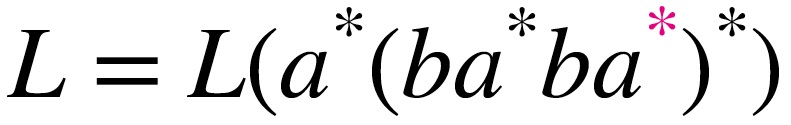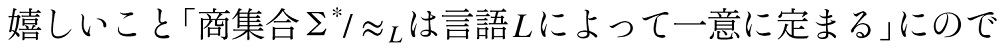目次
- 本書について
- 執筆担当一覧
- 各言語の公式ドキュメント,および正規表現の対応状況一覧表
第1章 [入門]正規表現 --メタ文字,構文,エンジン
1.1 正規表現の基本
- 正規表現とは何か
- パターンとマッチ
- 書き方はいろいろ
- 基本的な正規表現のメタ文字と構文
- 正規表現エンジン
1.2 文字列と文字列処理
- Column 「正規」とは?
- コンピュータと文字列
- 文字列は扱いやすい
- プログラミングで
- プログラムの実行で
- 設定ファイルの書き換えで
- ログの検索や整形で
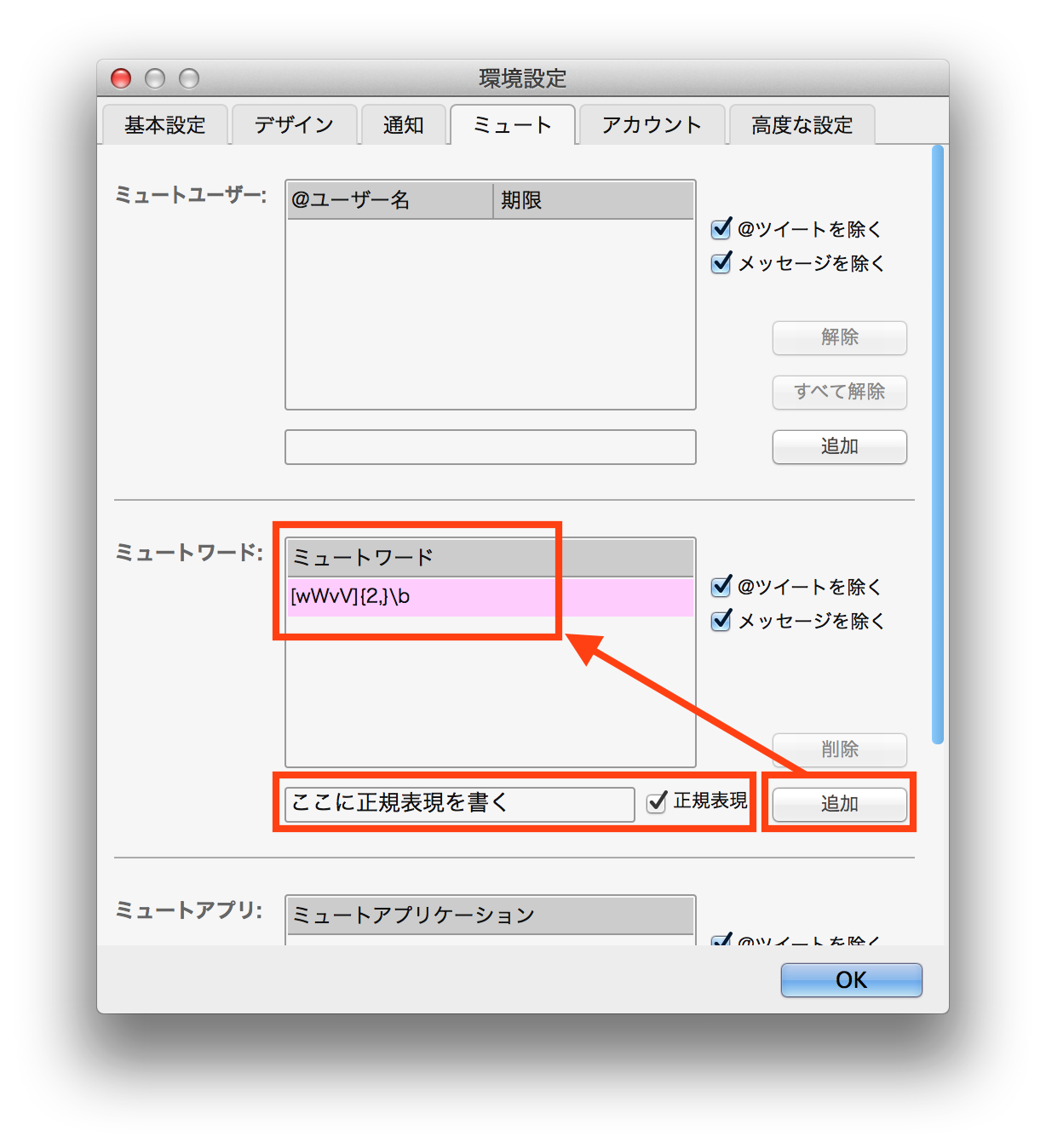
- Twitterで
1.3 正規表現の基本三演算 --連接,選択,繰り返し
- 3つの基本演算とは?
- パターンの連接
- パターンの選択
- 連接と選択の組み合わせ
- パターンの繰り返し
- Column 「任意の〜」
- 長さに制限のないパターン
- Column きちんとした文法の定義 --BNF
- 基本三演算の組み合わせ
- 基本三演算を1種類しか使えない場合
- 基本三演算を2種類しか使えない(1) --「連接/選択だけしか使えない」場合
- 基本三演算を2種類しか使えない(2) --「選択と繰り返しだけしか使えない」場合
- 基本三演算を2種類しか使えない(3) --「連接と繰り返しだけしか使えない」場合
- 演算を制限した場合に表現できるパターン
- 演算子の結合順位
- 丸括弧によるグループ化
1.4 正規表現のシンタックスシュガー
- より便利な構文を求めて
- 量指定子
- プラス演算 + --1回以上の任意回の繰り返し
- 疑問符演算 ? --0回か1回,あるかないか?
- 範囲量指定子 {n,m} --n回からm回の繰り返し
- 範囲量指定子の万能性
- ドット . --任意の1文字
- 文字クラス
- 範囲指定
- 否定
- エスケープシーケンス
- メタ文字をエスケープする
- アンカー
- Column 長さがゼロの文字列?
1.5 キャプチャと置換 --正規表現で文字列を操作する
- 文字列の部位 --接頭辞,接尾辞,部分文字列
- マッチングの種類
- 部分一致か,完全一致か
- アンカーとマッチングの種類
- サブパターンとサブマッチ
- キャプチャ
- 順番で指定
- 名前で指定 --名前付きキャプチャ
- grepでのキャプチャ
- キャプチャしないグループ化
- サブマッチの優先順位
- Column よく使う構文ほど簡潔に --Huffman符号化の原則
- 優先順位の高さは左から右
- 欲張り量指定子と控え目な量指定子
- 欲張りな量指定子と控え目な量指定子の挙動の違い
- 控え目な量指定子の活用例
- サブマッチの優先順位を理解する
- 正規表現による文字列の置換
- 文字列置換のツール
- sed
- Perlのワンライナー実行
- There's More Than One Way To Do It
1.6 正規表現の拡張機能 --先読み/再帰/後方参照
- 先読み
- 否定先読み
- 否定先読みで正規表現の「否定」を書く
- 後読みと否定後読み
- 先読み/後読みの便利さ
- 先読みで正規表現の「積」(AND)を書く
- 再帰
- 再帰的なパターン
- 再帰を使わないと書けないパターン
- 後方参照
- 基本三演算では表現できないパターン
- 強力さと読みやすさ
1.7 正規表現エンジンの基本
- 正規表現エンジンの種類 --DFA型とVM型
- DFA型のキーワード --決定性と非決定性
- 有限オートマトンで正規表現の理解を深める
- VM型のキーワード --バックトラック
- 次章からの流れ
- Column NFA? VM? バックトラック?
- Column プログラミングと正規表現
第2章 正規表現の歴史 --理論と実装の両面から
2.1 正規表現の起源 --「計算」に関する定式化
- チューリングマシンとアルゴリズム
- 脳の計算モデルと形式的ニューロン
2.2 Kleeneによる統一
- 記憶領域の有無 --形式的ニューロンとチューリングマシンの決定的な違い
- 正規表現の誕生
- 有限オートマトンの導入
- Column 正規(regular)って何?
- オートマトン理論の発展
2.3 [実装編]プログラマの相棒へ
- 最初の正規表現エンジン
- QED --正規表現による検索ができるテキストエディタの登場
- edエディタからgrepへ
- Unixと正規表現
2.4 プログラミング言語と正規表現の出会い
- 汎用プログラミング言語への進出 --AWK
- POSIXによる標準化
- Henry Spencerの正規表現ライブラリ
2.5 現代の正規表現エンジン事情
- GNU grep
- Google RE2
- Perl
- PCRE
- Column 後方参照の起源
- JavaScript
- Ruby
第3章 プログラマのための一歩進んだ正規表現 --純粋な正規表現と,最新エンジン実装の比較
3.1 「純粋」な正規表現と正規言語
- 集合の基本
- 文字の集合
- Column Σは総和記号? 文字の集合?
- 文字列の集合
- Σ*は空文字列を含む
- Σ*は無限集合
- 集合の書き方 --外延的記法と内延的記法
- 言語=文字列の集合
- Column 形式言語理論
- 純粋な正規表現
- Column 形式言語と自然言語
- 空集合と空文字列を表す正規表現
- 正規言語 --正規表現で表現できる言語
- Column 見た目の異なる正規表現が同じ正規言語を表すかどうか
3.2 現代の正規表現と,多様な機能/構文/実装
- 正規表現に対する機能追加の歴史,多様な実装の存在理由
- 正規表現エンジン間の機能/構文のサポートの違い
- 既存実装のベンチマーク
- 正規表現ライブラリ
- grepファミリー
3.3 読みやすい正規表現を書くために
- 簡潔に書く
- グループ化や量指定子,文字クラスやエスケープシーケンスをうまく使う
- 先読みや後読みなどの拡張機能をうまく使う
- 説明的に書く
3.4 現実的に妥協する
- 厳密な正規表現
- メールアドレスの正規表現
- 電話番号の正規表現
- URL/URIの正規表現
- Column 電話番号にマッチする「真」の正規表現
- 妥協した正規表現
- URLの正規表現
第4章 DFA型エンジン --有限オートマトンと決定性
4.1 正規表現と有限オートマトン
- 正規表現マッチングを有限状態で表す
- 有限オートマトン
- 非決定的な遷移
- NFAからDFAを作る
- 形式的定義
- NFAを形式的に書いてみる
- DFAを形式的に書いてみる
- オートマトンと正規表現の関係 --Kleeneの定理
- Column オートマトンの形式的定義
4.2 オートマトンを実装する
- Thompsonの構成法 --最もシンプルなオートマトンの作り方
- 文字に対応する標準オートマトン
- 選択に対応する標準オートマトン
- 連接に対応する標準オートマトン
- 繰り返しに対応する標準オートマトン
- Thompsonの構成法の例
- ε遷移の除去
- NFAからDFAを作る(再)
- NFAエンジン vs. DFAエンジン --有限オートマトンによるマッチングの計算効率
4.3 [実装テクニック]On-the-Fly構成法
- grepのソースコードの概要
- 遅延評価
- 必要になった状態だけ計算する
- GNU grepのOn-the-Fly構成コード
- On-the-Fly構成の威力
4.4 DFAの良い性質 --最小化と等価性判定
- 見た目は違うけど同じ言語を認識するオートマトン?
- Column シンプルで美しいBrzozowskiの最小化法
第5章 VM型エンジン --鍵を握るのは「バックトラック」
5.1 基本的なVM型エンジンの実装
- VM型エンジンの基本構成
- バックトラックの基礎知識
- 最も単純なバックトラック型実装
- match関数とmatchhere関数
- matchstar関数 --バックトラック実装の肝
- matchstar関数とバックトラックの関係
5.2 より実用的なVM実装
- 仮想マシンのしくみ --マッチの実行部分
- VMの基本命令
- 正規表現のコンパイルと実行例
- バックトラックの動作
- バックトラック型実装とスレッドの実行
- 仮想マシンの最小限の実装
- 共通部分
- 再帰的なバックトラック実装 --recursive,recursiveloop
- ループと再帰を組み合わせたバックトラック実装 --recursiveloop
- 非再帰的なバックトラック実装 --backtrackingvm
5.3 鬼雲のVM実装
- 鬼雲の基本構成
- VM命令
- スタック
- 個々の命令の実装
- 文字とのマッチ
- 複数文字とのマッチ
- 文字クラスとのマッチ
- JUMP
- PUSH
- キャプチャ
- 後方参照
- 部分式呼び出し
- 条件分岐
- 鬼雲VM実装のまとめ
5.4 VM以外の部分の実装
- パーサ
- 多文法対応
- 多文法対応の実装
- マルチバイト対応
- 文字単位のマッチとバイト単位のマッチ
- 鬼雲における実装方法
- コンパイラ
- 空のループのチェック
- 大文字小文字同一視の場合は,選択へ展開
- 括弧によるキャプチャの使用状況を確認
- 繰り返し文字列の展開
- その他の繰り返しの最適化
- 直後が固定文字のときの最適化
- 自動“強欲化”
- 暗黙のアンカーによる最適化
- 検索
- 固定文字列検索
- アンカーによる最適化
- 鬼雲の新機能
- \K:保持(Keep pattern)
- \R:改行文字
- \X:拡張Unicode結合文字シーケンス
- Column 鬼雲の今後の課題
5.5 鬼雲を動かしてみる
- 鬼雲のコンパイル
- デバッグ機能の有効化方法
- バックトラックの制御
- 欲張りマッチ
- 控え目なマッチ
- 強欲マッチ
5.6 まとめ
- Column Windows環境の正規表現エンジン事情
第6章 正規表現エンジンの三大技術動向 --JITコンパイル,固定文字列探索,ビットパラレル
6.1 JITコンパイル --JavaScriptや正規表現エンジンの高速化
- JavaScript --高速なテキスト処理を求めて
- JITコンパイルの導入と成果
- JITコンパイルによる高速化のカラクリ
- 正規表現のJITコンパイル
6.2 固定文字列探索による高速化
- 固定文字列とは?
- 正規表現とキーワード
- DFAよりも高速な固定文字列探索アルゴリズム
- ブルートフォースアルゴリズム
- Quick searchアルゴリズム
- 複数文字列探索アルゴリズム
- Column 固定文字列探索アルゴリズムのススメ
6.3 ビットパラレル手法によるマッチング
- ビットパラレル手法
- 固定文字列探索を行うNFA
- 固定文字列探索を行うNFAのシミュレーションを
- ビットパラレル手法で計算する
- 文字クラスへの拡張 --固定文字列探索よりも柔軟に
- Column SIMD命令による高速化
第7章 正規表現の落とし穴 --バックトラック増加,マッチ,振る舞いの違い
7.1 バックトラック増加によるパフォーマンスの低下とその解決策
- [問題点]指数関数的なバックトラックの増加
- バックトラックベースのVM型エンジン特有の問題
- [解決策(1)]控え目な量指定子によるサブマッチ優先度の明示
- [解決策(2)]強欲な量指定子によるバックトラックの抑制
- 強欲な量指定子で無駄なバックトラックを抑制する --PCREの例(1)
- 強欲な量指定子で無駄なバックトラックを抑制する --PCREの例(2)
- 自動強欲化
- 可能な限り量指定子のネストは避ける
- Column 量指定子のネストに関するPython 2.x系の制限
- 文字列探索による高速化の実例
- [押さえておきたい]正規表現エンジンの最適化/高速化技法
- アトミックグループ
- Column 欲張り,控え目,強欲
- バックトラックの制御機能
- --控え目/強欲な量指定子とアトミックグループのサポートの対応表
7.2 マッチについてさらに踏み込む
- 最左最長のPOSIX
- 早い者勝ちのVM型
- 最左最長と早い者勝ち --二刀流のRE2
- サブマッチは上書きされる
- マッチのオーバーラップ
- 先読みによるオーバーラップの回避
7.3 異なる正規表現エンジン間での振る舞いの違い
- 文字クラスについて
- Column さまざまな正規表現エンジンの検証
- マルチバイト文字の文字クラスとUnicodeプロパティ
- アトミックグループを先読みと後方参照で模倣する
- 先読みよりもサポートの弱い後読み
- 空文字列の繰り返しに関するJavaScript特有の挙動
第8章 正規表現を超えて --「書かない」「読み解く」「不向きな問題を知る」
8.1 正規表現を自動生成する
- ABNFから正規表現を自動生成する
- ABNFによるURIの文法の定義
- ABNFから正規表現へ変換するツール
- VerbalExpressions
8.2 複雑な正規表現を読み解く
- オートマトンで可視化
- 可視化ツール
- Column 最小の正規表現
- RFCに準拠したURIに対応するDFA
- 正規表現から「マッチする文字列」を生成する
- Column ファジング --正規表現で脆弱性チェック?
8.3 構文解析の世界
- --正規表現よりも表現力の高い文法を使う
- 正規表現と構文解析
- 基本三演算では表現できない再帰的な構文
- BNFとCFG --「四則演算の構文は再帰的な構文」を例に
- 文脈自由言語=正規言語+括弧の対応
- PEG
- Column 文脈自由言語とChomskyの階層
- PEGによる四則演算パーサ
- 強力さの代償
- Column CFGとPEGの構文解析計算量
Appendix
A.1 正規と非正規の壁 --正規表現の数学的背景
- 否定は正規
- 先読みは正規
- 正規言語のポンピング補題
- 必要条件と十分条件
- 言語が無限集合であるということ
- ポンピング補題の内容とその証明
- 正規言語Lが有限集合の場合
- Myhill-Nerodeの定理
- Column 便利で人気のあるポンピング補題
- 同値関係
- 同値関係で割ったもの
- 右同値類
- Myhill-Nerodeの定理の内容
- 最小DFAの一意性
- 再帰は非正規
- ポンピング補題による証明
- Myhill-Nerodeの定理による証明
- 後方参照は非正規
- ポンピング補題による証明
- Myhill-Nerodeの定理による証明
- ポンピング補題 vs. Myhill-Nerodeの定理
A.2 正規性の魅力 --正規言語の「より高度な数学的背景」
- [はじめに]正規言語の短所と長所
- 正規言語の「理論」への出発点 --最適化問題の視点から
- 正規表現の最適化に係る基本作業
- 正規表現からメタ文字を削除する
- メタ文字の役割と計算コスト
- 繰り返しの*を削除して,正規表現の形を根本から変えてみる
- 自動的に正規表現を最適化するには
- より高度な正規言語理論へ
- 正規言語の理論へ --正規言語のsyntactic monoid
- 正規言語のsyntactic monoid --その作り方
- 正規言語からsyntactic monoidを作る
- 第1段階
- 第2段階
- ここで少し用語の統一
- 積(multiplication)
- monoid(モノイド)
- 正規言語のsyntactic monoidの使い方
- Syntactic monoidを実際に使ってみる
- (1)正規表現から*を削除できるか確かめるアルゴリズム
- (2)を使わない,等価な正規表現を生成するアルゴリズム
- Schützenbergerの定理と,アルゴリズムとしての証明
- [まとめ]正規言語のsyntactic monoidの使い方 --より高いところから俯瞰してみる
- Syntactic monoidを使った方法の適用範囲
- この方法に伴うコスト
- じゃあ,なぜsyntactic monoidか?
- [エピローグ]背後にある数学「双対性」
- 双対性って?
- 正規言語とsyntactic monoidの双対性
- 正規言語とsyntactic monoidの相互関係を支えるストーン双対性
- おわりに