


前回は、CPUコントローラでの帯域幅制限がどのように行われるのかについて簡単に説明しました。
前回の最後に、説明のために挙げた例がかなり理想的な状況であると書きました。今回は、帯域幅制限の機能を詳しく見ていくために、前回よりはもう少し複雑な状況について説明していきましょう。
未使用クォータの返却
前回説明で示した例では、CPUは割り当てられたスライスをすべて使いきっていました。しかし、複数のCPUがある環境で、タスクが終了したり、I/
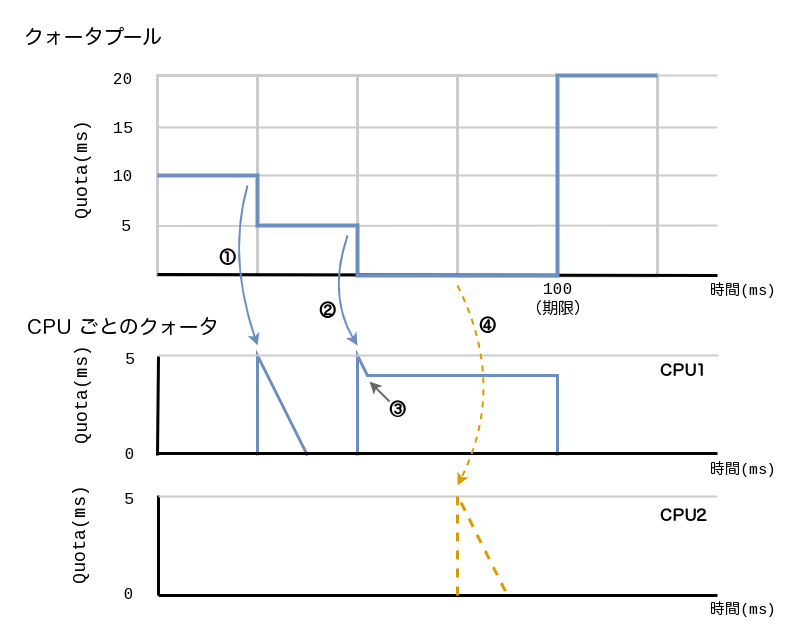
図1のように、クォータプールに10msクォータが残っているとします。
- ①でCPU1でCPUを使用するタスクから要求がありスライスが転送され、クォータの残りが5msとなりました
- ②で再度CPU1でCPUを使用するタスクから要求がありスライスが転送され、クォータの残りがなくなりました
- ③でCPU1のタスクは1msクォータを消費した時点で終了しました
- ④でCPU2でCPUを使用するタスクから要求がありましたが、クォータプールにはもうクォータが残っていません
もし、図1のように一度割り当てられたスライスがCPUに残ったままであれば、cgroup全体としてはクォータを使い切っていないにもかかわらず、他のCPUから要求があった場合でも、その期間内ではタスクが実行できないことになります。
これでは、割り当てられたクォータを使い切れず、CPUが有効に使われません。CPUが空いているにもかかわらず、タスクが無駄に制限にかかり、システムで動作するタスクのパフォーマンスが悪化することになるでしょう。
そこで、上で述べたようなことが起こらないように、一定期間使われないクォータが残っている場合、そのクォータをクォータプールに返却します。
その様子を図2を使って説明していきましょう。
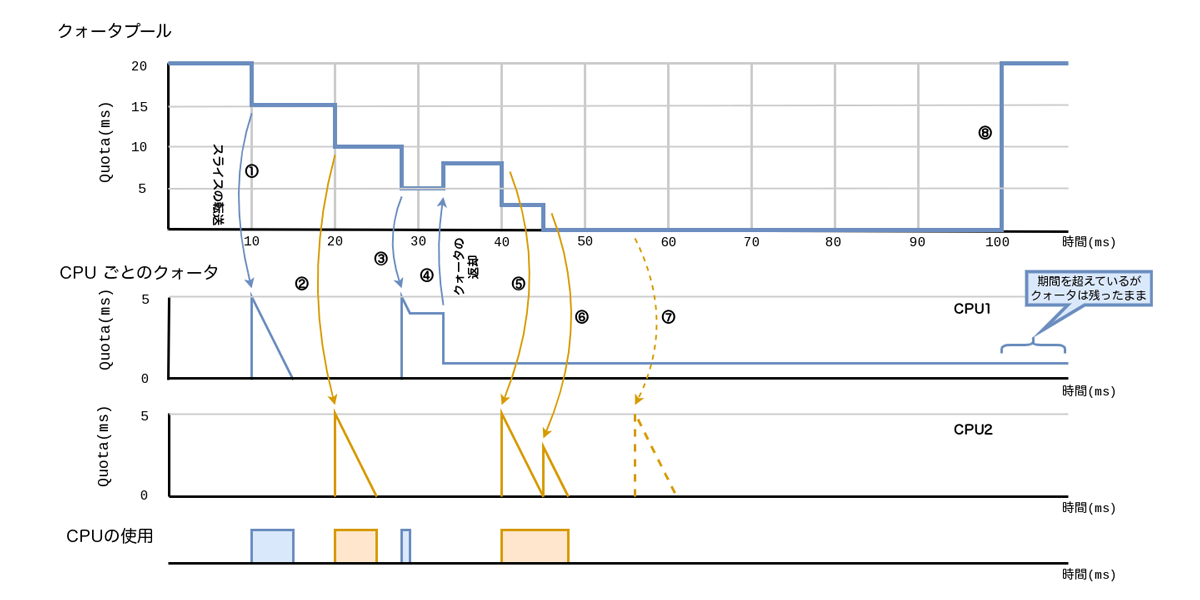
これまでの例と同様に、cgroupに対しては20ミリ秒の制限値が設定されており、2つのCPUが存在しています。
- ①でCPU1でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ②でCPU2でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ③でCPU1でCPUを使用するタスクから要求がありスライスが転送され、タスクは1ミリ秒間実行されました。この時点でCPU1にはクォータは4ミリ秒分残っています
- CPU1は一定期間残っているクォータを使わなかったため、④で残っているクォータをクォータプールに返却します。このとき、返却するクォータは残っているクォータから1ミリ秒をのぞいた分、つまり3ミリ秒です
- ⑤でCPU2でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ⑥でCPU2でCPUを使用するタスクからさらに要求があり、クォータプールに残っている3ミリ秒がCPU2に転送され、タスクは3ミリ秒実行され、転送されたスライスを使いました
- ⑦でCPU2でCPUを使用するタスクから要求がありました。しかし、クォータプールにはもうスライスが残っていませんので、この期間ではタスクは実行できません
③のように、タスクがCPUに残っているクォータを全部使わないまま、実行可能なタスクがない状態が一定期間続いた場合は、クォータプールにクォータを返却します。クォータを返却することにより、図1で示したように、cgroup全体では制限に達していないにも関わらず、タスクが実行できずに、割り当てられたクォータを無駄に捨ててしまうことが防げます。
ここで、1ミリ秒だけ残すのは、グローバルロックでの競合を防ぐためとのことです[1]。
そして、この1ミリ秒残ったクォータについては、cpu.で指定された期間を過ぎても有効なままです。つまり次の期間で使えます。
もし、期間が来たからといって、残っている1ミリ秒を捨ててしまうと、大量にCPUを搭載したホスト上でマルチスレッド化されたプロセスを動かす場合に、パフォーマンスが悪化するためです。たとえ1ミリ秒といえども、各CPUごとにクォータが残ったまま大量に放棄されるので、やはり与えられたクォータを十分に活かせないまま無駄に捨てることになります。
Memo:前回と今回の記事で参考にしているIndeedエンジニアリング・
機能が元々意図していた仕様は、CPUに残った1ミリ秒は期間内だけで有効でした。ですので、期間が終わると捨てられる実装がされているはずでした。しかし、実際にはバグで1ミリ秒が捨てられておらず、現在と同じように期間を超えて1ミリ秒はCPUに割り当てられたままになっていました。そのバグを修正し、1ミリ秒をきちんと捨てるように修正したとたんに、大規模環境でCPUが有効利用されずに、期待に反する制限がかかってしまう問題が出たようです。
1ミリ秒がきちんと捨てられないバグを修正したコミット
この1ミリ秒を返さない代わりに、1ミリ秒分のクォータについては次の期間で使えるようにすることで、前の期間に他のCPUで使えなくて無駄にした分を穴埋めするという感じでしょうか。そもそもこの1ミリ秒は、もともとcgroupとCPUに割り当たったクォータであり、余計に割り当てているわけではありません。CPUをまたいでは使えませんが、マルチスレッドのプロセスであれば、次の期間にそのCPU上でタスクが実行される可能性は高いでしょうから、トータルで見るとパフォーマンスが劣化しなくなるようです。
この無効にならずに、次の期間でも使用できるクォータに対して、バースト
ここまでで説明した1ミリ秒は、sysctlなどでは変更できません。カーネルのコード上でmin_という変数で定義されています。
/* a cfs_rq won't donate quota below this amount */
static const u64 min_cfs_rq_runtime = 1 * NSEC_PER_MSEC;
この1ミリ秒をのぞいた分を返却する処理は常に行われるわけではありません。次の場合は返却されません[3]。
- 返却分をクォータプールに返しても、クォータプールの残りがスライス
(sysctlパラメーターの sched_)cfs_ bandwidth_ slice_ us より小さい場合。返却後のクォータプールにスライスより小さいクォータしか残っていない場合、スライスが割り当てできないためだと思われます - 期間が終了する間際は返却されません。返却しても使う時間が残っていないためと思われます
以上で説明したように、CPUに割り当てられたあとに使わなかったクォータは、クォータプールに返却することで、無駄に使われないクォータが発生することを防げるようになっています。また、返却されない1ミリ秒のクォータについては、次の期間以降に使えるため、CPUを有効に使えます。この返却されないクォータは、割り当てられたCPUでのみ使えます。他のCPUに転送することはできません。
突発的にCPUを使用するタスクへのCPU時間の割り当て
ここからは少し話題を変えて、CPUを使用する期間と使用しない期間がはっきりと分かれるタスクに対する制限値の設定を考えましょう。
常にある程度一定のCPU時間を使用するタスクの場合、図3のように、タスクに合った期間と制限値を設定することで、性能の悪化を防げます。ここで、赤は制限値を、緑は実際にタスクが実行されている時間を示しています。赤の範囲内に緑が収まるように設定しています。

このように、多少の使用時間に差はあるものの、常時一定で負荷がかかっているタスクの場合は、タスクの実行を邪魔しない程度の制限値に調整できます。長い目
ところが図4のような、普段はほとんどCPUを使用しないけれども、CPUの使用が突発的に増えるタスクがあった場合はどうでしょうか? 例えば何らかの入出力を待つことが多いタスクです。
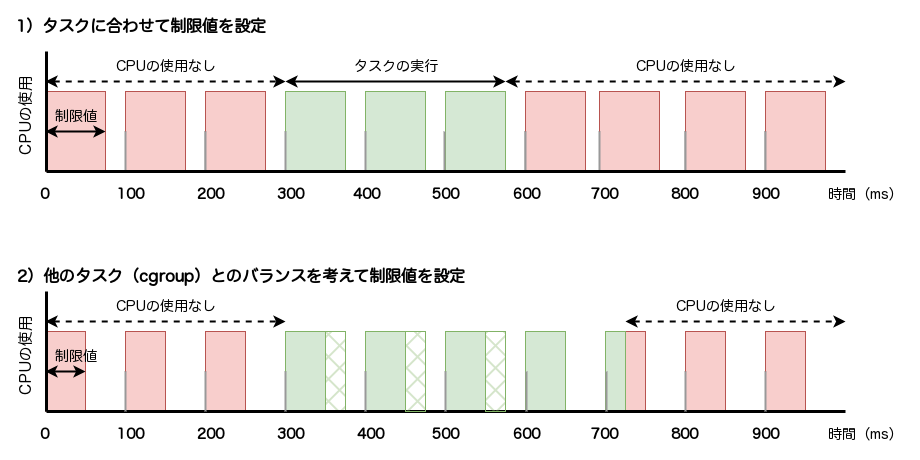
このようなタスクの実行を邪魔しないように図4の1)
では、図4の2)
このような場合、他のタスクはバランスよくCPUが割り当たるため問題がないかもしれませんが、このタスクはレイテンシが悪化します。もし、レイテンシがタスクにとって重要な場合は問題です。
制限値だけでなく期間も長くして、割り当たるCPU時間の割合を増やすことは考えられます。しかし、期間を伸ばすと、制限にかかった場合に次の期間を待つことになります。そうなるとより長く待つことになり、やはりレイテンシは悪くなる可能性があり、問題の解決にはなりません。
しかも、普段は全くCPUを使っていないにも関わらず、CPUを使い始めたときだけ制限がかかってしまうのは、長い時間で見たときに公平にCPUを割り当てているとは言えません。
バースト機能
先に説明したとおり、CPUに割り当たったクォータは、使われない場合クォータプールに返却されます。そして、返却する際にCPUに割り当たったクォータのうち、1ミリ秒だけはCPUに残り、使用せずに残った1ミリ秒のクォータは期間を超えて残りました。このバースト機能により、cgroupに割り当たったクォータが有効利用され、タスクのパフォーマンス悪化を防ぐ一定の効果が出ました。
ただ、この機能はCPUを超えてバーストされることはありません。そして上限は1ミリ秒です。この動きに合ったワークロードの場合は効果があるでしょうし、効果がないワークロードもあるでしょう。
図4の2)
そこで、図4の2)
先に説明した1ミリ秒のバーストとは違い、CPUに割り当てる前のクォータプールで貯めておけるため、特定のCPUにひもづくことはなく、単純に前の期間に使わなかったクォータを、次の期間にcgroup内で自由に使えます。
制限なくバーストできると、システム全体で見たときにバーストしたタスクがCPUを使いすぎる可能性があるため、このバーストできる時間には制限があります。バーストできる時間はcpu.で設定した制限値より小さい時間を設定します。
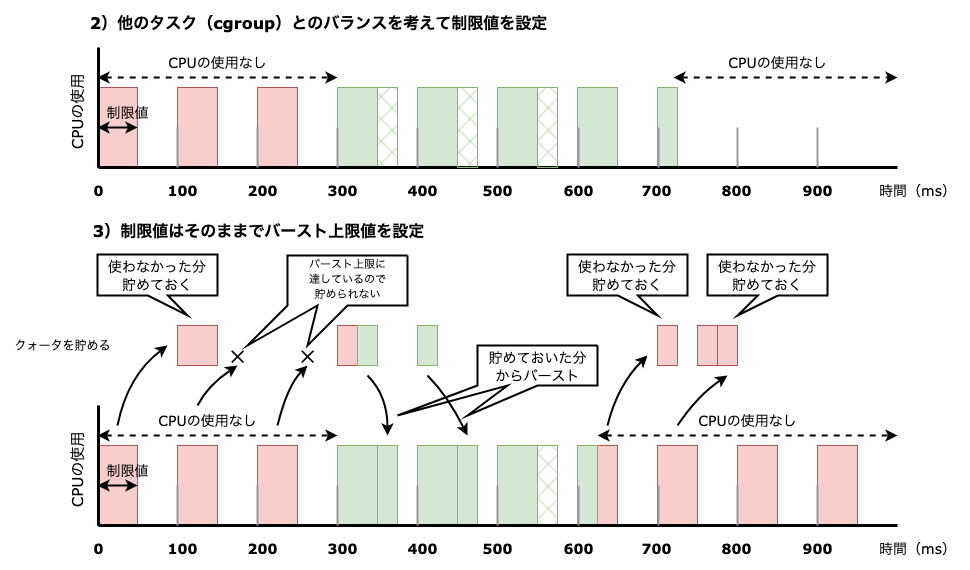
図5の3)
| パラメータ名 | 機能 | 操作 |
|---|---|---|
cpu. |
バーストできる0で、バースト機能を使わない場合と同じ動き。cpu.で設定した制限値より大きな値は設定できない。単位はマイクロ秒 |
読み書き |
このバースト機能はcgroup v1でも利用できます。cgroup v1の場合はcpu.ファイルを使用します。
設定の様子を見てみましょう。
$ sudo mkdir /sys/fs/cgroup/test01 (cgroupの作成) $ echo "50000 100000" | sudo tee /sys/fs/cgroup/test01/cpu.max (制限値として50000を、期間として100000を設定) 50000 100000 $ echo "50000" | sudo tee /sys/fs/cgroup/test01/cpu.max.burst 50000 (バースト上限として50000を設定) $ cat /sys/fs/cgroup/test01/cpu.max.burst 50000 (設定されている) $ echo "60000" | sudo tee /sys/fs/cgroup/test01/cpu.max.burst 60000 tee: /sys/fs/cgroup/test01/cpu.max.burst: Invalid argument (制限値より大きな値を設定しようとするとエラーになる)
上の例では、期間として100ミリ秒、制限値として50ミリ秒を設定し、最初バーストの上限値として50ミリ秒を設定しました。その後、制限値より大きな値である60ミリ秒を設定しようとしたところ、エラーになりました。
もちろん、CPU資源は有限ですので、CPUの使用率が高いシステムでバースト機能を使うと、システム全体でCPU資源が不足する可能性はあります。しかし、CPUに余裕があり、システム上にcgroupが多数存在する場合は問題が起こる可能性は限定的であることが示されているようです[4]。
まとめ
今回は、CPUコントローラの帯域幅制限で、CPUを有効に使用するための仕組みを紹介しました。
ひとつは、CPUに割り当てたものの、使われなかったクォータを返却する仕組みです。その際に、返却されないクォータがあり、そこでもCPUを有効に利用するための実装がされていることを紹介しました。
もうひとつは、突発的にCPUを使用するタスクに対応するためのバースト機能について紹介しました。使わなかったクォータを貯めておいて、制限にかかったときに使用する仕組みでした。
今回で、いったんCPUコントローラの話題は終わりです。
お知らせ:技術書典
筆者は2022年から、この連載をもとにした、Linuxコンテナで使われるカーネル技術を紹介する同人本を作り、技術書を対象にした同人誌即売会である技術書典に出展しています。
2023年11月11日
11月12日