サポートページ
お詫びと訂正(正誤表)
本書の以下の部分に誤りがありました。ここに訂正するとともに、ご迷惑をおかけしたことを深くお詫び申し上げます。
(2017年10月10日最終更新)
P.96 Tip「YARNコンテナ」内、上から2〜3行め
| 誤 | YARNにおけるコンテナはOSレベルの仮想化技術ではなく、どのホストでどのプロセスを走らせるかを決めるアプリケーションレベルの技術です。 |
|---|---|
| 正 | YARNにおけるコンテナは、Dockerコンテナのようにすべてのリソースを仮想化して隔離するものとは違って、CPUやメモリなどの使用量のみを制限します。 |
YARNコンテナもOSの仮想化技術を用いているとのこと。加えて、現在のYARNはDockerコンテナを使ってプログラムを実行できるようにもなっているようです。
P.119 Column「Mesosによるリソース管理」内、上から3〜4行め
| 誤 | YARNと比べるとより厳密なリソース制御を行います。 ... Linuxコンテナ(LXC)が用いられ |
|---|---|
| 正 | 分散アプリケーションを隔離するために厳密なリソース制御を行います。 ... Linuxのコンテナ技術が用いられ |
MesosやDockerはかつてLXCを利用していたものの、本書執筆時点で既に利用されなくなっているとのことで訂正。
P.150 見出し「重複排除は高コストなオペレーション」内、上から3行め
| 誤 | 分散システムではシーケンス番号はあまり使われません。 |
|---|---|
| 正 | メッセージ配送における重複排除ではシーケンス番号はあまり使われません。 |
ここでは重複排除におけるシーケンス番号の利用について論じています。本書では取り上げられませんでしたが、実際にはシーケンス番号が利用されるケースもあり、例えば2017年6月28日にリリースされたApache Kafka 0.11では、シーケンス番号を利用した重複排除が実装されたようです。
参考:
https://
(以下、2017年9月25日更新)
以下、第2刷以降、電子版では修正済み
P.81 下から4行め
| 誤 | 正規化によって分解さている |
|---|---|
| 正 | 正規化によって分解されている |
P.267 リスト6.14の続き 上から3行め〜4行め
| 誤 |
|
|---|---|
| 正 |
|
(以下、2017年9月19日更新)
P.29 ページ下方の、実行例の最終行
| 誤 |
|
|---|---|
| 正 |
|
P.80 図2.19
| 誤 | 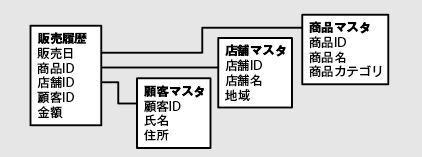 |
|---|---|
| 正 | 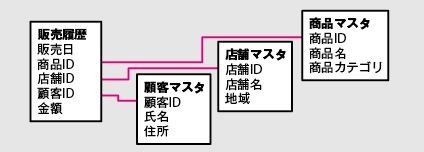 |
(以下、2017年9月12日更新)
(電子版では修正済み)
P.28 ページ下方の実行例内
| 誤 |
|
|---|---|
| 正 |
|