この記事を読むのに必要な時間:およそ 0.5 分
ダウンロード
付録記事のダウンロード
本書をご購入いただいた方は,次の特別記事をダウンロードしてお読みいただけます。
- Anacondaのインストール
- RとRStudioのインストール
- RStudioの使い方
- Jupyter Notebookの使い方
- Anacondaでのライブラリ追加方法
ご購入の証明として,以下の場所に記載された文字列をご入力のうえ,ダウンロード後に解凍してご利用ください。
なお,本書の増補改訂版をご利用の方は次のURLからダウンロードください。
サンプルソースのダウンロード
(2019年11月25日更新)
本書のサンプルソースがダウンロードできます。
- ダウンロード
- sample20191122.zip(約310KB)
解凍すると章ごとフォルダにサンプルが配置されています。
3.2.04.ModelComparison.R(P.155)のコメント行を修正したので差し替えました。
[Viewer]タブでの表示について
P.275の1~3行目に記載されている[Viewer]タブでの表示について,Windows上でRStudioを使用している場合に,正常にプロットが表示されないことがあります。その場合は[Viewer]タブにある[矢印と四角]のアイコン(下図参照)をクリックしてください。クリックするとWebブラウザが起動し,ブラウザ上にプロットが表示されます。
ライブラリtabplotを使った際のエラーについて
(以下2019年11月11日更新)
Rの新バージョン(3.6以降)とRStudioの旧バージョンの組み合わせにおいて,P.308のリスト4.8で,ライブラリtabplotを使って次のコードを実行する際にエラーが発生することが確認されています。
tableplot(DF[, -1], sortCol ="契約")
tableplot(DF[, -1], sortCol ="通話分数")
・エラーメッセージ
Error in if (by < 1) stop("'by' must be > 0")(以下略)
|
エラーを回避するためには,RStudioを最新のバージョンにアップデートしてください。
2019年11月5日現在の最新版は次のとおりです。
- RStudio 1.2.5019
- R 3.6.1
- tabplot 1.3-3
(以下2019年3月26日更新)
図3.15(P.129)のプロットをWindows環境で描画すると文字化けが生じる場合があります。その場合,リスト3.3「3.1.04.Correlation.R」(P.124)の関数qgrah()内の引数に次の1行を挿入してください(P.125の下から10行目に相当する箇所/#③相関係数のグラフ表示内)。
labels=colnames(COR), #ラベルを省略せずに表示
|
お詫びと訂正(正誤表)
本書の以下の部分に誤りがありました。ここに訂正するとともに,ご迷惑をおかけしたことを深くお詫び申し上げます。
P.254 図4.14:英語の成績
| 誤 |
98,85,NA,85,85
|
|---|
| 正 |
98,85,72,NA,85
|
|---|
P.255 本文:「ペアワイズ」項の上から5行目
| 誤 |
4名分のケースを使うことができます。
|
|---|
| 正 |
3名分のケースを使うことができます。
|
|---|
P.90 例2.40の上から4行目のコメント
| 誤 | #row 2, column 1
|
|---|
| 正 | #row 1, column 2
|
|---|
P.155 リスト3.6の中16~22行目のコメント
| 誤 |
#目的変数の値について、モデル上の理論値を求める
#=モデルを元のデータDFに当てはめて、DFの説明変数に
# 基づく予測値を算出する
#関数predict():モデルをデータに当てはめ予測値を算出
#ここではモデルを作成した際のデータをそのまま使う
#説明変数の値のみが予測に使われる
|
|---|
| 正 |
#目的変数の値について、モデル上の理論値を図示する
# モデル上の理論値
# =モデルをDFの説明変数の値に当てはめた場合の予測値
#理論値はモデル作成の際にfitted.valuesとして格納されている
#実測値との差(残差)は同様にresidualsとして格納されている
|
|---|
P.325 リスト4.8内 下から17行目
| 誤 |
box.col = c("pink", "palegreen3")[CRT1$frame$yval])
|
|---|
| 正 |
box.col = c("pink", "palegreen3")[CRT3$frame$yval])
|
|---|
P.329 本文 下から2行目
| 誤 |
実測値と一致します。
|
|---|
| 正 |
ロジスティック回帰による予測結果と一致します。
|
|---|
P.329 図4.47:枝を買った決定木
末端ノード(9)の一部の文字と背景色を変更しました。

P.47 例2.7:ベクトルへの要素の追加(上から3~4行目)
| 誤 |
[1] 2 2 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34
[20] 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64
|
|---|
| 正 |
[1] 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
[20] 42 44 46 48 50 52 54 56 58 60 62 64
|
|---|
P.47 例2.7:ベクトルへの要素の追加(下から1~2行目)
| 誤 |
[1] 2 2 2 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
[20] 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 64 64 64
|
|---|
| 正 |
[1] 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38
[20] 40 42 44 46 48 50 52 54 56 58 60 62 64
|
|---|
P.82 (3)条件分岐の構文
コード例がRの記述になっておりました。
| 誤 |
if (論理式) {
論理式の評価がTRUEの場合の処理
} else {
上記以外の場合の処理
}
|
|---|
| 正 |
if 論理式 :
論理式の評価がTRUEの場合の処理
else :
上記以外の場合の処理
|
|---|
※以降の訂正は第2刷では修正されています。
P.15 本文 上から7行目
| 誤 |
その商品が落ちたのか、
|
|---|
| 正 |
どの商品が落ちたのか、
|
|---|
P.20 本文 下から3行目
P.51 リスト2.2 2.2.03.DataStructure.R(続き)の上から14行目
| 誤 |
DFSize[, 3] #すべてのrow, column 2
|
|---|
| 正 |
DFSize[, 3] #すべてのrow, column 3
|
|---|
P.56 例2.14の上から8行目
| 誤 |
> DFSize[, 3] #すべてのrow, column 2
|
|---|
| 正 |
> DFSize[, 3] #すべてのrow, column 3
|
|---|
P.61 本文 上から6行目
| 誤 |
与えられたリスト(最初の引数)
|
|---|
| 正 |
与えられたベクトルやリスト(最初の引数)
|
|---|
P.94 本文 上から8行目(参照ファイル名)
| 誤 |
2.4.01.sample.csv
|
|---|
| 正 |
sample.csv
|
|---|
P.123 本文 下から1行目
P.129 図3.15 相関係数のグラフ表示
項目名称が見切れていました。

P.135 本文 下から7行目
P.145 注17 上から4行目
| 誤 |
123×104=1230000
|
|---|
| 正 |
123×104=1230000
|
|---|
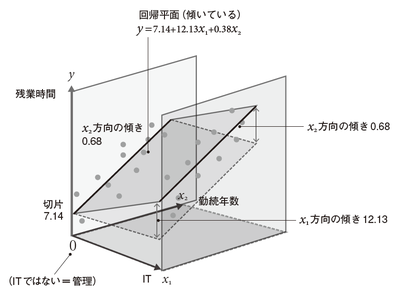
P.157 図3.26 通常の線形回帰モデル
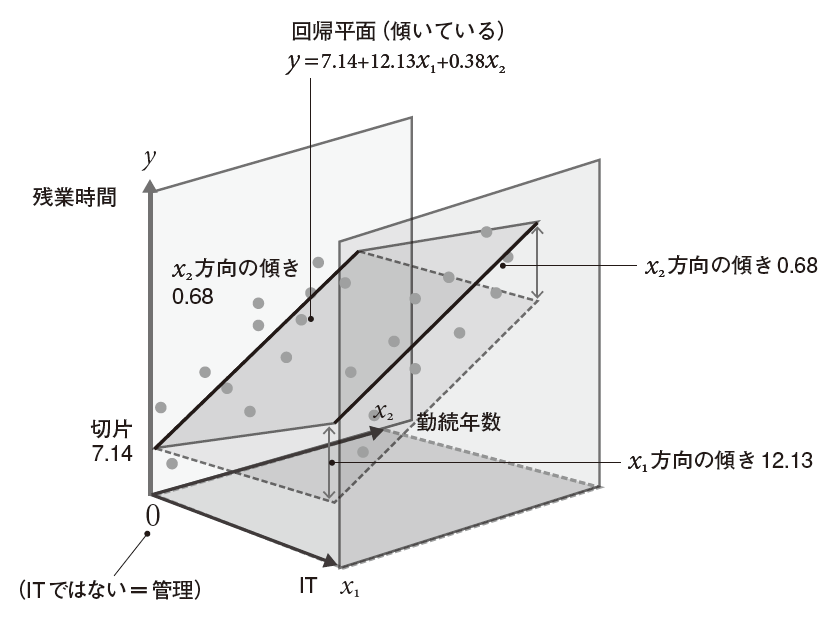
「x2方向の傾き0.68」を指し示す位置を変更しました。
P.161 図3.29 左「負の交互作用の例」の式
| 誤 |
b0 = 100, b1 = 100, b2 = 3, b3 = -0.1
|
|---|
| 正 |
b0 = 100, b1 = 2, b2 = 3, b3 = -0.1
|
|---|
P.161 図3.29 右「正の交互作用の例」の式
| 誤 |
b0 = 100, b1 = 0, b2 = 0, b3 = -0.1
|
|---|
| 正 |
b0 = 100, b1 = 0, b2 = 0, b3 = 0.1
|
|---|
P.182 本文 下から5~6行目(丸数字は紙面では黒丸数字)
| 誤 |
有意に多いカテゴリが赤(⑤⑥)、有意に少ないカテゴリが青(①②)
|
|---|
| 正 |
有意に少ないカテゴリが赤(⑤⑥)、有意に多いカテゴリが赤(①②)
|
|---|
P.184 本文 上から3行目
P.187 本文 上から6行目
| 誤 |
実測値と平均値との差 fi - M
|
|---|
| 正 |
実測値と平均値との差 yi - M
|
|---|
P.187 本文 上から7行目
| 誤 |
予測値と平均値との差 yi - M
|
|---|
| 正 |
予測値と平均値との差 fi - M
|
|---|
P.201 本文 上から8行目
P.202 本文 下から1行目
P.204 図番号
P.210 本文 上から10行目
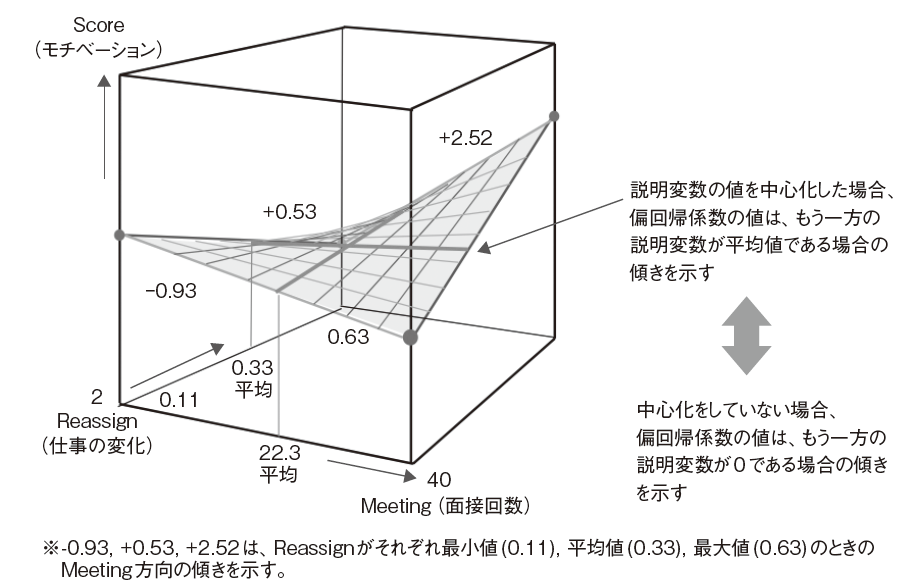
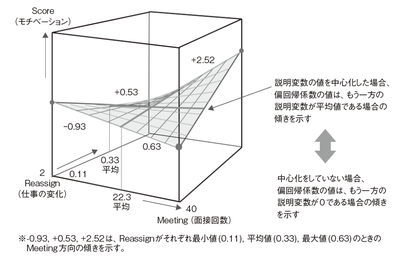
P.211 図3.47 交互作用を含むモデルと中心化
右側の説明から指す矢印の場所を修正し,数値の意味を追記しました。
P.267 本文 下から2行目
P.278 図4.26 表「因子負荷量」のヘッダ
P.296 本文 下から3行目
P.310 本文 上から4行目
P.335 本文 下から9行目
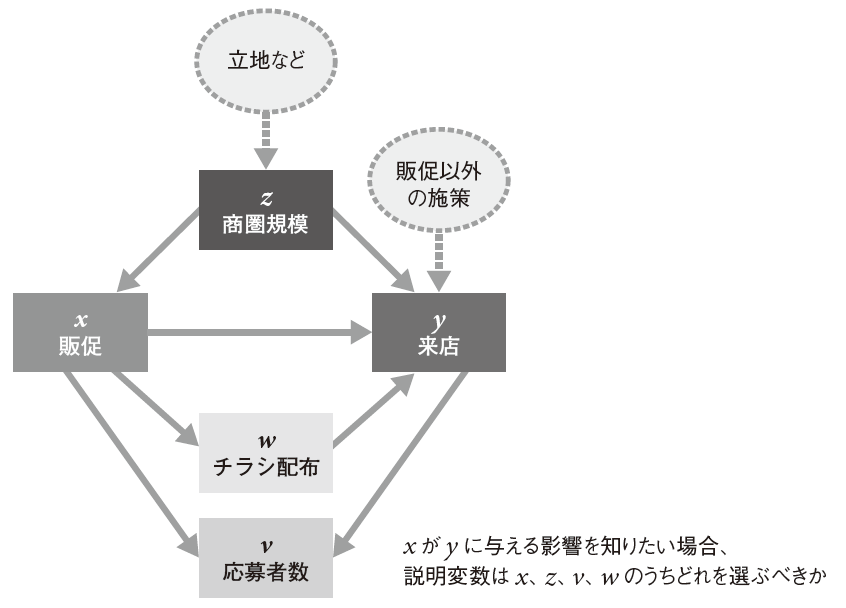
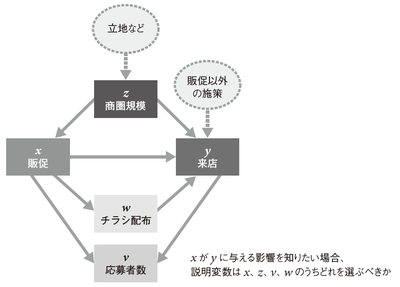
P.339 図4.48 各変数間の因果関係
「販促」と「チラシ配布」の矢印の向きを修正します。
P.375 本文 上から1行目
P.xiii 上から2行目
| 誤 |
(2) 一般線形モデル(GLM)
|
|---|
| 正 |
(2) 一般化線形モデル(GLM)
|
|---|
P.302 下から3行目(見出し)
| 誤 |
(2) 一般線形モデル(GLM)
|
|---|
| 正 |
(2) 一般化線形モデル(GLM)
|
|---|
P.115 リスト3.2(3.1.02.Summarize.R)の6行目
| 誤 |
stringsAsFactors = FALSE), #文字列を文字列型で取り込む
|
|---|
| 正 |
stringsAsFactors = FALSE) #文字列を文字列型で取り込む
|
|---|
P.154 リスト3.6(3.2.04.ModelComparison.R)の9行目
| 誤 |
stringsAsFactors = FALSE, #文字列を文字列型で取り込む
|
|---|
| 正 |
stringsAsFactors = FALSE) #文字列を文字列型で取り込む
|
|---|
P.167 リスト3.7(3.2.05.TwoRegression.R)の9行目
| 誤 |
stringsAsFactors = FALSE, #文字列を文字列型で取り込む
|
|---|
| 正 |
stringsAsFactors = FALSE) #文字列を文字列型で取り込む
|
|---|
P.209 リスト3.13(3.3.07.MultiColinearity.R 続き)の22行目
| 誤 |
stringsAsFactors = FALSE, #文字列を文字列型で取り込む
|
|---|
| 正 |
stringsAsFactors = FALSE) #文字列を文字列型で取り込む
|
|---|
P.215 リスト3.14(3.4.01.StadardizedRegression.R 続き)の29行目
P.215 リスト3.14(3.4.01.StadardizedRegression.R 続き)の31行目
P.215 リスト3.14(3.4.01.StadardizedRegression.R 続き)の36行目
| 誤 |
# 偏回帰係数*説明変数の不偏分散/目的変数の不偏分散
|
|---|
| 正 |
# 偏回帰係数*説明変数の標準偏差/目的変数の標準偏差
|
|---|
P.237 リスト4.1(4.2.03.Scaling.R)の7行目
P.260 リスト4.5(4.2.06.Outlier.R 続き)の21行目
| 誤 |
#lof値が2を超えてかどうかをTRUE/FALSEで配列化
|
|---|
| 正 |
#lof値が2を超えているかどうかをTRUE/FALSEで配列化
|
|---|