


本稿は
日本語では
早速ですが、まずカリブレーションとは
“確率の値を直に扱う”場合にカリブレーションが必要
まず明らかにしなければならないのは
例えば書籍
既に書籍
例「ローン金利のパーソナライゼーション」
ここでは
さて、あるユーザにローンサービスを提供した結果から得られる利益(Profit)は
です。ここでAはユーザへの貸出金額、rは貸出金額Aに対する支払い利息の金利、Tは返済時点, τは
ただしここで、
- 分割返済を考えたかったが、生存時間解析が必要なことに気が付いたのでやめた
- 現在価値への
“割引 (金融で言うディスカウントファクター)”は数式がゴチャゴチャして見づらくなるので一旦無視 (恒等的に1と置いたと等価)
としています。
ここで、あるユーザが債務不履行になるかならないかは現時点t (< T)ではわからないので、利益自体も確率変数とみなす必要があります。利益の期待値を計算すると
となります。ここで
という関係を用いて、
個人的にはこの数式だけでも含蓄が深いもので、一旦ここで可視化をしてみましょう。期待利益が0円になるいわゆる損益分岐点は、数式
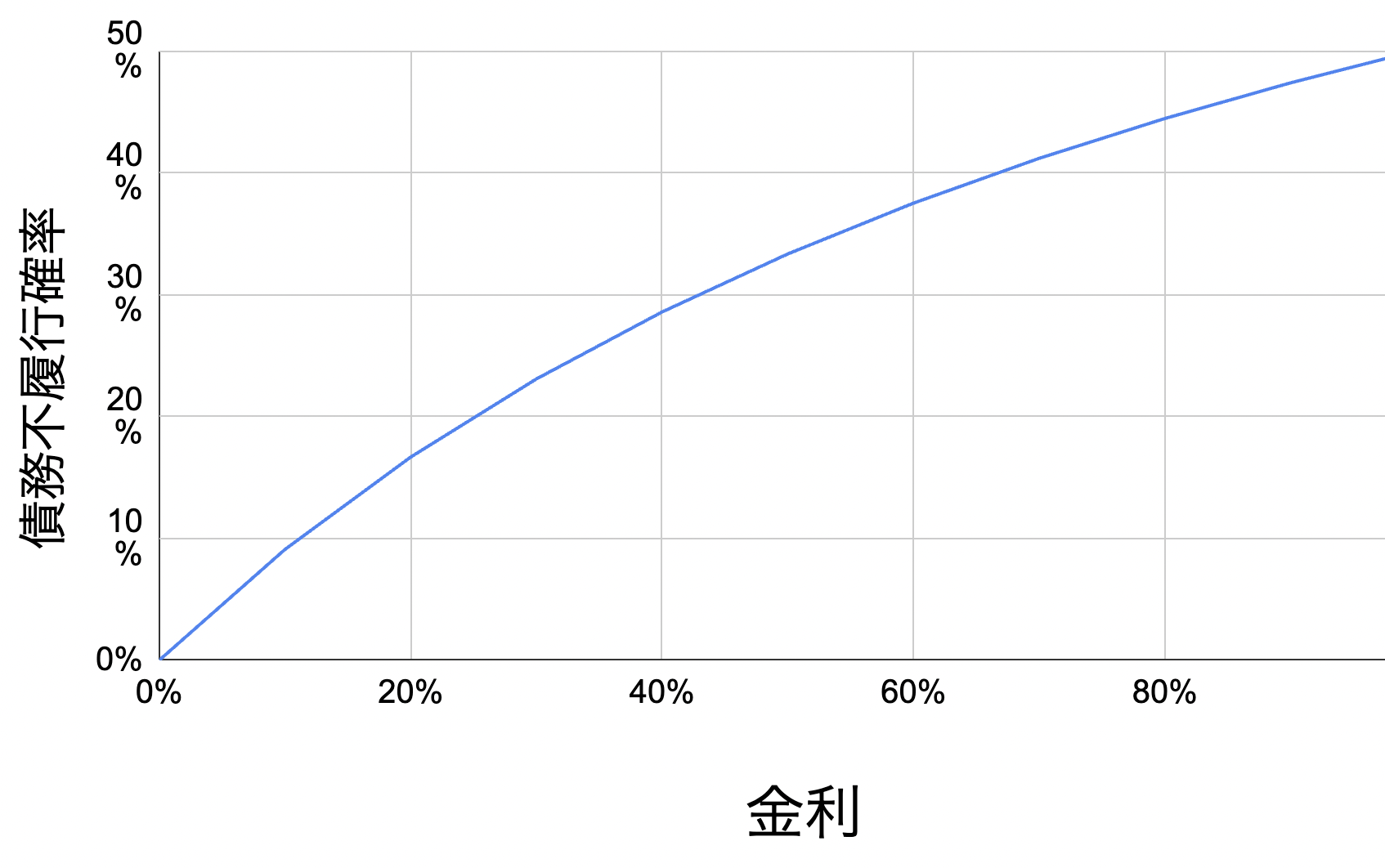
となります。日本の法定金利
上のグラフを使って、債務不履行確率に応じて金利を決めても良いのですが、それでは期待利益が0円になってしまいこれではビジネスが立ち行きません。なので、ここでは
これを金利rについて解くと
と利益率cを加味した上で金利rを決定することができます。数式のチェックを兼ねて、まず
となります。これは例えば
以下では
その他の直感的な考え方として
さて、ここではデータを作るのも面倒なので scikit-learnの make_
import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
import numpy.typing as npt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.calibration import CalibratedClassifierCV, CalibrationDisplay
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import brier_score_loss, log_loss, average_precision_score, roc_auc_score
import pandas as pd
# Train + Testで10万サンプルを生成、標本全体での平均的な債務不履行確率を5%とする
X, y = make_classification(n_samples=100_000, n_features=10, n_informative=7, weights=[0.95, 0.05], random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=43)
#モデルは適当に4つ用意、パラメータは適当
lr = LogisticRegression(C=1.0)
nb = GaussianNB()
rf = RandomForestClassifier(max_depth=3, random_state=71)
nbc = CalibratedClassifierCV(nb, cv=5, method="sigmoid")
clf_list = [(lr, "LR"), (nb, "NB"), (rf, "RF"), (nbc, "NBC")]
作成したデータは1レコードが
PythonでのカリブレーションのCodeの書き方や教科書的な評価指標
などよく書かれたブログを参考にするのがよく、ここでは説明はしません。
タイトル/冒頭にあるように本稿では
次に
fig = plt.figure(figsize=(10, 10))
gs= GridSpec(4, 2)
colors = plt.cm.get_cmap("Dark2")
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=20,
name=name,
ax=ax_calibration_curve,
color=colors(i),
)
calibration_displays[name] = display
ax_calibration_curve.set_title("Calibration plots")
plt.show()
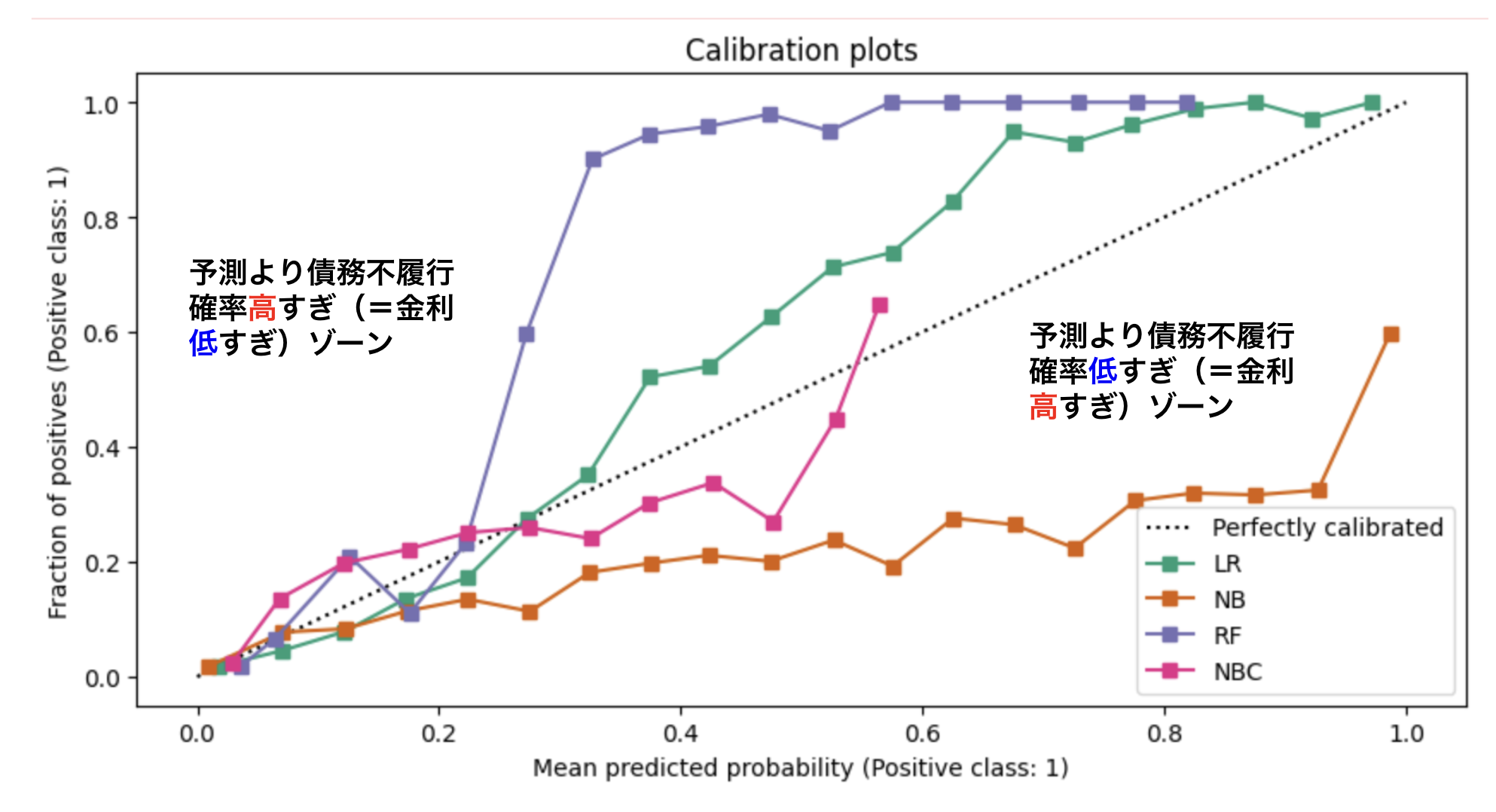
さて、scikit-learnが返してくれるカリブレーション描画結果をビジネス
整理すると
- 損ゾーンでは債務不履行確率を低めに見積もりすぎるため、利益を圧迫し、場合によっては赤字になってしまう
- 儲ゾーンでは債務不履行確率を高めに見積もりすぎるため、想定した利益率cよりも多くのユーザから利益を得てしまうことになる
ということになります。それぞれのモデルの線がどちらの領域に入っているのかを見比べることで、債務不履行を過剰/
例えばナイーブベイズモデル
なぜカリブレーションが必要なのか?
さて、無事にカリブレーションの計算を終えることができました。次に
- 債務不履行確率を低く見積もってしまう損ゾーンは利益を圧迫する。つまり安売り
(低金利貸出) し過ぎているので、ここを減らさないとビジネスとして立ち行かなくなる。ユーザのモラルハザード (自身の債務不履行確率に比べて金利が著しく安い場合、ユーザがお金を借りまくってローンサービスの損失が大きくなる可能性あり) を引き起こす恐れもある - 債務不履行確率を高く見積もってしまう儲ゾーンは利益を多くあげることができる。一方、ユーザにとって不利益であり、高すぎる金利の提示はユーザからのサービスへの心象を悪くしLTV
(Life Time Value) の低下を招く。また競合他社から見ると、同じ利益率c (5%) を設定しているならば、まだ金利を下げる余地があることを意味し顧客の流出を招き得る - 利益率cが指定した値
(ここでは5%) になるのは、機械学習モデルの吐き出す債務不履行確率が完全にカリブレーションされている場合である。例えばナイーブベイズモデルの場合、カリブレーションは明らかになされていないのでユーザごとの利益率がバラつく
最初の1と2は簡潔に言うと1:
3を解釈するにはもう少しビジネス的な視点が必要です。ここではユーザによらず利益率cが一定であると仮定していたのでした。こうすることで得られるメリットは、
例えば
- 貸出金額と利益率から、現時点での利益の着地点が見えるので、目標との乖離を計算しそこを埋めるための施策を考えることができる
- 例:あえて金利を下げて薄利多売にしてでも貸出額を増やす
- 例:マーケティング施策を行い新規顧客を増やす
- 各月単位などでの将来時点での利益
(手元に入ってくる現金) が見えるので資金繰りの計画が立てやすい
を考えることができるでしょう。書籍
def interest_rate(c: float, prob: npt.ArrayLike) -> npt.ArrayLike:
"""数式にそって金利を計算する関数
Args:
c(float): 利益率
prob(npt.ArrayLike): 債務不履行確率のベクトル
Returns:
npt.ArrayLike: 貸出の金利
"""
# prob == 1 の場合を避けるためのおまじない
epsilon = 1e-6
return((1 + c)/(1 - prob + epsilon) - 1)
def profit(A: float, r: npt.ArrayLike, y: npt.ArrayLike):
"""数式にそって利益を計算する関数
Args:
A(float): 貸出金額
r(npt.ArrayLike): 金利のベクトル
y(npt.ArrayLike): 債務不履行(1) or not(0)のベクトル
Returns:
npt.ArrayLike: 利益
"""
return((1 + r) * A * (1 - y) - A)
# 貸出金額
A = 1
# 利益率
c = 0.05
# 利息制限法の上限金利20%/年
r_upper = 0.2
# A円をlen(y_test)人に利益率cで貸し出した場合の利益(合計)
sum_profit_expected = c * A * len(y_test)
scores = defaultdict(list)
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
y_prob = clf.predict_proba(X_test)
y_pred = clf.predict(X_test)
scores["Classifier"].append(name)
for metric in [brier_score_loss, log_loss]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_prob[:, 1]))
for metric in [average_precision_score, roc_auc_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_pred))
# 金利、利益(ベクトル and 合計)の計算
r = interest_rate(c, y_prob[:, 1])
p = profit(A, r, y_test)
profit_rate = sum(p)/(A*len(y_test))
# 利息制限法の上限金利20%/年を考慮した版の計算
profit_rate_limited = sum(p * (r < r_upper))/(A*sum(r < r_upper))
# スコア化
scores["Profit Rate"].append(profit_rate)
scores["Profit Rate (limited)"].append(profit_rate_limited)
score_df = pd.DataFrame(scores).set_index("Classifier")
pd.options.display.precision = 4
score_df
計算した結果、以下のようになります。
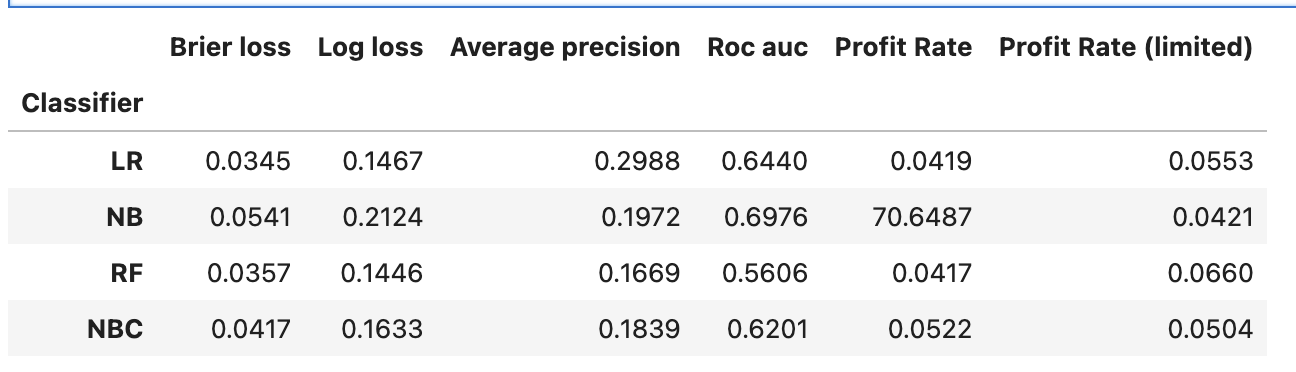
確率を使って評価する評価指標brier lossやlog lossではロジスティック回帰
また、日本の法定金利
このような