


今回はベアボーンのMinisforum AI X1 PROにUbuntu 24.
ミニPCでLLM
筆者はこれまで、主にディスクリートGPU
性能は1ランク落ちるものの、Ryzen AI 300シリーズ搭載であればベアボーンモデルもあるAI X1 PROであれば、まだなんとか手に入るので、購入してみました。
AMDのGPUなのでLLMを高速化するフレームワークはROCmとなります。しかしROCmは原則としてiGPUでは動かないことになっています。長らくそんな状態でしたが、せっかくハードウェアとしてのスペックが高いにもかかわらず、それを活かせないのは宝の持ち腐れです。というわけでROCmでもiGPUサポート対応が開発されてきましたが、本記事の執筆時点でその実を結んだのがROCm 6.
モデルはgpt-oss-120bで、今回もllama.
gpt-oss-120bは、少なくとも筆者にとってはあらゆる意味で
ベアボーンからPCへ
筆者が購入したAI X1 PROは前述のとおりベアボーンのため、PCとしては動作しません。メモリーとSSDを取り付ける必要があります。
取り付けの様子を、写真で追ってみましょう。まずは正面の写真が図1です。

USBポートからサイズ感が想像できることでしょうが、ミニPCとしては大きめです。
続いて背面の写真です

左からイヤフォンジャック、ケンジントンロック、USB Aポート、OCulinkポート、USB 4ポート、DPポート、HDMIポート、2.
ネジ穴は裏面にあります

4隅と、上部中央の◯に+のゴムを剥がしたところの5箇所がネジ穴です。ここにあるネジを外します。
するとファンが2つ見えてきます。ここのネジもすべて外します

ようやくメモリーとSSDを取り付けるところにたどり着けました

今回使用したのは、DDR5 SO-DIMM 96GBのCT2K48G56C46S5と、2TB SSDのSSD-CK2.

ヒートシンクはAI X1 PROに付属していたものを使用しています。
Ubuntuのバージョン
インストールしたUbuntuのバージョンは24.

ROCmのインストール
ROCmのインストールはドキュメントにありますが、少々簡略化して紹介します。
$ sudo apt-get install linux-oem-24.04c $ wget wget https://repo.radeon.com/amdgpu-install/6.4.4/ubuntu/noble/amdgpu-install_6.4.60404-1_all.deb $ sudo apt install ./amdgpu-install_6.4.60404-1_all.deb $ sudo amdgpu-install -y --usecase=rocm --no-dkms $ sudo usermod -a -G render,video $LOGNAME
上記のコマンドを一気に実行し、再起動します。最初にlinux-oem-24.をインストールしていますが、意図は不明です。カーネルが新しく
再起動後、ログインしてrocminfoコマンドを実行します。
$ rocminfo ROCk module is loaded (中略) ========== HSA Agents ========== ******* Agent 1 ******* (中略) ******* Agent 2 ******* Name: gfx1150 Uuid: GPU-XX Marketing Name: AMD Radeon Graphics Vendor Name: AMD Feature: KERNEL_DISPATCH Profile: BASE_PROFILE Float Round Mode: NEAR Max Queue Number: 128(0x80) Queue Min Size: 64(0x40) Queue Max Size: 131072(0x20000) Queue Type: MULTI Node: 1 Device Type: GPU (攻略)
デフォルトでは、メモリー総量の半分が、UEFI BIOSのVRAM割当量とは無関係に、iGPUで使用できるように設定されています。これはamd-debug-toolsのamd-ttmコマンドで割当量を変更できます。今回はメモリー総量が96GBなので、80GBほどにしてみましょう。
次のコマンドを実行し、amd-debug-toolsをインストールしてください。
$ sudo apt install pipx $ pipx ensurepath $ pipx install amd-debug-tools
一度端末を終了し、再起動してamd-ttmコマンドを実行すると次のようになります。
$ amd-ttm 💻 Current TTM pages limit: 11793340 pages (44.99 GB) 💻 Total system memory: 89.98 GB
96GBのメモリーを搭載していてもVRAM等に振り分けられているので、実際にメインメモリーとして使用しているのは約90GBであり、そのうち約45GBがTTMとして割り当てられていることがわかります。余談ですが、コマンドの結果に絵文字が出力されるのがなかなかにユニークです。
なおTTMに関しては、のちほどLLMに聞いてみることにします。
では、iGPUで使用するメモリー割当を80GBにしてみましょう。
$ amd-ttm --set 80 (必要に応じてパスワードの入力) 🐧 Successfully set TTM pages limit to 20971520 pages (80.00 GB) 🐧 Configuration written to /etc/modprobe.d/ttm.conf ○ NOTE: You need to reboot for changes to take effect. Would you like to reboot the system now? (y/n):
再起動後、実際の割当が変更されます。
llama.cppのビルドとモデルのダウンロード
llama.
$ sudo apt install -y git cmake g++ libcurlpp-dev $ mkdir ~/git $ cd ~/git $ git clone https://github.com/ggml-org/llama.cpp.git $ cd llama.cpp $ mkdir build $ HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" cmake -S . -B build -DGGML_HIP=ON -DGPU_TARGETS=gfx1151 -DCMAKE_BUILD_TYPE=Release $ cmake --build build --config Release -j 24
モデルはHugging Faceのunsloth/
$ wget https://huggingface.co/unsloth/gpt-oss-120b-GGUF/resolve/main/Q4_K_M/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf https://huggingface.co/unsloth/gpt-oss-120b-GGUF/resolve/main/Q4_K_M/gpt-oss-120b-Q4_K_M-00002-of-00002.gguf
なおダウンロードは~/Downloads/フォルダーにしたこととします。
60GBくらいダウンロードするので、それなりに時間がかかります。
ベンチマークとサーバー起動
すべての準備が整ったので、ベンチマークを実行してみましょう。
$ ./build/bin/llama-bench -m ~/Downloads/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf -ngl 99 --n-cp10 --flash-attn on ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx1150 (0x1150), VMM: no, Wave Size: 32 | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | gpt-oss 120B Q4_K - Medium | 58.45 GiB | 116.83 B | ROCm | 99 | pp512 | 128.09 ± 10.53 | | gpt-oss 120B Q4_K - Medium | 58.45 GiB | 116.83 B | ROCm | 99 | tg128 | 18.54 ± 0.04 |
実際に出力されるのは18.
サーバーとして起動するなら、次のコマンドを参考にしてください。
$ ./build/bin/llama-server -m ~/Downloads/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf --ctx-size 0
--jinja -ub 2048 -b 2048 -ngl 99 --n-cpu-moe 10 --flash-attn on --host 0.0.0.0 --port 8080 --chat-template-kwargs '{"reasoning
_effort": "medium"}' --temp 1.0 --top-p 1.0 --no-mmap
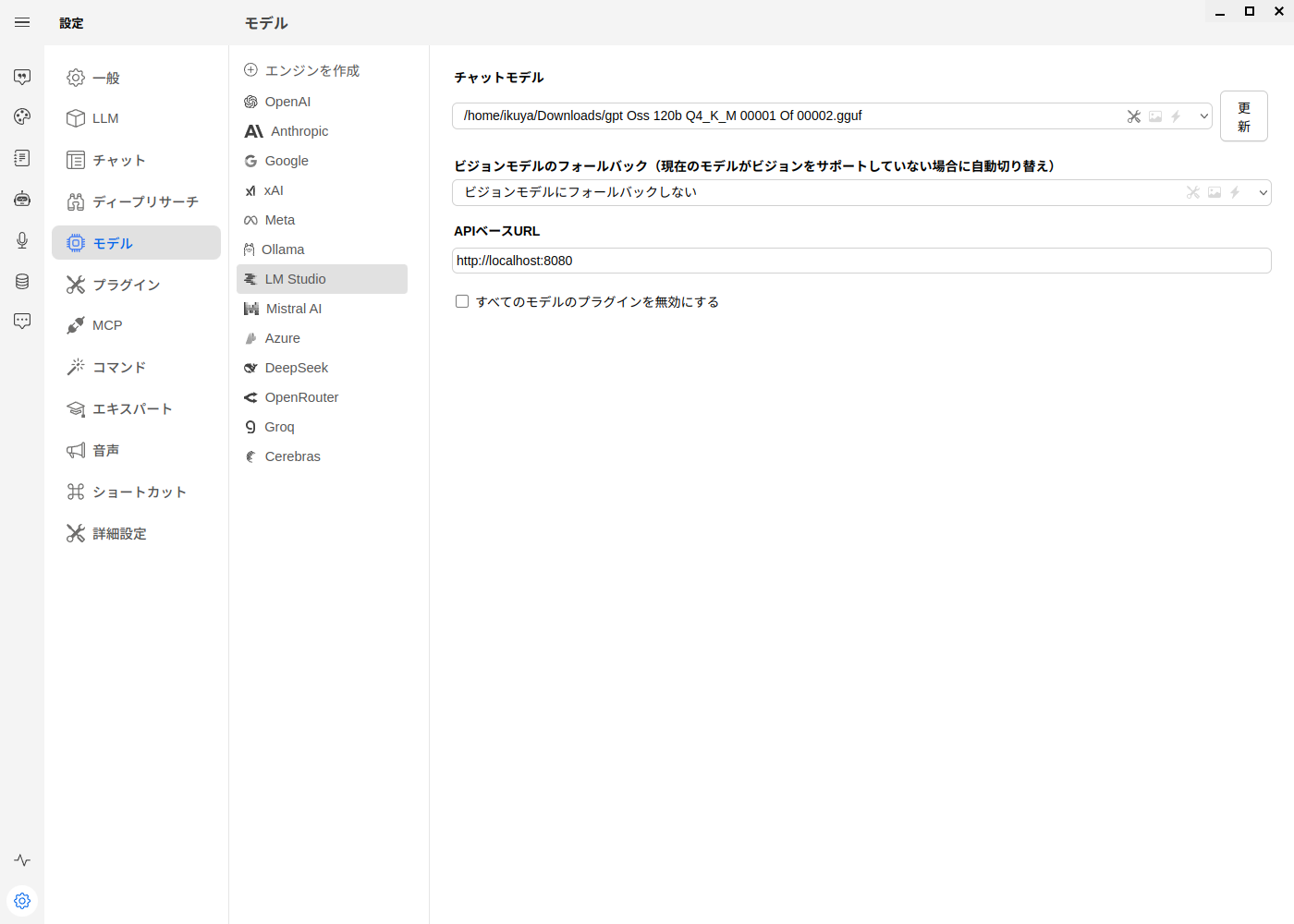
前述のとおり、いい機会なのでTTMについてLLMに聞いてみましょう。フロントエンドはWitsyです。執筆時点で最新版の2.
左下の歯車アイコンから
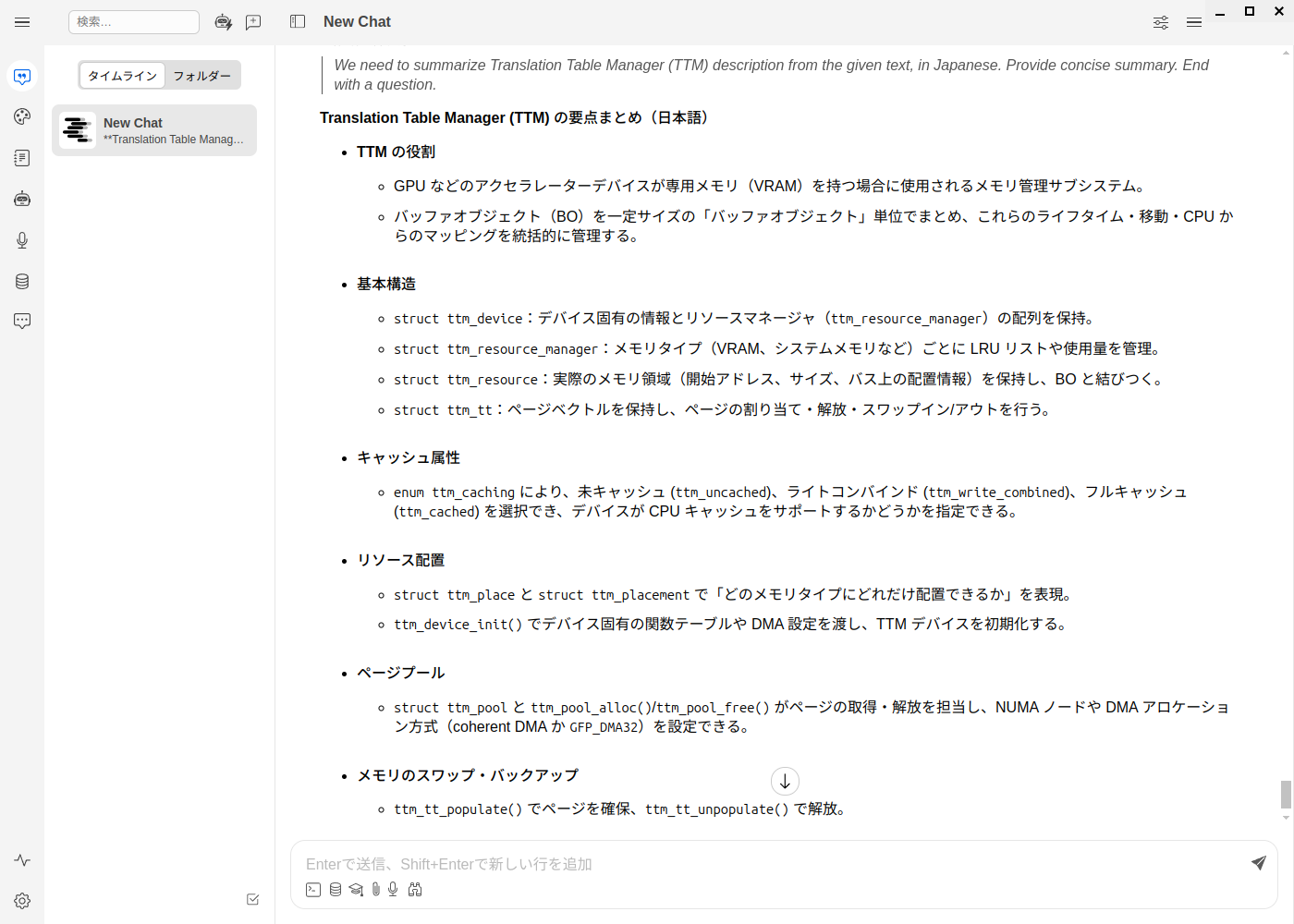
TTLに関する説明は、Linuxカーネルドキュメントの
図9、図10がその結果です。
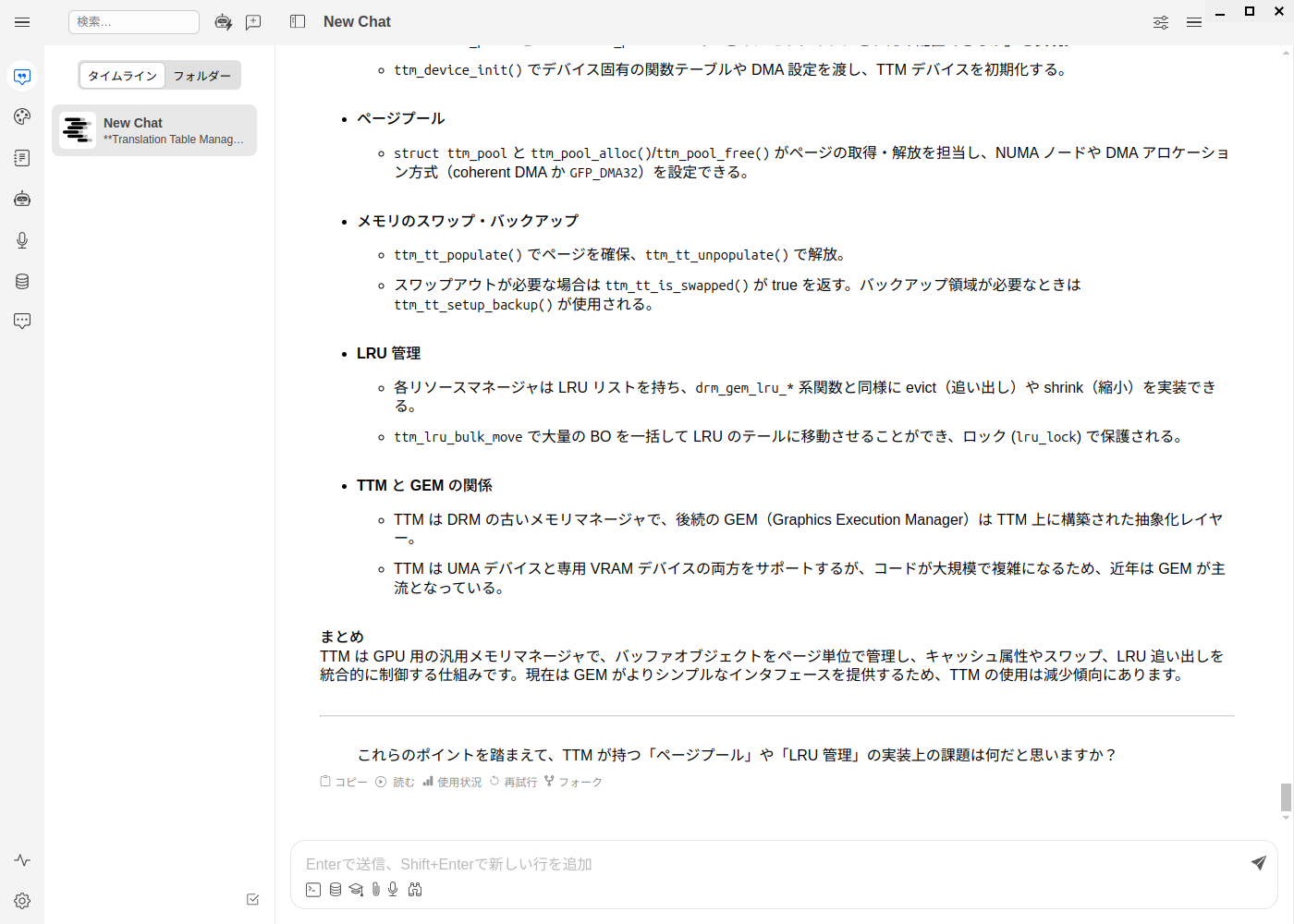
ちなみに筆者はこんなふうにLLMを活用しています。