



本特集は、ヘッドレスChromeの紹介に始まり、PuppeteerのAPIの解説や、実践的なE2Eテストの実現方法を説明してきました。最終章では、これまでに学んだ集大成として、実在するサイトのスクレイピングを行います。具体的には、人気サービス
本章では、画像の読み込みのブロックや無限スクロールへの対応など、実用的なテクニックを紹介していきます。ですがその前に、スクレイピングに関する重要な注意点をお伝えします。
スクレイピングに関する注意点
スクレイピングとは、プログラムを使ってサイトにアクセスし、そのサイトのコンテンツから欲しい情報を引き出す行為です。そのサイトがインターネットに公開されていたとしても、ブラウザではなくプログラムからアクセスしてもよいのか、確認を取る必要があります。
また、複数のページにアクセスする場合は、連続してアクセスすることで、サイトに負荷をかけすぎてしまう恐れもあります。そのため、アクセスの間隔を空けるよう気を付けなければなりません。
そこで、最低限注意すべき利用規約とrobots.
利用規約を守る
サイトによって、プログラムからのアクセスや、抜き出した情報の再利用を利用規約で禁止している場合があります。そのようなサイトに対してスクレイピングを行うと、アクセスがブロックされるだけでなく、プログラムが悪質な場合は、法的に訴えられる可能性もあります。具体例として、Amazonの利用規約には下記の一文が書かれており、スクレイピングは固く禁止されています。
この利用許可には、アマゾンサービスまたはそのコンテンツの転売および商業目的での利用、製品リスト、解説、価格などの収集と利用、アマゾンサービスまたはそのコンテンツの二次的利用、第三者のために行うアカウント情報のダウンロードとコピーやそのほかの利用、データマイニング、ロボットなどのデータ収集・
抽出ツールの使用は、一切含まれません。
そのほか、Facebookの利用規約でも、スクレイピングを禁止する項目が書かれています。
弊社から事前の許可を得ることなく、自動化された手段を用いて製品のデータにアクセスしたり取得したりすることや、アクセス許可のないデータへのアクセスを試みることを禁止します。
スクレイピングを行うサイトについては、同様の利用規約が書かれていないか、必ず事前に確認しなければなりません。noteの利用規約については後述します。
robots.txtを守る
robots.
| サイト名 | robots. |
|---|---|
| https:// |
|
| Amazon | https:// |
| https:// |
|
| Apple | https:// |
たとえば、URLのパスが
# 対象となるプログラムのユーザーエージェント
User-agent: *
# アクセスを禁止するURLのパス
Disallow: /mypage
# アクセスを許可するパス
Allow: /
この例では、User-agent: *となっているので、すべてのユーザーエージェントに対しての指示になっています。DisallowとAllowの両方が適用されるURLの場合は、より限定的に指定されているほうが優先されます。先ほどの例では、
実在するサイトの具体例
より理解を深めるために、実在するサイトの具体例を見てみましょう。Googleのrobots.
User-agent: *
Disallow: /search
Googleの検索結果ページのパスは、
次に、今回スクレイピングを行うnoteのrobots.
User-agent: *
Disallow: /*/message
Disallow: /*/terms/specified
Disallow: /*/menu/*
Disallow: /admin/*
Disallow: /_nourlname*
Disallow: /settings/*
Disallow: /library/*
スクレイピング対象のタイムラインのパスは
なお、robots.
ユーザーエージェントを指定する
スクレイピングを行う場合は、ユーザーエージェントに連絡先を入れることをお勧めします。そうすることで、万が一サイト管理者が異常を検知した場合に、スクレイピングを行った開発者と連絡をとることが可能になります。連絡先には、URLやメールアドレスを書くとよいでしょう。
たとえば、Googleのクローラhttp://というURLが含まれています。このURLにアクセスすると、Googleクローラの説明記事が掲載されています。なお、Googleクローラの完全なユーザーエージェントは下記のとおりです。
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Puppeteerを使った指定方法
Puppeteerでユーザーエージェントを指定するためには、page.を使用します。下記のコードでは、メールアドレスを含むユーザーエージェントを指定したあとに、サイトにアクセスしています。なお、ユーザーエージェントに含まれる
// ユーザーエージェントを指定する
await page.setUserAgent(
'WDB109 Puppeteer (自分のメールアドレス)'
);
// サイトにアクセスする
await page.goto('https://example.com');
このように、ユーザーエージェントの指定は、必ずサイトにアクセスする前に実行してください。そうしないと、最初のページに対して、デフォルトのユーザーエージェントでアクセスしてしまいます。
デフォルトのユーザーエージェント
デフォルトのユーザーエージェントは、ヘッドレスモードで起動しているか否かによって異なります。ヘッド
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/72.0.3617.0 Safari/537.36
人気サービス「note」とは
本章では、誰でも文章、写真、音楽、動画などのコンテンツを投稿できるWebサービスnoteのスクレイピングを行います。noteに投稿したコンテンツは、ブログやSNS
本特集を執筆するにあたり、noteの運営元であるピースオブケイクに問い合わせたところ、スクレイピングの題材として使用することを快諾していただきました。
掲載コードに関する注意点
本章の掲載コードは、noteの利用規約およびrobots.
また、今後サイトリニューアルなどによって、プログラムが動作しなくなる可能性もあります。その場合は、本特集で学んだことを応用し、適宜コードの修正を行ってください。
スクレイピングの目的
本章の目的は、noteのタイムラインをスクレイピングし、最新の20件のノートを取得することです。タイムラインとは、ログイン後noteを開いたときに最初に表示されるページを指します。このページでは、自分がフォローしているユーザーやマガジンのノートが、新着順に表示されます。なお、ブログと比較すると、ノートは一つ一つの記事、マガジンは記事のカテゴリのようなものだと考えて差し支えはないでしょう。
筆者は普段からnoteを利用していますが、自分だけのタイムラインをチャットツールに連携したいと考えていました。しかし、noteのタイムラインは執筆時点ではSPAになっており、スクレイピングを行うためにはブラウザの自動化が不可欠です。そこで、チャットツールとの連携は本特集のテーマから外れるため扱いませんが、noteのタイムラインをスクレイピングの題材として選択しました。
アカウントの登録
noteで自分だけのタイムラインを表示するためには、ログインするためのアカウントが必要です。アカウントは一度登録するだけなので、自動化する必要はありません。まだアカウントを持っていない方は、通常のブラウザで新規登録ページを開き、案内に従って登録を完了してください
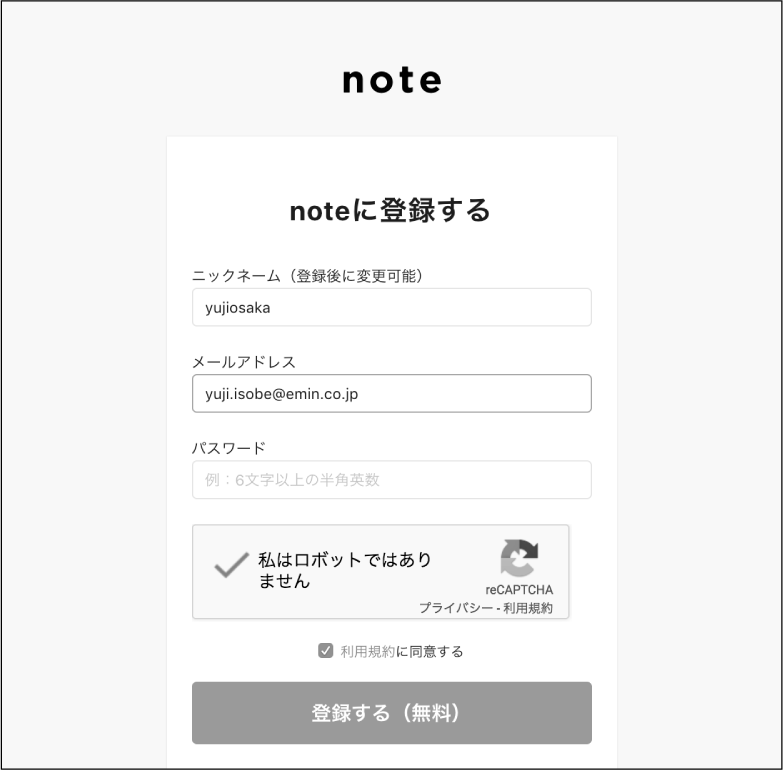
なお、登録に使用したメールアドレスおよびパスワードはログインの自動化で使用するため、控えておく必要があります。
スクレイピングの流れ
アカウントの登録が完了したら、さっそくスクレイピングの流れを見ていきましょう。今回は、noteのログイン後に表示されるタイムラインから、最新の20件のノートを取得するまでを解説します。
セットアップ
まずはじめに、基本的なセットアップを開始します。手順はこれまでと変わらず、適当なディレクトリを作成し、そのディレクトリ内でインストールコマンドを実行するだけです。
$ npm init -y
$ npm install --save puppeteer@1.11.0
基本のプログラムを保存する
次に、先ほど作成したディレクトリ直下に、index.
// ライブラリを読み込む
const puppeteer = require('puppeteer');
(async () => {
const options = process.env.DEBUG
? {devtools: true} // デバッグ実行時のオプション
: {}; // 通常時のオプション
// ブラウザを立ち上げる
const browser = await puppeteer.launch(options);
// ブラウザのタブを開く
const page = await browser.newPage();
// ユーザーエージェントを指定する
await page.setUserAgent(
`WDB109 Puppeteer (${process.env.NOTE_EMAIL})`
);
// ログインフォームにアクセスする
await page.goto('https://note.mu/login');
// デバッグを開始する
await page.evaluate(() => { debugger; });
// ブラウザを閉じる
await browser.close();
})();
プログラムの内容は、noteのログインフォームでデバッグを開始するだけの単純なものです。ほとんどが第3章までに学んだ内容ですが、本章で学んだばかりのpage.を使ったユーザーエージェントの指定も行われています。
今回は2ヵ所で環境変数にアクセスしています。1ヵ所は起動オプションの切り替えで、もう1ヵ所はユーザーエージェントに含まれるメールアドレスです。DEBUGを使ってデバッグ実行を行うのは、毎回起動オプションを変更する手間を省くためです。
一方、NOTE_を通じてメールアドスを受け渡すのは、プログラムが漏洩したときに、メールアドレスが悪用されるリスクを防ぐためです。また、この環境変数は、のちほどnoteのログインにも使用します。
プログラムを実行する
実際に下記コマンドを実行し、コードが問題なく動作することを確認しましょう。
$ DEBUG=true \ NOTE_EMAIL=登録したメールアドレス \ node index.js
> set DEBUG=true > set NOTE_EMAIL=登録したメールアドレス > node index.js
すると、noteのログインフォームが表示されたところで、JavaScriptの実行が一時停止されます
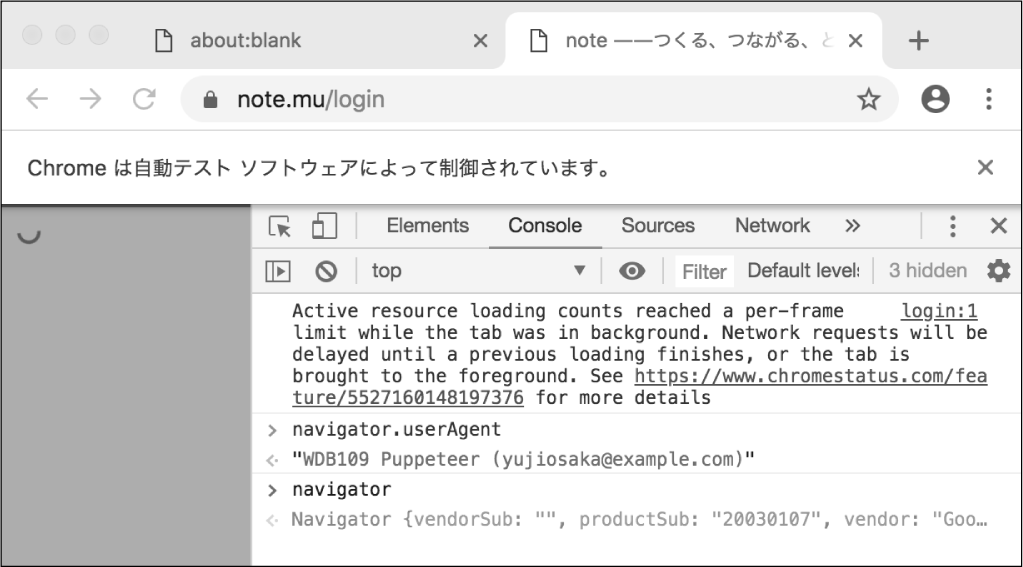
// ユーザーエージェントを確認する
navigator.userAgent
ユーザーエージェントが問題なく書き換わっていれば、デバッグ実行を終了し、このプログラムを終了してください。
画像の読み込みをブロックする
ブラウザを自動化してスクレイピングする場合、必要のないファイルのダウンロードに時間がかかってしまう場合があります。今回のスクレイピングでは、タイムラインを動的に生成するためにJavaScriptを読み込む必要はありますが、画像ファイルを読み込む必要はありません。
そのような場合は、page.を用いて不要なリクエストをブロックすることが効果的です。このメソッドの引数にtrueを渡して実行すると、requestイベントを受け取ったときに、request.、request.およびrequest.の3つのメソッドが有効化されます。
requestイベントは、下記のコードで受け取ることができます。
// リクエストのフィルタリングを有効化する
await page.setRequestInterception(true);
// リクエストイベントを受け取る
page.on('request', request => {
// さまざまな処理を行う
// ...
});
リクエストを書き換える
先ほど有効化されたメソッドを用いることで、リクエストを許可したり、中断するだけでなく、もとのリクエストやレスポンスを書き換えることも可能になります。
// リクエストを許可する
request.continue();
// リクエストをブロックする
request.abort();
// リクエストを書き換える
request.continue({
// ボディの上書き
postData: { foo: 'bar },
// ヘッダの上書き
headers: { origin: 'https://note.mu/login' },
});
// レスポンスを書き換える
request.respond({
// ステータスコードの上書き
status: 404,
// コンテンツタイプの上書き
contentType: 'text/plain',
// ボディの上書き
body: 'Not Found!',
});
この機能を用いて、テスト用のサーバをモックしたり、特定のアクセス解析ツールへのリクエストをブロックすることにも応用できます。下記のプログラムは、request.メソッドを使ってコンテンツタイプを判定し、画像ファイルへのリクエストだけをブロックするコードになっています。
await page.setRequestInterception(true);
page.on('request', request => {
if (request.resourceType() === 'image') {
// リクエストをブロックする
request.abort();
} else {
// リクエストを許可する
request.continue();
}
});
このプログラムのポイントは、page.と同じように、page.よりも先に実行することです。そうすることで、最初にアクセスするページから、リクエストを書き換えることができます。
プログラムを実行する
実際に、このコードをpage.の直前に埋め込んで、再びプログラムを実行してみましょう。
すると、気が付きにくいかもしれませんが、noteのロゴが読み込まれないようになっていることがわかります
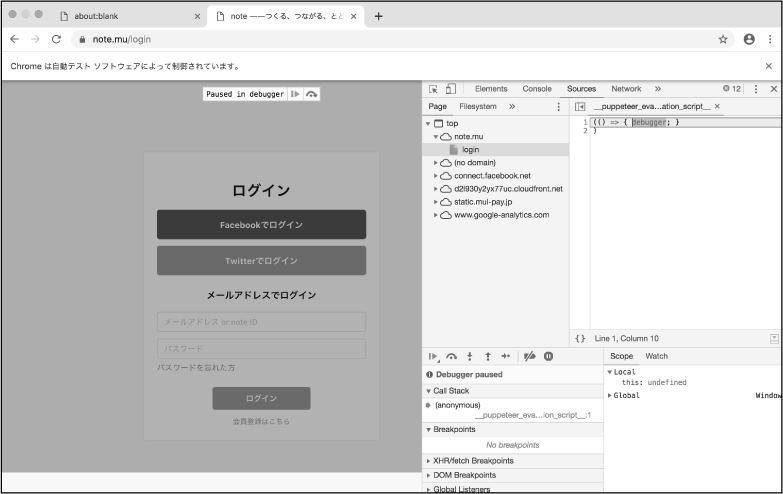
ログインフォームに入力する
次に、ログインを実行します。ログインするアカウントは、事前に登録したものを使用します。フォームの送信に必要なコードは、第3章までに学んだとおりです。
環境変数にアクセスする
コード中にパスワードを直接書き込んでしまうと、コードが漏洩したときにセキュリティ事故につながる恐れがあります。そこでメールアドレスと同じように、環境変数を通じてパスワードをプログラムに渡しましょう。
// メールアドレスを入力する
await page.type(
'input[name=login]',
process.env.NOTE_EMAIL
);
// 環境変数を使ってパスワードを入力する
await page.type(
'input[name=password]',
process.env.NOTE_PASSWORD
);
// 複数の非同期処理を並列で実行する
await Promise.all([
// タイムラインが表示されるまで待機する
page.waitFor('.feed'),
// ログインする
page.click('button')
]);
なお、タイムライン上の一つ一つのノートは、page.を使って、ログインが完了してタイムラインが表示されるまで待機するコードになっています。
プログラムを実行する
先ほどのコードを、page.の直下に加えて保存します。次に、実行時のコマンドに、NOTE_の環境変数を加えて実行しましょう。
$ DEBUG=true \ NOTE_EMAIL=登録したメールアドレス \ NOTE_PASSWORD=登録したパスワード \ node index.js
> set DEBUG=true > set NOTE_EMAIL=登録したメールアドレス > set NOTE_PASSWORD=登録したパスワード > node index.js
ログイン後タイムラインが表示され、デバッグモードが開始されれば、次のステップに進むことができます。
無限スクロールに対応する
それでは、いったいどのような状態でJavaScriptの実行が一時停止されているでしょうか。画面を見てみると、たしかにタイムラインにノート一覧が表示されていることがわかります
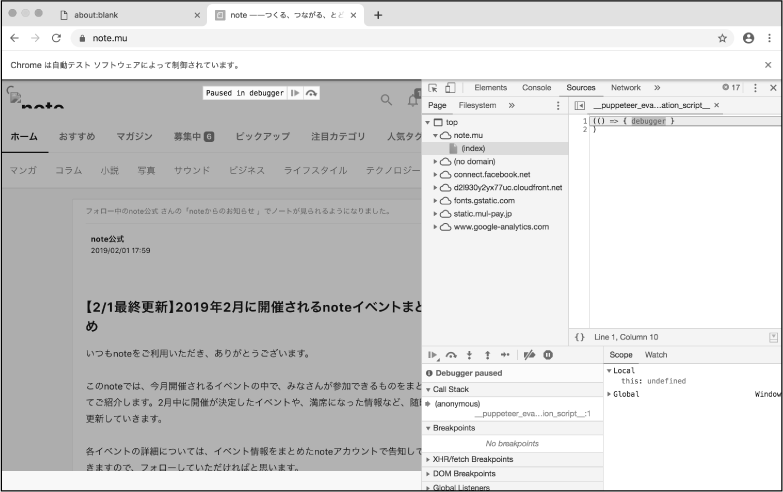
この状態で、目的であった最新の20件のノートが表示されているか確かめてみましょう。
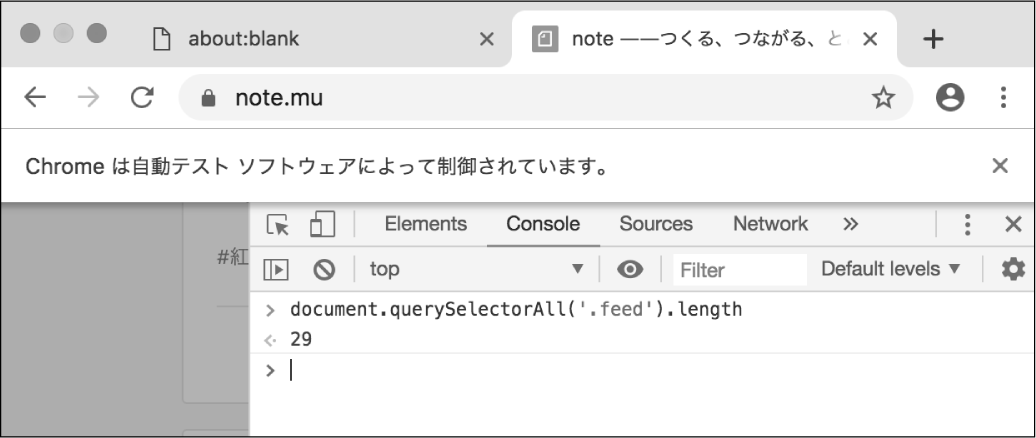
下記のコードを、デベロッパーツールのコンソールに入力して実行します。
// ノートの件数を取得する
document.querySelectorAll('.feed').length
すると、JavaScriptの実行結果が10であることがわかりました。このことは、最新の10件までのノートしか表示されていないことを意味します。これは、noteのタイムラインが無限スクロール
ブラウザは、一度にすべてのコンテンツを読み込んでしまうと、画面の描画に時間がかかりすぎてしまいます。無限スクロールとは、このような問題を回避するために、画面をスクロールするたびに少しずつコンテンツを読み込む手法です。
画面下部までスクロールする
この無限スクロールに対応して20件以上のノートを表示するためには、画面下部までスクロールし、新しくノートが表示されるまで待機する必要があります。
ブラウザ上で条件を満たすまで待機するメソッドは、page.でした。このメソッドを使って、20件以上のノートが表示されるまで待機するコードは、下記のようになります。
// ブラウザ上で関数を実行し、trueが返るまで待機する
await page.waitFor(() => {
// ノートの件数が20件以上かチェック
const notes = document.querySelectorAll('.feed');
return notes.length >= 20;
});
ブラウザ上で実行されるJavaScriptに、画面の下部までスクロールするためのwindow.を組み合わせます。
すると、下記のようなコードができあがります。
await page.waitFor(() => {
// 画面下部までスクロールする
window.scrollTo(0, document.body.scrollHeight);
const notes = document.querySelectorAll('.feed');
return notes.length >= 20;
});
プログラムを実行する
このコードを、先ほどのログインコードの下に追記して実行してみましょう。すると、ノートの件数をチェックするJavaScriptがブラウザ上で実行されるたびに、画面下部にスクロールされるようになりました。
以上で、無限スクロールに対応できました。実際にコードが動いているか、再びプログラムを実行して確かめてみましょう。コンソールでノートの件数を取得し、20以上の数値が得られれば成功です
タイムラインからタイトルとURLを取得する
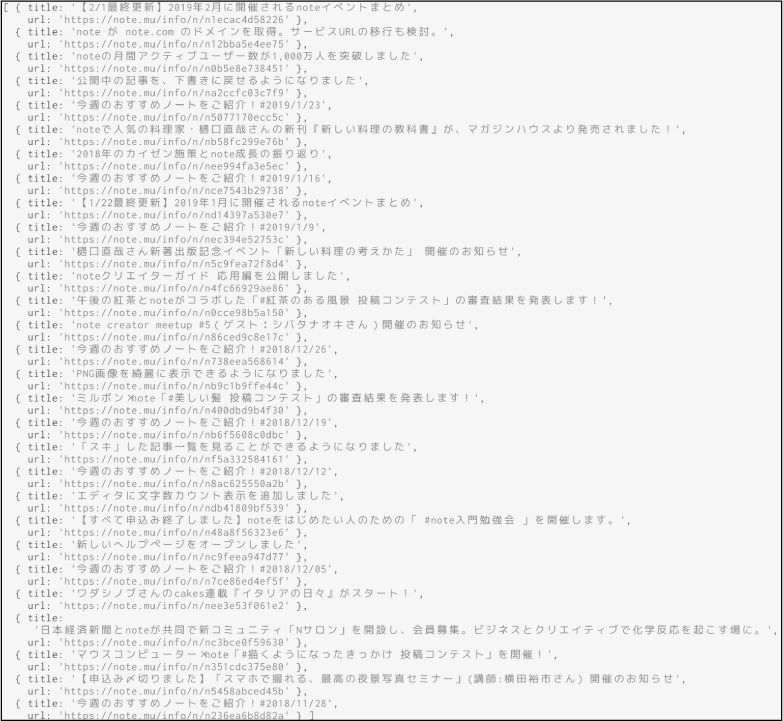
最後にブラウザ上でJavaScriptを実行し、表示されているノートのタイトルとURLの一覧を取得します。結果は、page.$$eval()メソッドを用いて、下記のコードで受け取ることができます。
// ノートのタイトルとURLの一覧を受け取る
const query = '.renewal-p-cardItem__title a';
const notes = await page.$$eval(query, anchors =>
anchors.map(anchor => ({
title: anchor.innerText,
url: anchor.href
}))
);
// ログに出力する
console.log(notes);
このコードを、先ほどまでデバッグに用いていたawait page.の代わりに置き換えて保存します。これ以上デバッグは必要ないので、DEBUGの環境変数を渡さずにプログラムを実行します。すると、図7のような配列がログに出力されるはずです。
以上で、noteのタイムラインをスクレイピングし、最新の20件のノートを取得するプログラムが完成しました。
最終的なプログラム
最終的には、下記のようなプログラムが完成しているはずです。プログラム中では、ユーザーエージェントの指定、画像のブロック、無限スクロールへの対応など、実践的なテクニックが数多く使われています。また、本特集では扱いませんが、取得したノート一覧をログに出力するだけでなく、Slackのようなチャットツールに流し込むことで、より実用的なコードにできるでしょう。
// ライブラリを読み込む
const puppeteer = require('puppeteer');
(async () => {
const options = process.env.DEBUG
? {devtools: true} // デバッグ実行時のオプション
: {}; // 通常時のオプション
// ブラウザを立ち上げる
const browser = await puppeteer.launch(options);
// ブラウザのタブを開く
const page = await browser.newPage();
// ユーザーエージェントを指定する
await page.setUserAgent(
`WDB109 Puppeteer (${process.env.NOTE_EMAIL})`
);
// リクエストのフィルタリングを有効化する
await page.setRequestInterception(true);
// リクエストイベントを受け取る
page.on('request', request => {
if (request.resourceType() === 'image') {
// リクエストをブロックする
request.abort();
} else {
// リクエストを許可する
request.continue();
}
});
// ログインフォームにアクセスする
await page.goto('https://note.mu/login');
// メールアドレスを入力する
await page.type(
'input[name=login]',
process.env.NOTE_EMAIL
);
// 環境変数を使ってパスワードを入力する
await page.type(
'input[name=password]',
process.env.NOTE_PASSWORD
);
// 複数の非同期処理を並列で実行する
await Promise.all([
// タイムラインが表示されるまで待機する
page.waitFor('.feed'),
// ログインする
page.click('button')
]);
// ブラウザ上で関数を実行し、trueが返るまで待機する
await page.waitFor(() => {
// 画面下部までスクロールする
window.scrollTo(0, document.body.scrollHeight);
// ノートの件数が20件以上かチェック
const notes = document.querySelectorAll('.feed');
return notes.length >= 20;
});
// ノートのタイトルとURLの一覧を受け取る
const query = '.renewal-p-cardItem__title a';
const notes = await page.$$eval(query, anchors =>
anchors.map(anchor => ({
title: anchor.innerText,
url: anchor.href
}))
);
// ログに出力する
console.log(notes);
// ブラウザを閉じる
await browser.close();
})();
特集のおわりに
いかがだったでしょうか。本特集の前半では、ヘッドレスChromeとPuppeteerの紹介から、JavaScriptの構文やPuppeteerのAPIのような基本的な解説をしました。そして後半では、E2Eテストや実在するサービスのスクレイピングなど、実践的なプログラムを解説しました。
実のところ、本特集だけではPuppeteerの豊富な機能のほんの一部しか紹介できていません。それでも、ヘッドレスChromeを簡単に自動化でき、多くの分野に適用できる可能性に満ち溢れたツールであることが、少しでも伝わっていれば幸いです。
今後みなさんがPuppeteerを使って、快適なブラウザ自動化を行うことを願っています。