目次
本書について
本書の構成
本書の読者対象および必要となる前提知識について
第1章 [入門]プロセッサとGPU
1.1 コンピュータシステムと画像表示の基礎 ……フレームバッファ,VRAM,ディスプレイインターフェース
- コンピュータで画像を表示する仕組み
- 画像を表示するディスプレイ ……ブラウン管とラスタースキャン
- 液晶ディスプレイ ……液晶セル,ピクセル,dpi
- 液晶セルのアクセス ……互換性が高いスキャン方法
- Column ……プロセッサの構造と動き
- フレームバッファとディスプレイインターフェース
1.2 3Dグラフィックスの歴史 ……文字から図,2D,3Dへ。高品質とリアルタイム
- 初期のグラフィックス
- コンピュータグラフィックスの利用の広がり ……高品質画像,リアルタイム描画
- 3次元物体のモデル化と表示
1.3 3Dモデルの作成 ……パネル,座標,配置,光
- 張りぼてモデルを作る ……パネル,ローカル座標とグローバル座標
- マトリクスを掛けて位置や向きを変えて配置を決める ……モデリング変換,視点変換,モデリングビュー変換,トランスポーズ
- 光の反射を計算する ……ライティング
1.4 CPUとGPUの違い ……プロセッサも適材適所
- GPUは並列処理で高い性能を実現する ……数十~数千個の演算器,GDDR DRAM
- GPUの出現
- GPUコンピューティングの出現 ……浮動小数点演算で広がった活躍の場
- GPUは超並列プロセッサ ……デスクトップPC向けCPUとゲーム向けGPUの比較
- GPUは,並列に実行できない処理は苦手
- CPUとGPUのヘテロジニアスシステムと,抱える問題
- Column ……整数と浮動小数点数
- ヘテロジニアス構成では「データ転送」が必要
- ディープコピーの問題
1.5 ユーザーの身近にあるGPUのバリエーション ……SoC,CPUチップ内蔵,ディスクリートGPU
- 携帯機器向けのGPU ……スマートフォンやタブレット向けのSoCに搭載
- CPUチップに内蔵されたGPU ……Intel Coreシリーズ,AMD APU
- ディスクリートGPUとグラフィックスワークステーション ……消費電力は200W超え(!?)コストの許す範囲で最高の性能を求めるユーザー達
1.6 GPUとおもな処理方式 ……メモリ空間,描画時のGPUメモリ確保方式,並列処理
- 共通メモリ空間か,別メモリ空間か
- CPUとGPUが同一チップ ……共用の一つのメモリのバンド幅で我慢
- 高いメモリバンドへの要求
- フルバッファ方式か,タイリング方式か ……描画時のGPUメモリ確保方式
- SIMD方式か,SIMT方式か ……座標やピクセル色で,4要素を一まとめに扱うために
1.7 まとめ
- Column ……プロセッサと半導体の世代 ……24nm世代,16nm世代... 「PxxMxx」表記
第2章 GPUと計算処理の変遷
2.1 グラフィックスとアクセラレータの歴史 ……ゲーム機,PCグラフィックス
- グラフィックス処理ハードウェアの歴史 ……ゲーム,ハイエンドシュミレータ,科学技術計算
- アーケードゲーム機
- 家庭用ゲーム機
- グラフィックス
2.2 グラフィックスボードの技術 ……2Dの背景+スプライト,BitBLT,2D/2.5D/3Dグラフィックアクセラレータ
- 2Dの背景+スプライト
- BitBLT
- 2Dグラフィックアクセラレータ
- 3Dグラフィックアクセラレータ
2.3 GPUの科学技術計算への応用 ……ユニファイドシェーダ,倍精度浮動小数点演算,プログラミング環境
- ユニファイドシェーダ
- GPUで科学技術計算 ……G80アーキテクチャ
- 科学技術計算は32ビットでは精度不足 ……GT200のアーキテクチャ,GF100 Fermi GPU
- CUDAプログラミング環境
- エラー検出,訂正
- Column ……ムーアの法則と並列プロセッサ
2.4 並列処理のパラダイム ……基本,MIMD/SIMD/SIMTの違い
- GPUの座標変換計算を並列化する ……並列計算のための基礎知識
- MIMD型プロセッサ
- SIMD型プロセッサ
- SIMD実行の問題
- 演算器の数とベクトル長のマッチング
- メモリアクセスと分岐命令の処理
- SIMT実行
- SIMT実行では条件分岐が実現できる ……プレディケート機構
- SIMTプロセッサのロード/ストア命令の実行
- SIMT実行のプログラミング上のメリット
2.5 まとめ
- Column ……ARMv7のプレディケート実行機能
第3章 [基礎知識]GPUと計算処理
3.1 3Dグラフィックスの基本 ……OpenGLのレンダリングパイプラインを例に
- [基礎知識]OpenGLのレンダリングパイプライン
- 頂点シェーダ ……頂点データの入力と出力
- テッセレーション ……細かく分解して,多数のプリミティブを生成
- ジオメトリシェーダ ……プリミティブの全頂点データが入力され,面の法線の計算などに使える
- 頂点ポストプロセスとプリミティブアセンブリ ……ビューボリューム,クリッピング
- ラスタライズ ……フラグメント(ピクセル)への変換
- フラグメントシェーダ ……フラグメントの色と奥行き方向の位置を計算
- Zバッファ ……多数のプリミティブの重なりを処理するための機構
- テクスチャマッピング ……壁紙を立体の表面に貼り付ける
- ライティング ……光の当たり具合,反射,光源
- 光の反射を計算するフラグメントシェーディング
- サンプルごとのオペレーション ……レンダリングパイプラインの最後
3.2 グラフィックス処理を行うハードウェアの構造 ……Intel HD Graphics Gen 9 GPUの例
- Intel HD Graphics Gen 9 GPUコア ……強力なGPUを搭載したPC用プロセッサ
3.3 [速習]ゲームグラフィックスとGPU ……ハードウェアとソフトウェア,進化の軌跡
- ○特別寄稿 西川 善司
- [ハードウェア面の進化]先端3Dゲームグラフィックスはアーケードから ……独自のシステム,独自の3Dグラフィックス
- PlayStationとセガサターンが呼び込んだ3Dゲームグラフィックス・デモクラシー ……PCの3Dグラフィックスの黎明期
- DirectX 7時代 ……本当の意味での「GPU」が台頭し始めた
- プログラマブルシェーダ時代の幕開け ……Shader Model(SM)仕様
- [ソフトウェア面の進化]近代ゲームグラフィックスにおける「三種の神器」 ……表現要素で見る近代ゲームグラフィックス
- [光の表現]法線マッピング ……HDゲームグラフィックス時代だからこそ求められたハイディテール表現
- [影の表現]最新のGPUでも影生成の自動生成メカニズムは搭載されていない
- 「丸影」と「シルエット影」 ……前世代までの影表現
- [現在主流の影表現]デプスシャドウ技法 ……あらゆる影が出せるようになった
- HDRレンダリング ……現実世界の輝度をできるだけ正確に表現するために
- HDRレンダリングがもたらした3つの効能
3.4 GPUと科学技術計算 ……高い演算性能で用途が拡大
- 科学技術計算の対象は非常に範囲が広い
- 科学技術計算と浮動小数点演算 ……極めて大きい数や極めて小さい数を同時に扱うために
- 浮動小数点演算の精度の使い分け ……グラフィックス,スマートフォン,科学技術計算
- 脚光を浴びる16ビット長の半精度浮動小数点演算 ……ディープラーニングでの使用
3.5 並列計算処理 ……プロセッサのコア数の増加と,計算/プログラムの関係
- GPUのデータ並列とスレッド並列
- 3Dグラフィックスの並列性 ……頂点の座標変換,ピクセルのシェーディング
- 科学技術計算の並列計算 ……並列化をどのように活かすか
- 流体計算
- 重力多体計算
3.6 GPUの関連ハードウェア ……メモリ容量,バンド幅,CPUとの接続,エラーと対策
- デバイスメモリに関する基礎知識
- CPUとGPUの接続
- 電子回路のエラーメカニズムと対策
3.7 まとめ
第4章 [詳説]GPUの超並列処理
4.1 GPUの並列処理方式
- SIMD方式……4つの座標値を一まとまりのデータとして扱う
- SIMD演算での座標変換
- 全部のSIMD演算器が使えない場合がある
- SIMT方式……1つ1つ計算する
- SIMT方式GPUの広がり
- SIMT方式の実行の問題点
- SIMT方式での条件分岐の実現
4.2 GPUの構造 ……NVIDIA Pascal GPU
- NVIDIA Pascal GPUの基礎知識
- NVIDIA GPUの命令実行のメカニズム ……[ハードウェア観点]プログラムの構造と実行
- GPUを使うプログラムの構造
- 多数のスレッドの実行
- グリッドとスレッドブロックの管理 ……ギガスレッドエンジン
- NVIDIAのダイナミックパラレリズム ……カーネルプログラムを直接起動
- SMの実行ユニット
- FP32に加えてFP64,FP16をサポートする演算器
- GPUのメモリシステム ……演算器に直結した高速な最上位の記憶レジスタファイルから
- Column ……ディープラーニングの計算と演算精度
- シェアードメモリ
- ロード/ストアユニットとリプレイ
- Column ……RISCとCISC
- L1データキャッシュ
- L2キャッシュとデバイスメモリの関係
- デバイスメモリのテクノロジー
- ワープスケジューラ ……演算レイテンシを隠す
- メモリアクセスレイテンシを隠すには?
- NVIDIA GPUは,できるだけ32の倍数のスレッドで実行する
- 条件分岐を実現するプレディケート実行
4.3 AMDとARMのSIMT方式のGPU ……AMD GCNアーキテクチャとARM Bifrost GPU
- AMD GCNアーキテクチャGPU
- GCNアーキテクチャのCU
- スマートフォン用SoC
- スマートフォン用SoCは省電力
- ARM Bifrost GPU
- タイリングで画面を分割して描画を処理
4.4 GPUの使い勝手を改善する最近の技術 ……ユニファイドメモリ,SSG,細粒度プリエンプション
- ユニファイドメモリアドレス
- NVIDIA Pascal GPUのユニファイドメモリ
- ユニファイドメモリがあれば,ディープコピーも簡単
- AMD Polaris GPUのSSG
- 命令の終わりで処理を切り替える細粒度プリエンプション
4.5 エラーの検出と訂正 ……科学技術計算用途では必須機能
- 科学技術計算の計算結果とエラー
- エラー検出と訂正の基本の仕組み
- パリティーチェック
- ECC ……ハミングコード
- SECDEDコード
- 強力なエラー検出能力を持つCRC
- 再送によるエラー訂正
- デバイスメモリのECCの問題
- Column Advanced eXtensible Interface
4.6 まとめ
第5章 GPUプログラミングの基本
5.1 GPUの互換性の考え方 ……完全な上位互換は難しい状況
- ハードウェアの互換性,機械語命令レベルの互換性
- NVIDIAの抽象化アセンブラPTX
- GPU言語レベルの互換性 ……CUDAやOpenCL
5.2 CUDA ……NVIDIAのGPUプログラミング環境
- CUDAのC言語拡張
- CUDA実行プログラム(関数)の修飾子
- NVIDIA CPU+GPUシステムのメモリ構造
- メモリ領域の修飾子
- CUDAプログラムで使われる変数 ……ベクトル型の変数のサポート
- CUDAにおけるベクトル型の変数タイプ
- 自分の処理分担を知る組み込み変数
- デバイスメモリの獲得/解放とホストメモリとのデータ転送
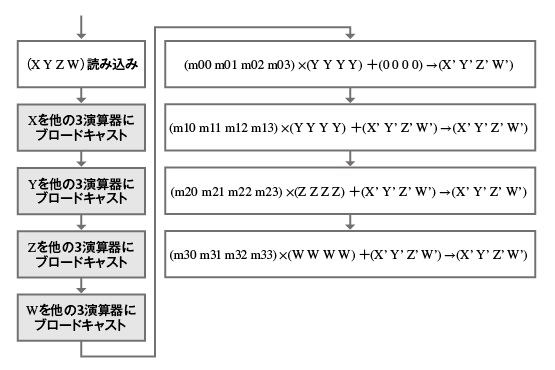
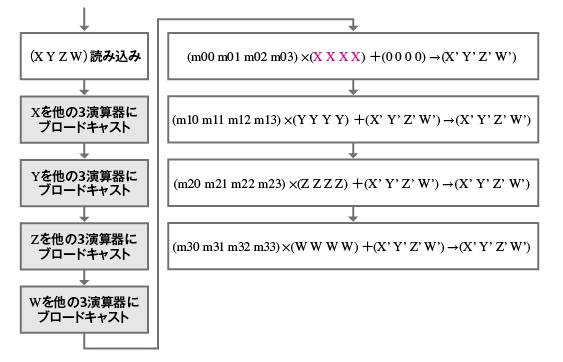
- [簡単な例]行列積を計算するCUDAプログラム
- CUDAの数学ライブラリ
- NVIDIA GPUのコンピュート能力
- CUDAプログラムの実行制御
- ストリームを使ってメモリ転送とカーネル実行をオーバーラップする
- フェンス関数を使ってメモリアクセスを順序付ける
- CUDAの関数実行を同期させるsyncthreads関数
- ストリームの実行を同期させるcudaDeviceSynchronize関数
- CUDAのダイナミックパラレリズム
- CUDAのユニファイドメモリ
- 複数GPUシステムの制御
5.3 OpenCL ……業界標準のGPU計算言語
- OpenCLとは
- OpenCLの変数
- OpenCLの実行環境
- カーネルの実行
- OpenCLのメモリ
- OpenCLのメモリの獲得と転送
- OpenCLのSVM
- OpenCLのプログラム例
- OpenCL使用上の注意
5.4 GPUプログラムの最適化 ……性能を引き出す
- NVIDIA GPUのグリッドの実行
- すべての演算器を有効に使う
- 演算器に待ちぼうけをさせない
- 条件分岐は気をつけて使おう
- メモリアクセスを効率化する
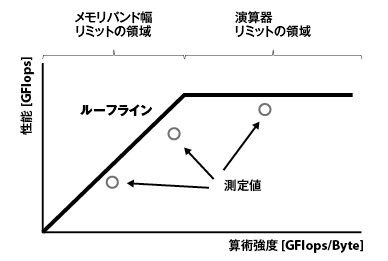
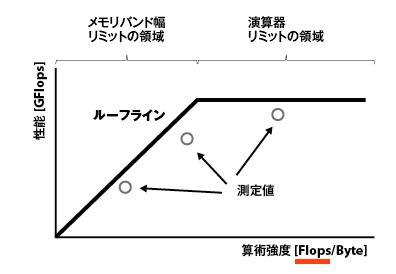
- メモリアクセスと演算の比率 ……Byte/Flop比
- ルーフラインモデルを使って性能を見積もる
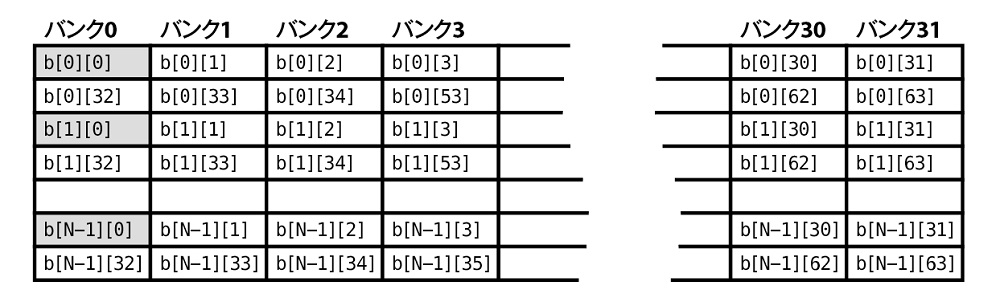
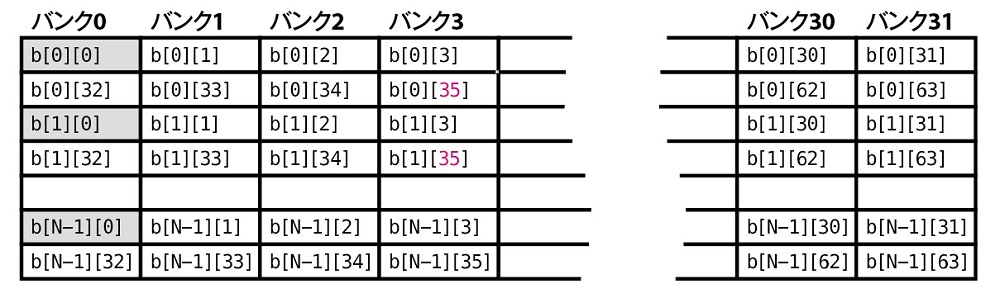
- メモリのアクセスパターンに注意する
- シェアードメモリをうまく使う
- シェアードメモリをもっとうまく使う
- ブロッキング
- ダブルバッファを使って通信と計算をオーバーラップする
5.5 OpenMPとOpenACC ……ディレクティブを使うGPUプログラミング
- OpenMPとOpenACCの基礎知識
- OpenMPの基本的な並列処理方法
- NVIDIAが力を入れるOpenACC
- OpenACCの並列実行モデル
- OpenACCの並列化指示
- OpenACCを使う場合の注意点 ……データ依存の解決が必要
- OpenACCを使う場合の注意点 ……ディープコピー
- OpenACCで合計を求める
- OpenACCのデータ転送指示
- データの領域の有効期間をコントロールする
- OpenMPを使う並列化
- OpenMP4の簡単な例
- OpenMP4のデバイスの起動と並列実行
- OpenMP4のデータ領域指定
- OpenMP4の処理分散
- OpenACCとOpenMP4
- Column ……GoogleのTPU
5.6 まとめ
第6章 GPUの周辺技術
6.1 GPUのデバイスメモリ ……大量データを高速に供給
- DRAM
- GDDR5 グラフィックスDRAM
- HBM
- GDDR5XとGDDR6
6.2 CPUとGPU間のデータ伝送 ……PCI Express関連技術,NVLink,CAPI
- PCI Express
- PCI ExpressのPeer to Peer転送
- NVIDIAのGPU Direct
- PCI Expressスイッチ
- NVIDIAのNVLink
- IBMのCAPI
- AMDのSSD搭載GPU ……ビッグデータ処理に威力発揮の可能性
6.3 まとめ
第7章 GPU活用の最前線
7.1 ディープラーニングにGPUを活用する ……ニューラルネットの基本から活用事例まで
- ディープラーニングで使われるニューラルネットワーク
- 基本構成単位のニューロン
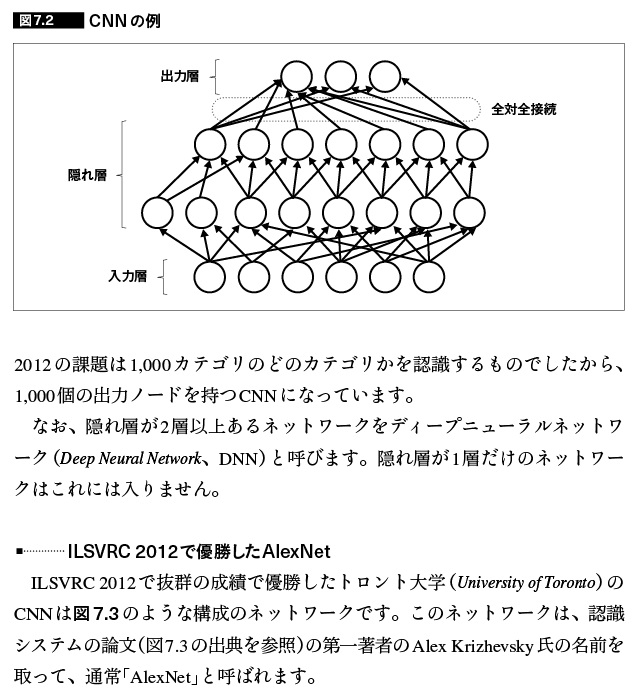
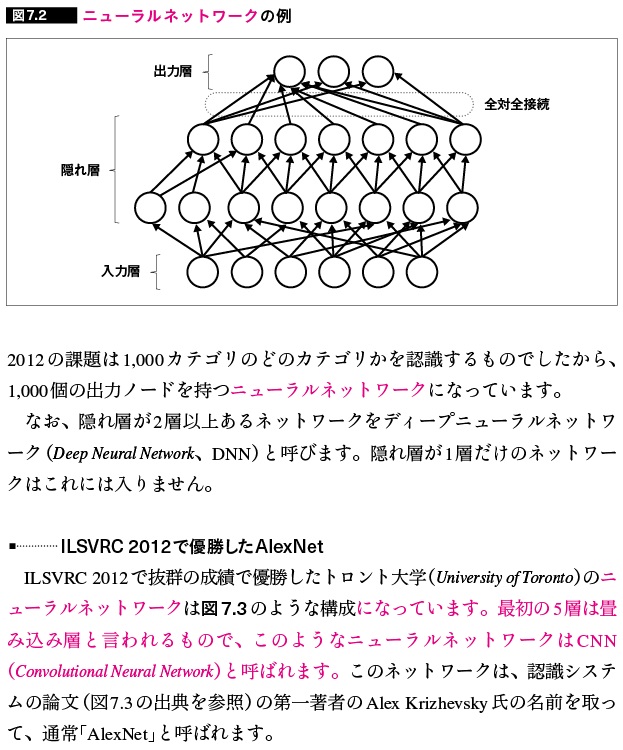
- ニューラルネットワーク
- ILSVRC 2012で優勝したAlexNet
- ディープラーニングの推論動作
- ディープラーニングの学習動作
- 画像認識CNNはどう作るのか
- ディープラーニングとGPU
- カスタムASICやFPGAによるディープラーニング ……強力なライバルの存在
- ディープラーニングでのGPUの活用事例
- 視覚障害者を補助するHorusのウェアラブルデバイス
- 画像認識は多くの分野で利用が始まっている
- NVIDIAは自動運転に向けたSoCに注力
7.2 3Dグラフィックスの活用 ……3Dで広がる事例
- 自動車の開発や販売への活用
- 建設や建築での活用
- Nikeのスポーツシューズの開発
- VR,ARの産業利用
- NVIDIAのGRID
7.3 GPUを活用するスーパーコンピュータ ……高い演算性能を求めて
- 世界の上位15位までのスーパーコンピュータの状況
- 筑波大学のHA-PACS/TCAスーパーコンピュータ
- スーパーコンピュータを何に使うのか
7.4 まとめ
第8章 プロセッサとGPUの技術動向
8.1 CPUはどうなっていくのか ……スマートフォンSoC向け,データセンター向けCPU
- スマートフォンSoC向けCPU
- データセンター向けCPU
- 高性能CPUの技術動向
- Intelの変換命令キャッシュ
- 機械学習を使う分岐予測
- 演算性能を引き上げるSIMD命令
8.2 GPUはどうなっていくのか ……GPUの種別と今後
- GPUの種類
- スマートフォンGPUはどうなっていくのか
- ハイエンドGPUはどうなっていくのか
- CPU - GPU分離メモリの問題の解決
- AMDを中心とするHSA
- 新世代のメモリインターコネクト ……CCIX,Gen-Z,OpenCAPI
- Knights Landing ……CPUとアクセラレータを一体化
- PEZY-SC ……日本発メニーコアCPU
8.3 消費電力の低減 ……アーキテクチャおよび回路技術からのアプローチ
- アーキテクチャによる省電力設計 ……カスタムロジック,ビデオ,ディープラーニング
- 回路技術による省電力化
8.4 ディープラーニングのサポート ……AIへの挑戦
- ディープラーニングの処理エンジン ……16ビットの半精度浮動小数点演算や8ビットの固定小数点演算の機能
- Column ……AI(人工知能)の歴史
- Microsoftのチャットボット達 ……Tay,Xiaoice,Zo