今回はオープンソースでマルチプラットフォームのOCRエンジンであるTesseract OCRを使用し、読み取り精度を確認してみます。
UbuntuでOCR?
「日本語でOCR 」と聞くと、プロプライエタリの牙城というか、高価なソフトを購入しないと実用に耐えないというイメージがあるかもしれません。あるいはないかもしれませんが、いずれにせよ日本語の文字は難しいのでOCRで高い精度を出すのはなかなか難しそうに思えます。
少なくとも筆者はそう考えていたので、OCRで高精度の結果を出すのは困難、ましてやオープンソースで……と考えていました。そんなところに、Tesseract OCR のバージョン4.0以降では日本語でもかなりの高精度で認識するという話を小耳に挟みました。実際に試してみると想定していた以上の結果だったので、ここで紹介することにします。
Tesseract OCRとgImageReader
Tesseract OCRはOCRエンジンのみです。コマンドラインのフロントエンドも用意されていますが、やはりGUIフロントエンドがほしいところです。そのようなことを考える人が多いからか、Tesseract OCR自体がマルチプラットフォームであることもあり、たくさんのGUIフロントエンドが開発 されています。
そのなかで現在も継続して開発が進んでおり、かつUbuntuのリポジトリにあるものということでgImageReader を選択しました。なお、今回はTesseract OCRの精度を確認することを主旨としているため、gImageReaderのさまざまな機能には触れません[1] 。
使用するUbuntuは19.04です。Tesseract OCRのバージョンは4.0のリリース版です。それ以前のUbuntuだとTesseract OCRのバージョンが若干古いため(具体的には18.04 LTSだと4.0の開発版) 、同様の結果にならないかもしれません。また快適に動作させるにはそれなりのスペックのPCが必要です。逆にいえば、ハードウェアのスペックが高ければ高いほど短時間で処理が行なえます。
インストール
前述のとおりTesseract OCRとそのフロントエンドであるgImageReaderはUbuntuのリポジトリにありますので、これをインストールするだけです。注意点としては言語データが言語ごとに分かれてパッケージングされており、また日本語の場合は日本語(横書き)と縦書き日本語に分かれているため、その両方をインストールします。
端末を起動し、次のコマンドを実行してください。
$ sudo apt install gimagerader tesseract-ocr-jpn-* 読み込む画像を作成
読み込む画像は何でもいいですが、LibreOffice Writerを起動してキーボードのd→t→F3を順番に押すと挿入されるダミーテキストを使用することにします。書式はデフォルトだとレイアウトがあまりきれいではないため、第440回 を参考に適宜修正しています。
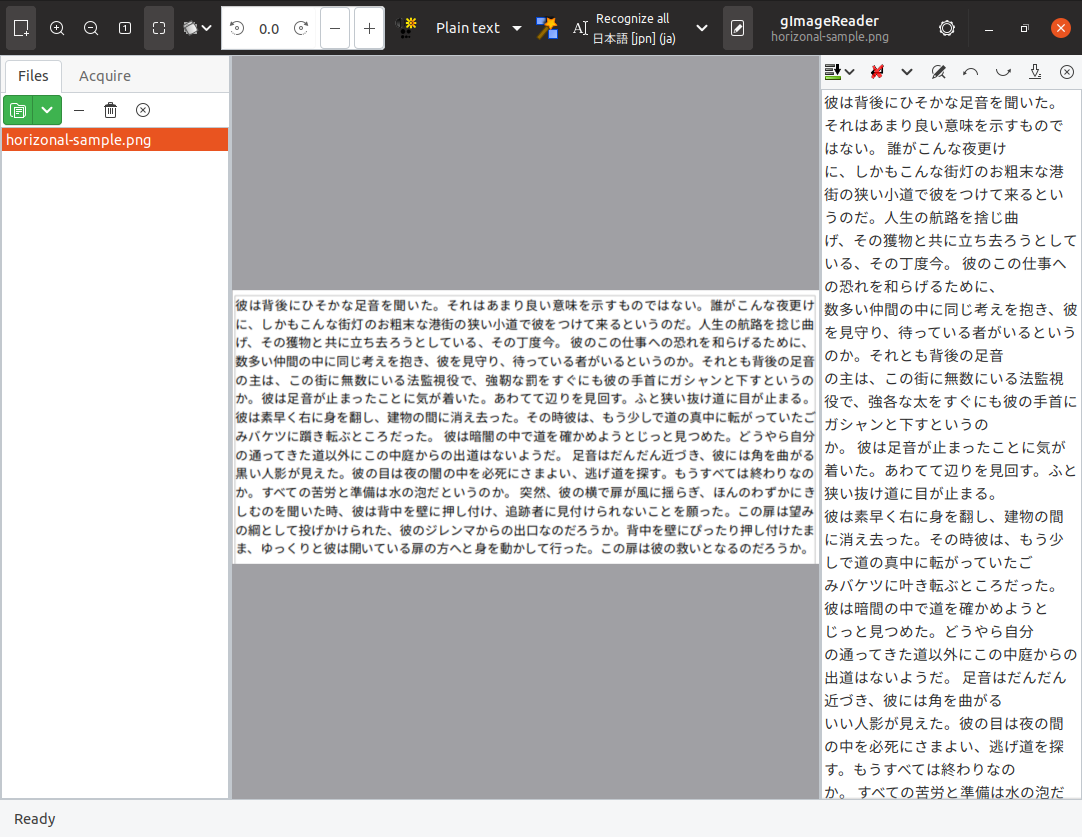
続けてこれを画像として保存しますが、「 ファイル」 -「 エクスポート」でPNGやJPEGで保存する方法もありますし、「 スクリーンショット」( GNOMEスクリーンショット)を起動して「取得する領域の選択」で文字の部分だけを保存する方法もあります。今回は後者を使用します。図1 が実際に使用した画像です。
図1 横書きサンプルあまり縦書きのOCRを使用することはないでしょうが、縦書きの画像も用意して試してみることにします。ダミーテキストも縦書きになりますが、こちらはページサイズをA5にしています。図2 が実際の画像です。
図2 縦書きサンプル読み込みと実行
ではgImageReaderを起動し、画像の文字を読み取っていきます。
起動はアクティビティから行ってください。昨今あまり見なくなった情報量多めのアイコンが目印です。
起動直後のスクリーンショットは図3 です。下のほうにスペルチェックがインストールされていない旨の警告が表示されています。日本語のスペルチェック辞書はないので「Don’t show again」をクリックします。
図3 gImageReaderの起動直後また中央やや右側にフォントが正しく表示されていない(いわゆるトーフ状態)の文字列が見えます。これは実は言語データで、これを元に文字の読み取りが行われるのですが、見にくくて仕方がないので変更します。
右にある歯車アイコンをクリックし、さらに「Preference」をクリックします。「 Predefined language definitions」の「Filename Prefix」が「jpn」と「jpn_vert」のところまでスクロールし(図4 ) 、「 Native name」を書き換えます。ここでは「日本語」「 日本語(縦書) 」としました(図5 、※2 ) 。
図4 「 Filename Prefix」が「jpn」と「jpn_vert」のところまでスクロールし、「 Native name」を書き換える 図5 言語データのトーフが直ったこれで準備は完了で、続けて画像を読み込みます。左側のペインにある緑色のアイコンをクリックするとファイルダイアログが表示されるので、読み込ませる画像を選択してください。
この状態だと縦書きの言語データが選択されているため、「 ∨」アイコンをクリックして「日本語[jpn]」に変更します(図6 ) 。また「Page segmentation mode」を「Automatic segmentation mode」に変更します。
図6 言語モデルと「Page segmentation mode」を変更する ここまできたら、あとは「Recognize all 日本語[jpn](ja)」をクリックします。すると処理が実行され、認識された文字が右ペインに表示されます(図7 ) 。右から2番目のアイコンをクリックすると保存することができますが、この場合はコピーしてLibreOffice Writerに貼り付けるというのも一つの手です。
図7 読み取った結果は右ペインに表示される縦書きも言語データを縦書きのものに変更することを除けばおおむね同じ方法で実行できます。
精度
気になる精度はいかがなものでしょうか。目視では正確性に不安があるため、差分を表示するツールであるMeldを使用して確認します。なお先ほど保存したテキストファイルには改行やスペースが含まれているため、事前にこれを除去してください。
サンプルテキストもLibreOffice Writerの機能でテキストファイルとして保存するか、あるいはエディター(gedit)に貼り付けて保存してもいいでしょう。
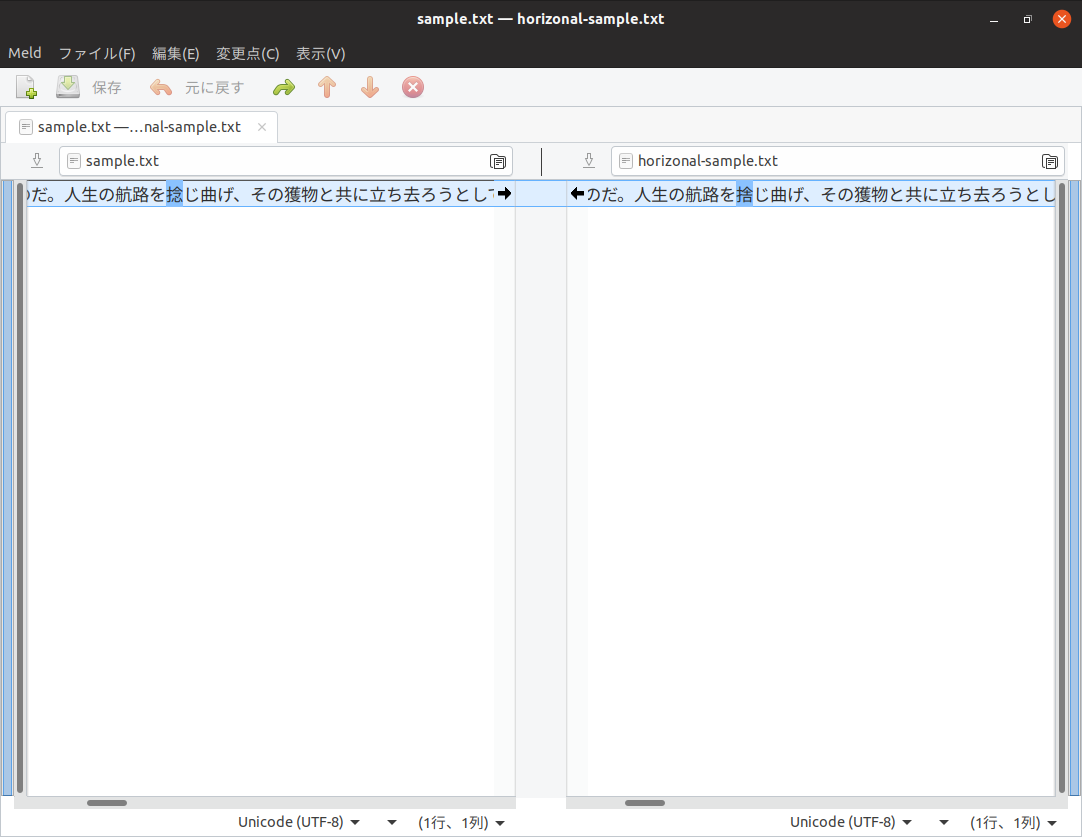
MeldをUbuntuソフトウェアあるいはコマンドラインからインストールし(パッケージ名はmeld) 、起動後それぞれのファイルを指定すると差分が表示されます(図8 、図9 ) 。スペースを除いて同一にすると637文字であり、うち9文字が誤りという結果になりました。すなわち正解は628文字で、628÷637で0.985871、約98.6%の正解率です。もちろんサンプルがこれだけなので断言はできないものの、かなりの精度であるとはいえると思います。
図8 Meldを起動し、差分を表示するテキストを指定する 図9 差分がわかりやすく表示されるちなみに誤った文字は次のとおりです。「 闇」は2回間違えているので全部で9文字の誤りとなります。
捻→捨
靭→各
罰→太
躓→叶
闇→間
黒→い
望→過
綱→網縦書きの場合はスペースが大量に入るので確認しにくいのですが、整形して確認すると誤りは7文字と、横書きよりも精度が高かったです。
ちなみに誤った文字は次のとおりです。ひらがなを間違えたのが横書きにはなかった特徴でしょうか。
聞→間
捻→太
靭→朝
翻→番
躓→中
闇→間
ぴ→びサンプルとしては適切な量ではありませんが、精度の高さを垣間見ることはできました。紙の書類の山に埋もれて困っているような場合は、是非とも試してみてください。