概要
本書は野村総合研究所のシステムコンサルティング事業本部で実施している「アナリティクス研修」をベースにした増補改訂版で,「統計的なモデリングとは何か?」「モデルに基づく要因の分析と予測の違いとは?」「具体的なモデルの作り方」「結果を解釈する際の落とし穴の見分け方」など,ビジネスの現場感を重視した構成です。実務で遭遇するデータ品質や加工のポイント,さらにRとPythonを利用し,データからモデルを作成して結果を得るという基本的な手順を体験できます。これからデータ分析や統計解析,機械学習を学び,現場でそれらを活用したい方に最短学習コースでお届けします。
こんな方におすすめ
- データ分析・統計解析や機械学習について知りたい方
- データサイエンティストになりたい方
目次
第1章 データサイエンス入門
- 1.1 データサイエンスの基本
- 1.1.1 データサイエンスの重要性
- 1.1.2 データサイエンスの定義とその歴史
- 1.1.3 データサイエンスにおけるモデリング
- 1.1.4 データサイエンスとその関連領域
- 1.2 データサイエンスの実践
- 1.2.1 データサイエンスのプロセスとタスク
- 1.2.2 データサイエンスの実践に必要なツール
- 1.2.3 データサイエンスの実践に必要なスキル
- 1.2.4 データサイエンスの限界と課題
- コラム ビジネス活用における留意点
第2章 RとPython
- 2.1 RとPython
- 2.2 R入門
- 2.2.1 Rの概要
- 2.2.2 Rの文法
- 2.2.3 データ構造と制御構造
- 2.3 Python入門
- 2.3.1 Pythonの概要
- 2.3.2 Pythonの文法
- 2.3.3 Pythonでのプログラミング
- 2.3.4 NumPyとpandas
- 2.4 RとPythonの実行例の比較
第3章 データ分析と基本的なモデリング
- 3.1 データの特徴を捉える
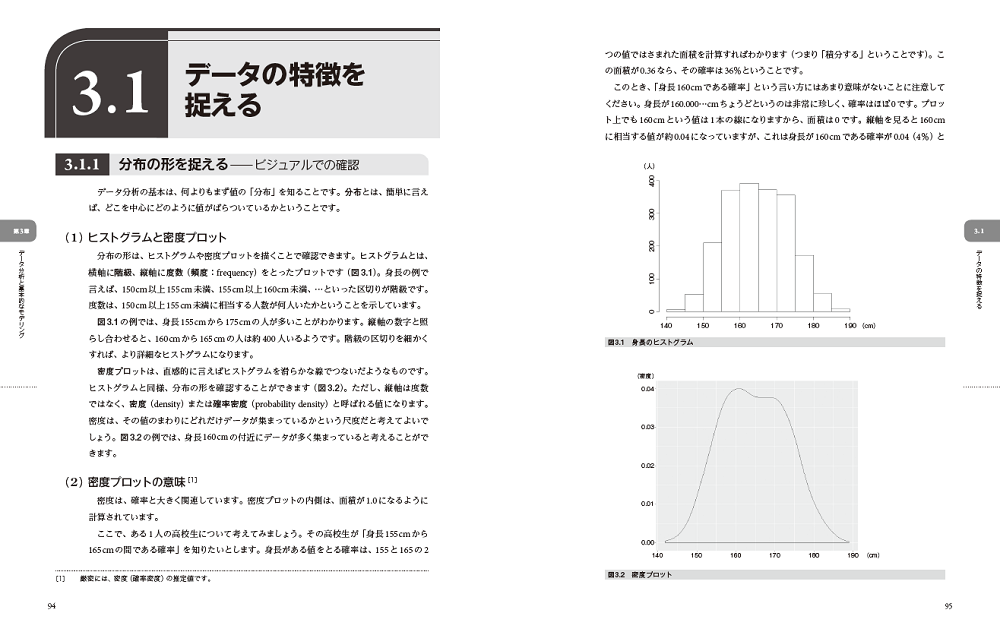
- 3.1.1 分布の形を捉える ─ ビジュアルでの確認
- 3.1.2 要約統計量を算出する ─ 代表値とばらつき
- 3.1.3 関連性を把握する ─ 相関係数の使い方と意味
- 3.1.4 Rを使った相関分析 ─ 自治体のデータを使った例
- 3.1.5 確立分布とその利用 ─ 理論と実際の考え方
- 3.2 データからモデルを作る
- 3.2.1 目的変数と説明変数 ─ 説明と予測の「向き」
- 3.2.2 簡単な線形回帰モデル ─ Rによる実行と結果
- 3.2.3 ダミー変数を使ったモデル ─ グループ間の差異を分析
- 3.2.4 複雑な線形回帰モデル ─ 交互作用,モデル間の比較
- 3.2.5 線形回帰の仕組みと最小二乗法
- 3.3 モデルを評価する
- 3.3.1 モデルを評価するための観点
- 3.3.2 この結果は偶然ではないのか? ─ 有意確率と有意差検定
- 3.3.3 モデルはデータに当てはまっているか? ─ フィッティングと決定係数
- 3.3.4 モデルは複雑すぎないか? ─ オーバーフィッティングと予測精度
- 3.3.5 残差の分布 ─ 線形回帰モデルと診断プロット
- 3.3.6 説明変数同士の相関 ─ 多重共線性
- 3.3.7 標準偏回帰係数
第4章 実践的なモデリング
- 4.1 モデリングの準備
- 4.1.1 データの準備と加工
- 4.1.2 分析とモデリングの手法
- 4.2 データの加工
- 4.2.1 データのクレンジング
- 4.2.2 カテゴリ変数の加工
- 4.2.3 数値変数の加工とスケーリング
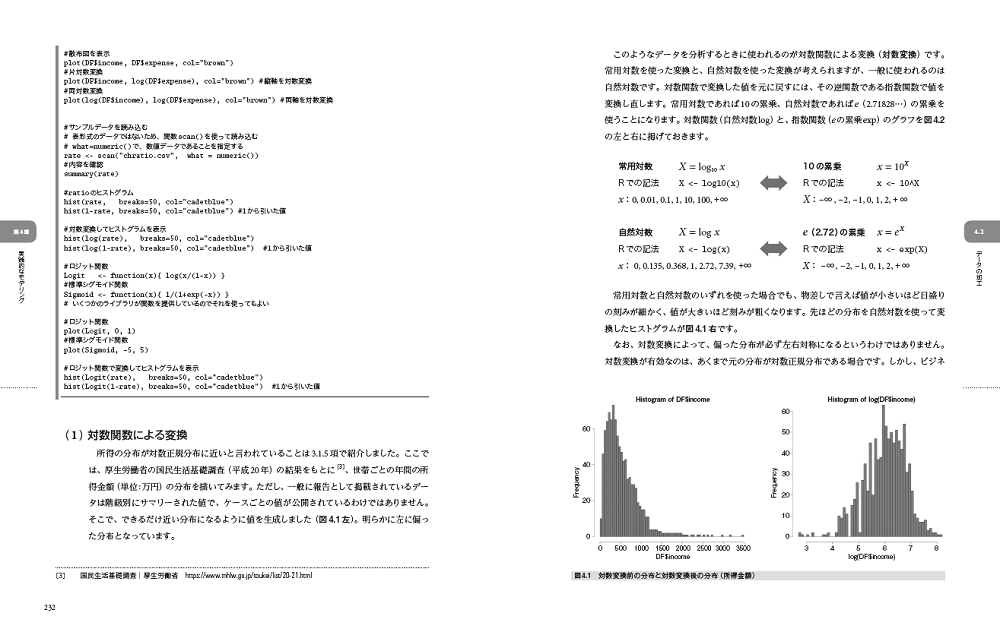
- 4.2.4 分布の形を変える ─ 対数変換とロジット変換
- 4.2.5 欠損値の処理
- 4.2.6 外れ値の処理
- 4.3 モデリングの手法
- 4.3.1 グループに分ける ─ クラスタリング
- 4.3.2 指標を集約する ─ 因子分析と主成分分析
- 4.3.3 一般化線形モデル(GLM)とステップワイズ法
- 4.3.4 2値データを目的変数とする分析 ─ ロジスティック回帰
- 4.3.5 セグメントの抽出とその特徴の分析 ─ 決定木
- 4.4 因果推論
- 4.4.1 データから因果関係を明らかにする ─ 統計的因果推論
- 4.4.2 因果の有無の検証
- 4.4.3 因果効果の推定
- 4.4.4 因果関係の定式化 ─ 構造方程式モデリング
- 4.4.5 因果関係の定式化 ─ 構造的因果モデル
- 4.4.6 因果関係の定式化 ─ ベイズ統計モデリング
- 4.4.7 因果の探索
- 4.4.8 因果関係に基づく変数選択
第5章 機械学習とディープラーニング
- 5.1 機械学習の基本とその実行
- 5.1.1 機械学習の基本
- 5.1.2 機械学習ライブラリの活用 ─ scikit-learn
- 5.1.3 機械学習の実行(教師あり学習)
- 5.1.4 機械学習の実行(教師なし学習)
- 5.1.5 スケーリングの実行(標準化・正規化)
- 5.1.6 次元の削減(主成分分析)
- コラム 機械学習と強化学習
- 5.2 機械学習アルゴリズムの例
- 5.2.1 k近傍法
- 5.2.2 ランダムフォレスト
- 5.2.3 ロジスティック回帰とリッジ回帰
- 5.2.4 サポートベクターマシン(SVM)
- 5.3 機械学習の手順
- 5.3.1 機械学習の主要な手順
- 5.3.2 ホールドアウト法による実行
- 5.3.3 クロスバリデーションとグリッドサーチ
- 5.3.4 閾値の調整
- 5.3.5 特徴量の重要度と部分従属プロット
- 5.4 機械学習の実践
- 5.4.1 データの準備に関わる問題
- 5.4.2 特徴抽出と特徴ベクトル
- 5.4.3 機械学習の実行例
- 5.5 ディープラーニング
- 5.5.1 ニューラルネットワーク
- 5.5.2 ディープラーニングを支える技術
- 5.5.3 ディープラーニング・フレームワーク
- 5.5.4 ディープラーニングの実行
- 5.5.5 生成モデル
サポート
ダウンロード
付録記事のダウンロード
本書をご購入いただいた方は,次の特別記事をダウンロードしてお読みいただけます。
- Anacondaのインストール
- RとRStudioのインストール
- RStudioの使い方
- Jupyter Notebookの使い方
- Anacondaでのライブラリ追加方法
- R,Pythonを使う上で知っておきたいこと
ご購入の証明として,以下の場所に記載された文字列をご入力のうえ,ダウンロード後に解凍してご利用ください。
サンプルソースのダウンロード
(2022年5月23日最終更新)
本書のサンプルソースがダウンロードできます。
- ダウンロード
- sample20220523.zip(約2.3MB)
※Chapter 4の「chratio.csv」を追加しました。
解凍すると章ごとフォルダにサンプルソースとデータファイルが配置されています。
正誤表
本書の以下の部分に誤りがありました。ここに訂正するとともに,ご迷惑をおかけしたことを深くお詫び申し上げます。
P.16:図1.4「CRISP-DMで定義されている6つのフェーズ」の「展開」の英字