


本連載を執筆している伊藤
RedPenでの機能追加方法
先回RedPenの内部についての解説をしました。その知識をもとにRedPen内部の理解をもとに簡単な機能を実装してみます。実装する機能は半角カナ文字のチェックです。
機能追加:半角カナ機能
半角カナの混入は人目での判別が難しいため、
- Validatorの追加
- validateメソッドの実装
- メッセージの追加
- テストの作成
Validatorの追加
RedPenに機能を追加するには、
Validatorはいくつもメソッドを持ちますが、
validate(List<ValidationError> errorList, Document document)
validate(List<ValidationError> errors, Section section)
validate(List<ValidationError> errors, Sentence sentence)通常機能を実現するにはValidationメソッドの一つを実装します。機能が一文を独立してチェックするだけで実現できるのであればSentenceを引数に取るメソッドを実装します。逆に文書の節間の関係等をチェックしたい場合にはSection、
今回実装する機能
public class HankakuKanaValidator extends Validator {
private static Pattern pattern = Pattern.compile("[\\uFF65-\\uFF9F\\s-]");
public HankakuKanaValidator() {}
@Override
public void validate(List<ValidationError> errors, Sentence sentence) {
Matcher matcher = pattern.matcher(sentence.getContent());
while (matcher.find()) {
errors.add(createValidationError(sentence,
sentence.getContent().charAt(matcher.start())));
}
}
}上のコードではpatternというstatic変数に半角カナを検知する正規表現を代入しています。実際に検査を行うvalidateメソッドでは、
createValidationErrorの第一引数は入力文です。第二引数以降は次節で述べるエラーメッセージの引数として利用されます。HankakuKanaValidatorではマッチした半角文字を引数として渡しています。
メッセージの追加
RedPenではエラーが含まれる文だけでなく、
文長("80")が最大値 "100" を超えています。出力するエラーメッセージにはパラメータを追加して文の具体的な情報を付加できます。たとえばHankakuKanaValidatorでは検知された半角カナ文字を出力します。付加する情報はcreateValidationErrorの第二引数以降で指定します。
先ほど作成したHankakuKanaValidatorでは第二引数に発見した半角文字を与えたことを思い出してください。HanakakuKana機能のエラーメッセージは以下のとおりです。
HankakuKanaValidator=半角カナの文字 "{0}" が見つかりました。ここで、
テストの作成
では、
testRunValidaotrWithoutHanakakuKanaでは入力文に半角カナが含まれていない場合に、
public class HankakuKanaValidatorTest {
@Test
public void testDetectHankakuKana() {
Validator validator = new HankakuKanaValidator();
List<ValidationError> errors = new ArrayList<>();
validator.validate(errors, new Sentence("岩の木陰にハナが咲いている", 0));
assertEquals(2, errors.size());
}
@Test
public void testRunValidatorWithoutHanakakuKana() {
Validator validator = new HankakuKanaValidator();
List<ValidationError> errors = new ArrayList<>();
validator.validate(errors, new Sentence("岩の木陰にハナが咲いている", 0));
assertEquals(0, errors.size());
}
}テストを実行するにはredpenのトップディレクトリ上でmvn testコマンドを実行します。今回の変更を加えた状態でのテストの実行は次項で取り上げますが、
動作の確認
ここまででHankakuKana機能の実装が終わり、mvn installを実行しRedPenの生成物を出力します。
次に以下のコマンドを実行して生成物を解凍します。
$cd redpen-cli/target/ $tar xvf redpen-cli-1.1-assembled.tar.gz x redpen-cli-1.1/lib/redpen-core-1.1.jar x redpen-cli-1.1/lib/kuromoji-0.7.7.jar x redpen-cli-1.1/lib/commons-cli-1.2.jar x redpen-cli-1.1/lib/json-20080701.jar x redpen-cli-1.1/lib/logback-classic-1.1.1.jar x redpen-cli-1.1/lib/logback-core-1.1.1.jar x redpen-cli-1.1/lib/slf4j-api-1.7.6.jar ...
解凍されたディレクトリに移動します。
$cd redpen-cli-1.1
このディレクトリ以下にRedPenの設定ファイル
<redpen-conf lang="ja">
<validators>
<validator name="SentenceLength">
<property name="max_len" value="100"/>
</validator>
...
<validator name="SpaceBetweenAlphabeticalWord" />
<validator name="CommaNumber" />
<validator name="SuccessiveWord" />
<validator name="HankakuKana" />
</validators>
</redpen-conf>次にサンプル文書に半角カナ文字を追加してみます。
最近利用されているソフトウェアの中には複数の計算機上で動作(分散)するものが多く存在し、このような分散ソフトウェアは複数の計算機で動作することで大量のデータを扱えたり、高負荷な状況に対処できたりします。
本稿では,複数の計算機(クラスタ)でで動作する各サーバーを「インスタンス」と呼びまます。
たとえば検索エンジンやデータベースではインデックスを複数のインスタンスで分割して保持します。
このような場合、各インデクスの結果をマージしてclientプログラムに渡す機構が必要となります。変更した箇所はマージという単語を半角カナ
$ bin/redpen -c conf/redpen-conf-ja.xml sample-doc/ja/sampledoc-ja.txt ... sampledoc-ja.txt:4: ValidationError[HankakuKana], Found Hankaku Kana character "マ". at line: このような場合、各インデクスの結果をマージしてclientプログラムに渡す機構が必要となります。 sampledoc-ja.txt:4: ValidationError[HankakuKana], Found Hankaku Kana character "ー". at line: このような場合、各インデクスの結果をマージしてclientプログラムに渡す機構が必要となります。 sampledoc-ja.txt:4: ValidationError[HankakuKana], Found Hankaku Kana character "シ". at line: このような場合、各インデクスの結果をマージしてclientプログラムに渡す機構が必要となります。 sampledoc-ja.txt:4: ValidationError[HankakuKana], Found Hankaku Kana character "゙". at line: このような場合、各インデクスの結果をマージしてclientプログラムに渡す機構が必要となります。
上記の出力より、
最近のニュースと今後の予定
連載開始時点から、
ポジション情報の追加
RedPenはエラーを出力する際に、
- 文内で文が開始されるポジション
- エラーが発生したポジション情報
現状では、
サンプルUIの更新
もう一つ、
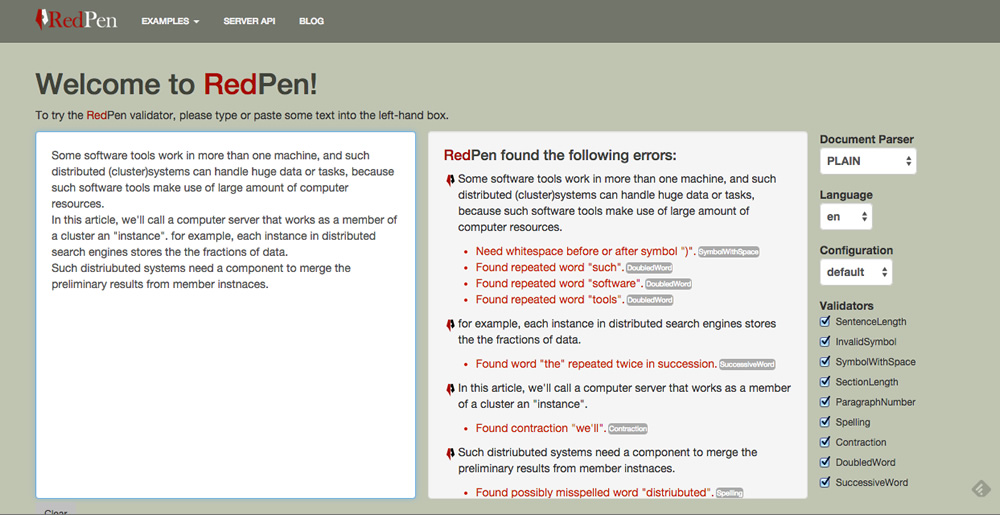
見た目以外の改良点には、
Android アプリ
最近@hotchemiさんがRedPenのAndroidアプリを公開されました。Android端末があれば簡単にRedPenの機能を体験できます。是非一度使ってみてください。
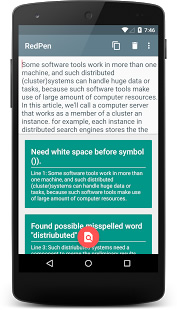
文字設定の推測
現在では言語毎に設定されたデフォルト文字をオーバライドするには、
まとめ
今回は連載最後ということで、
RedPenについての連載自体はこれで終わりますが、