本日(6月21日)行われている、RubyKaigi2008 1dayのPhotoレポートです。随時、更新予定です。本日は、大ホールの様子をメインにお伝えしていきます。
各セッションの模様は、角田さんにレポートしていただきました。
セッション前の受付の様子
セッション前の様子です。大ホール前で、RubyKaigi2008の受付が行われました。
開会の辞
RubyKaigi2008の1日目は、日本Rubyの会会長の高橋征義さんによる開会の辞から始まりました。昨年のRubyKaigiでのDave Thomas氏の「新参者を迎えよう」という言葉を受け、今回のテーマを「多様性」としました。また、異なる目的や習慣、文化を持つ人を抱擁すべく、Rubyの「多様性は善」というポリシーに基づき、2つの新しい試みを行っています。1つめはビジネス寄りなセッションを集めた0日目の開催、2つめは2つの会場を設けマルチトラックにてセッションを行うことです。
以下の動画は、その模様です。
ニコニコ動画:https://www.nicovideo.jp/watch/sm3718455 JavaScriptを有効にしてください。 現在の、そしてこれからのRubyVM開発(ささだこういちさん)
ささだこういちさんは、「 現在の、そしてこれからのRuby VM開発」というテーマで、Ruby 1.9より採用されたRuby VMについての発表を行いました。
まずは現状のRuby実装とMRI(CRuby)について紹介を行いました。現在のRuby実装はJRuby、Rubinius、IronRuby、MagLev、CRubyと数多くあり、本筋であるMRIは前日の2008年6月20日にリリースされた1.9.0_2が最新です。今年のクリスマス前にはStableである1.9.1のリリースを目指しているとのことです。
次にRuby VMの話に進み、スレッドの並列実行や1つのプロセスで複数のVMが動くMulti VMなど、多くの特徴を紹介しました。
続いて、次々に立ち上がるRuby関連プロジェクトの紹介に移りました。RubyコードからCコードに変換してパフォーマンス向上を目指した「Running Project Compilation」や「High Performance Computing」 、3人の学生で進められている、自由にカスタマイズできるRuby処理系「Atomic Ruby」などが紹介されました。
なお、東京大学に笹田研が設けられ、現在学生を募集しており、7/1より願書を受け付けるようです。
JRuby: Ready for Action(Charles Nutterさん)
JRubyのメンテナであり、パフォーマンスに厳しいCharles Nutter氏により(「 MRI 1.8より遅かったらバグだ」と定義づけているそうです) 、JRubyの発表が行われました。
JRubyは2002年にプロジェクトがスタートし、現在バージョンは1.1.2までアップデートしています。間もなく1.1.3がリリースされるとのことです。
JRubyの利用実績として以下を挙げました。
NetBeansやEclipseなどのIDE(Rubyのパーサとして)
Swing GUI
Graphics
Webアプリケーション(JRuby on Rails) SwingはJavaの複雑なAPIとRubyのクロスプラットフォームの問題を克服したと述べ、Rubyのシンプルな記述の利点を活かしirb上でSwingアプリケーションを作るデモを披露しました。また、JRubyによるSwing開発を支援する「Cheri」「 Proligacy」「 MonkeyBars」などを紹介しました。
Ruby-ProcessingというProcessingのJRubyラッパーを使って音声に反応するパーティクルのデモも披露しました。120行あまりのコードで実現しているのには驚きです。
そしてJRuby on Railsの紹介に移りました。「 JavaのWeb開発は設定が多く複雑すぎる」とし、JRuby on Railsの有用性を示しました。また、デプロイ環境について、mongrelと最近登場したPassengerを紹介しました。
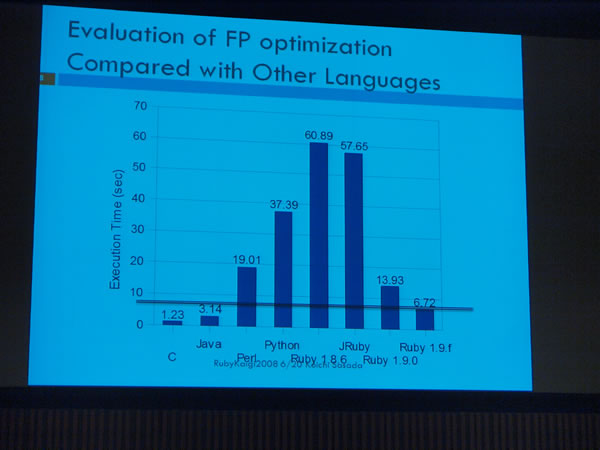
JRuby on Railsのデモとして、Glassfishを使ってRailsプロジェクトを作成しデプロイするまでを行いました。warbleコマンド(gem install warblerで利用可能)を実行するだけでWARファイルが作られ、GlassfishのasadminコマンドでWARファイルをデプロイすることができます。この仕組みはRailsだけでなくMerbでも利用できるようです。スライドではWEBrick、Mongrelとの比較をグラフにしていましたが、リクエスト頻度が高くなるについてGlassfishが優勢になっていました。
なお、現在Glashfish gemを開発中で、glassfish_rails <app_name>とするだけでプロジェクト作成からデプロイ、起動までが行えるとのことです。
最後に医療記録管理サービスやOracleユーザのコミュニケーションサイトなど多くのJRuby on Railsの事例を挙げ、JRuby on Railsはちゃんと使えるものであることをアピールしました。
質問にて、Ruby 1.9について聞かれたCharles氏は、自身のマシンに入っているjrubyに引数--1.9を付け、1.9から導入されたfiberライブラリをrequireしてみせ会場を大いに沸かせました。
「Rubiniusの魔法」(Evan Phoenixさん)
Evan氏による新しいRuby処理系「Rubinius」の発表です。Evan氏はEngine Yardという会社でRubiniusの開発を仕事にしています。
RubiniusはRuby VMとは別の新しいバイトコードベースのVMであり、コアライブラリを含むカーネルと、拡張モジュールを実行するための互換性のあるC APIで構成されています。またSmalltalkのVMのアーテクチャをベースにしており、世代別GCを備えています。
仕組みとして、コンパイラはまずRubyコードをto_sexpメソッドにてS式に変換し、そのS式を抽象構文木に変換します。そしてVisitorパターンを用いてバイトコードを生成します。
Rubiniusはプラグインをサポートしており、Evan氏はサンプルコードをベースに解説しました。そしてSmalltalkと同じように実行中のコンテキストを取得するMethodContext、ブロックで必要なデータを格納するためのBlockEnviromnent、インラインメソッドキャッシュの役割を持つSendSiteと、いくつかの重要なクラスをサンプルコードを交え解説しました。
また、Rubiniusは一つのプロセスに複数のVMを持ちVM間でコミュニケーションが可能なMulti VMの機能を持っています。
最後にスレッド実装に関する説明を行い、「 ほかにも紹介することがたくさんあり過ぎる」としてひとまずのセッションは終わりました。
セッション中に一度もデモを行わなかったため何からのデモを行うことになり、観客から「JRubyセッションの質問にて挙がったBinding#of_callerを実装してほしい」というリクエストが挙がりました。Evan氏は以下のコードを書いてof_caller.rbというファイルで保存し、rbxコマンドを実行して見事「1」と出力させてみせました。
class Binding
def self.of_caller
Binding.setup MethodContext.current.sender.sender
end
end
def foo
a = 1
bar
end
def bar
b = Binding.of_caller
eval("p a", b)
end
foo()
質問では、「 パフォーマンスは?」( A:よくなっている) 、「 マクロのような機能は実現できる?」( A:Yes) 、「 パーサをいじる仕組みはある?」( A:今RubyでRubyパーサを書いている)など、たくさんのやりとりが行われました。
ジュンク堂書店池袋店の出張販売
本日から、ジュンク堂書店池袋店の出張販売が行われています。販売を担当しているジュンク堂の長田さんは、郵送が間に合わなかった本をがんばって自宅からキャリアで運んできたそうです。
そのおかげで、たくさんのRuby本と、なぜか一部PerlやPythonの本が並んでいます。そして、『 初めてのRuby』( オライリー)と『WEB+DB PRESS Vol.45 』( 技術評論社)は先行発売されています。『 WEB+DB PRESS Vol.45』はなんと100冊もあります! 売れ残ったら悲しいので、みなさんぜひ買ってください。
追記:
昼休みの販売だけで、『 WEB+DB PRESS Vol.45』は40冊以上売れました! 買って
くださってみなさん、ありがとうございました。
Yuguiさんの新著『初めてのRuby』( オライリー)もバカ売れで、サイン会には長蛇の列ができていました。Yuguiさんは『WEB+DB PRESS Vol.45』でもRSpecの記事を書いていますので、tackenさんは『WEB+DB PRESS Vol.45』にもサインをゲット!
さらに追記:2日目には、100冊が完売しました。買ってくださってみなさん、ありがとうございました!!
基調講演「プログラミング梁山泊」(まつもとゆきひろさん)
午後一に行われたまつもとゆきひろさんによる基調講演は、プログラミングの世界におけるコミュニティをテーマに行われました。
優れた人が集まる場所を「梁山泊(Sanctuary) 」と表し、Lispにメタプログラミングやマクロなどの先進的な機能が古くからあった背景には梁山泊があったことにある、と説明しました。そしてLispのコミュニティから、次のような梁山泊の定義を導き出しました。
技術者が集まる
新しい技術が生まれる
世界が変わる その最初の部分の動画です。
ニコニコ動画:https://www.nicovideo.jp/watch/sm3726490 JavaScriptを有効にしてください。 仕事の道具として使われ技術よりも結果に関心があるFortranやCOBOL、Adaなどは梁山泊とは言えない、いろいろな側面から見るとUNIXやSmalltalk、Javaなども梁山泊の領域に入るとのことです。
そして、Rubyにも梁山泊ができつつあると述べました。RubyはLispからメタプログラミング、Smalltalkからはオブジェクト指向など過去の良い技術を継承しています。Rubyは使う人や使う楽しさに注目しています。生産性や変化にすばやく対応する俊敏性を重視しているため、Ruby on Railsのようなフレームワークが生まれました。現在、数多くのRuby実装が活発に開発されている要因の一つにRubyのポリシーである「多様性は善」が挙げられます。各実装の互換性を合わせるために仕様を統一するRubySpecプロジェクトも立ち上がっています。
また、セッションの途中で、技術フェローとして関わっている楽天技術研究所で現在進行中のプロジェクトが紹介されました。「 ROMA」と呼ばれる大規模分散メモリストレージは、いわゆる分散ハッシュテーブルの一種で、ホットスケールやデータの冗長保存、フェイルオーバの機能を持っているようです。次に分散並列処理フレームワークである「fairy」が紹介され、分散grepの例をスライドアニメーションと疑似コードにて解説しました。fairyは開発当初、GoogleのMapReduceを想定していたようですが、MapReduceでは厳しい処理が多くあり、違う計算モデルを検討しているようです。現在は両方ともPure Rubyで実装しており、パフォーマンス面で問題が出てきたら一部C言語に置き換えることも検討しているようです。
質問コーナーにて、Matz日記の更新が停滞していることを指摘され「今日帰ったら更新します」と答えていましたが、今現在更新されていないところをみるとまつもとさんの中ではまだRuby会議は終わってないようです。
以下は、松本さんのセッションの後半部分から終わりまでの動画です。
ニコニコ動画:https://www.nicovideo.jp/watch/sm3726641 JavaScriptを有効にしてください。 ニコニコ動画:https://www.nicovideo.jp/watch/sm3726943 JavaScriptを有効にしてください。 ※これらのセッションの動画は、後日、公式サイトにきちんとした動画が掲載される予定です。
Ruby M17N(成瀬ゆいささん、Martin J. Durstさん)
成瀬ゆいさんとMartin J. Durstさんによる、Ruby 1.9から導入されたMultilingualization(同時に複数の言語を扱えるようにすること)の発表です。一般的に採用されることが多いUCS Normalization方式ではなくCSI(Code Set Independent)方式を採用し、独自の変換モジュールを持っていることが特徴です。
Rubyは1.9より、Stringにエンコーディングを持ちます。UTF-8、Shift_JIS、EUC-JPなどのASCII互換のエンコーディングはすべてサポートしており、UTF-16や32などはBOM対応が困難で非対応です。また、ISO-2022-JPとUTF-7もDummy Encoding(Encoding#dummy?でtrueが返るエンコーディング)としてとらえ、対応していません。
サポートしているエンコーディングを調べるにはEncoding.listを使います。1.9ではシステム全体の内部コードは決定不可能なため$Kcodeは使えません。1.9より文字列に対してエンコーディングがつきますが、当時1つの文字を表すCharacterクラスが導入されるかどうかが議題に挙がったようです。しかし「文字は1つの文字列である」とし、Stringで表すこととしました。
Ruby 1.8と1.9ではStringや文字リテラルの挙動が変わっています。また、Ruby 1.9よりString#eachはなくなり代わりにeach_byte、each_char、each_lineを使うようになります。文字列同士を比較・結合する時には若干注意が必要で、比較では双方が同じエンコーディングでなければ等しいこととはみなされません。
Rubyコードを書くファイルにはファイルの先頭(shebangの下)に「# -*- coding: UTF-8 -*-」というMagic Commentを書く必要があります。-Kオプションは1.9でも有効になりますが、Magic Commentが優先されます。
IO#openに関するサンプルコードをいくつか示した後、Martin氏によるtranscoding(文字コード変換)の説明に移りました。詳しい使い方はテストコード を見ればよいそうです。
ファイル名や関数名などはtranscodeというネーミングが使われていますが、メソッド名はまつもとさんの要望によりString#encodeになりました。
実装の説明はコードやデータ構造レベルにまで及びます。str_encodeまたはstr_encode_bang関数で文字列を受け取り、str_transcode関数でパラメータ解析を行います。そしてtranscode_dispatch関数でtranscoderを決定し、1バイトずつtranscode_loop関数にて処理していきます。
変換する際に一対一で対応していくと膨大な数になるため、Unicode(UTF-8)を変換ハブとして利用しています。1バイトずつ、1つのバイトごとに2つのテーブル「offsets」「 infos」を利用します。テーブルを2つ持つことの利点として、以下が挙げられます。
同じバイトでinfoをシェアできる
似たようなエンコーディングの時にコード構造をシェアできる
最後に、次にやるべきこととしてテーブル入れ換え処理の見直し、より多くのエンコーディング対応、テーブル生成処理の見直しなどが挙げられ、セッションのまとめが行われました。
質疑応答では、以下に挙げた項目があがり、エンコーディングに対する関心の高さが伺えました。
Cygwin環境は?
A: Unix環境と同じように動くはず。
RDocでMagic Commentがそのまま出る
A: RDocを直せばいいじゃない。
「自動変換はサポートする?
A: 将来、指定出来るようにする。
ほかにも、正規表現のエンコーディングの扱いについて熱い議論がされていましたが、正直、全然ついていけませんでした(汗。非常に内容の濃い、難しいセッションでした。
Ruby《を》教えてるんじゃない、Ruby《で》教えてるんだってば(増原英彦さん)
東大でプログラミングやコンピュータサイエンスを教えている増原さんによるセッションです。
アメリカの大学ではコンピュータサイエンスを選択する学生が2000年以降から減少傾向にあることをグラフで示し、これからはハッカーではない人に目を向けるべきと主張しました。
講義のプログラミング言語にRubyを選んだ理由として、以下を挙げました。
ほかにもOcamlやScheme、JavaScriptなどの候補があったようですが、Lispの世界や関数プログラミングの世界で著名な人がRubyを選んだことにより、Rubyに決まりました。ただ、講義では、Rubyのクラスやブロック、イテレータなどのいわゆるRubyらしい機能は使っておらず、トップレベルでメソッドを定義し、forループを使うなどのシンプルな使い方をしているようです。
次に、「 Rubyを採用してよかった点、悪い点」を挙げました。良い点には、次の項目をを挙げました。
多倍長整数の変換ができる
リッチなライブラリがある
簡単に扱える また、計算量の比較を行うときに、Ruby自体の遅さがパフォーマンスの差を明確にしてくれる点で良かったと話し、会場の笑いを誘いました。
反対にRubyを使っててハマッた点として、「 インデントしないことでend忘れが見つかりづらかった」「 ローカルのライブラリをロードしたつもりがデフォルトライブラリだった」「 二重引用符やインデントスペースが全角だった」など、初心者が陥りやすいポイントを挙げていきました。
成功するRuby教育のプラクティス(吉田裕美さん)
2000年に独立し、2005年から教育事業を開始した吉田裕美さんによるセッションです。
吉田さんは最初に、社内にRuby開発者を増やすには教育会社やコミュニティに頼る選択肢もあるが、「 社内で教えること」が一番であると結論づけました。理由としては、社内の特徴を活かすことができ、勉強を行う文化が根付くというメリットにあるようです。また、教える人自身にも「講師役が実は一番勉強になる」などのメリットが存在します。
次に、実習に関するベストプラクティスについて紹介しました。実習をペアプログラミングで行うと考え込む時間が少なくなり実習時間が長くならないほか、一人で黙々と行うのに比べて盛り上がりやすいというメリットがあるそうです。また、TDD(テスト駆動開発)ベースの実習を勧めており、その際テストコードをあらかじめ用意して提供することがポイントとのことです。テストコードを用意することによってテスト単位で取り組めるようになるため、一つ一つの粒度が小さくなり、大きなソフト開発を体験させやすくなります。実際にTDDによる実習を受けた受講者から「ゲーム感覚で楽しい」という感想をもらったそうです。また、ほかの言語で書かれた良質の教材をうまく利用することをTipsとして挙げました。吉田さんは、書籍『なぜ、あなたはJavaでオブジェクト指向開発ができないのか 』( 技術評論社)のサンプルコードをRubyに置き換えて利用しているそうです。ちなみにサンプルコードは次のページからダウンロードできます。
最後にまとめとして、「 教育も開発と同じようにチャレンジに溢れている」と、教育に対する熱い情熱を会場へ伝えていました。
RSpecによるRailsアプリケーションのBDD事例報告(Yugui(園田裕貴)さん)
書籍『初めてのRuby』( オライリー・ジャパン)の著者Yuguiさんが、過去に経験したRailsによる開発プロジェクトについて語りました。
Yuguiさんが入ったプロジェクトは、毎日バグが出続け、テストコードはおろかバージョン管理システムもない状態でした。すぐにSubversionとTracを導入しビルド、デプロイの自動化に取り組み、Seleniumによるテストをチーム内に浸透させました。ただ、それでもプロジェクトの状況は改善されなかったため、1ヵ月後に差し迫ったリリースに向けてCOMとASP.NETで構築されたシステムのリプレースを敢行することになりました。
リプレースでは、フレームワークにRailsを、テストと仕様記述にRspecを採用しました。これらを採用した理由として、YuguiさんがRubyやRailsのソースコードを読んでいて「何か問題があった場合はソースを調べて解決できる」という自信があったことにあります。
フェーズ1となる1ヵ月間でSeleniumの資産を活用しながらたった2人でシステムを作り上げました。そしてフェーズ2でメンバーを4人に増やし、カバレッジを上げることに専念した結果、Rspecのコードが全体の7割を占めるようになりました。そしてフェーズ3ではペアプログラミングやポストイットなど多くの方法を活用して、メンバー全員にRailsやRspec、BDD(振舞駆動開発)の概念を浸透させることに成功しました。
会場から「上司から『テストコードなんか書いてないで実装コードを書いて機能を追加しろ』と言われたと思うが、どうやって説得したのか」との質問がありましたが、Yuguiさんは(説得するのではなく)「 基本的にお前は何もわからんのだから、黙ってろ!」と答えたそうで、会場は爆笑と拍手で埋め尽くされました。
Ruby技術者認定試験 模擬問題解説
CTCテクノロジー株式会社松田慎弥さんから、Ruby技術者認定試験の説明、模擬問題とその解説が行われました。模擬問題をいくつか解いたり、出題傾向などが分析されました(編集部) 。
サブセッション:Rubyで快適に連投する11の方法(ujihisaさん)
ujihisaさんの発表は、第26回Ruby/Rails勉強会@関西にて行われた内容をRubyKaigiバージョンにしたものでした。ちなみにRuby/Rails勉強会@関西のときの資料はslideshareのサイト で公開されています。
ujihisaさんは、普段使っているWebサービスにすばやくPOSTするためのツールをWWW:Mechanizeを使って作っています。そしてVimスクリプトの「LustyExplorer」を使ってVimスクリプトファイルにRubyのコードを記述することができるようにしています。「 :Mixi」とコマンドするとmixiに日記を投稿するvimスクリプトを実演しました。またその応用として「Rubiskell」というRubyコード内にHaskellコードを埋め込めるライブラリを使って、Vimスクリプト経由でHaskellコードを実行してmixi日記に投稿する、というデモを実演しました。
途中、「 有須子」という恐怖系画像が突然現れるGreasemonkeyからインスパイアした、特定ポートで待ち受けているときに誰かからアクセスされると「有須子」画像がデスクトップに表示される「usukod」という冗談系ツールも披露しました。
ライトニング・トークス
本日のメイン・セッションが終わり、いったん休憩を挟んだ後に、ライトニング・トークスが行われました。
「JavaからRubyへ」について、どうしても言いたいことがある(桑田誠さん)
同名の書籍とは関係ないようです。JavaからRubyに言語を変える際、単にコードを変えるのでは意味がなく「考え方」を変えることが重要である、と主張しました。また、コードが変わるだけでは10年前に起きたCOBOL風のJavaコードが量産された歴史を繰り返すことになる、と警告しました。
この問題はプロジェクトについても当てはまり、パレートの法則が示すように80%の成果は20%の上級者によって作られているのに、80%側の初級者に技術水準を合わせるのはおかしい、と「初心者偏重」を批判しました。また、「 Rubyは大規模開発に向かない」という批判を取り上げ、そもそもコードや開発者数の規模が大きくなるのは物事を簡潔にする能力や努力が欠けており、冗長なコードが大規模の要因となっていることがある、と大規模自慢をする風潮を真っ向から批判しました。
dRubyとセキュリティ(西山和広さん)
dRubyを不特定多数に向けて公開するのは危険だ、というお話です。
drb/drb.rbのrdocにはセキュリティ事項が記載されていますが、この方法をそのまま適用しても防ぎきれません。また、INSECURE_METHODを利用してもinstance_evalを使えば呼べてしまい、__send__ではなくsendメソッドを使って呼ぶことも可能です。ほかにもMethodオブジェクトを取得してメソッドを呼び出すことができます。$SAFEのレベルを上げることでいくぶん制限できますが、DoS攻撃は防ぎきれないためOSのrlimit(resource limit)の設定を変える必要があります。
最後にdRubyを利用したプレゼンテーションソフト「Rabbit」を使ってリモートからメソッドを呼ぶデモを行いました。
RubyとODEでピタゴラ装置 (佐々木竹充さん)
オープンソースの3次元動力学シミュレータライブラリ「ODE(Open Dynamics Engine) 」とRubyを使ったデモが行われました。3D画面内にドミノやスロープなどの形状が置かれており、Wiiリモコンで操作して、空中に物体を作ってピタゴラスイッチを実現させていました。
以下の動画は、そのデモの一部です。
ニコニコ動画:https://www.nicovideo.jp/watch/sm3727664 JavaScriptを有効にしてください。 初級者は Enumerator の夢を見るか?(今井伸広さん)
「みねーよ」という身もふたもない結論から始まります。自身のハンドルネームをEnumeratorを使って文字列操作を行ったデモを行ったあと、eachばかりを使う初級者に対してeach_sliceやeach_consですっきり書けることをサンプルコードを通して説明しました。
Rubyで楽しむフォークプログラミング (Webアプリじゃないよ蝙)(高山征大(mootoh)さん)
フォークソングが醸し出す雰囲気のように、趣味で気軽にプログラミングを楽しもう、というお話です。現在はWebアプリケーションが流行っていますが、Webアプリ以外にも楽しく手軽にプログラミングができる、ということでプラグイン開発を勧めています。
例として自身が作ったRubyCocoaを使ったCocoaアプリのブラグインや、Rubyで記述できるVimスクリプトを紹介しました。
Ruby.pm - CライブラリとしてのRuby(藤吾郎さん)
CPANに公開されているPerlモジュール「Ruby.pm」の紹介です。Ruby.pmはRubyのC APIを呼び出してPerlからRubyの機能にアクセスできるモジュールです。
いろいろなサンプルを示しながらも「テストが完全に通らないので実質使えない」と自虐的なオチで締めました。
toRubyでみつけた Rubyist人生再出発(池澤一廣さん)
ちょっとしたドラマを感じた、心にしみるTalkでした。
2000年にRubyを初めて知り、テキスト処理として使っていました。「 昔はワープロ喫茶というのがあった」という昔話を交え、awkやらPerlやら次々に知らない技術が出現して苦労した話を披露しました。そしてRubyを知り、ずっと使っていたもののいっこうにクラスを扱えなかったり、メーリングリストを読んでもついていけない状況が続きました。
そして2007年、dRubyの開発者である咳さんが同じ栃木であることを知り、勇気を出してコンタクトをとったところ勉強会を行うまでに至りました。
「まだまだついていけていないところがあるが、最後は自分が頑張るしかない」と結論づけ、栃木Rubyの会に感謝の意を述べ終了しました。
終わったあとのIRCには「感動的な話だった」「 泣きそう」「 全つくばが泣いた」と感動した旨のログが流れていました。
Ruby 1.9 on Rails 2.1による新時代DBプログラミング(松田明さん)
まずDBプログラミングの現在までの変遷から入りました。PHPで生SQLを書くプログラミングを「古代」 、O/Rマッパーを利用しXML地獄に悩まされることを「近代」と位置づけ、ActiveRecordを利用するのが「現代」のDBプログラミング手法と語りました。
しかしながら、実際の業務がActiveRecordの持つCoC(Convention over Configuration:設定より規約)にぴったり当てはまることは少なく、結局生SQLを書くはめになってしまいます。そこで、「 そもそもDBとは集合演算である」という考えに基づき、Rails 2.1より利用できるnamed_scopeの紹介をしました。
テストベースコードリーディングのすすめ(遠藤侑介さん)
今年の1月よりRubyのコミッタになり、Rubyのコードを読んだときに身につけた方法の紹介です。
方法自体は簡単で、gcovというテストカバレッジツールで測定し、実行されていない行を探して、実行するようなテストコードを書くというものです。テストコードを書く際、周辺のコードを読まなければいけないため、結果的にコードリーディングが促進されます。また、テストコードが充実していきバグも見つかるのでやり込みゲームの感覚で楽しめる、というメリットもあります。逆に、すでにテストコードがある個所は読めず、重箱の隅をついたような部分しか読めないという問題点もあります。
この方法は「テストコードが充実していないこと」が前提条件となり、Rubyはそういう意味では最適だったそうです。この方法により、当初70%だったカバレッジを85%にまで上げることに成功しました。ち
なみに、ほかのLLではPHPが51%と最も低く、この方法を試すにはうってつけのようです。
A Jail Web Development with Rails 2008 でわっふるわっふる(竹迫良範さん)
似たような名前の書籍とは関係なく、Webアプリを堅牢にするというテーマです。
CGI.escapeHTMLを使ってサニタイズ……ではなく、HTMLエスケープを行っていても、問題が起こるケースがあり、実際にブラウザの文字エンコーディングバグによるXSSのデモを披露しました。
そこで、Apacheの設定ファイルにエンコーディングを指定するとその範囲外の値をフィルタリングするというApache 2モジュール「mod_waffle」を開発し公開しています。
Industrial-Designed Language: Ruby(斎藤ただしさん)
トラブルでプレゼン資料が用意できず、スピーチのみで行いました。Rubyを「工業デザイン」として見る、というテーマです。
2007年のグッドデザイン賞にFirefoxが選ばれた背景には、ソフトウェアは人が使うものであるため工業製品ともみなせる、ということがあります。よってRubyも工業製品であるといえます。
また「何も説明せずともわかる」という概念を表す「アフォーダンス」という観点から見て、名前を見れば使い方を推測できるRubyはアフォーダンスを重視しており、工業デザインとして優れていると言えます。
このような使いやすさを重視し、優れている言語を使わないのは損をするので使おう、と何度も主張し、最後に「そしてMatzの屍を超えて新しい言語をRe-designしましょう!」と熱いスピーチを締めました。