



目次
- はじめに
第1章 ゲームの中の人工知能──ゲームの中で生きているキャラクターを作る
1.1 ゲームAIの全体像
- キャラクターAI
- ナビゲーションAI
- メタAI
1.2 ゲームAIの連携
- フレームとは
- 3つの人工知能のフレームの違い
- ゲームAIのミッション
- ゲームデザインとAI
1.3 ゲーム世界に溶け込むAI
- 合理的である
- 人間的である
1.4 シミュレーション
- 物理シミュレーションと知能シミュレーション
- 知能をシミュレーションするには
- 知能そのものをシミュレーションする/知能が実現していることをシミュレーションする
1.5 シンボルと数値ダイナミクス
1.6 まとめ
第2章 知能のしくみ
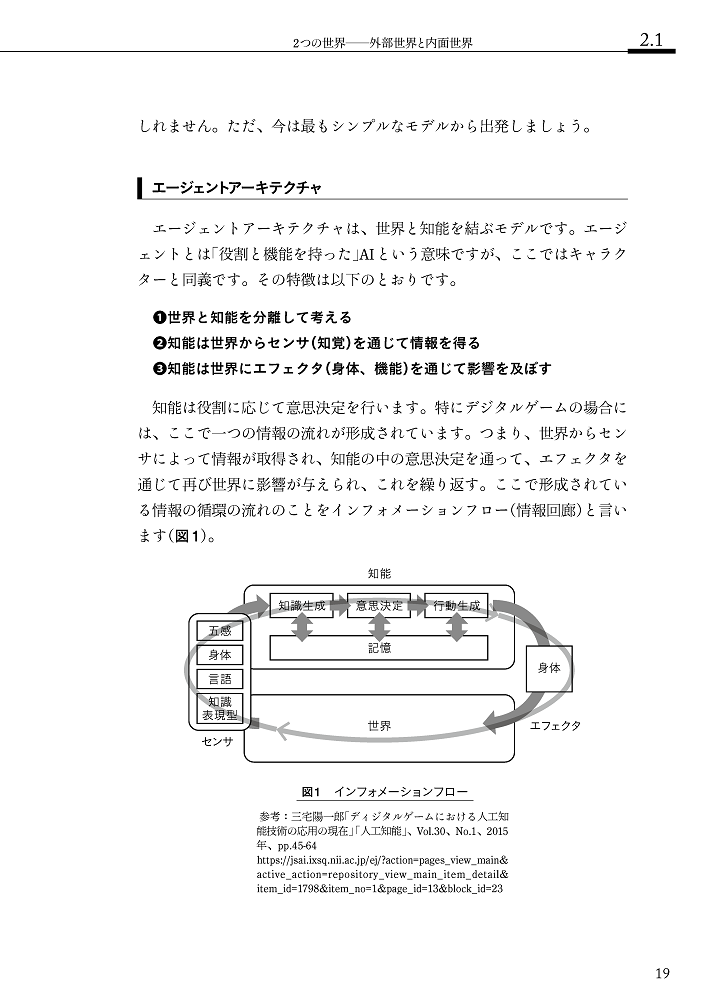
2.1 2つの世界──外部世界と内面世界
- エージェントアーキテクチャ
- 知能の3分類
- 知識生成(Knowledge Making)/意思決定(Decision Making)/行動生成(Action Making)
2.2 内部循環インフォメーションフロー
2.3 環境の中の知性
- センサ
- エフェクタ
- 知識生成
- 行動生成
- 意思決定
- 柔軟な知能の運動
- 記憶
2.4 アーキテクチャ全体について
2.5 C4アーキテクチャ
2.6 意識の理論
2.7 まとめ
第3章 知識表現──世界を噛み砕く
3.1 キャラクターの認識とは何か
- 人工知能における「表現」とは
- フレーム
3.2 センサの設計方法
- 視覚の実装
- 視覚システムの応用「存在確率マップ」
- 聴覚の実装
- 音の伝搬シミュレーション/プレイヤーが聞く音
- 身体の感覚
- 外力,内力/姿勢
- 感覚統合と事実表現
- 事実からの推測
3.3 位置検索システム
- 戦術位置解析技術
- 行動のための環境のヒントデータ
- 環境理解のための抽象的表現
- 事実表現
- 『Gunslinger』における事実表現
3.4 知識から感覚へ,感覚から知識へ
- 行為と認識
- メタ知識
3.5 環世界へ
- 環世界の例
- 環世界の構造
- キャラクターの持つ環世界
- アフォーダンス
- 人工知能の知識表現
3.6 エージェントアーキテクチャと環世界
3.7 まとめ
第4章 記憶──AIの内側の表現メモリ
4.1 記憶って何だろう?
- 身体の知識表現
- 精神の知識表現
4.2 記憶の構造とダイナミクス
- 固定記憶
- ワーキングメモリ
- 短期記憶
- 長期記憶
4.3 記憶の形
- 感覚記憶
- エピソード記憶
- 記憶の整理機能
- エージェントセントリック
4.4 記憶の論理階層構造
- 世界をアクティブに知る
- 統合/形成/消滅
- 記憶の管理
4.5 まとめ
第5章 古典的な意思決定
5.1 反射型と非反射型の意思決定アルゴリズム
5.2 ルールベースの意思決定
- ルールセレクタ
- ルールの連鎖
5.3 ステートベースの意思決定
- ステートマシンの基本
- 階層化ステートマシン
- 具体例
5.4 ユーティリティベースの意思決定
- 効用の計算方法
- ダイナミックなユーティリティ
- ムードとその変化(効用)の計算方法
- 限界効用逓減の法則
5.5 まとめ
第6章 現代風の意思決定
6.1 ゴールベースの意思決定
- ゴール指向型意思決定
- 2つのゴール指向プランニング/ゴール指向は未来の観念を持つこと/フォワードプランニングとバックワードプランニング
- ゴール指向型アクションプランニング
- ❶ゲーム状態のシンボル化/❷シンボルによるアクション表現/❸プランニング/複数のアクションプラン
- 階層型ゴール指向プランニング
- 階層型ゴール指向プランニングの考え方/階層型ゴール指向プランニングの設計指針/ゴールの列挙/ゴールの分解/小さいゴールを組み合わせて大きなゴールを達成する/ゴールを操作に還元する
6.2 タスクベースの意思決定
- 階層型タスクネットワーク
- 階層型タスクネットワークの例:回復薬を作る/階層型タスクネットワークの例:回復薬を届ける
- 階層型タスクネットワークの実例
- 衛生兵のAI/部隊長のAI
6.3 ビヘイビアベースの意思決定
- アクションゲームにおけるビヘイビアツリー
- RPGにおけるビヘイビアツリー
6.4 シミュレーションベースの意思決定
- レーシングゲームの例
- さまざまなゲームにおけるシミュレーションベースの考え方
- キャラクターの運動への応用
6.5 まとめ
第7章 ナビゲーションAIと地形認識
7.1 生物と環境の関係
- 空間と環境を認識すること
- 世界を表現する
7.2 知識表現
- 敵表現リスト
- 依存グラフ
- 意味ネットワーク
- 事実表現
- ルールベース表現
- 世界表現
7.3 さまざまな世界表現
- ウェイポイント,ナビゲーションメッシュ表現と経路検索
- ナビメッシュ-ウェイポイント階層表現/マップクラスタリング表現
- テリトリー表現
- 戦術ポイント表現
- LOSマップ表現
- 敵配位マップ
7.4 パス検索
- パス検索の黎明期
- パス検索の本格的な導入事例
- パス検索の広がり
- スマートテレイン
- 3次元のパス検索
- ルックアップテーブル法
7.5 意思決定と世界表現
- 地形の認識
- 地形の接続情報/最適な戦術位置/状況判断
- 戦術位置検索システム
- ゴールデンパス
- 影響マップ
7.6 まとめ
第8章 群衆AI
8.1 マルチエージェント
- コミュニケーション/メッセージング
- 階層型アーキテクチャ
- ファシリテーター型
- ブラックボード/ベルギアンAI/トークンによるタイミング制御
8.2 群衆の作り方
- 生物の群れ「ボイド」
- 整列/集合/離散/回避
- 場の力による群衆生成
- ソーシャルな関係を入れた群衆
8.3 街の群衆の作り方の実例
- 巡回するキャラクター
- 密度コントロール
- イベントと人だかり
- 交戦キャラクター
- 商店/働く人々/動物たち
- 応用:監視兵キャラクターの協調方法
8.4 まとめ
第9章 メタAI──ユーザーを楽しませるために
9.1 古典的メタAI
- 難易度調整
9.2 現代のメタAI
- 敵の動的配置
- プレイヤーの監視
- プレイヤーの感情推定
- メタAIとプロシージャル技術
- 地形生成/物語生成
- メタAIの内部構造
- ユーザー解析技術
- メタAIのほかの分野への応用
- スマートシティ構想/複数台のロボットの協調
- 現代的なメタAIのさらなる発展
9.3 まとめ
第10章 生態学的人工知能とキャラクターの身体性
10.1 エージェントアーキテクチャの発展
- 生物学における環世界
- 認知科学におけるアフォーダンス
- 環世界,知識表現,アフォーダンス
- 多層構造
- 知能の多層構造
- 主体と対象の階層化
10.2 キャラクターの身体システム
- 身体と知能をつなぐ
- 意識/無意識構造──身体からの認識
- 人工身体モジュールと人工知能モジュールをつなぐ
- 身体レイヤ
10.3 多層レイヤシステムの実例
10.4 キャラクターモーションシステムの発展
- 身体からのフィードバック
- ベルンシュタインの身体運動論
- 身体能力の認識
- 運動感覚の形成
- ニューラルネットワークによる身体運動
10.5 まとめ
第11章 学習,進化,プロシージャル技術
11.1 学習/進化アルゴリズムのゲームへの応用の歴史
- 1980〜1990年代中盤
- 1990年代後半
- 2000年代
- 2010年代
11.2 学習/進化アルゴリズムの事例
- 『Creatures』におけるニューラルネットワーク
- 1990年代の日本のゲームシーンにおける学習/進化アルゴリズム
- 『アストロノーカ』における遺伝的アルゴリズム/『シーマン』における自然言語会話
- マイクロソフトリサーチにおける機械学習の研究
- 『Forza Motorsport』シリーズにおける機械学習
- 『Killer Instinct』におけるケースベーストリーゾニング
- 『Total War』におけるモンテカルロ木探索
- 格闘ゲームにおけるニューラルネットワーク
11.3 プロシージャル技術
- プロシージャル技術の始まり
- ダンジョン自動生成
- 自然地形の自動生成
- 植物自動生成と植物自動配置
- 街自動生成
- ゲームエンジンにおける総合型ゲームレベル自動生成技術
11.4 まとめ──学習,進化,プロシージャル技術の展望
第12章 ゲーム開発の品質保証/デバッグにおける人工知能技術の応用
12.1 ゲーム開発環境/デバッグ/品質保証における人工知能技術
12.2 ゲーム開発工程(ゲーム開発者)を助けるAI
- パラメータ調整
- ゲーム自動バランス/自動調整
12.3 ゲームサービスを支援するAI
- データビジュアリゼーション
12.4 ゲーム品質保証のためのAI
- 人工知能による自動プレイ
- システムテスト
- ログデータの活用
- 強化学習
- 『Assassin's Creed Origins』における自動解析システム
- ディープラーニングのゲームへの応用
- ディープラーニングの躍進と課題/品質保証とディープラーニング
- ボットを用いた品質保証
12.5 まとめ
- あとがきと謝辞
- 索引