概要
第1特集
適材適所で活用していますか?
NoSQLの教科書
もはやRDBの対抗軸としてのNoSQLではなく,「適材適所でNoSQLを使う」ようになってきました。本特集では,NoSQLのしくみについてKey-Value Storeやドキュメント指向といった基礎技術の確認を最初に行います。その後,人気の高いMongoDB,ダークホースであるCouchbase Server,定番的なRedisを解説します。そしてMySQLでもNoSQLを実現できるmemcachedプラグインをMySQL Clusterとともに紹介します。これらNoSQLの実装を多面的に確認することでデータストアとしての活用方法を会得してください。
第2特集
文字コード攻略マニュアル
HTML・Java・Ruby・MySQLのハマりどころ
文字列の変換・数え上げ,Webページの作成,クローリング……。プログラミングと文字列は切っても切れない関係です。そして文字列を扱う以上,文字コードを避けては通れません。
本特集では文字コードの扱いで失敗しないために,文字コードの基本と主要プログラミング言語+DBMSでの扱いを押さえましょう。Part1では文字列の歴史をひも解きながら,各文字コードの成り立ちと特徴を学びます。Part2からはHTML・Java・Ruby・MySQLをピックアップして,各処理系でどんな文字コードをサポートしているのかを解説し,文字化けやエラーを発生させないためのTipsを紹介します。
第3特集
年末特別企画
温故知新 ITむかしばなしスペシャル
今回は年末特別企画として,いつもは連載の「ITむかしばなし」を特別編でお送りします。日本国内でパソコンという言葉が使われ始めた1980年代,マシン環境は昨今のような高速なスペックではなく,CPUは周波数だけとっても千分の一程度。本体メモリは百分の一程度でした。
そんな時代を過ごされた9人の方に,それぞれの経験を披露していただきました。懐かしく思う方も,想像がつかない方もいらっしゃると思いますが,むかしばなしをお楽しみください。
一般記事
[次世代言語]Elixirの実力を知る――Phoenixで高機能Webアプリ開発(後編)
ElixirにおけるプロセスとPhoenixによるアプリ開発
Rubyのような書き味で,簡単に並行処理が実現できる関数型プログラミング言語「Elixir」の入門記事。前編では,Elixirの概要,環境作成,簡単なコーディングを紹介しました。後編では,プロセスによる並列処理,mixを使ったプロジェクト作成,PhoenixによるWebアプリ作成について解説します。
サポート
ダウンロード
(2016年11月18日更新)
P.110 「[次世代言語]Elixirの実力を知る 後編」
記事で紹介した,Phoenixのサンプルアプリ「blog_sample」がダウンロードできます。
ダウンロードしたzipファイルを解凍してご利用ください。実行する際は,
$ mix deps.get && npm install && node node_modules/brunch/bin/brunch build
|
と実行してください。
- ダウンロード
- サンプルプログラム(blog_sample.zip)
P.118「使って考える仮想化技術 第7回」サンプルファイル
本誌P.118からの「使って考える仮想化技術 第7回」で紹介している「リスト1 CentOS自動インストールのためのキックスタートファイル」の、省略箇所のないサンプルがダウンロードできます。詳細については,記事をご覧ください。
- ダウンロード
- サンプルファイル(ks.cfg_sample)
免責:本サンプルを使用することによって,使用者が受けたあらゆる不利益に対して,原著者および技術評論社はその責任を負いません。
正誤表
本書の以下の部分に誤りがありました。ここに訂正するとともに,ご迷惑をおかけしたことを深くお詫び申し上げます。
(2016年12月12日更新)
第2特集「文字コード攻略マニュアル」
P.61 左段下から8行目
| 誤 |
表1はUS-ASCIIのコード表です。
|
|---|
| 正 |
表1はASCIIのコード表です。
|
|---|
P.61 表1のタイトル
P.61 表1中のキャラクター
| 上位3ビット | 下位4ビット | 誤 | 正 |
|---|
| 1 | C | FC | FS |
| 3 | B | ;; | ; |
| 3 | C | ← | < |
| 3 | E | → | > |
P.63 図3「ISO/IEC 2022のしくみ」中の各バッファの名称
| 誤 |
左から「G0」「G1」「G3」「G4」
|
|---|
| 正 |
左から「G0」「G1」「G2」「G3」
|
|---|
P.64 左段9行目
| 誤 |
0x8F未満のコードポイントはすべてASCII
|
|---|
| 正 |
0x7F以下のコードポイントはすべてASCII
|
|---|
P.64 右段14行目
| 誤 |
漢字や日本語の2バイト目として0x8F未満のコード
|
|---|
| 正 |
漢字や日本語の2バイト目として0x7F以下のコード
|
|---|
P.64 図5「EUC-JPの符号化例」“シャ乱”の説明文
| 誤 |
0x90以上は2バイト文字の1バイト
|
|---|
| 正 |
0xA1以上は2バイト文字の1バイト
|
|---|
P.64 図5「EUC-JPの符号化例」“Q”の説明文
| 誤 |
0x8F以下はASCII
|
|---|
| 正 |
0x7F以下はASCII
|
|---|
P.67 左段18行目
| 誤 |
そのHTMLをUTF-7と解釈していました(図1)
|
|---|
| 正 |
そのHTMLをUTF-7 注A と解釈していました(図1)
|
|---|
P.67 脚注の[注4]前に次の注Aを追加
| 追加文 |
[注A]UTF-7は、かつてUnicodeの規格として存在した7ビットの文字コードです。E-mailなどでの利用を想定し、Base64をもとにした変換方法とシフト文字によって、Unicodeの文字すべてを7ビットで符号化するのが特徴です。
|
|---|
P.69 右段7行目
| 誤 |
「<」がHTML要素の一部と認識されないように使う>
|
|---|
| 正 |
「<」がHTML要素の一部と認識されないように使う<
|
|---|
P.71 右段最下行
| 誤 |
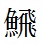
(U+29E15 とびうお)
|
|---|
| 正 |
(U+29E49 とびうお)
|
|---|
P.71~73 全体(14ヵ所)