あけましておめでとうございます。以前このgihyo.jpで「OpenCVで学ぶ画像認識」というタイトルで連載をさせていただいた皆川です。
今回、技術評論社様から「コンピュータ・ビジョンの今」についての執筆依頼をいただきました。私が普段ウォッチしている業界や技術分野には偏りがあるため、俯瞰的な形での解説は難しいかもしれませんが、私の独断と偏見で最近の動向についてまとめてみたいと思います。
ここでは、主に以下の3点について述べさせていただければと思います。
- ビジネスでの動向
- アカデミックでの動向
- コミュニティでの動向
「コンピュータ・ビジョンってなに?」という方は、「OpenCVで学ぶ画像認識」の第1回をお読みください。
ビジネスでの動向
拡張現実感(AR)
昨年、IT業界で間違いなく一つの流行語となったのは“拡張現実感(AR: Augmented Reality)”でしょう。ARは現実の環境に仮想世界(例えばインターネットや遠隔地など)の情報を付加することで、現実世界を拡張するという広い意味を持つ概念ですが、コンピュータ・ビジョンの分野でARというとカメラで撮影した対象を認識し、その上に3D画像等を重畳表示する技術のことを言います。
ARについて詳しく解説しだすと長くなるのでそれは他の記事に譲るとして、簡単な具体例を並べます。まず最初にIT業界にARの存在を大きく知らしめたのは、間違いなく2008年に発売された芸者東京エンターテイメントのARisでしょう。以下の動画を見て頂ければ、そのインパクトは一発でお分かりいただけるかと思います。
電脳フィギュア ARis
また、最近は広告キャンペーンなどにおいて、ARを多く見るようになりました。例えば、BMWが自車のプロモーションに使用したり、大阪道頓堀のARを使ったプリクラ「未来SNAP」、住友商事がAR連動型新聞広告を発表したり、また今年EPSONはARを使った3D年賀状を発表しました。
ゲームの分野では、ARisよりも前に「THE EYE OF JUDGMENT」というゲームがPS3向けに発売されています。また、欧米のみのようですが昨年PSP向けに「Invizimals」というゲームも発表されした。
なお、昨年大きく話題になったセカイカメラは無線LANを用いた位置計測(クウジットのプレースエンジン)を用いており、画像認識は使っていません。
他にも昨年話題になったARには枚挙に暇がありませんが、マーカーを使用したARに顔認識やモーションキャプチャを組み合わせるような例もいくつか見受けられました(例えば、PS3ゲームのEyePet、映画「トランスフォーマー2」のキャンペーン、AR試着サービスなど)。
このようなAR流行の背景には、iPhoneやAndroidなどのスマートフォンの普及があるのではないかと思います。かつてカメラ付き携帯電話が普及したことにより、顔認識や特定物体認識(後述)といった技術を実生活で見かけるようになりましたが、同様にスマートフォンが普及したことで、カメラから撮影された画像への重畳表示が開発しやすくなったことが一つの要因と考えられます。
大手IT企業の動向
もう一つ、私が大きな流れになってきたと感じているのが、これまでコンピュータ・ビジョンのR&Dに多大な投資を行ってきたIT系の大企業が、いよいよ本気で商品を世に出し始めたのではないかという点です。
この分野の研究に多大な投資をしているIT企業というと例えば、Microsoft、Adobe、Googleが挙げられます。特に前の2社は、CVPRやICCV、SIGGRAPHといった世界トップクラスの国際会議に、毎回多くの研究を通しています。この3社が昨年、次々と驚くべき製品/サービスを発表しました。
Microsoft
まずMicrosoftですが、昨年のE3でXBOX360向けに"Project Natal"を発表しました。これは以下の動画を見ていただければ分かる通り、体の動き(モーションキャプチャ)や顔認識、音声認識などを併用したゲームコントローラです。
Project Natal
またMicrosoftは、Google Mapへの対抗として"Bing Maps"のベータ版を公開しましたが、その中でMicrosoftが2006年のSIGGRAPHで発表し、2008年に一般公開したPhotosynthとの連携が行われています。Photosynthはあるランドマーク(例えば自由の女神など)の写真が、どのカメラ位置から取られたのかを判定し、それらの画像をつなぎあわてブラウズできる技術です。
Bing Map + Photosynth
確かにPhotosynthの地図との連携は非常に親和性が高いと思いますし、何よりここまでの視覚的インパクトは今のGoogle Mapでも実現できていません。Microsoft Researchの面目躍如といったところでしょうか。
Adobe
AdobeはPhotoshop CS5において、SIGGRAPH 2009で発表されたPatchMatchという技術を実装する予定だそうです。PatchMatchがどういう技術かは、以下の動画を見ていただくのが早いと思います。
PatchMatch
学会で発表されてから、これほどすぐに製品に反映される予定とは思いませんでした。それだけ実用に耐えうる、自信のある技術ということなのでしょう。
Google
Googleは昨年、多くのビジョンに関する話題を提供しました。簡単にまとめると以下の通りです。
- Picasaデスクトップ版への顔認識機能実装
- CVPR 2009でランドマーク検索技術を発表
- 類似画像検索機能がラボから卒業
- Google Gogglesの発表
中でも注目はGoogle Gogglesでしょう。これはAndroid向けのアプリケーションで、携帯電話のカメラから撮影した画像を検索に使うサービスです。
Google Goggles
ここで使用されている技術は、文字認識(OCR)、特定物体認識、そしてGPS及び電子コンパスの位置計測です。また今回は実装しませんでしたが、将来的には顔認識を入れる予定とのことです。
特定物体認識とは、クエリーとなる画像から「特徴点」と呼ばれる、画像上のエッジや端点のような際立った特徴を持つ点とその点周辺の情報を取得し、その特徴点とどれだけマッチングするかを元にDB内の画像のどれが近いのかを特定する技術です。
特定物体認識
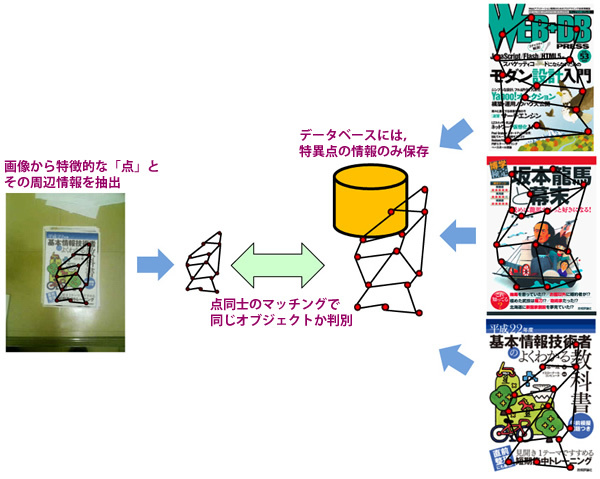
このような携帯カメラによる特定物体認識を用いた検索自体は、特に真新しいものではありません。日本でもオリンパスやゼータブリッジ、Everyxの技術が広告キャンペーンなどに利用されてきました(最近であれば、サントリーのFF13エリクサーのキャンペーンなど)。
ただ、これを巨人Googleが本気で取り組んでいるということが、画像による検索を生業としている各企業にとっては大きな脅威であると言えます。Googleの強みは優秀な技術者をたくさん抱えているということもありますが、それだけでなくインターネット上の大量のデータにアクセスし、かつ膨大な計算のためのリソースを利用できるという点があげられます。これにより検索技術自体を向上させたり、検索結果に豊富な情報を提供することができます。
今回、Gogglesは重畳表示こそしていませんが、ARを提供しようとしている各企業もうかうかしていられないのではないでしょうか。
余談ですが上のGoogle Gogglesのビデオに登場しているHartmutという人物は、数年前にGoogleが買収したNeven Visionの創設者(かつ私の元雇い主)です。そのため、Google Gogglesの特定物体認識技術にはNeven Visionのものが使われていると推察されます。またGogglesの中のランドマーク検索にはCVPR 2009で発表したランドマーク画像検索が利用されているのではないかとも予想できます。
大企業でありながら、買収した企業の技術をしっかりと活かして、自分たちのサービスとして組み上げたことは、さすがとしか言いようがありません。
これからもこれらの企業から目が離せません。
アカデミック及びコミュニティの動向
ビジネスでの話が長くなってしまいましたが、以降は簡単にアカデミックの領域と開発者コミュニティの話に触れたいと思います。
注目の研究分野
研究の分野でここ数年盛り上がっているテーマの一つに「一般物体認識」と呼ばれる技術があります。これは、例えば「車」「顔」「犬」といった、画像に写っているオブジェクトのカテゴリを判別するための技術を指します。先程説明した「特定物体認識」が事前に登録した画像の中からマッチするものを検索するのに対し、一般物体認識では例えば「カローラ」であっても「プリウス」であっても全て「車」として認識します。技術的により詳細な全体像を知りたい方は、電気通信大学の柳井先生が書かれた論文[1]を読んでいただくと良いかと思います。
国際学会等で見られるここ最近の動きとしては、単にカテゴリを判別するだけでなく、その位置を効率的に探索する方法[2][3]や、判別性能を上げるために様々な特徴(異なる特徴量や色など)を組み合わせたり[4]、そのオブジェクトの持っている属性(例えば顔であれば、性別、年齢、肌の色など)[5][6][7]、オブジェクト周辺のコンテクスト[8]や物体の姿勢変化[9]にまで認識の枠組みを広げるような発表が見受けられるようになってきました。
日本においても昨年11月に、電気情報通信学会の「パターン認識・メディア理解研究会」及び情報処理学会の「コンピュータビジョンとイメージメディア研究会」合同で「一般物体認識・画像特徴量」という独立したテーマセッションが開かれるまでに至りました。
各企業も力を入れて研究しているようなので、今後数年のうちに市場に出てくる可能性が高いと思います。
私がもう一つ注目しているトレンドが、インターネット上の膨大な画像データを積極的に使うことによって、なんらかの新しい結果を出している研究群です。例えば画像の欠損をインターネット中の大量の画像からそれらしいパーツを集めて補間してしまう研究[10]、インターネット上の大量の画像から街全体を“1日で”3次元復元してしまうプロジェクト[11]などがあります(技術的にはPhotosynthの流れを組んでいます)。また、デジカメで撮影された画像にはカメラ情報が"exif"と呼ばれる形式で埋め込まれているのですが、ネット上の大量の画像からexifを取り出して統計的に分析することで、カメラごとの特性(応答特性やレンズ口径)や、その写真が素人が撮ったか玄人が撮ったかまで分析してしまうという研究も発表されました[12]。
GoogleがCVPRで発表したランドマーク検索は、ジオタグのついたインターネット中の大量の画像とwikitravelなどの旅行ガイドから、ランドマーク画像を自動収集するというものですが[13]、これもネット上の大量データを利用したものと言えます。
これらは、まさに今の時代だからこそ生まれた研究達で、これからこういった新しいアプローチが次々に生まれてくるのではないかと期待しています。
ネット上の大量データを用いた画像補間(画像出典:SIGGRAPH 2007[10])
 ネット上の画像から町並みを3D復元
ネット上の画像から町並みを3D復元
開発者コミュニティの成長
これまで、コンピュータ・ビジョンという分野はほとんど研究者だけの閉じられた世界でしたが、最近はコンピュータ・ビジョンを専門としないプログラマー達も加わった開発コミュニティが成長してきているようです。私も昨年「CV・ARに関する普通じゃない勉強会」というものに初めて参加して、その盛況ぶりに驚きました。
その背景としてあるのが、ARToolKitやOpenCVなどのオープンなライブラリによって、開発の敷居が大きく下がったことがあげられます。また工学ナビのようなエヴァンジェリストの存在や、ニコニコ動画のように、作った作品を公開する「場」が整ったことも大きな要因と言えるでしょう。コンピュータ・ビジョンは元々視覚的インパクトの強い研究分野なので、このような動画共有サイトは発表の場として最適ですし、視聴者の反応が見えるため開発者のモチベーションも上がり易いという利点があります。
OpenCVはまだまだ研究者のためのライブラリという側面が強いですが、それでも今後はより顔検出のような使い易い機能が増えていくでしょう(実際OpenCV 2.0から顔検出だけでなく、人物検出も加わりました)。そうなれば、これから益々コミュニティは盛り上がり、それがビジネスへも波及することでしょう。
またOpenCVの新しいバージョンを待たずとも、研究者がそれらのライブラリを使ったソフトを書いて使い方と一緒に公開すれば、このようなハッカー達の間に一気に広がる可能性があります。例えば、2007年に発表されたPTAMなどはソースコードが公開された途端に、ニコニコ動画へ「街中を歩く初音ミク」としてアップされました。
Parallel Tracking and Mapping (PTAM)
初音ミクが家の前を歩いてたんだけど…ニコニコ動画:https://www.nicovideo.jp/watch/sm4788237
今後、こういったコミュニティが盛り上がっていくことで、よりコンピュータ・ビジョンの技術が一般に浸透したり、思わぬ使われ方が提案されたりと言ったことが期待されます。
終わりに
というわけで、私見に基づいてコンピュータ・ビジョンの業界動向をまとめてみました。近年、明らかにこの分野の動きは加速しています。今年1年、一体どんな動きが起こるのか大変楽しみです。





