


第721回の
LinuxのCPUベンチマーク事情
新しいCPUがリリースされると、各技術系のサイトからさまざまベンチマークの情報が提供されます。これらのベンチマークのほとんどはWindows上で取得したものです。定番のCinebenchや3DMarkであれば、Wineを利用してUbuntuでも利用可能な可能性が高いですし、CPUベンチマーク機能を持っているBlenderなんかは公式にUbuntuをサポートしているものの、
継続的にLinuxのベンチマークを取得しているサイトだとPhoronixが有名です。Phoronixでは、Linuxも含むマルチプラットフォームなベンチマークランチャーであるPhoronix Test Suite
Linux向けのCPUベンチマークに限って言えば、たとえば次のようなツールが定番です。
- UnixBench:Dhrystoneをはじめとする定番のベンチマークセット。Ubuntuのリポジトリにはパッケージは用意されていない。サードパーティのsnapパッケージはある。
- sysbench:データベース向けのベンチマークツールとして有名。CPUのベンチマークも可能。Ubuntuのリポジトリにはsysbenchパッケージが用意されている。
- Blender:幅広く利用されている3DCG作成ツールである
「Blender」 を利用したCPU/ GPUのベンチマークツール。 - 7-Zip:定番のファイルアーカイバーで、簡単な圧縮・
展開のベンチマークツールが備わっている。Ubuntuのリポジトリにはp7zip-fullパッケージが用意されている。 - HPC Challenge:HPC
(High-Perormance Computer) システムの性能評価に使われるツール。Ubuntuのリポジトリにもhpccパッケージが用意されている。 - CoreMark:元々は組み込み向けのCPUコアをターゲットにしたベンチマークセット。基本機能を備えた通常版と浮動小数点演算に特化したPRO版がある。
Blenderを除くといずれもCLI前提のツールです。Blender自体もGUI無し版が存在し、Unix/
ちなみに前述したように、CinebenchのようなWindows版のベンチマークツールであってもWineを経由してLinuxで動く可能性は高いです。特にゲーム系のベンチマークは、Steamを経由してProton上で動かす方法を取れば比較的簡単に動かせる可能性もあります。よって単にGPUを含むシステム全体のベンチマークを実施したいだけなら、これらのGUI系のツールも選択肢に入ってくるでしょう。
さて、今回はP-Core・
Pythonでベンチマークを実施し視覚化する
今回は7-Zipをベンチマークツールとして使い、Pythonで結果を取得・
- パッケージとして簡単にインストールできること
- CPUコア単体のベンチマークが取りやすいこと
- 計測結果をPythonスクリプトから参照しやすいこと
ただし、パッケージが用意されているsysbench、Blender、HPC Challengeでも、そこまで大きな違いはありません。単に出力結果が一番わかりやすかったのが7-Zipというけです。
また、次のような理由からあえてPythonスクリプトを組んでベンチマークの取得を行おうとしています。
- 単体・
複数のCPUコアを組み合わせて順番にベンチマークを実施したい - ベンチマークの実施期間中、CPUの周波数・
各種温度センサーの値を取得したい - 結果を機械読み取り可能なフォーマットで保存したい
Linuxの場合、sysfs/
UbuntuにおけるCPUベンチマークの注意点
先にUbuntuにおいてCPUベンチマークを計測する際の注意点をまとめておきましょう。なお、ここの説明のほとんどがIntel CPU向けの話です。
CPUFreqによる周波数のスケーリング
現在のLinuxはその負荷に応じて適切にCPUの周波数をコントロールする仕組み
CPUFreqは
scaling governorはCPUの周波数をダイレクトに設定するか、現在の作業量に応じて動的に設定する挙動を行います。それとは別に

sysfsだとおおよそ次の項目から挙動を変更できます。
$ cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor powersave $ cat /sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference performance
ただしいちいちsysfsの適切な場所を思い出して設定するのは面倒です。そこで便利なツールがcpupowerコマンドとなります。cpupowerコマンドは最初からインストールされていないので、次のように追加のパッケージをインストールしてください。
$ sudo apt install linux-tools-generic
この手のツールはカーネルバージョンごとのsysfsの変更をフォローする必要があるため、バージョンごとに異なるバイナリを生成しています。上記のインストール方法だと、リポジトリにある最新のカーネル向けのパッケージがインストールされます。特定のバージョンをインストールしたければlinux-tools-$(uname -r)」
$ sudo cpupower frequency-info
analyzing CPU 0:
driver: intel_pstate
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: Cannot determine or is not supported.
hardware limits: 800 MHz - 5.10 GHz
available cpufreq governors: performance powersave
current policy: frequency should be within 800 MHz and 5.10 GHz.
The governor "powersave" may decide which speed to use
within this range.
current CPU frequency: Unable to call hardware
current CPU frequency: 4.86 GHz (asserted by call to kernel)
boost state support:
Supported: yes
Active: yes
上記はCPU0だけの表示ですが、cpupower -c all frequency-info」
analyzing CPU 23:
driver: intel_pstate
CPUs which run at the same hardware frequency: 23
CPUs which need to have their frequency coordinated by software: 23
maximum transition latency: Cannot determine or is not supported.
hardware limits: 800 MHz - 3.80 GHz
available cpufreq governors: performance powersave
current policy: frequency should be within 800 MHz and 3.80 GHz.
The governor "powersave" may decide which speed to use
within this range.
current CPU frequency: Unable to call hardware
current CPU frequency: 3.77 GHz (asserted by call to kernel)
boost state support:
Supported: yes
Active: yes
ちなみにcpupowerだと、EPB/x86_コマンドを利用します。
$ sudo x86_energy_perf_policy -r cpu0: EPB 6 cpu0: HWP_REQ: min 11 max 64 des 0 epp 0 window 0x0 (0*10^0us) use_pkg 0 cpu0: HWP_CAP: low 1 eff 12 guar 31 high 64 cpu1: EPB 6 cpu1: HWP_REQ: min 11 max 64 des 0 epp 0 window 0x0 (0*10^0us) use_pkg 0 cpu1: HWP_CAP: low 1 eff 12 guar 31 high 64 (中略) cpu23: EPB 6 cpu23: HWP_REQ: min 8 max 38 des 0 epp 0 window 0x0 (0*10^0us) use_pkg 0 cpu23: HWP_CAP: low 1 eff 9 guar 18 high 38 pkg0: HWP_REQ_PKG: min 1 max 255 des 0 epp 128 window 0x0 (0*10^0us) pkg0: MSR_HWP_INTERRUPT: 0x00000000 (Excursion_Min-Disabled, Guaranteed_Perf_Change-Disabled) pkg0: MSR_HWP_STATUS: 0x00000004 (Excursion_Min, No-Guaranteed_Perf_Change)
少しわかりにくいですが、manページにあるように次のような値の対応を持っているようです。
VALUE STRING EPB EPP
performance 0 0
balance-performance 4 128
normal,default 6 128
balance-power 8 192
power 15 255
ベンチマークの際は、どちらのケースも常に全力を出せる
$ sudo cpupower -c all frequency-set -g performance $ sudo x86_energy_perf_policy -a performance
thermaldによる周波数のスケーリング
CPUとは電力を熱に変える暖房器具です。高速に計算しようとすればするほど、消費電力も向上し、熱を発します。しかしながらCPUを構成する半導体は熱に弱い部品です。あんまり全力で計算しすぎると、自分が発した熱で壊れてしまいます。よって使う側はそのことを考えてやさしく扱ってあげなければいけないのです[5]。
そこで登場するのがIntel製のthermaldです。何も指定しなければCPUコアの温度を監視し、100度以下に収まるようCPUの周波数を調整する/etc/以下に適切なXMLファイルを書けば、100度以外のリミットを設けたり、ファンの速度を調整したり等、柔軟な調整が可能です。
ただし高温状態だとCPUが壊れてしまう可能性を考えると、性能のためにthermaldを切るということはないでしょう。よってベンチマークの際は各種温度も同時に監視して、thermald等によって何がしかの調整が入っていないかを確認するのが定番です。
Turbo Boost/Turbo Core Technorogy
IntelやAMDのCPUには、特定のCPUコアを一時的に定格よりも大きなクロックで動作することを許容する仕組みが存在します。特定のCPUコアが全開のその先にたどり着いたとしても
Ubuntuの場合、IntelのTurbo Boost Technologyは特に設定しなくてもCPU側の都合に合わせて自動的に活用します。また、もし
$ cat /sys/devices/system/cpu/intel_pstate/no_turbo 0
ちなみにIntel以外だと/sys/でコントロール可能なようです。
CPU affinity
Linuxにおいて、あるプロセスがどのCPUコアで動くかは決まっていません。最初のうちはCPU3で動いていたとしても、何かの拍子にCPU5で動くようになる、ということはよくあります。たとえば特定のPIDに対して/proc/<PID>/sched」se.」
$ cat /proc/$$/sched bash (2534043, #threads: 1) ------------------------------------------------------------------- se.exec_start : 948566367.554390 se.vruntime : 48240125.337559 se.sum_exec_runtime : 340.907496 se.nr_migrations : 80 nr_switches : 708 nr_voluntary_switches : 686 nr_involuntary_switches : 22 se.load.weight : 1048576 se.avg.load_sum : 193 se.avg.runnable_sum : 197632 se.avg.util_sum : 197632 se.avg.load_avg : 4 se.avg.runnable_avg : 4 se.avg.util_avg : 4 se.avg.last_update_time : 948539438000128 se.avg.util_est.ewma : 9 se.avg.util_est.enqueued : 0 uclamp.min : 0 uclamp.max : 1024 effective uclamp.min : 0 effective uclamp.max : 1024 policy : 0 prio : 120 clock-delta : 67 mm->numa_scan_seq : 0 numa_pages_migrated : 0 numa_preferred_nid : -1 total_numa_faults : 0 current_node=0, numa_group_id=0 numa_faults node=0 task_private=0 task_shared=0 group_private=0 group_shared=0
特定のCPUコアのベンチマークを取りたいなら、そのプロセスは特定のCPUコアでのみ動くことが求められます。これをコントロールするのがtasksetコマンドを利用するとCPU affinytの状態を確認できます。
$ taskset -p -c $$ プロセス ID 1956 の現在の親和性リスト: 0-23
上記の場合CPU0からCPU23までのいずれかのCPUコアで動くということがわかります。CPU affinityは-c」
$ taskset -p -c 0,3,5 PID
affinityの後ろにPIDがくることに注意してください。
さまざまなCPUコアの組み合わせでベンチマークを取る
さて、ようやくPythonの話に戻ってきます。今回は手間を省くために次のような形で実装しました。
- CPUの使用率や温度はGlancesを利用して取得する
- PythonスクリプトとGlances、Glancesからデータを収集する部分はCPU1で動かす
/proc/とcpuinfo /sys/の両方からCPU周波数の値を取得するdevices/ system/ cpu/ cpu0/ cpufreq/ scaling_ cur_ freq - 7-Zipのベンチマークは1スレッドで実施
( 7z b -mmt1を複数のCPUコアで実施) - 7-Zipのベンチマーク実行の間は30秒のクールタイムを設ける
- 出力結果はJSONで保存する
- Ubuntu 22.
04 LTS、Python 3. 10を前提とする
3番目のCPU周波数については、どうやらこの2個のファイルはそれぞれ計算方法が異なるようです。前者が慣らした値で、後者がほぼリアルタイムな値という説明が多いようですが、カーネルのバージョンによっても状況が異なるため、両方取得することにしました。
また、ベンチマークにおけるCPUコアの利用方法は次のとおりです。
- CPUコアを0から順番に1コアずつ実施
- Hyper Threading/
SMTで作られたCPUスレッドについて、同じコアに属するスレッド同士をまとめて順番に実施 (E-Coreの場合はシングルコアなので、上記と結果は同じ) - 偶数コアだけ同時に実施
- 奇数コアだけ同時に実施
- 全コア同時に実施
ベンチマークの実行環境にはあらかじめ、次のツールをインストールしておいてください。ただし最後のpython3-requests自体は、大抵のUbuntuには最初からインストールされているはずです。
$ sudo apt install glances p7zip-full python3-requests
というわけで、実際のPythonスクリプトは次のとおりです。このPythonスクリプトであるbenchmark.
#!/usr/bin/env python3
import datetime
import json
import multiprocessing
import os
import re
import shutil
import subprocess
import sys
import threading
import time
import typing
import requests
def monitoring(
queue: "multiprocessing.Queue[list[typing.Any]]",
event: threading.Event,
cpunum: int,
epoch: datetime.datetime,
):
data = []
while not event.is_set():
datum: dict[str, typing.Any] = {"time": 0, "cpu": {}, "sensor": {}}
# Retrieve from glances
datum["time"] = (datetime.datetime.now() - epoch).seconds
percpu = requests.get("http://localhost:61208/api/3/percpu")
sensors = requests.get("http://localhost:61208/api/3/sensors")
# Retrieve from sysfs
freq = {}
if os.access("/sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq", os.R_OK):
for i in range(cpunum):
with open(
"/sys/devices/system/cpu/cpu{0}/cpufreq/scaling_cur_freq".format(i)
) as f:
freq[i] = int(f.readline())
# Retrieve from procfs
hz = {}
with open("/proc/cpuinfo") as f:
cpuinfo = f.read().split("\n\n")
for cpu, info in enumerate(cpuinfo):
for line in info.split("\n"):
if "cpu MHz" in line:
hz[cpu] = float(line.split(":")[1].strip())
# Organize retrieved data
for stat in percpu.json():
cpu = int(stat["cpu_number"])
datum["cpu"][cpu] = {
"usage": int(stat["total"]),
"freq": freq[cpu],
"hz": hz[cpu],
}
for stat in sensors.json():
datum["sensor"][stat["label"]] = stat["value"]
data.append(datum)
time.sleep(1)
queue.put(data)
def parse_smp_cores():
pattern = re.compile(
r"processor\s+:\s+(?P<logi>\d+)|physical id\s+:\s+(?P<phys>\d+)|core id\s+:\s+(?P<core>\d+)"
)
cores = {}
with open("/proc/cpuinfo") as f:
cpuinfo = f.read().split("\n\n")
for block in cpuinfo:
if len(block) == 0:
continue
coreinfo = {}
for m in re.finditer(pattern, block):
coreinfo.update({k: int(v) for k, v in m.groupdict().items() if v})
# On the assumption that under max core per a CPU package will be less than 2^16.
key = str(coreinfo["phys"] << 16 | coreinfo["core"])
if key not in cores:
cores[key] = []
cores[key].append(coreinfo["logi"])
return cores
def bench_7z(
queue: "multiprocessing.Queue[dict[str, typing.Any]]",
cpu: int,
epoch: datetime.datetime,
):
comm = shutil.which("7z") or sys.exit("needs 7z command")
os.sched_setaffinity(0, {cpu})
result = subprocess.run([comm, "b", "-mmt1"], stdout=subprocess.PIPE)
if result.returncode != 0:
sys.exit("failed to {0} on cpu {1}".format(comm, cpu))
end = (datetime.datetime.now() - epoch).seconds
data = []
for line in result.stdout.decode("utf-8").splitlines():
if line.startswith("Tot:"):
data = line.split()
break
queue.put(
{
"end": end,
"result": (int(data[2]) + int(data[3])) / 2,
}
)
if __name__ == "__main__":
# Start glances as daemon
glances = shutil.which("glances") or sys.exit("needs glances command")
daemon = subprocess.Popen(
[glances, "-w", "--disable-webui"],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
bufsize=0,
pipesize=0,
)
os.sched_setaffinity(daemon.pid, {1})
# Wait to start server
time.sleep(3)
# Get CPU info
result = requests.get("http://localhost:61208/api/3/quicklook")
cpuname = result.json()["cpu_name"]
cpunum = len(os.sched_getaffinity(0))
data = {"cpunum": cpunum, "name": cpuname, "system": " ".join(os.uname())}
# Prepare time epoch
os.sched_setaffinity(0, {1})
epoch = datetime.datetime.now()
# Start monitor thread
queue = multiprocessing.Queue()
event = multiprocessing.Event()
monitor = multiprocessing.Process(
target=monitoring,
args=(
queue,
event,
cpunum,
epoch,
),
daemon=True,
)
monitor.start()
if not monitor.pid:
sys.exit("failed to start monitor process")
os.sched_setaffinity(monitor.pid, {1})
# Start benchmark processes
do_bench = bench_7z
data["benchmark"] = []
start = (datetime.datetime.now() - epoch).seconds
reset = {
"time": (datetime.datetime.now() - epoch).seconds,
"cpu": dict.fromkeys(range(cpunum), {"end": 0, "result": 0}),
}
data["benchmark"].append(reset)
time.sleep(3)
patterns = [(x,) for x in range(cpunum)] # single core
patterns = [(x,) for x in range(cpunum)] # single core
patterns.extend([tuple(v) for _, v in parse_smp_cores().items()]) # with SMT
patterns.append(tuple([x for x in range(0, cpunum, 2)])) # without SMT, even cores
patterns.append(tuple([x for x in range(1, cpunum, 2)])) # without SMT, odd cores
patterns.append(tuple([x for x in range(cpunum)])) # all cores
for pattern in patterns:
print("Start benchmark on CPU", end=" ", file=sys.stderr)
start = (datetime.datetime.now() - epoch).seconds
benchmark_result: list[dict[str, typing.Any]] = [{"time": start, "cpu": {}}]
bench = {}
for i in pattern:
print("{}".format(i), end=" ", file=sys.stderr)
bench[i] = {}
bench[i]["queue"] = multiprocessing.Queue()
bench[i]["proc"] = multiprocessing.Process(
target=do_bench,
args=(
bench[i]["queue"],
i,
epoch,
),
)
bench[i]["proc"].start()
if not bench[i]["proc"].pid:
sys.exit("failed to start benchmark process")
print(file=sys.stderr)
for i in pattern:
bench[i]["proc"].join()
if bench[i]["proc"].exitcode != 0:
sys.exit("failed benchmark process")
result = bench[i]["queue"].get()
benchmark_result[0]["cpu"][i] = result
end = {"time": result["end"], "cpu": {}}
end["cpu"][i] = result
benchmark_result.append(end)
data["benchmark"].extend(benchmark_result)
reset = {
"time": (datetime.datetime.now() - epoch).seconds,
"cpu": dict.fromkeys(range(cpunum), {"end": 0, "result": 0}),
}
data["benchmark"].append(reset.copy())
time.sleep(30)
reset["time"] = (datetime.datetime.now() - epoch).seconds
data["benchmark"].append(reset)
# Output retrieved data
event.set()
data["monitoring"] = queue.get()
print(json.dumps(data))
# Finalize monitor thread and glances daemon
event.set()
monitor.join()
daemon.terminate()
記事を書きながらトライアンドエラーしていたため、いろいろハードコードな部分が残っていますがそのあたりはご愛嬌ということで。各自の好みに応じてもっとうまいやり方に直して実施していただければと思います。
特にこの方法だと、センサーの取得結果が
あとは次のように出力ファイルを指定して実行するだけです。
$ ./benchmark.py > result.json Start benchmark on CPU 0 Start benchmark on CPU 1 Start benchmark on CPU 2 Start benchmark on CPU 3 Start benchmark on CPU 4 Start benchmark on CPU 5 Start benchmark on CPU 6 Start benchmark on CPU 7 Start benchmark on CPU 8 Start benchmark on CPU 9 Start benchmark on CPU 10 Start benchmark on CPU 11 Start benchmark on CPU 12 Start benchmark on CPU 13 Start benchmark on CPU 14 Start benchmark on CPU 15 Start benchmark on CPU 16 Start benchmark on CPU 17 Start benchmark on CPU 18 Start benchmark on CPU 19 Start benchmark on CPU 20 Start benchmark on CPU 21 Start benchmark on CPU 22 Start benchmark on CPU 23 Start benchmark on CPU 0 1 Start benchmark on CPU 2 3 Start benchmark on CPU 4 5 Start benchmark on CPU 6 7 Start benchmark on CPU 8 9 Start benchmark on CPU 10 11 Start benchmark on CPU 12 13 Start benchmark on CPU 14 15 Start benchmark on CPU 16 Start benchmark on CPU 17 Start benchmark on CPU 18 Start benchmark on CPU 19 Start benchmark on CPU 20 Start benchmark on CPU 21 Start benchmark on CPU 22 Start benchmark on CPU 23 Start benchmark on CPU 0 2 4 6 8 10 12 14 16 18 20 22 Start benchmark on CPU 1 3 5 7 9 11 13 15 17 19 21 23 Start benchmark on CPU 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
計測結果を視覚化する
次に生成したJSONファイルを視覚化しましょう。こちらについてはPandasでJSONファイルを読み込み、Matplotlibでグラフの描画を行っています。よって次のツールをインストールする必要があります。
$ sudo apt install python3-matplotlib python3-pandas
実際のPythonスクリプトは次のとおりです。このPythonスクリプトであるplot.
#!/usr/bin/env python3
import argparse
import json
import os
import re
import sys
import matplotlib.pyplot as plt
import pandas
def rename_legend(s: str):
s = re.sub("^cpu.([0-9]+)\\.", "CPU\\1 ", s)
return re.sub("^sensor.(.*)$", "\\1", s)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("json")
parser.add_argument("output")
args = parser.parse_args()
data = []
if not os.access(args.json, os.R_OK):
sys.exit("could not read json {}".format(args.json))
with open(args.json) as f:
data = json.load(f)
cpunum = data["cpunum"]
system = "\n".join((data["name"],data["system"]))
plots = [
{"title": "CPU Usage(%)", "filter": "(time|.usage$)", "style": "plain"},
{
"title": "Even CPU Freq via sysfs (Hz)",
"filter": "(time|\\d*[02468].freq$)",
"style": "plain",
},
{
"title": "Odd CPU Freq via sysfs (Hz)",
"filter": "(time|\\d*[13579].freq$)",
"style": "plain",
},
{
"title": "Even CPU Freq via procfs (MHz)",
"filter": "(time|\\d*[02468].hz$)",
"style": "plain",
},
{
"title": "Odd CPU Freq via procfs (MHz)",
"filter": "(time|\\d*[13579].hz$)",
"style": "plain",
},
{"title": "Sensors (C)", "filter": "(time|^sensor.)", "style": "plain"},
]
fig, axes = plt.subplots(
ncols=1, nrows=len(plots) + 1, sharex=False, figsize=(20, 40)
)
fig.suptitle(system, fontsize=20, y=0.9)
df_mon = pandas.json_normalize(data["monitoring"])
for i, v in enumerate(plots):
df_mon.filter(regex=v["filter"]).rename(columns=rename_legend).plot(
x="time", ax=axes[i]
).legend(loc="upper left", bbox_to_anchor=(1, 1), fontsize="small")
axes[i].set_title(v["title"])
axes[i].ticklabel_format(style=v["style"])
axes[i].grid()
df_bench = pandas.json_normalize(data["benchmark"])
df_bench.filter(regex="(time|result)").fillna(method="ffill").rename(
columns=rename_legend
).plot.area(x="time", ax=axes[len(plots)], stacked=False,).legend(
loc="upper left", bbox_to_anchor=(1, 1), fontsize="small"
)
axes[len(plots)].set_title("Benchmark result")
axes[len(plots)].grid()
fig.savefig(args.output, bbox_inches="tight")
記事を書きながらトライアンドエラーしていたため、いろいろハードコードな部分が残っていますがそのあたりはご愛嬌ということで。各自の好みに応じてもっとうまいやり方に直して実施していただければと思います
さすがに24コアもあるとひとつのグラフにまとめてしまうとごちゃごちゃになってわかりづらかったので、偶数コア・
実行のしかたはJSONファイルと出力ファイルを指定するだけです。
$ ./plot.py result.json result.pdf
出力フォーマットは、出力ファイルの拡張子に準じます。
実行結果を見てみる
さて具体的な実行結果を見ていきましょう。実際の出力結果は1ファイルにまとまっていますが、ここでは説明のしやすいように上から分割していきます。
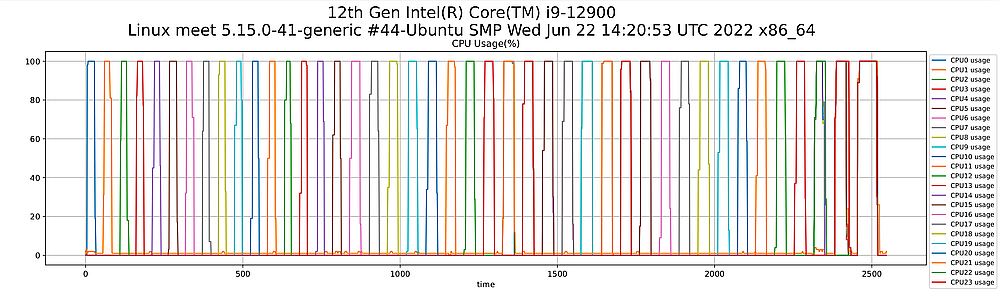
CPUコアごとの使用率の遷移です。100%になっているところがベンチマークを実行中の区間だと考えるときれいに試行回数分ピークが登場しています。また、ピーク期間の幅が広い=ベンチマークに時間がかかっている=性能が落ちているという状態です。最初の16回

/sys/からCPUコアごとに取得した周波数情報です。ほぼリアルタイムの値と考えられます。今回利用したIntel Core i9-12900は次のような性能を備えています。
- Turbo Boost:5.
10 GHz - P-Core Turbo Boost:5.
00 GHz - E-Core Turbo Boost:3.
80 GHz - P-Core Base Frequency:2.
40 GHz - E-Core Base Frequency:1.
80 GHz
今回は周波数設定を
1500秒を超えたあたりと最後のほうでE-Coreも含めて全体的に周波数が落ちている領域がありますが、これは後ほど確認する温度センサーの結果から、おそらくthermaldによるサーマルスロットリングが発生したのだと思われます。
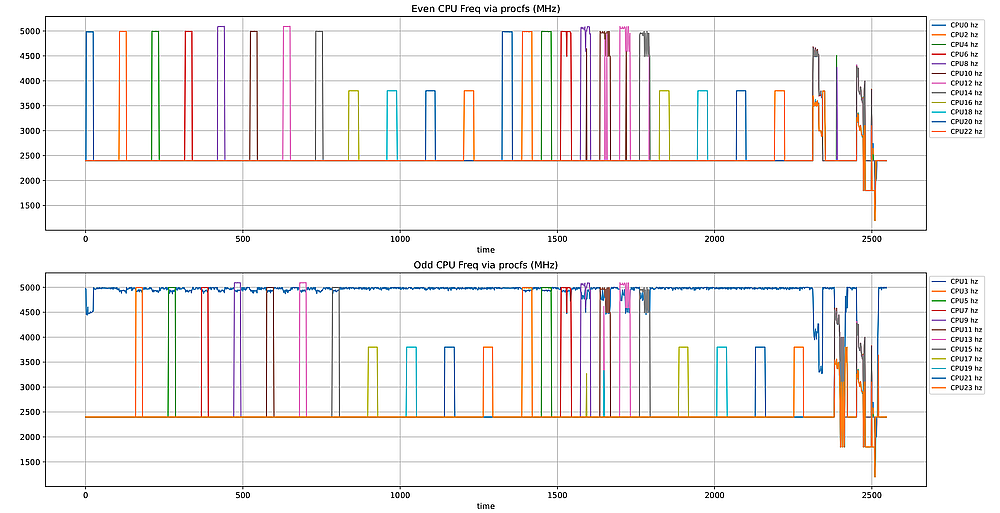
/proc/のほうはもうすこし慣らした値が表示されるようです。よって、sysfsのそれよりはわかりやすいですね。こちらも偶数コアと奇数コアに分けています。
最初の16コアがP-Coreで、次の一段低い8コアがE-Coreです。CPU1はパフォーマンスモニタ等を動かしている都合上、ずっと上に張り付いています。
1300秒から2300秒ぐらいにかけては、同じ物理コアに属する論理コアを同時に動かしています。今回のCPUだとCPU0とCPU1、CPU2とCPU3がそれぞれ同じ物理コアに属する形なので、上下のグラフで同時にピークが来ています。ただしSMTで全力で回すとすぐに高熱になってしまうらしく、1500秒を超えたあたりから周波数が落ちる形になっています。ちなみにE-CoreはSMT非対応なので、1800秒ぐらいから先はシングルコアでのテストと結果は同じです。
また2300秒ぐらいから先の偶数コアだけ・
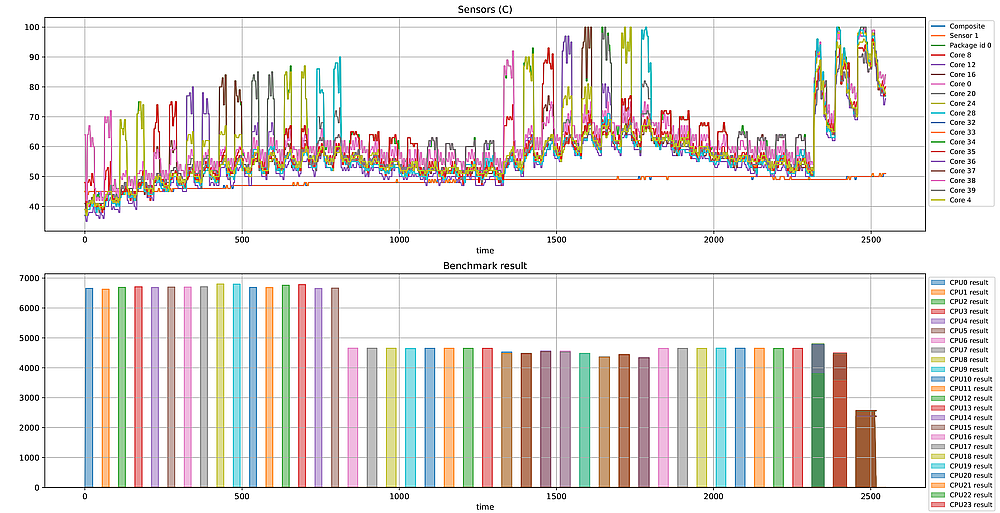
最後はセンサーで取得した温度の結果と、7-Zipのベンチマークスコアです。
P-Coreを全力で回している間はさすがに温度が上昇するもののシングルコア程度ならゆるやかです。またその後のE-Coreのベンチマークの際はほとんど温度があがっていません。むしろ少し前のP-Coreで上昇した分を戻しています。
1300秒ぐらいから2コアずつベンチマークを行う形にしている結果、CPU8とCPU9のベンチマークあたりで100度に到達してしまいました。下段のベンチマークスコアをみてもこのあたりで少し下がっています。というかそもそも2コア同時に実施すると、E-Core単体よりも性能が下がっているみたいですね。
ベンチマークスコアの最後の3本は、次のようなパターンのベンチマークです。
- 偶数コア全部でベンチマークを走らせる
- 奇数コア全部でベンチマークを走らせる
- 全コアでベンチマークを走らせる
前者が2色に分かれているのは、上がP-Coreによるもの、下がE-Coreにるものです。つまりE-Coreもスコアが下がっていることになります。さらに全コア同時だとシングルコアの半分以下の結果です。当たり前の話ではありますが、今回のシステムにおいてCPUの性能を発揮するためには、まずは冷却を頑張らないといけなさそうな雰囲気です[6]。
ただし性能低下は温度だけでは説明できません。今後Alder Lakeの真価を発揮するにはP-Core/