茨城県つくば市のつくば国際会議場にて日本Ruby会議2010が開催されています。本日は3日目、最終日です。本稿では、3日目の模様を随時レポートしていきます。
今年も世界各地からRubyistのみなさんが参加されています。
Kei Hamanakaさん、Yuichi Saotomeさん「Rubyでクラウドを便利にする方法~ニフティクラウドの事例~」
@nifty からは、WebアプリケーションエンジニアのHamanakaさんと、インフラエンジニアのSaotomeさんが登壇し、ニフティクラウド がWebアプリケーション開発をどのように変えるのかを紹介しました。
@niftyでは、ココログ広場 やアバウトミー 、@nifty TimeLine などのRuby製・Rails製アプリケーションが数多く運営されています。いざ、Webアプリケーションを開発しようとすると、「 インフラ設計」「 サーバ調達」「 ミドルウェア設定」といった下準備は避けて通れない道であり、なかなかに大変な作業が発生します。
自動化できずに人手による作業に依存してしまうと、Haas(Human as a Service)な状況になり、とてもスケールできません。こういった背景の中で、Iaas(Infrastructure as a Service)は「プログラマブルなインフラ環境である」と説明し、Rubyを用いた作業の自動化について話されました。
IaaSを提供するニフティクラウドは、今月10日に開発者向けAPIの公開を開始し、プログラムによる自動化を支援しています。現在はSOAPのAPIのみですが、今後、RESTのAPIも提供される予定です。例として、Wakame とニフティクラウドを組み合わせて、負荷の状況に合わせて自動でインスタンスを生成・削除したり、設定を変更したり、といった自動運用の話が紹介されました。
ニフティクラウドの特徴として「オンデマンド」「 従量課金」「 伸縮可能」「 @niftyで培った高い運用実績」をあげ、最後に「国内のクラウドサービスなので、海外のサービスに比べてレイテンシが低いです。ぜひご利用ください」と、自信をみせて紹介しました。
Toshiyuki Terashitaさん「Rubyによる分散ストレージシステムの実装」
発表者のTerashitaさんはリコーに所属するエンジニアで、鳥取Ruby会(tottoruby)の主催もされているそうです。リコーではquanp というオンラインストレージサービスを運営しており、数GBのファイルをアップロードできること、PDFやPhotoshopなどのファイルやドキュメントを画像化できることが特徴と紹介がありました。
quanpの初期の頃のストレージでは、RailsアプリケーションでNASをマージしてたそうですが、設計も管理も運用もかなり大変だったそうですが、現在では単一ノードの構成になっているとのことです。とは言え、現状実質スケールアウトが不可能でスケールアップも不可能なことから、これからは30台のサーバーを導入し、近いうちに100台以上の構成にするとのことでした。それをサポートするのが、Rubyによる分散ストレージシステムの「Castoro」であることが説明されました。
Castoroを実装する前にmobileFSやkumofsについて調べたそうですが、どちらも「巨大なファイルの扱いが不便、向いていない」「 NFSが使えない」などの理由により断念したそうです。なぜNFSにこだわるのかという話では、画像処理の関係で使わないといけないと話しますが、スケールアウトするには向かないため「本心としては捨てたい」とも述べていました。
Castoroには数百KBから100GBまで扱えること、HTTPとNFSの両方でアクセスできることが求められていたと話します。逆に任意文字列キーを捨て、キーは数値に限定したそうです。また、キーのユニーク性の保証についてもCastoroでは行わず、アプリケーション側で行う必要があると説明されました。
Castoroの特徴として「遅延レプリケーション」「 ファイルIOはNFSとHTTP」「 マルチキャストの利用」と話し、実装としてはCastoro::Client、Castoro::Gateway、Castoro::Peerの3つのコンポーネントで構成されることが示されました。
最後に、Rubyで分散ストレージシステムを実装した感想として、「 プロトタイプの開発が楽だった」と話します。CastoroのVersion0.0.0(試作品)はCastoro::Client、Castoro::Gateway、Castoro:Peerの3つのコンポーネントの実装とマルチキャストの実験を含みますが、Terashitaさん一人で一日でできたことが述べられました。また、RubyはExtentionの開発がラクであるとも言及し、クリティカルな部分をC/C++で書けることで「どうにでもなるという安心感」があると述べられていました。
Castoroについてはgithub上でLGPLライセンスで公開されている とのことです。
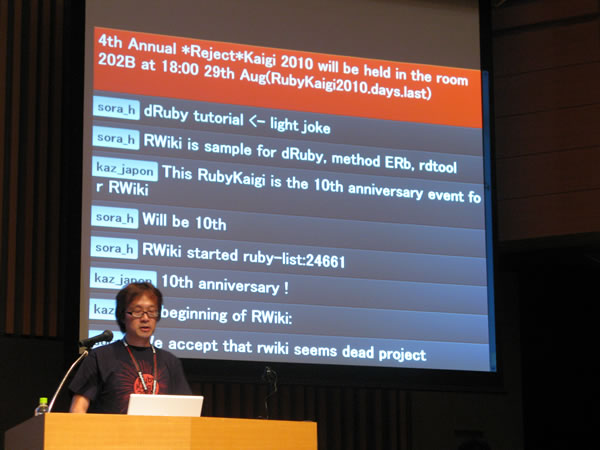
Masatoshi SEKIさん「RWikiと怠惰な私の10年間」
SEKIさんの発表です。冒頭で「Castoro、おもしろかった!」と一つ前の発表に言及してから、セッションがはじまりました。
最初に「私」に関する紹介がありました。SEKIさんはとちぎRuby(toRuby)を開催されており、毎月第一水曜日に開催しているとのことです。また、「 サラリーマン」と「自称アーティスト」であると述べ、「 理想の開発者とかうさんくさい」「 オープンソースに愛はなく自分のため」などと話し、会場の笑いを誘っていました。
SEKIさんはdRubyの開発者であり、dRubyについて解説された本「dRubyによる分散・Webプログラミング」の初刷が5周年と話し、会場から拍手がありました。RubyKaigiについては5回登壇しており、皆勤賞であるとも語っていました。
RWikiの現状
RWikiはオープンソースソフトウェアとして、cosmixngのsvnで管理されているそうです。ここ最近では特に変更は加えられておらず、Ruby1.9の対応については「飽きた。むしろ1.9がRWikiに対応してほしい」と述べました。RWikiは非公開のものと公開のものとが存在し、非公開のものは2つあり、それぞれ35,000ページと25,000ページにもなっているそうです。
RWikiは10年前にruby-listで公開されたのがはじまりで、8月31日に10周年を迎えるそうです。RubyKaigiの開催日と近いことからRubyKaigiはRWikiの10周年記念イベントであると冗談を交えながら、RWikiはdRubyやERB、RDToolのサンプルとして作られたと説明されました。
RWikiの特徴
RWikiはRDを使うWikiであり、機能としては特徴的なものはないと話します。どちらかと言うと実装の方が自慢とのことです。dRubyの長生きなサーバとCGIで構成されており、CGIは実質ただのHTTPインターフェースであると説明されました。
拡張性については「プラグインはよくわからない」と話し、機能としては用意していないそうです。とは言え、dRubyを用いれば外部から操作し放題とのことです。
ビューについてはHTMLを生成するオブジェクトがあり、RDからERBソースを生成し、さらにそれをコンパイルをしたものを保持しているとのことでした。
RWikiはデータやオブジェクトを全てメモリに配置するとし、ファイルは起動時に読込むそうです。RWikiはデータベースを持たないのでSQLもORMも不要と説明し、むしろRWikiがデータベースのように見えることから「RWikiはドキュメント指向データベース、10年前からバズワードをおさえている」と冗談混りに話されていました。
某サイトの紹介
某サイトの紹介と称し、10年間の運用でおきた問題と対応について話されました。ある大きなチーム向けのRwikiがあり、35,000ページと25,000ページのRWikiが1つのマシンで動作し、プロセスのサイズが1.2GBにもなることから「Rubyは案外強い」と話されていました。実行中のレスポンスも特に問題はないが、再起動に時間がかるのが問題だそうです。
いくつかカスタマイズを加えられているそうで、主にStoryCard拡張やTestSuite生成などが実装されているそうです。StoryCard拡張は運用中でもチケットの属性や書式、ワークフローがどんどん変更できると話し、この紙のような無法ぷりが長期的な運用には必要と説明されました。TestSuite生成はたくさんのテストケースを見せるとやる気をなくすことから、テスト計画、成績などからおすすめのものを抽出する機能だそうです。他にもCSVのブラウズなどに手が加えられているとのことです。
運用中の問題として、「 基本的には遅いんですけど問題」と称し、起動やirb操作、全文検索が遅いことが問題と話します。起動については、「 数ヶ月に一度の問題なので我慢できなくもない」と述べ、結局他者に指摘されるまで直さなかったと語られました。また、ページ数が増えるにつれレスポンスが悪化した問題はめずらしく自主的に直した問題だそうで、「 たまにやると気分がいい」とのことです。
RWikiはirbからdRubyを用いて操作することができるそうですが、メソッド名を打ち間違えると反応が非常に遅くなる問題があったそうです。原因についてruby-devで相談したら、Matzさんから「咳さん」のアクセントについて話題をふられ、そこで議論は終わってしまったそうです。
問題の傾向としては、オブジェクトを一つのプロセスに配置することは自然としながらも、主にそれによるメモリや、速度の問題が多いと話されました。オブジェクト数がボトルネックになることが多く、「 不要なオブジェクトを保持しない」「 問題が起きてから考える」とも述べられました。
また、規模については今後のことは予想がつかないので、あらかじめ準備するのは無駄と話し、問題の状況に応じて対応すべきと説明されました。数GBのGCについても少し触れ、そこそこと評しながらも「GC開発者はRWikiに挑戦すべき」と会場の笑いを誘っていました。
ところどころでSEKIさんの挟む小ネタが聴衆の笑いを誘い、終始なごやかなムードの発表でした。
Alex Sharpさん「Practical Ruby Projects with MongoDB」
Alexさんによる、MongoDBの発表です。最初に「SQLの問題」と称し、RDBMSは悪くないとしながらも、RDBMSは開発者のニーズに合わないと話します。開発者はオブジェクトを扱うが、そのオブジェクトとRDBのリレーションが合わないと言及し、ORMはオブジェクトとリレーションをマッピングするが、もっとうまくできるはずと語りました。ストーカーの例をだしながら、MongoDBはjsonでデータを格納することや、RDBMSと違い不要なテーブルを作る必要がないと説明されました。AlexさんはSQLも悪くはないと話しながらも、「 Rubyistだからこれで満足してはいけない」と述べました。
MongoDBの特徴
MongoDBの特徴として「スキーマがない」「 アジャイルでイテレーティブな開発に向く」ことをあげていました。マイグレーションについては不要と言い切り、面倒なだけと話します。MongoDBはドキュメント指向でそもそもRDBとは考え方が違うと述べ、embedded documentのおかげでかなり楽ができると話されました。
MongoDBは書き込みと読み込みが早いとし、「 upsert(Update + Insert)」という概念とインデックスについて説明されました。upsertはドキュメントが存在すれば更新、なければ新規に追加するという概念で、MongoDBのrubyドライバーではsaveメソッドに相当します。MongoDBではインデックスを張ることが可能で、複合キーも用いることができると言います。JOINやトランザクション、参照整合性はサポートされていないと説明がありました。参照整合性については、データベースではなく、アプリケーション側の責任であると説明されました。
Practical Projects
Practical Projectsとしていくつかの事例の紹介がありました。1つ目は簿記アプリケーションでMySQLなどでは複数のテーブルを用意する必要があり、トランザクションが必要になりますが、MongoDBではembedded documentsがあるためデータモデルが簡潔に定義できると説明されました。
2つ目はcapped collectionによるロギングのお話でした。MongoDBにはcapped collectionというmemcachedと似た機能があり、それを用いてログの分析を行われるそうです。
最後に定番な例として、ブログアプリケーションの実装についてお話されました。ブログについては実はSQLよりMongoDBの方が作りやすいとし、SQLではPostモデルはAuthor、Tags、Commentsの3つのモデルが必要になりますが、MongoDBではembedded documentsを用いることでTagsを配列としてPostモデルに格納できるため、簡潔に定義できる上にちゃんと検索できると説明されました。
Object-Document Mappers
MongoDBにもORMのようなものがいくつか存在しており、「 Ruby Mongo Driver」「 MongoMapper」「 Mongoid」の3つが紹介されました。勉強としてRuby Mongo Driverを直接叩くことをおすすめされていました。MongoidについてはRails3と相性が良いと話し、Rails2とRails3それぞれで使えると述べました。
質疑応答
質疑応答ではたくさんの人から質問があり、MongoDBへの注目が伺えました。MongoDBはまだまだ情報が少ないので、実際に使用している方のお話はとても貴重でした。
Kenta Murataさん「bigdecimal ライブラリと Ruby の数値系の未来」
BigDecimalのメンテナであり、Ruby札幌メンバーの一人である、Kenta MurataさんのBigDecimalの発表から中ホール最終日は始まりました。セッションの冒頭で、12月4日に札幌Ruby会議03 が開催されるとの告知がされました。
BigDecimalとは、Rubyに標準添付されている数値計算ライブラリです。BigDecimalクラスとBigMathモジュールの2つから構成されています。BigDecimal classは多倍長浮動小数点数を扱うことができ、メモリが許す限りまで"一応"小数を扱えるクラス。もう一つのBigMath moduleは、BigDecimal用のMathモジュールです。Mathクラスのメソッドに対応しており、桁数を指定できるようになっています。今回Murataさんは、このBigDecimalが抱えている問題点を指摘しました。
グローバルに管理されている動作モード
BigDecimalでは、動作モードを設定して、例外発生の有無や、計算の丸め方を設定できるようになっています。しかし、「 動作モードがグローバル変数であるため、スレッドセーフでない」とMurataさんは指摘されました。
そのため、Murataさんは発表の前日に動作モードについて、Rubyのスレッドごと独立した動作モードを設定できるように改善したことを説明されました。さらに、ブロック内で動作モードを変更しても、ブロックから抜けた時にはモードが戻るようにされたそうです。このブロックでの動作は、「 動作モードがスレッドセーフになったからこそできた」と語られました。
有効桁数について
小数点第何桁まで意味があるかということを示すのが有効桁数です。「 現在のBigDecimalでは、この有効桁数が管理されていない」とBigDecimalの問題点を指摘されました。現在の実装では、メモリ確保済み桁数と使用済み桁数が管理されているそうです。また、RubyのFloatも有効桁数を管理していないため、BigDecimalとFloatを混在して使用した場合、Floatへ強制変換されるため、数値の信頼性がなくなってしまいます。
インスタンス生成
BigDecimalのインスタンス生成は、文字列から生成します。
BigDecimal.new("3.14")
しかし、数値からインスタンスを生成することができず、さらにBigDecimalのインスタンスからインスタンスを生成もできません。「 インスタンス生成方法も改善していきたい」と述べられていました。
スピード
BigDecimalは内部での数値の表現方法が複雑であるため、かけ算や割り算の計算が遅くなっているそうです。しかし、計算を短縮するアルゴリズムがあるため、それを利用することで早くできるため、改善していきたいと述べられました。
BigDecimalの未来について
Murataさんは、今後のBigDecimalの未来として、「 Rubyでは無理数に対応したクラスがないため、計算可能実数を利用してBigDecimalで対応したい」と意気込みを語られました。計算可能実数を利用することで、無理数を内部ではアルゴリズムとして表現し、小数表現が必要になったときのみ計算するという方法をとることで、きれいに実装できるのでは、と説明されました。
Masahiro Tanakaさん「NArray and scientific computing with Ruby」
Ruby/NArray の開発者である、Masahiro TanakaさんによるNArrayの紹介です。NArrayとは、多次元数値配列クラスのライブラリです。NArrayを使用することで、大規模な多次元数値配列の計算を高速かつ簡単に扱うことができます。
最初に、Ruby/NArrayを利用している科学分野を紹介してくれました。使用されている分野としては、「 地球物理学」「 物質科学」「 分子生物学」「 力学」など幅広い分野で使われているそうです。
Ruby/NArrayは、1999年に0.3.0を最初にリリースされ、「 IDL(Interactive Data Language) 」 「 Yorick」「 Python Numeric」などを参考に作成されたと語られました。NArrayの実装の特徴としては、「 次元数の扱い方」「 配列の形」「 要素の型のもち方」「 メモリブロック」というのがあるそうです。
続いて、Ruby/NArrayの操作方法が説明され、Rubyの配列で計算を行ったときとの、コードと速度の違いが紹介されました。Ruby1.9.2で100万の要素のある配列同士のかけ算を行なった場合、
(0...n).map{|i| a[i] * b[i]}
のようなコードになり、180msかかるそうです。しかし、NArrayなら、
a * b
と書け、6.4msと28倍速くなりました。簡潔に記述できて、高速というのは嬉しいですね。ただし、NArrayは直接メインメモリにアクセスしてしまい、最近の計算機のアーキテクチャにはあっていなく遅くなってしまうことがあると述べられました。
最後に、現在研究されている並列分散ワークフローについて説明されました。科学データ処理は複雑なワークフロー記述が必要なのですが、現在はMakeを使って記述されているそうです。しかし、Makeでは表現力が乏しいため、より表現力のあるRakeを利用したPwRake を作成されています。
Q&Aでは「NArrayは標準添付になりませんか?」という質問に対して、「 今は満足していないので次のバージョンで満足できれば標準添付にしていきたい」と意気込みを述べていました。
Hideki Miuraさん「yarv2llvmはどう失敗したのか」
Hideki Miuraさんによる、Yarv2llvmというRuby1.9から採用されているYARVのバイトコードをLLVMで動作するように変換するツールがどのようにして失敗していったのか、そして今後新たに取り組んでいくYtlというツールの紹介が発表されました。
まず、そもそもなぜRuby処理系が遅くなってしまうのか、という問題は以下の2点にあると語りました。
Dynamic Method Search ( 実行時でないと解決できない)のコスト
BONXING/UNBOXING によるデータ変換のコスト そして、その問題点を「型推論を利用することで解決できるのではないか」ということを出発点としてyarv2llvmの開発が始まったのですが、型推論を行う時間が掛かりすぎてしまうなどの理由で頓挫してしまったそうです。
そこで、新たに開発が始まったのがYtlです。YtlはRuby1.9の機能をフルセットでサポートすることを目標に開発しているトランスレータです。
現在の進捗状況として、簡単な型推論なしでHelloWorldが表示される程度とのことでしたが、今後の展望や乗り越えていく必要のある課題についても語り、今後の発展に期待が高まる紹介になりました。
Satoshi Shibaさん「Ruby 用 AOT コンパイラ」
東京大学笹田研究室 の学生の芝 哲史さんによる、Ruby用AOTコンパイラについての発表です。AOTコンパイラ(rcc)とは、ahead-of-time(AOT)といい、実行前にスクリプトを機械語に変換すること方法のことです。最初は笹田さんと卜部さんによって作成されていたものです。
rccは、「 Rubyの高速化」「 Ruby1.9との互換性」をかかげ、いつかRuby自身に取り込んでもらうという大きな目標があるようです。
rccでは、1つのスクリプトから1つのバイナリを生成する形式をとっているそうです。生成されるファイルは、単体実行可能ファイルと共有ライブラリの生成できます。ソースコードの変換の流れは、一度YARVのバイトコードに変換されたコード列をCの関数に変換します。その変換方法は、テンプレートを使用して変換していると説明されました。そのとき、高速化や変換後のコードサイズ削減のために工夫されていることが述べられました。
現在rccは、互換性や可搬性、細かい高速化については実装が完了しているそうです。今後は、「 プロファイル情報を用いたコード生成や、更なる最適化を目標としている」と、今後の展望を述べられました。
最後にrccの評価を紹介し、現時点の総括を以下のようにされました。
Rubyについているテストは99%通過
5種類のOS、2種類のプロセッサアーキテクチャで動作可能
マイクロベンチマークは全体的に速度向上
マクロベンチマークの速度が低下してしまうものもある
今後の更なる改良に期待です。
Tetsu Sohさん「Memory Profiler for Ruby」
Tetsu Sohさんが、現在研究されているRubyのメモリプロファイラについて紹介されました。Tetsuさんは、一つ前に発表された芝さんと同じく、東京大学笹田研究室 の学生さんです。
まず、Tetsuさんが作成したメモリプロファイラの使用方法をデモ動画で紹介されました。動画の内容は、RDocを動かし、メモリが解放されない箇所を特定するという内容でした。Rubyのソースリポジトリにあるlibディレクトリに対してRDocを実行したところ、ドキュメントの生成に15分かかって、1.3GBのメモリを消費していたそうです。しかし、このメモリプロファイラを使用して問題点を発見し、RDocに対する3行の修正で7分の生成時間、82MBのメモリ使用量になったことが述べられました。
Tetsuさんの作成されたメモリプロファイラのUIは、とても優れたものでした。実行しているアプリケーションの状況がリアルタイムに確認できるだけでなく、アプリケーションの実行を止めたり、再起動したりできます。また、どのオブジェクトがGCされたかという円グラフが見れたり、そのオブジェクトがソースコード内のどの箇所に沢山あるかというのがわかるようになっています。動画内でメモリプロファイラの操作が行われるたびに、会場からは歓声があがりました。
「可能な限りメモリプロファイラによる影響を少なくする」「 取得するプロファイル情報の変更を簡単に行なえるようにする」というコンセプトで作成されていることが話されました。影響を少なくするため、RubyVMとは別にプロファイラのバックエンドを持つようにし、VMのeventとcontrol情報のやりとりを行なっているそうです。バッグエンドからは、Javaで作成されたプロファイラのフロントエンドにTCP/IP経由で情報を送りあっていることが説明されました。また、どのプロファイル情報を取得するかをコントロールできるようにもなっていることが述べられました。
IRCやQ&Aで、「 すぐ使いたい」という声が沢山でていました。Tetsuさん自身も「RubyのVMの一部を変更する必要があり、現在コミット件はない。でも1.9.3には入れたい」と意気込みを語っていました。
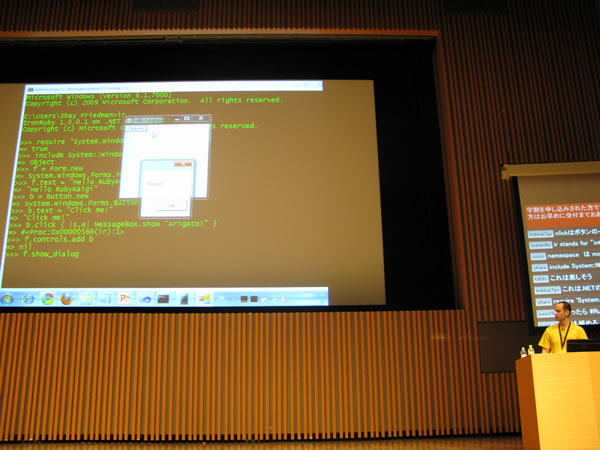
Shay Friedmanさん「IronRuby - What's in it for Rubyists?」
Shay Friedmanさんによる、今年の4月に1.0がリリースされたIronRubyの発表です。聴衆に対して「MacBookやiPhone持ってますね。IronRubyはMicrosoftだよ」というジョークで笑いを誘いながらの開始となりました。
「.NET、Microsoftの世界と繋げたい」と語り始めたShayさんはIronRubyが好きで、そこからRubyを好きになった。だから、みんなにもIronRubyを通じて.NETを好きになってもらいたいと語りました。
IronRubyの特徴として、.NET Frameworkとのシームレスな連携ができるデモとし、irb上で.NET上のwindowライブラリを読み込んでウィンドウとボタンをを表示させるデモを行ない、容易に連携できることが紹介されました。
.NET Framework との連携の容易さとして、クラスやメソッド名がRuby形式になっていたり、namespaceがModuleになっているため、Rubyからの操作でも違和感なく扱えると述べられました。
また、リリースされたばかりのIronRuby1.0はRuby1.8.6相当とやや古いバージョンなのですが、次のリリース予定であるIronRuby1.1はRuby1.9.2相当としてリリースされる予定だそうで、できるだけ早く出したいとのことです。
WPFを使ったデモとして、Twitterのトレンドを表示して、クリックされるとトレンドの検索結果を表示するWindowsアプリケーションのデモが行われました。そして、ソースを表示して、Windowsの表示などを行う部分のソースコードが20~30行程度でかけることが説明されました。
その後、Silverlightを使ってブラウザ上で動作するデモが行われました。ブラウザ上でSilverlightを使うためのJavaScriptファイルを読み込んだあと、HTML上でJavaScriptを書くのと同じように、
<script language="ruby">
内でRubyのコードを書いてDOMを操作できるということを、HTML上のソースコードを示しながら説明されました。
最後にエミュレーター上ではあるものの、Windows Phone 7上でも動作するというデモを行い、IronRubyの可能性について多くのことが語られました。
なお、IronRubyについての情報源としては、以下を参照すると良いとのことです。
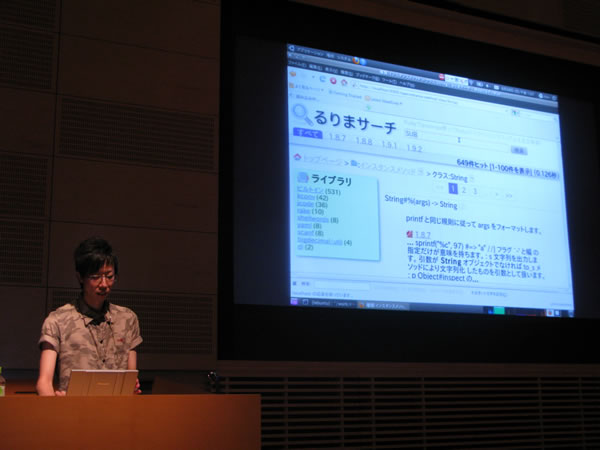
Kouhei Sutouさん「るりまサーチの作り方 - Ruby 1.9でgroonga使って全文検索」
「Rabbitを使っていないとコミッタにはなれません。プレゼンテーションにはRabbitを使いましょう」といって発表を始めたのは、Rubyのコミッターであり、件のRabbit や画像処理ライブラリrcairo の他にも、数多くのプロダクトで知られるSutouさんです。RubyKaigi2010用には、名札には名前を大きく書きましょうジェネレータ を開発して公開されていました。
今日は、るりまを全文検索するWebアプリケーション「るりまサーチ」の紹介です。
単にクエリを入力して全文検索するだけではなく、Rubyのバージョンを指定したり、「 インスタンスメソッド」等の種類を指定してドリルダウン検索(絞り込んで検索)することもできることが説明されました。また、検索結果ページのURLにクエリを含めるようにすることで検索エンジンにもインデックスされやすくなっていることや、さらにはキャッシュを有効活用しており、高速にレスポンスを返すように実装されていることが語られました。
前半は「ユーザから見たるりまサーチ」の紹介でしたが、後半は「るりまサーチの作り方」について話されました。
るりまサーチでは、バックエンドとしてgroonga を使用していることが言及されました。groongaは、Senna: An Embeddable Fulltext Search Engine - Senna 組み込み型全文検索エンジン の後継にあたる全文検索エンジンで、連携するRDBMS側の更新時にロックが発生してしまうというSennaの問題を解決するため、自前でデータストアを持つようになっています。おかげで、高速でロックフリーな検索が実現され、るりまサーチのようなアプリケーションの内部で活躍していることが説明されました。
groongaがカラム指向であることも、るりまサーチの上で活きていることが語られました。よく知られたRDBMSとは異なり、groongaはレコードごとではなく、カラムごとにデータを保持するため、ドリルダウン検索に向いていると言えるそうです。大量のデータの中から「ある属性を持ったデータの集合」を取り出すときには、カラム指向データストアが有効であると説明されました。
最後に、るりまサーチの「副産物」であるとしてracknga の話が少しだけ語られました。興味のある方は、こちらも合わせてチェックしてみてください。
Tom Lieberさん「ゲームとバーチャルタイム」
iPhoneアプリのOcarina や、iPadアプリのMagic Piano はご存じでしょうか。これらの革新的なプロダクトを提供するSmule から、開発者のTom Lieberさん の登壇です。発表では、Rubyのプログラム上でのタイミング制御について話されました。
Tomさんの発表は、なんと楽曲の演奏から始まりました。テキストエディタに書かれた
piano([C3, E3, G3])
といった、なにやら演奏用と思しきコードが次々と実行されて奏でられるリズムに、発表の舞台である中ホールは愉快な雰囲気に包まれました。歓声と拍手のあと、実装技術についての説明へと入りました。
ニコニコ動画:https://www.nicovideo.jp/watch/sm11927013 JavaScriptを有効にしてください。 まず紹介されたのはChucK 、オン・ザ・フライ方式のオーディオプログラミング言語です。特殊なタイミング制御を行っているのが特徴で、ChunKにおけるスレッドは「Shred」 、スケジューラは「Shreduler」 、フォークは「spork」と、それぞれ呼ばれます。
Tomさん作のライブラリruck は、ChunKの強力なタイミング制御の力をRubyにもたらすのです。通常のRubyのコードでは、例えば2つのオーディオファイルを読み込んで再生しようとしたとき、読み込みにかかる時間が異なれば、同時に再生を始めることはできません。RubyのThreadの代わりにruchのShredを使えば、タイミングを制御することができることが説明されました。
説明の中で、もう一度、音声を扱うサンプルが示されたあと、ruck のサンプルにも含まれている宇宙空間をさまよう宇宙船を操作して星を集める2Dアニメーションゲーム のデモが行われました。これには、午前の企画「Rubyゲーム会議 」に参加していた聴衆たちが大いに食い付いており、発表終了後も、ソースコードを通じたコミュニケーションが盛り上がっていたようです。
デモも参加者からの質問も多く、賑やかな発表でした!
Hiroshi Yoshiokaさん「Ruby業務システムの広がりとホットスポット島根」
島根で長年システム開発を行っているというYoshiokaさんは、「 今日はスーツ族の代表として来ました」と述べてから、島根でのRubyを使ったシステム開発の取り組みについて発表されました。
島根では、まつもとさんをテコにしてRubyがマスコミにも取り上げられ、松江市民の半分くらいが"Ruby"をコンピュータ言語だと知っているそうです。
吉岡さんはメインフレームが普及する以前からシステム開発をされていましたが、2009年頃から小規模システムを中心に、Rubyの開発事例を拡大したそうです。産業振興として、Rubyで開発を行うと1/2の補助がでるなど、行政の後押しも強いことが言及されました。
行政などの業務システムではCOBOLを使ったシステムが多く、ベテランのエンジニアはCOBOLerが多いそうです。そんななか、若手のRubyエンジニアの育成と、開発現場から遠ざかってしまったCOBOLエンジニアがWebシステムの開発に参加できるよう、COBOLer向けRuby/Rails教育を行われていることが語られました。
また、テスト駆動開発などには抵抗を感じるエンジニアが多いそうですが、あるべき姿として、厳格なコーディング規約やソースのレビューなどを実施しているそうです。ベテランSEと若手エンジニアが一緒に取り組むことでできることがいっぱいあるはずだ、と語っていたのが印象的でした。
質疑応答では、「 進めていくなか、気持ちの上での難しさは?」という質問に対して、ベテランエンジニアにオブジェクト指向が誤解されてしまっている点をあげ、「 シンプルに業務システムに合わせて示してあげられれば、ノウハウを活かせるのではないか」と述べられていました。
淡々とした語り口のなかに、RubyKaigi2010のテーマである「Conflicts and Resolution(衝突と解決) 」が詰まった発表でした。
Shintaro Kakutaniさん「There Is No Spoon -- Think Global、Act Regional」
Kakutaniさんの発表は、"I come here not to how good RubyKaigi is、but to thank RubyKaigi that made my life much better."との言葉で始まりました。
角谷さんは、いまだにRubyの良さはうまく語れないが、「 禅とオートバイ修理技術」という書籍から「Rubyには『クオリティ』がある」と述べ、時代を超えて受け継がれてきた価値がRubyにあると言及しました。そして、Clistoper Alexanderの「時を超えた建設の道」からこう語りました。「 質に通じるための道がある。質に通じるための道の入口に門を建てなさい。門を建てれば、そこをくぐって価値に通じることができる。わたし(わたしたち)が建てた門は、RubyKaigiだった。」
この世界に対する違和感(スーツや人月商売)があった、これを映画Matrixから「The Matrix」であるとし、本当の世界に行くための赤いピルとしてRubyを選んだ、と語りました。しかし、少なくとも日本では、Rubyを選んだからといって簡単にうまくいくわけではないという「砂漠のような現実」があった、とも述べました。それを踏まえて、「 私が今日確信を持ってお話するのは、コミュニティのこと」といい、「 コミュニティとは何か?」と提起しました。
これに対して、高橋さんがるびま にて「コミュニティとは誰か。もちろん、あなたのことだ。あなたがコミュニティであり、それ以外にコミュニティはいない。あなたのような人々の集まりを、コミュニティと呼ぶのだ」と述べたことを紹介し、Rubyを好きなひとが集まる場所がもっとたくさんあっていいのではないか、と考え、「 地域Ruby会議(Regional RubyKaigi) 」の提案をしたそうです。
Regional RubyKaigiについて、「 RubyConfの下にRubyKaigiがあり、その下にRegionalがあるわけではない。コミュニティはツリーではない」といい、コミュニティは複雑な全体があり、構造がどうなっているのかわからないようなものではないか、と述べました。そして「『 結果』は焦点ではない」とも述べ、大事なことは、ひとりひとりの活動を続けていくプロセスである、最初から大きな結果を求めていたわけではなく、できることをひとつづつやっていくうちにできることが増えていった、と、RubyKaigiとAsakusa.rbの活動を通じて語りました。
では、最初の一歩をどうすればいいのかと思ったときに、Matrixから"There is no spoon"、「 スプーンを曲げようとするから曲がらないんだ。スプーンなんか無いんだ」と引用し、目の前のものにとらわれすぎると先へ進めなくなる、少しでもいいから自分にできることを始めてみる、それを積み重ねることで大きな成果につながるものができるのではないか、と語りました。
そして、あなたがRubyに感じる価値を見つけ、そこに通じる道の入口に、自分ができることをみつけて「門」を建て、進んでほしい、と語りました。
角谷さんは最後に、「 むかしは人との関わりがうまくとれなかった。RubyKaigiを始めてRubyを好きな人たちと会い、話し、なにかすることで、それがすごく大切なことだと思えるようになった。なので、みなさんRubyistと、Rubyistが存在する世界に感謝したい。そして、そんなRubyを作ってくれたまつもとさんに感謝します」と締めくくりました。
準備していたプレゼンテーションがうまく動かないアクシデントもありましたが、ひとつひとつ言葉を探しながら語る姿が印象的でした。
SHIBATA Hiroshiさん「before Rails 時代のプログラマが如何にして after Rails の世界にたどりついたか」
RubyKaigi2010のテーマである「Conflicts and Resolutions(衝突と解決) 」を軸に、before Rails世代とafter Rails世代という定義の元でのギャップについて語りました。セッションの途中でPCがフリーズしてしまい、中盤を口頭だけで話すというアクシデントに見舞われましたが、資料がなくてもわかるよう丁寧に進められました。
まず、Confictsをテーマとしてbefore Rails世代とafter Rails世代を以下のように定義しました。
このような時代を経て育ってきた世代をbefore Rails世代とし、それ以降の世代をafter Rails世代としました。
そして、よく観察するとその2つの世代ではプログラミングスタイルには、以下のような違いがあると説明されました。
ベタなeachメソッドではなく、mapやinjectメソッドを好む
文字列よりもSymbolを好む
Metaprogrammingを好む そして、Resolutionsとして、普段の行いはあまり変わらないはずなのに、なぜこのようなスタイルの違いが生まれてくるのだろうか、という疑問に対して、GitHubが大きな役割を果たしているのではないかと気がついたそうです。
ソースコードのホスティングとしてはSourceForgeもあるのですが、GitHubの場合はコミュニケーション、フィードバックを受け取る機構が優れており、独自にforkして修正したコードが気がついたらfork元に取り込まれてお礼を言われたりすることがあり、そのような交流から良いサイクルが生まれてくるのでろうと分析していました。
そのことに気がついてから、tDiary(hsbtさんはtDiaryのコミッタの一人です)をGitHubに移行させたそうです。
最後に行われた質疑応答では「after Rails時代に持っていきたいものは?」という質問に対して、「 tDiaryとHikiを持っていきたい」と述べられました。
Makoto Kuwataさん「HTMLデザインをまったく崩さない、美しいテンプレートエンジンの作り方」
Makoto Kuwataさんは、テンプレートエンジンとして必要なもの、テンプレートエンジンを正しく使うためにはどのようなことを意識する必要があるのかを詳しく紹介しました。
ビジネスロジック層(サーバサイドでのロジック部分)とプレゼンテーション層(HTMLテンプレート部分)の分離するだけでは不十分で、正しくはビジネスロジック層とプレゼンテーション層、そしてプレゼンテーションロジック層の3点に分けられるという切り口から話が始まりました。
Matzにっきに記載されていた内容 を引用し、テーブルの行ごとに色を変えるという処理はプレゼンテーション層に入るべきではなく、プレゼンテーションロジック層として分離するべきであると語りました。
また、テンプレートエンジンに求められるものとして、できるだけデザインの担当者が難なく編集や確認ができるようにpure HTMLであることが望ましく、デザインとロジックで作業がコンフリクトしないような形式が良いと話しました。
そこで、Kuwataさんが開発したKwartz を使うことで問題を解決できるとして、Kwartzの詳細が説明されました。HTML内にはid属性にキーワードを含んだ形での名前をつけ、別ファイルで用意するKwartzファイルにその名前と紐づいたCSSライクな記法を用いてロジック部分を記述する、というスタイルで開発ができるようになるそうです。これにより、HTMLはpure HTMLに近く、プレゼンテーションロジックはKwartz用のファイルに集約でき、作業ファイルのコンフリクトも避けられると言及されました。
また、最後に改めて「テンプレートが pure HTML であること」と「プレゼンテーションロジックを分離・独立させること」の2つが大事なことですと述べていました。
Chad Fowlerさん「基調講演」
基調講演は、高橋さんによるChadさんの紹介からスタートしました。Chadさんは、今年日本で翻訳された「情熱プログラマー」をもとに、「 何故すばらしいキャリアを構築することが大切か」ということについて話されました。子供を持つ社会人の平均的な平日の時間の使い方として、53.05%が仕事の時間だそうです。そのため、「 すばらしいキャリアを作ることは、すばらしい人生を過ごすことと同じ」と述べました。
創造的自由
「プログラマーとしてどうやるか言われてやるのは嫌い。何をなし遂げるのか」というのが大事、とChadさんは言います。人によってすばらしい仕事という概念は違います。Chadさんは、「 自分が本当にやりたいことは何なのか」と、よく自問してきたそうです。しかし、未だに答えはでていないが、自問することは今の人生計画を作るためには大切だと述べます。「 スマーフが好きならスマーフになればいい」「 どんなにニッチなことでも追求しろ」「 他の人がおかしなことと思うことであっても好きにやれ」とChadさんは言います。
先送りの人生
「引退後にやりたいことをやるために苦しんでいると考えている人がいる」と話されました。Chadさんは、「 今の人生は将来のためなんてことはやめるべき。待つべきではない。行きたい人生を生きなさい」と語りました。
一見し難しいそうで大事なことは簡単に手に入る
「難しいことでも、システムを作り、それに使うことでやりとげることができる」と、難しいことに挑戦するときのコツが紹介されました。ミュージシャンになった昔のルームメイト、ヒンズー語を学んだとき、ダイエットしたときの経験談を混じえ、目標を達成するためのシステムを構築することの重要性が話されました。
ビジネスに対する自分の価値の提供
自分という商品をどう売りこむかということについて、Chadさんはコードの形で以下のような仕組みが紹介されました。
loop do
choose_your_market
invest
execute
market
end
一番へたくそであれ
Chadさんは、自分より何かできる人と一緒に仕事すると良いと言います。自分が一番下手であることで、他の人から色々勉強ができるそうです。しかし、周りがダメだとそこから悪影響を受けてしまうことがあるため注意するようにとのことです。
専門家vsなんでも屋
自分のキャリアとして、専門家になるという選択肢もあるでしょう。また、なんでもできるなんでも屋になるという選択肢もあります。しかし、Chadさんはどちらか一つを選択するのではなく、どちらになるようにしたほうがいいと言います。一つのことを詳しく知っているだけというのではなく、一つの分野について深く探ることができ、そこに関わる周辺知識を知っているといいと言います。
プログラミングにも練習を
プログラミング業界はOJTと称して、練習なしに仕事をすることが多いです。Chadさんは、練習を自分でするようにすべきと言います。練習用として、以下のような課題をあげました。
Code kata
Ruby Quiz
Project Euler
Golf 誰のために働いているか忘れないようにしよう
タスクの優先順位を決めるのはとても大変です。自分にとって一番重要なことをやるまえに簡単なことをやってしまいがちです。そうはならないよう、誰のために働いているか常に考えるようにと注意されていました。そのためのやり方として「daily hit」というやり方を教えてくれました。「 daily hit」とは、毎日マネージャーが評価するようなことを少なくとも1つやって成果をみせるというボブ・マーティンさんが始めたものです。
8時間完全燃焼
8時間しか働かないって考え方は間違っていると指摘していました。XPの週40時間働くということは、8時間だけ働いて、その8時間でもう働けなくなるほど頑張るという意識でやりなさいということです。
目立ちなさい
「昔すごいことをやった時に傲慢に見えるのがいやだったから、誰にも言わなかった」と、昔の自分をふりかえっていました。しかし、「 誰にもやったことを言わなければ、誰にもメリットがない」と語っていました。そのため、「 目立つことが重要。ただし、印象が悪くならないよう気をつけなさい」と言及しました。
コネを作ろう
RubyKaigi2010に参加していた中学2年生のsoraくんを例に出し、積極的に有名人に声をかけ、コネを作ることはキャリア形成では大事であることが語られました。
ごちゃまぜコラボ
「自分が習ったことを他の人に伝えよう」と、Chadさんは語ります。昔、Rich Kilmerと最初にコードを書いたときは一緒に働くことが嫌いだったが、しばらく働くと仲良くなり今でも一緒にコラボしていると、自分の経験談が紹介されました。
繰り返しを忘れるな
twitter上であった体重に悩みがある人の「毎日、わたしに"昨日よりよくなっているか"と聞いてくれ」というライフハックを例にだし、「 毎日昨日よりよかったことを1つやっていくことで、すごく進歩できる」ということが伝えられました。
燃えつきるな
情熱を燃やして仕事をするということは重要です。しかし、もっと重要なこととして「情熱を使いすぎて、燃えつきないように」と注意をされました。情熱を使いすぎて燃えつきてしまうと、廃人になってしまいます。そうならないように、情熱を節約していく必要があると言及しました。
プログラマだろう?クーラー効いているし、楽しいことやっているじゃん
後半は時間が足りず、早足でプレゼンを終えましたが、わたしたちに情熱を絶やさずに仕事をする重要性が紹介されました。わたしたちが、これからも情熱をもって仕事をするのに役立つ、素敵な情報が沢山ありました。
クロージング
実行委員長の高橋さんからクロージングの挨拶が行われました。その際、次回のRubykaigiが2011年7月東京で開催されることが発表されました。
来年のRubyKaigiのテーマが「最後のRubyKaigi」と言及されたときには会場の空気が一瞬固まりかけましたが、このテーマに至るまでの経緯の説明と、「 あなたはそこで何がしたいですか?」「 もう2度とRubyKaigiがないとしたら」「 なんでもできるはず」などの言葉が投げかけられることで、参加者の皆さん一人一人がこのイベントについて思いを馳せているように感じました。
RejectKaigi2010
RubyKaigi終了後、スタッフの撤収作業の合間を縫って、今年もRejectKaigiが開催されました。
RejectKaigi2010では冒頭に「Timer Conference 0」と称してRejectKaigi2010では発表の時間が「2分30秒」であることが説明されました。また、ドラ娘ならぬブブゼラ娘が時間終了の際にブブゼラを吹き会場の笑いを誘っていました。
匿名希望さん 「 The End of Enterprise Ruby」
RejectKaigi2010の一番最初の発表は匿名希望さんによる、紙袋を被って顔を隠した状態での発表でした。冒頭で「この作品はフィクション」と話し、ある企業の売上が2,900億円(うち、開発は660億)でそのうちRubyの案件の数が「3」であると説明されました。理由としては「不況」であると話し、投資抑制による「リスク回避」や「Javaプログラマが余る」と話しているところで時間切れとなりました。
@m_kawatoさん 「 Rubyによる実用Androitスクリプティング」
Android端末での開発はコードを書いてから実行するまでのタイムラグが大きいと話し、開発サイクルを早めるためにRubyを用いるという発表でした。Androidマーケットには「Ruboto IRB」というアプリケーションがあり、そこでRubyスクリプトを動かすという話が紹介されました。
@technohippyさん 「 RubyでGoogle Waveのボットを作る方法」
Google Waveには様々なAPIがあり、その中の1つ「Robot API」の紹介でした。もともとRobot APIはJavaとPythonでしか扱えなかったそうですが、Rubyでも扱えるライブラリを作ったとのことです。github上で公開されているそうですが「URL忘れた。いいですよね?」との発言で会場は笑いで大盛り上りでした。
@nari3さん 「 シャイなRubyistにできること(RubyKaigi編)」
「おれがGCだ」と話したらchadにdisられたと話す、@nari3さんの発表でした。「 Rubyistのほとんどはシャイ」であると話し、「 シャイは個性」と説明し、そんなシャイボーイ達が来年のRubyKaigiでは何ができるかというお話でした。
すとうさん 「 racknga るりまサーチの副産物」
昼間の本編でも発表されたすとうさんの発表です。「 昼間の発表の続き」と話し、「 るりまサーチの中から他でも使えるように抜き出したのがracknga」との説明がありました。rackngaはRuby1.9とRackで動く全文検索用のユーティリティ集であると言及し、最後に「と言うことでClear Codeでした」と締め括っていました。
@koyhogeさん 「 2010年度 日本OSS貢献者賞応募のお願い」
@koyhogeさんによる日本OSS貢献者賞応募のお話でした。IPAが行っているアワードで今年6回目になるそうで、昨年から奨励賞というのもできたそうです。奨励賞は団体でも応募可能とし、「 ぜひ応募をお願いします」とのことでした。
大林さん 「 RRSE 2010」
RRSEとはEmacsのミニバッファにメソッドの情報を表示するライブラリとのことで、2006年ごろにRubyKaigiのLTでも話されたそうです。開発自体は「1年に1度ぐらいは触ってる」と話し、新しいバージョンをリリースしたとのお知らせがありました。
@fumi1さん 「 RDF.rb」
「セマンティックWebプログラミング」の監訳を行った@fumi1さんによる発表でした。RDFは11年前に仕様が決まったそうですが、Rubyでは今までまともなライブラリがなかったそうです。しかし、今年になって「RDF.rb」というものがリリースされ、Pure Rubyで今話題のMongoDBも使えるとの説明がありました。
永井@知能.九州大さん 「 マイナーな組込クラス探訪 ThreadGroupクラスって知ってる?」
永井さんはマイナーな組込みクラスを作ったり作ってもらってると話し、そのうちの一つが「ThreadGroup」だそうです。いくつかの事例を示しながら「そんなときはThreadGropu」と説明されていました。
@nankiさん 「 プログラミング言語Purl」
@nankiさんによる「プログラミング言語Purl」の紹介でした。PurlはなんとURL上で動く言語らしく、数値や文字列が扱えるそうです。add、dup、push、popなどスタックに似たようなメソッドを持つそうです。また、画像の変換も行うことができるとのことでした。Purlはgithub に公開しているとのことです。
ささださん 「 電光石火Ruby仮想機械へ向けて」
本編でも発表されたささださんですが、「 本編の英語が不評なので日本語で話します」と話し会場が笑いに包まれました。本編の発表の補足に近い内容でパフォーマンスや並列導入などが紹介されました。
@Johnwoodellさん and @urekotさん 「 怪しげなMirah and Dubias」
あやしげな二人組と話す@Johnwoodellさんと@urekotさんによる発表でした。@Johnwoodellさんの英語を@urekotさんが逐次訳しながらの発表でしたが、どことなくテンポの良い発表でした。MirahはRubyっぽく書けるJVM上で動く言語で、型推論も実装されているそうです。最終的にバイトコードになるのでJRubyより速いとのことでした。DubiasはMirahのフレームワークで「怪しげ」という意味だそうです。実際にいくつかコード例を表示し、Railsっぽく書けることを強調していました。最後に「怪しくないです」と話し会場の笑いを誘いました。
@vestigeさん 「 東京ボルダリング部について」
これだけは覚えて帰って欲しいと「#TKBB」と言うTwitterのハッシュタグの紹介からはじまりました。主にボルタリングとそれを行う集り、東京ボルダリング部の紹介でした。「 作戦」「 俯瞰」「 継続」「 シンクロ率」といったキーワードをあげ、「 ボルダリングはプログラマーに合ってる」と説明がありました。
ayuminさん 「個人スポンサーの皆さまへのお礼!」
RubyKaigi2010スタッフのayuminさんからの発表です。RubyKaigi2010は今年から「個人スポンサー」という枠組みを用意したとの説明がありました。結果、今年の総予算のうち23%が個人スポンサーだったと説明があり、個人スポンサーに向けて感謝の言葉を述べていました。
@tsuyoshikawaさん 「OOPJog in つくば レポート」
Chad Fowlerをだました男と自己紹介した@tsuyoshikawaさんの発表でした。OOPJogの活動として、RubyKaigi2010の最終日に朝の7時半からChad Fowlerさんなどとジョギングを行ったと説明がありました。ジョギングしながらChad Fowlerさんとの会話で「情熱が0になったらどうする?」と言った話になり「他人に情熱を伝える。その人が情熱を持てば自分にまた返ってきて無限ループになる」と言ったら、Chad Folwerさんから褒められたと話されていました。
@manveruさん 「Vim Emacs in Ruby」
残念ながらモニタとプロジェクタの接続でトラブルが発生し、急遽口頭のみでの発表となりました。RubyKaigi2009でも発表された自作のエディタの話で資料も通訳もいない中で「manveru」とホワイトボードに名前を書く場面がありました。
@bash0C7さん 「RubyDSL for All Business Scene」
@bash0c7さんによるビジネスドキュメントに特化したRuby DSLの話です。PowerPointのAPIを用いてRubyのコードでPowerPointの資料を作れると説明し、たくさんの細々とした作業もRubyならメソッドにまとめてそれを実行するだけと話されてました。
@yaa0121さん 「LOCAL学生部 in RejectKaigi2010 - 僕達の見たつくば -」
最後の発表は@yaa0121さんによる発表です。@yaa0121さんは株式会社えにしテックの学生招待で北海道から来られたそうです。宣伝としてLOCAL学生部は勉強会を交流の場にと言うことで、温泉での開発合宿の写真を見せられました。RubyKaigi2010では前日準備を手伝ったことにふれ、来年はスタッフとして参加したいと話し、「 結果は来年のRubyKaigi2011で!」と発表を終わりにしました。
RejectKaigi終了後
フィードバック用のホワイトボードが設けられました。多数のフィードバックがされていました。
会場を後にする参加者の方へ、手を振って見送るスタッフの皆さん。
最後に、スタッフによる、ふりかえりが行われました。
セッション以外の模様
ジュンク堂書店RubyKaigi店
RubyKaigi店書店員さんたちです。聞いたところ、『 メタプログラミングRuby』は初日入荷分が完売して、再度入荷した分も完売したとのことです。
サイン会(2)
本日もジュンク堂書店RubyKaigi店ではサイン会が行われました。
大場光一郎さん、大場寧子さん、田中祐樹さんによる『JRuby on Rails実践開発ガイド』 、橋本吉治さんによる『JRuby on Railsシステム構築入門』 、あんどうやすしさんによる『Google Wave入門』のサイン会がそれぞれ行われました。
『Google Wave入門』はサイン会の効果もあり、なんと会場持ち込み25冊が完売しました!!
また、松田明さんによる『Head First Rails』 、中村成洋さんによる『ガベージコレクションのアルゴリズムと実装』のサイン回もそれぞれ行われました。
「コンピュータ書がすごい!! in つくば」 急遽、ジュンク堂書店RubyKaigi店では実行委員長の高橋さんによる、特別トークセッション「コンピュータ書がすごい!! in つくば」が行われました(セッション休憩中に2回も!) 。RubyKaigi店にあるRuby関連書籍を多数紹介しました。
ノベルティ
今回のノベルティです。
このほかイベント開催期間中には、企画部屋を利用した多数のセッションや会議、昼食会などが開かれましたが、レポートができませんでした。メインのセッションよりも盛況だったものも、いくつもあったようです。
レポートは以上になります。最後までお読みいただきまして、ありがとうございました。