


OpenAIが高精度の音声認識・
WhisperLiveKitは低遅延な文字起こしツール
たとえあなたが比類なきぼっちだったとしても、人間である以上は何らかのコミュニケーションから逃れられません。視覚を使うのか、聴覚なのか、それ以外か。会話重視なのか、それとも文字主体なのか。どのようなコミュニケーション手段を取るかはその人の特性次第な部分があります。この記事を読まれているのであれば、おそらくYouTubeで動画を見るよりも、文字を読んで情報を取得するほうが得意なタイプなのでしょう。
今回紹介するWhisperLiveKitは、誰が喋っているかの判別
Whisperはその精度の高さと利用のお手軽さから登場後もいろいろな人が
さっそくWhisperLiveKitを実際にインストールして使ってみましょう。Python製のツールですので、Pythonの流儀に従ってインストールします。いくつか選択肢はありますが、今回は第850回の
まずは必要なパッケージを先にインストールしておきます。
$ sudo apt install pipx ffmpeg python3-dev
ここでffmpegはWhisperLiveKit内部の音声処理のために使われます。また、python3-devはCUDAを使うために必要です。一応CPUのみでも動きますが、せっかくの低遅延性がほぼ活かせません[2]。よってCUDAが動く環境で試すことをおすすめします。ここではNVIDAのGPUとCUDA環境がインストール済みである前提で進めます。具体的にはUbuntu 24.
次にWhisperLiveKitをインストールしましょう。
$ pipx install whisperlivekit
installed package whisperlivekit 0.2.7, installed using Python 3.12.3
These apps are now globally available
- whisperlivekit-server
done! ✨ 🌟 ✨
ここでは0.
ただしこれだけでは動きません。torchaudioモジュールがないなどのメッセージが出てしまいます。必要なモジュールを追加でインストールしましょう。pipxでインストールしたコマンドは、~/.local/以下にvenv環境が作られます。ここにPythonライブラリを追加でインストールするには、pipx injectコマンドを使います。
$ pipx inject whisperlivekit torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu129 injected package torch into venv whisperlivekit done! ✨ 🌟 ✨ injected package torchvision into venv whisperlivekit done! ✨ 🌟 ✨ injected package torchaudio into venv whisperlivekit done! ✨ 🌟 ✨
ここではPyTorchのダウンロードサイトからCUDA 12.
では、実際にサーバーを起動してみましょう。
$ whisperlivekit-server --model medium --language ja --host 0.0.0.0 INFO: Started server process [402677] INFO: Waiting for application startup. Using cache found in /home/shibata/.cache/torch/hub/snakers4_silero-vad_master WARNING:whisperlivekit.simul_whisper.backend: SimulStreaming backend is dual-licensed: • Non-Commercial Use: PolyForm Noncommercial License 1.0.0. • Commercial Use: Check SimulStreaming README (github.com/ufal/SimulStreaming) for more details. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
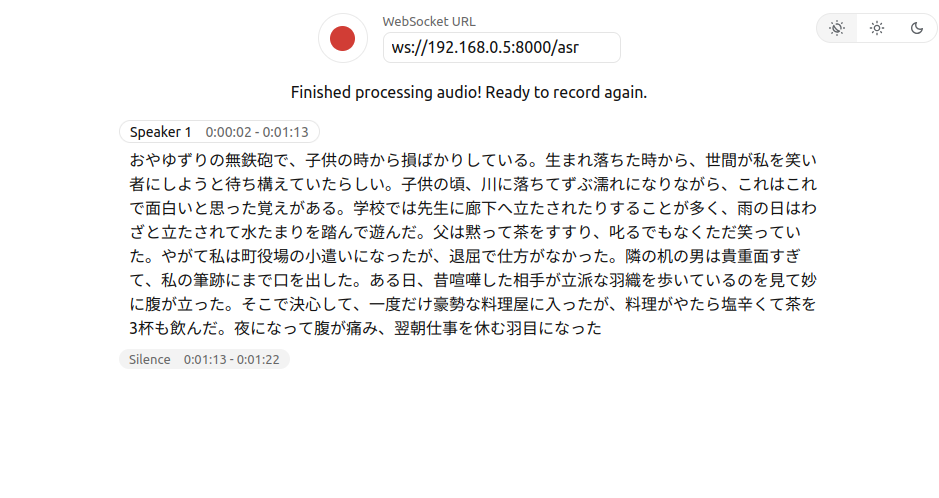
上記のように
WhisperLiveKitをインストールしたマシンのIPアドレスにアクセスしてみましょう。
早速録音ボタンを押したいところですが、まだ準備は完了していません。最近のFirefoxはHTTPS接続でない場合、マイクを使えない設定になっているからです。正しい対処法はWhisperLiveKitをHTTPS対応にすることです。自己署名証明書を作成して、それを取り込んで、whisperlivekit-serverコマンドのオプションで指定するか、Nginxなどのリバースプロキシーを経由することになるでしょう。
ただ、今回はそこまで手間をかけたくないので、Firefox側の設定を変更します。まずFirefoxのアドレスバーからabout:config」
ここで検索バーにmedia.*.insecure.」
media.devices. insecure. enabled media.getusermedia. insecure. enabled
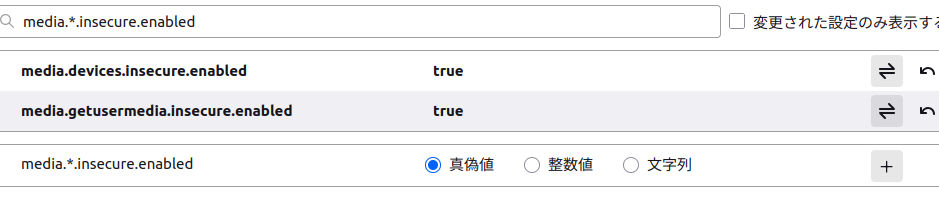
これで準備完了です。なお、この設定はHTTPでもメディアデバイスのリストアップやアクセス可否のダイアログの表示を許容するものです。基本的には
あとは
今回は次のような環境を使いました。
| Machine | MINISFORUM MS-A2 |
| CPU | AMD Ryzen 9 9955HX 16C/ |
| Memory | DDR5-5600 128GiB |
| GPU | RTX A1000 8GiB |
| OS | Ubuntu 24. |
この環境ではlarge-v3はロードできませんでしたが、large-v3-turboやmediumを使えばほぼリアルタイムで変換してくれました。認識率も悪くなかったのですが、たまに文字化けするようです。どうやら音声認識の過程で、生成した文字列を修正するときにUTF-8な日本語文字列をうまく扱えていない印象があります。これは後述する--never-fire」
--never-fireを組み合わせて読み上げた例。音の読み取りという観点だとほぼ完璧に文字起こしできており、漢字への変換もおおよそ期待通りの挙動を示している上記動画の
さらに変換中は
ちなみに実行中のGPU/
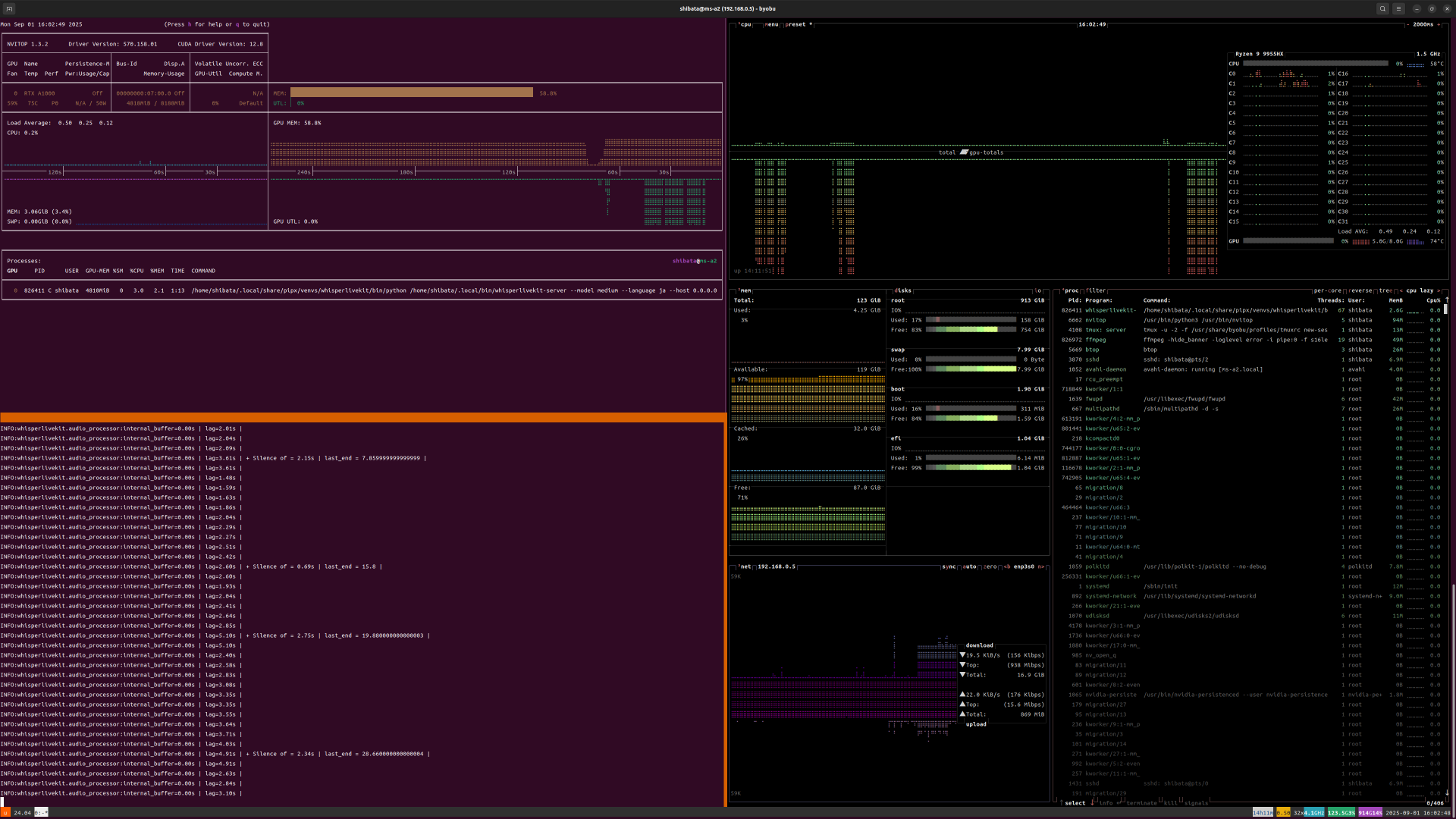
画像をみていただければわかるように、GPUのメモリーは8GiBの半分ぐらいを恒常的に使用しています。CPU側のメモリーはほぼ使用しません。また音声認識時はCPUも1コアだけ負荷が大きく上がるようです。
精度を維持したままより遅延を小さくするという観点だと、GPUメモリーが12GiB以上搭載されており、なおかつ高性能なGPUを使うのが一番となります。
WhisperLiveKitのさまざまなオプション
ここまでだけで、ある程度は使い物になるはずです。ただ、WhisperLiveKitにはさまざまなオプションもあるのでそれも試してみましょう。結論から言うと、そのまま動くものはほとんどなく、環境依存で使えたり使えなかったりするようです。
モデルの選択
音声認識の品質を左右するモデルは--model モデル名」
- tiny: 1GiB程度
- base: 1GiB程度
- small: 2GiB程度
- medium: 5GiB程度
- large-v3-turbo: 6GiB程度
- large-v3: 10GiB程度
GPUメモリーの使用量は、こちらで試してみた体感の数字です。もちろん大きいほうが精度はあがりますが、速度は遅くなります。ただ、mediumとlarge-v3-turboについてはその差は実感できませんでした。
言語の選択
言語の選択は--language 言語コード」autoを書くと自動判定してくれます。こちらで試した限り、autoでは日本語として判定してもらえませんでした。
ネットワーク関連の設定
「--host IPアドレス」--port ポート番号」--host 0.」
「--ssl-certfile」--ssl-keyfile」
音声認識のバックエンドの設定
「--backend バックエンド」
- faster-whisper:OpenAIが開発したオリジナルのWhisperを高速化したもの
- whisper_
timestamped:単語ごとの正確なタイムスタンプをつけるような機能を追加したWhisper - mlx-whisper:AppleのCPU向けに最適化されたバックエンド
- opeai-api:OpenAIのAPIを利用するバックエンド
simultreaming以外はそれぞれ追加でPythonパッケージをインストールする必要があります。詳細はREADME.
冒頭でも触れたように、音声認識の分野はWhisperの登場でがらっと変わった印象があります。Faster Whisperをはじめとして、Whisperベースのいろいろなものが登場しました。今回のWhisperLiveKit以外にもいろいろありますので、探してみると良いでしょう。
特にこだわりがなければ、まずはSimulStreamingをそのまま使うと良いでしょう。ただしこれは
話者検知の設定
「--diarization」
$ pipx inject whisperlivekit "git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]"
ただし今回の環境では複数人で喋ってみたり声色を変えたり、動画を聴かせてみたものの、うまく検知できませんでした。NVIDIA NeMoが結構な量の警告を出しているので、他にも足りないか、何らかのバージョン依存性が存在していた可能性もあります。
その他の設定
他にもいろいろなパラメーターがありますが、代表的なものをあげておきましょう。
- 「
--min-chunk-size」は最小の音声チャンクサイズを秒単位で指定する。小さくするほど負荷はあがるものの、処理が間に合えばレイテンシーは下がる - 「
--frame-threshold」は小さくするほど高速に、大きくするほど正確になるパラメーター - 「
--never-fire」は誤認識でありやすい最後の単語を切り捨てない設定
最後の--never-fire」
音声認識もまた、未来感のある世界
最近のAIと言えば、LLMを活用した画像生成やVibe Coding、AIエージェントなどの話題に事欠きまん。ただし音声認識もまたAI活用事例として有力な存在です。議事録の文字起こしはもちろん、音声入力や聴覚障害者への支援、リアルタイム翻訳など既に応用例も多々あります。うまく実世界と組み合わせれば、きっと未来感のある何かを創り出せるはずです。
WhisperLiveKitも今回のように単独でも使えますが、どちらかというとその低遅延性を活かして、他と組み合わせて応用する方向性と相性が良いでしょう。Webサーバー部分の実装を参考にしながら、ぜひいろんな仕組みに組み込んでみてください。