



はじめに
データベースを利用する目的の1つとして、
リレーショナルデータベースとSQLにおいては、
そうすると当然、
具体的には、
まあ、
まずは基本
直近を求める
まずは基本的な時系列分析から始めましょう。時系列にデータを比較する場合、
| sample_ | load |
|---|---|
| 2008-02-01 | 1024 |
| 2008-02-02 | 2366 |
| 2008-02-05 | 2366 |
| 2008-02-07 | 985 |
| 2008-02-08 | 780 |
| 2008-02-12 | 1000 |
まずは、
SELECT sample_date AS cur_date,
MIN(sample_date)
OVER (ORDER BY sample_date ASC
ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING) AS latest
FROM LoadSample;cur_date latest -------- -------- 08-02-01 08-02-02 08-02-01 08-02-05 08-02-02 08-02-07 08-02-05 08-02-08 08-02-07 08-02-12 08-02-08
2月1日より前のデータはこのテーブルには登録されていないので、
これを実装非依存のクエリにするには、
SELECT LS0.sample_date AS cur_date,
(SELECT MAX(sample_date)
FROM LoadSample LS1
WHERE LS1.sample_date < LS0.sample_date) AS latest
FROM LoadSample LS0;これも結果はリスト1と同じです。ポイントはWHERE句の
SELECT LS0.sample_date AS cur_date,
MAX(LS1.sample_date) AS latest
FROM LoadSample LS0
LEFT OUTER JOIN LoadSample LS1
ON LS1.sample_date < LS0.sample_date
GROUP BY LS0.sample_date;この自己結合の場合も、
SELECT LS0.sample_date AS cur_date,
LS1.sample_date AS latest
FROM LoadSample LS0
LEFT OUTER JOIN LoadSample LS1
ON LS1.sample_date < LS0.sample_date;cur_date latest
-------- --------
08-02-01 ← S0:2月1日より小さい日付は
1つもないので、0個
08-02-02 08-02-01 ← S1:2月2日より小さい日付は1個
08-02-05 08-02-01 ← S2:2月5日より小さい日付は2個
08-02-05 08-02-02
08-02-07 08-02-01 ← S3:2月7日より小さい日付は3個
08-02-07 08-02-02
08-02-07 08-02-05
08-02-08 08-02-01 ← S4:2月8日より小さい日付は4個
08-02-08 08-02-02
08-02-08 08-02-05
08-02-08 08-02-07
08-02-12 08-02-01 ← S5:2月12日より小さい日付は5個
08-02-12 08-02-02
08-02-12 08-02-05
08-02-12 08-02-07
08-02-12 08-02-08
このように、
S0~S5の部分集合は、
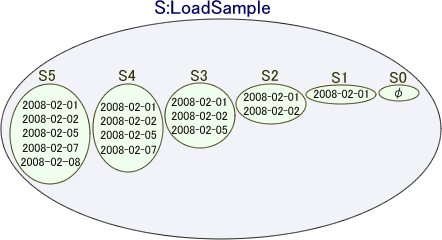
という包含関係のある部分集合群です
現在の日付の処理量と、
SELECT LS0.sample_date AS cur_date,
MAX(LS0.load_amt) AS cur_load_amt,
MAX(LS1.sample_date) AS latest,
(SELECT MAX(load_amt)
FROM LoadSample
WHERE sample_date = MAX(LS1.sample_date)) AS latest_load_amt
FROM LoadSample LS0
LEFT OUTER JOIN LoadSample LS1
ON LS1.sample_date < LS0.sample_date
GROUP BY LS0.sample_date;
cur_date cur_load_amt latest latest_load_amt ---------- --------- ---------- ----------- 2008-02-01 1024 2008-02-02 2366 2008-02-01 1024 2008-02-05 2366 2008-02-02 2366 2008-02-07 985 2008-02-05 2366 2008-02-08 780 2008-02-07 985 2008-02-12 1000 2008-02-08 780
ただし注意が必要なのは、
そこで代替案として、
SELECT LS0.sample_date AS cur_date,
LS0.load_amt AS cur_load,
LS1.sample_date AS latest,
LS1.load_amt AS latest_load
FROM LoadSample LS0
LEFT OUTER JOIN LoadSample LS1
ON LS1.sample_date = (SELECT MAX(sample_date)
FROM LoadSample
WHERE sample_date < LS0.sample_date);これも結果は先ほどと同じになります