


皆さんは、異なるDB間でのデータコピーを行う際にどういう方法を使うでしょうか? まるっと全部コピーするのであれば第127回 CLONEプラグインを導入しようで紹介したcloneプラグインを使ったり、レプリケーションを使ったりします。またバックアップを使う方法なら第153回 mysqlpumpを使ってバックアップを取ってみるで紹介したmysqlpumpや、第59回 Percona XtraBackupを使ってみようで取り上げたxtrabackup、第168回と第171回で紹介したMyDumperを使ったりと、データベースを丸ごとコピーするためのさまざまな方法を、この連載では紹介してきました。改めて振り返ってみると、いろいろな方法があるなとびっくりしますね。
ただ、丸ごとではなく部分的に、しかも抽出を行ごとではなく、列ごとに取捨選択をしながらコピーしたい場合には、上記に挙げたような方法ではうまくいかない場合もあります。今回は、そんな時に知っておくとちょっとだけ便利なMySQL Workbenchの機能を紹介していきます。MySQL Workbenchのexport機能を便利に使用して、SELECTした結果をSQLにする方法を試していきましょう。
検証環境
今回はdockerで建てたMySQLを使用します。以下のコマンドでdockerを建てて、ローカルからアクセスをします。
% docker run --platform linux/x86_64 -p 3307:3306 -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:latest % mysql -uroot -pmy-secret-pw -P3307 -h127.0.0.1
執筆時点では、以下の通りMySQL 8.
mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.31 | +-----------+ 1 row in set (0.01 sec)
ここに、今回はusersテーブルを作って確認をしてみようと思います。
mysql> CREATE DATABASE test; mysql> use test; mysql> CREATE TABLE users(id SERIAL, name TEXT);
このテーブルにデータを2件入れておきましょう。
mysql> INSERT INTO users(name) VALUES('kimura'),('kk2170');
mysql> select * from users;
+----+--------+
| id | name |
+----+--------+
| 1 | kimura |
| 2 | kk2170 |
+----+--------+
2 rows in set (0.00 sec)
MySQL Workbenchを使ってみる
MySQL Workbenchは、第13回MySQL Workbenchを使ってER図を編集するでも紹介させていただいた、MySQLのクライアントツールです。GUIで操作することができたり、MySQLの管理や開発に便利な機能がいろいろと備わっています。今回はインストールに関しての詳細は省かせていただきます。
MySQL WorkbenchでSQLを実行する
それでは、まずはMySQL WorkbenchでMySQLに接続して見ましょう。起動画面は以下の通りです。
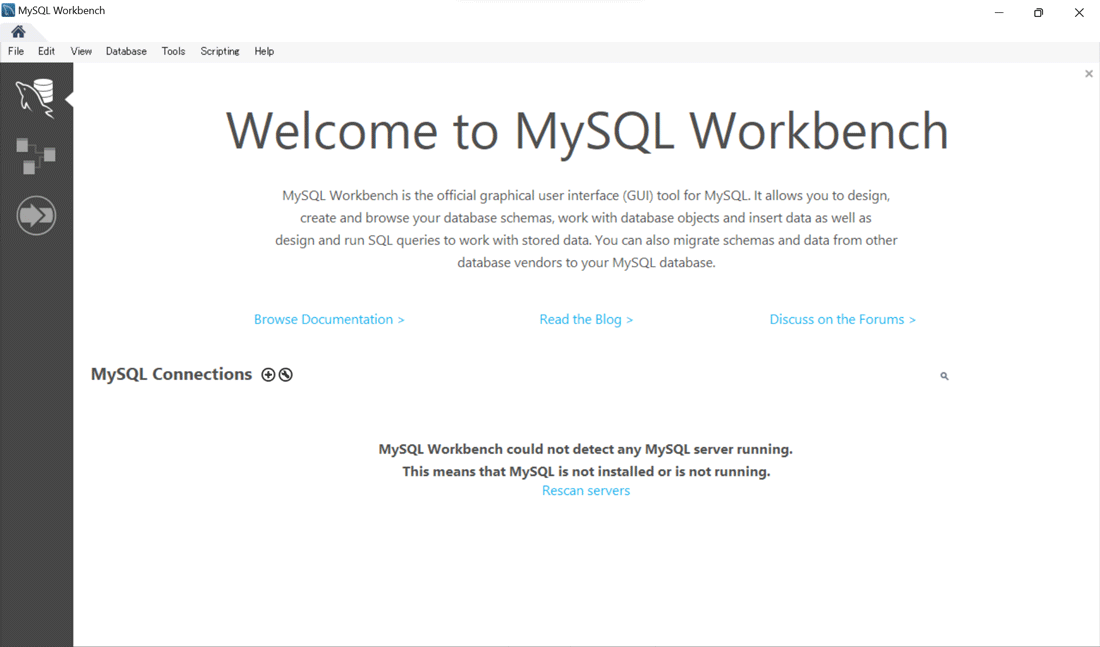
ではまず、メニューバーの
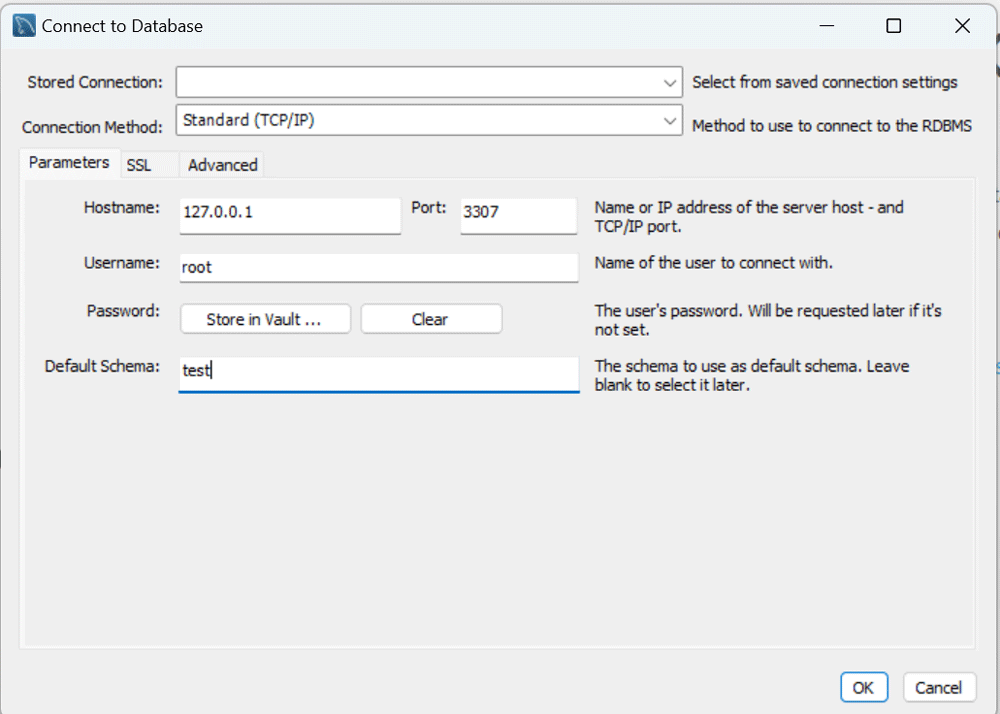
「Store in Vault ...」
そのあとにokを押すと以下のような画面が開きます。これで準備完了です。
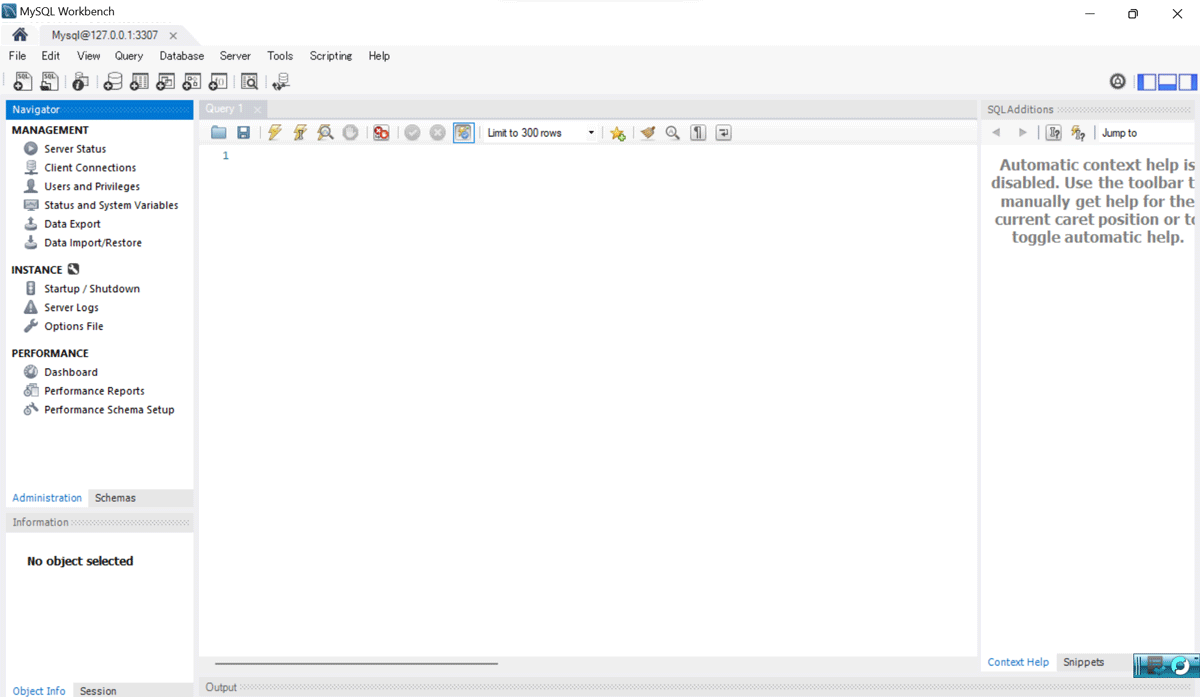
SQLを生成してみる
大仰なタイトルを付けてみましたが、あまり難しいことは行いません。まずは、queryウィンドウにSELECT文を入力してみましょう。
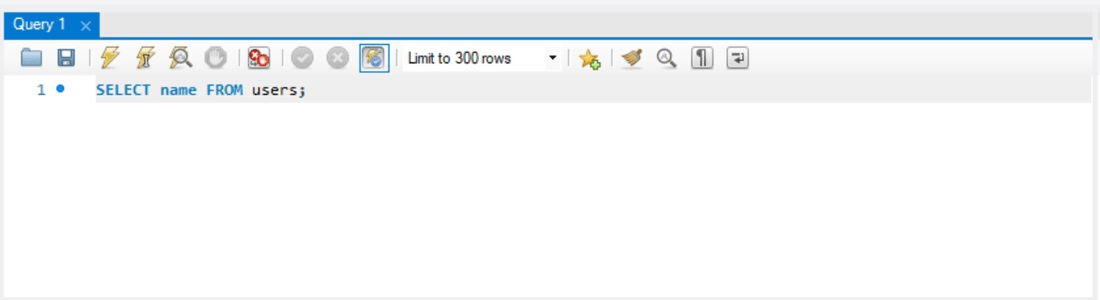
これを実行するには雷のアイコンのボタンを押します。雷のアイコンは3個あり、左は複数行のSQLを書いた場合は全行実行されます。真ん中のものはカーソルが当たった行のみを実行します。右側はカーソルが当たった行のexplainを取得します。

しばらくすると以下の様に実行結果が表示されます。
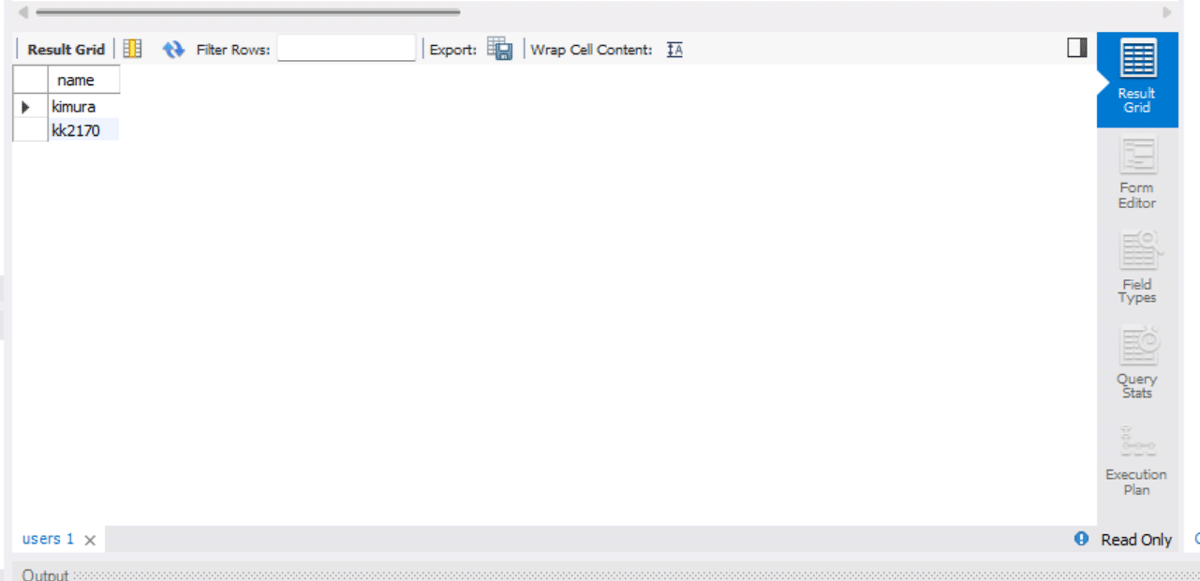
ではここから出力してみましょう。と言っても結果のウィンドウのメニューからexportを選択するだけです。
exportを選択すると、SQLだけではなくてCSVやXMLなど複数の形式が出力できることがわかります。必要に応じて簡単に必要なデータをEXPORTできるのが、MySQL Workbenchの本当に優れている所だと思います。
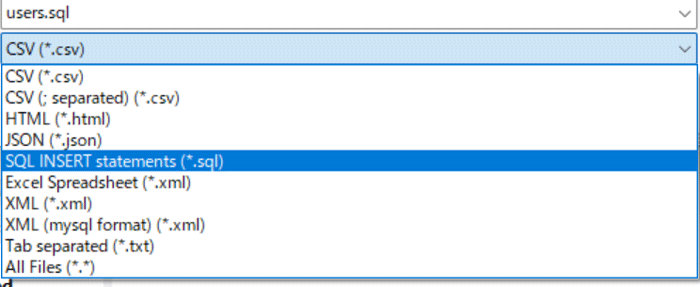
SQLを選択するとテーブル名を選択するウィンドウが表示されるので、テーブル名を入力します。
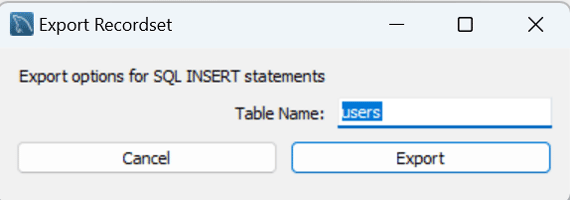
これで完了です。
生成されたSQLを見てみる
生成されたSQLの中身を確認してみましょう。一見INSERT INTO文が正しく生成されているように見えますが、このまま実行するとエラーになってしまいます。
/*
-- Query: SELECT name FROM users
LIMIT 0, 300
-- Date: 2022-11-25 11:54
*/
INSERT INTO `` (`name`) VALUES ('kimura');
INSERT INTO `` (`name`) VALUES ('kk2170');
実は現在のバージョンのMySQL Workbenchのexport機能で生成したSQLには、テーブル指定が通らないバグが存在しています。なのでこの機能を利用する際には、一旦SQLを出力してinsertのSQLにテーブル名を手で入れてあげてください。
この問題はすでにMySQL Bugs #95275で報告されているので、ちょっと困ったなと思った方は、affect meを押してあげてください。
この機能の何が嬉しいか
さて、この機能ですが、一番うれしいのはカラムを自由に選択してexportできるという点になります。本番サーバに投入するためのデータを他のDBで作った場合に、そのデータを吸い上げて入れたいと考えることもあるかもしれません。そんな場合に、まず考えるのはmysqlpumpなどを使って必要なデータをwhere句を使って絞り込むことかもしれません。しかし、Auto IncrementでユニークなIDなどが設定されていると、出力したSQLをそのまま別のDBに移し替えようとするとキーが衝突してしまい、できない場合があります。
そんな時に、idだけ除外してSQLを作りたいといったことはありませんか? LOAD DATA INFILE構文を使えば、mysqlコマンドラインクライアントから出力したCSVからデータを投入することもできますが、FILE権限が必要ですし、サーバを直接触れるようにする必要もあります。
それに比べると、SQLとして取得することができれば、最悪アプリケーションとしての権限があれば実行できますし、SQLとしてアプリケーションから実行することもできます。それならCSVからデータをimportするプログラムを書けばいいんじゃ?
まとめ
今回は、MySQL Workbenchを使ってSELECTした結果をSQLに変換してみました。SELECTした結果をそのままSQLにしたいというワークロードはあまりないようで、発生した場合にどうしたらいいか悩んでしまうこともあると思います。そういった場合に、バグが一部あるものの、MySQL Workbenchを使うとGUIからSQLを簡単に出力できるので、利用してみてはいかがでしょうか。
また、こういうバグに引っかかった際にはぜひともMySQL-Bugsを調べてみて、もし誰かが先にレポートしていたら、affect meを押しましょう。