



こんにちは、Amazon Web Services Japan ソリューションアーキテクトの榎本です。本連載の第1回ではデータ活用の全体像について解説しました。第2回は分析の前準備である
データ分析を快適に進めるためのポイント
データ分析を快適に進めるための重要なポイントは、データが検索できること、発見が容易であること、データに対していつでもどこからでもアクセスができることです。
しかしながら、最初から分析に特化した環境が用意されていることは稀です。多くの場合、データ分析を始めるにあたり、以下のような様々な問題に直面することでしょう。
- データの取得に手間がかかっている
-
- ログファイルは各サーバー上に置かれており、都度ダウンロードしている
- ファイルサーバー上のファイルは、共有ファイルシステムや共有ボリュームをマウントしているサーバー経由でデータを取り出している
- SaaSなどの外部サービスからデータを取得するにあたり、APIを何度も実行する必要がある
- セキュリティ上の理由によりデータへのアクセスが制限されている
-
- セキュリティポリシーより、データベースに直接アクセスすることが許されていない
- キャパシティ上の理由により分析用の処理に制限が設けられている
-
- データベースに直接分析クエリを発行することが禁止されている
- データベースに一度に発行できる分析クエリの数に制限がかけられている
- データベースに分析クエリを発行しても、制限時間内に処理が終わらない
- ストレージの容量不足で、分析対象のデータをすべて置いておくことができない。数回に分けて処理を行う必要がある
- リアルタイムのデータ処理要件がある
-
- 発生したデータに対して直近1分の集計値を算出し閾値判定を行う必要がある
今回はデータ分析にまつわる課題を解決し、最適な環境を整えるために必要な、データ収集について解説していきます。
データ収集の流れ
データ収集は、以下のようにいくつかのフェーズを踏んで実装していきます。
- ① データソースの確認:収集元のデータの所在やアクセス手段を確認する
- ② データ格納先の選定:格納先のデータストアを用途を元に決定する
- ③ データ取得フローの設計・
実装 :データソースからデータを取得する方法を確認、使用するツールやプロダクトを決定する - ④ データ加工フローの設計・
実装 :データの加工方法、加工タイミング(データストアに格納する前か、後か) を確認し、使用するツールやプロダクトを決定する
これらすべてのフェーズが常に必要というわけではありません。データの性質や種類、リアルタイム処理の必要性など、様々な条件によって必要な要素は変化します。またデータ取得とデータ処理などは、要件によって順番が前後することもあります。
以降では、各フェーズにおける考慮事項や、具体的なデザインパターンを解説していきます。
データソースの確認
データ収集ツールがサポートしているデータソース、利用可能なプロトコルは異なるため、まずはデータソースの情報を確認しましょう。データソースの情報は、データの所在や取得方法などが該当します。
リレーショナルデータベースやデータウェアハウスであれば、ホスト情報、ID、パスワード等の接続情報、データベース名、テーブル名が必要になるでしょう。また、データ変換処理を実装するにあたっては、カラム名やデータ型などのスキーマ情報も必要となります。このタイミングで合わせて確認しておくとよいでしょう。
ログファイルなどの個々のサーバーに格納されているファイルについては、ファイルが格納されているサーバーの情報、格納先のディレクトリ名、ファイル名を確認しておきましょう。また、ログローテーションの方式によってデータ収集ツール側の設定が変わってくるため、ログローテーションの有無と方式も確認しておくとよいでしょう。
ファイルサーバーや共有ストレージにファイルが格納されている場合は、ファイルサーバーのホスト情報、対象ファイルが格納されているディレクトリ、ファイルサーバーの認証情報を確認しておきましょう。
なお、上記のようなデータソースに関する情報をメタデータと呼びます。メタデータは手作業による収集だけではなく、データカタログなどのサービス・
データ格納先の選定
データソースの情報収集を通じて、データ分析者は対象データの格納先、データの取得方法を確認できるようになりました。このまま直接データストア上のデータを分析することもできますが、先に説明したような課題がある場合は、分析用に別途データを取得、必要に応じて変換したうえで、分析専用のデータストアに格納する必要性が出てくるでしょう。
この項では、代表的な分析用のデータストアについて解説していきます。
データウェアハウス
データウェアハウスは、数百ギガバイトからペタバイトスケールの大規模データを分析するためのプラットフォームです。データウェアハウスの多くがリレーショナルデータベースと同様に正規化されたデータをテーブル内に持ち、SQLでの分析をサポートしています。BIツールなどのユーザーインターフェイスを備えた分析ツールや、アプリケーションから頻繁に分析用のクエリが発行されるようなケースで特に力を発揮します。
データウェアハウスの多くは、複数のノードで分散処理を行う前提でアーキテクチャーが設計されています。エンジンに特化した独自のデータ構造を採用するほか、独自のキャッシュ機構を備えているなど、複雑なクエリを素早く処理できるよう最適化が図られています。
AWSでも様々な最適化技術が組み込まれたクラウドデータウェアハウスとして、Amazon Redshiftを提供しています。本サービスは2013年のリリース以降様々な改善を重ねており、今年の7月にはサーバーレス化されたサービスとしてAmazon Redshift Serverlessの一般提供が開始されました。Redshift Serverlessと付属のQuery Editorを使用することで、インフラストラクチャの準備・
オブジェクトストレージ
オブジェクトストレージは、データを
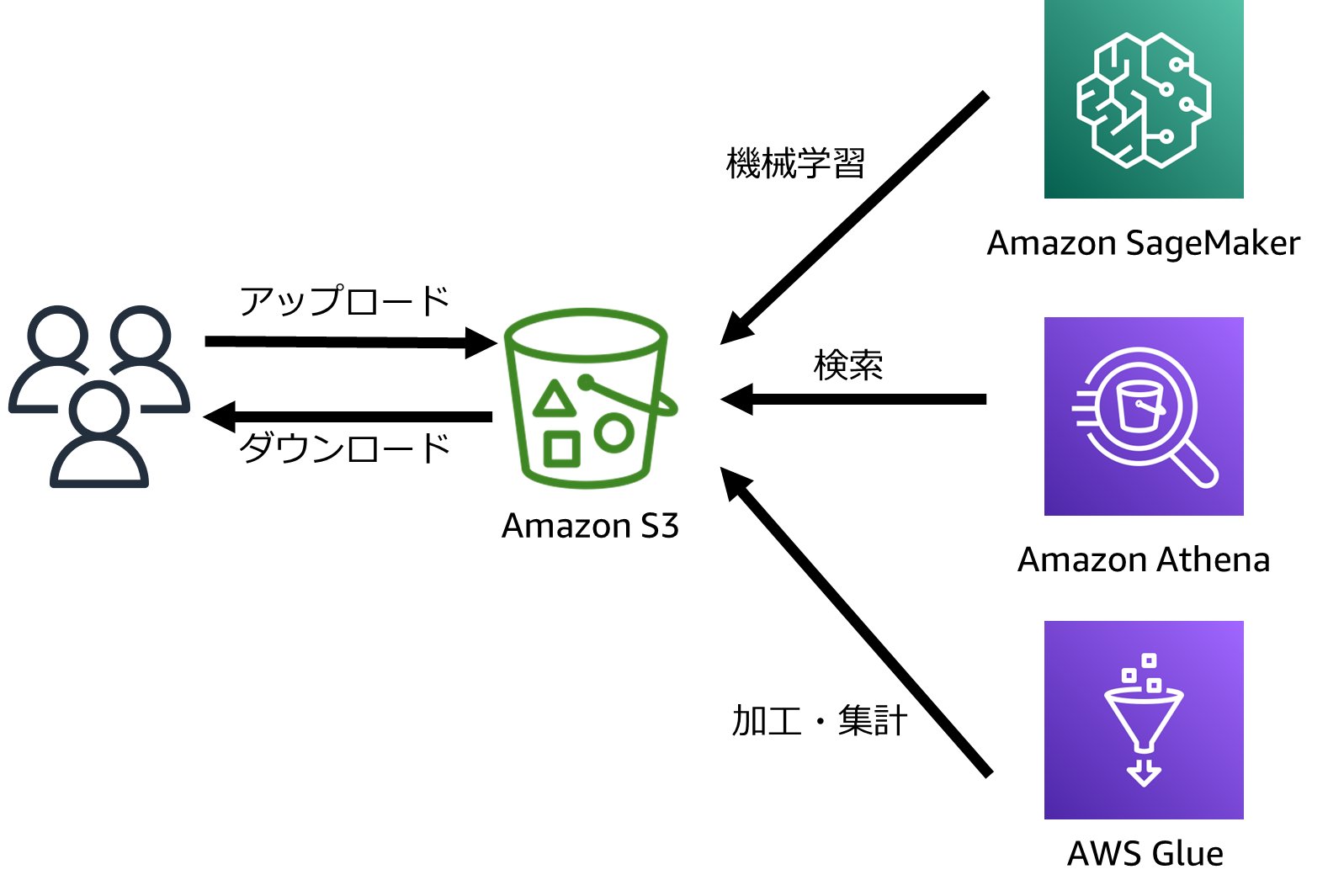
オブジェクトストレージはスケーラビリティに優れており、膨大な数のファイルも問題なく格納できます。その特性上、Apache Sparkなどの大規模な分散アプリケーションプラットフォームや機械学習のためのライブラリなど、様々なクライアントがオブジェクトストレージをサポートしています。様々なアプリケーションがアドホックに参照するようなデータは、オブジェクトストレージに格納するとよいでしょう。
オブジェクトストレージは自前で構築することも可能ですが、様々な事業者が提供しているクラウドオブジェクトストレージを利用することも可能です。AWSでも、オブジェクトストレージサービスとしてAmazon S3を提供しています。AWSサービスと統合されており、クエリサービスAmazon AthenaによるSQLを使ったデータ分析、Amazon EMRやAWS Glueによる大規模かつ高度なデータ処理、機械学習サービスAmazon SageMakerにおけるモデルのトレーニングやデータセットの管理など、様々な場面で利用されています。
注意:オブジェクトストレージを利用する場合は削除要件や更新要件を確認する
データ分析でオブジェクトストレージを使用する場合は、データソースごとにデータの削除要件や更新要件を確認しておきましょう。データソースがファイルであればファイル単位で削除、更新を反映するだけで済みますが、データソースがデータベースの場合は注意が必要です。
データベースから取得したデータをオブジェクトストレージに格納して分析に利用する場合、分析パフォーマンスを高めるために、通常、オブジェクトストレージ上の単一のオブジェクトには複数のデータベースレコード相当の情報を格納しています。
このため、あるレコードに対して変更や削除が加えられた場合は、対象のレコードが含まれるオブジェクトを置き換える必要があります。この仕組みを一から実装するとなると大変ですが、幸いなことにApache Iceberg、Apache Hudi、Delta LakeなどのOSSや、AWSサービスであればAWS Lake FormationのGoverned Tableといった、レコードの追加・
こうした既存の仕組みは単にオブジェクトを置き換えるのではなく、元のオブジェクトに加えてメタデータや変更情報
なお、AWSが提供するAmazon Athenaでも、Apache Iceberg、Apache Hudi、AWS Lake Formation Governed Tableに対するSQLによる検索が可能です。どの仕組みを使用するかは、自分が使っているクエリサービスのサポート状況を確認してから決めていきましょう。
データストリーム
データストリームとは、継続的に生成され続ける大量のストリーミングデータを効率よく処理する目的に特化した一時的なデータストアです。格納可能なデータ量の上限や、データの格納期間が決められている代わりに、低レイテンシでのデータ格納、提供をサポートしています。また、クライアント向けにはオフセットやチェックポイントなど、ストリーム内のどのデータまで処理したかを記録する機能も提供しています。
データストリームを使用して、リアルタイムにデータを収集、処理を行うためのデータ処理方式をストリーム処理と呼びます。以下のような従来のバッチ処理で解決が難しい要件については、ストリーム処理を検討するとよいでしょう。
- データウェアハウスやオブジェクトストレージにデータを格納する前に、簡易的なデータ加工を行いたい
- 発生したデータをリアルタイムに処理したい
(異常検出やレコメンデーションなど)
ストリーム処理では、データストリームに対してデータを書き込むクライアントであるプロデューサーと、データストリームからデータを読み取り処理を行うクライアントであるコンシューマーが登場します。
データストリーム、プロデューサー、コンシューマーの3つの要素でストリーム処理を実装することで、プロデューサーはデータの格納、データストリームはデータの保持、コンシューマーはデータの取得と、各コンポーネントの役割がシンプルになります。また、スケールも各コンポーネントごとに個別に行うことができるため、コスト面でのメリットもあります。
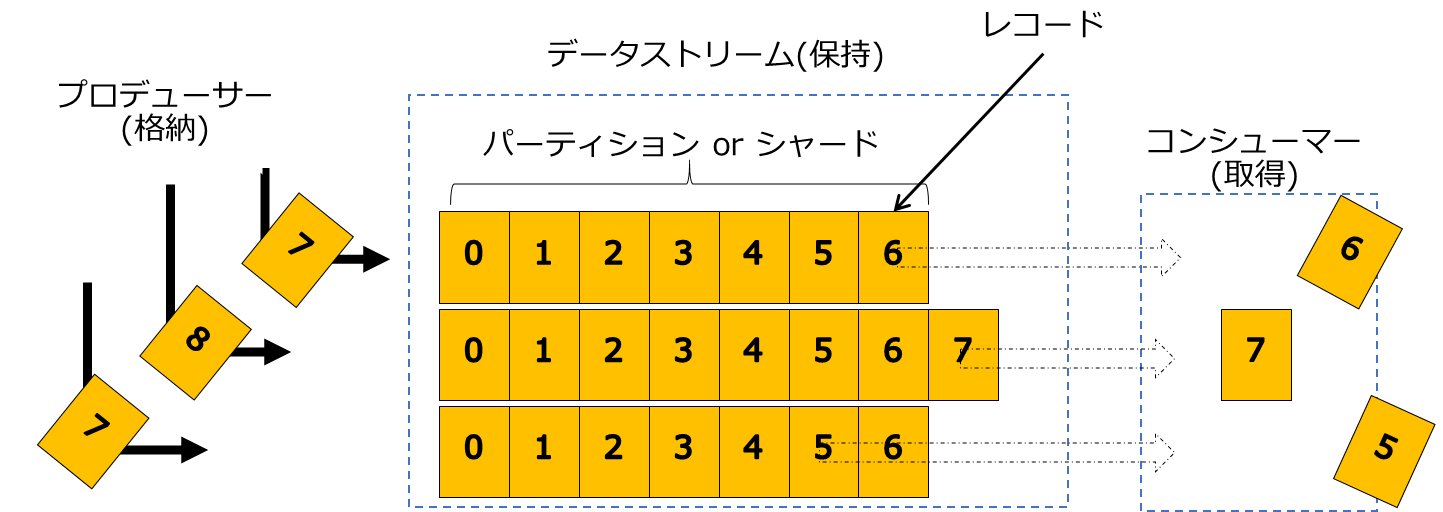
OSSのデータストリームとしてApache Kafkaの名前を目にしたことがある人も多いかと思います。Apache KafkaはLinkedInにより開発された分散メッセージングプラットフォームです。
AWSからはAmazon Kinesis、およびAmazon Managed Service for Apache Kafka (MSK)をデータストリームサービスとして提供しています。Amazon KinesisはAWSが独自に開発したサーバレスのストリームサービスです。セットアップ・
データストリームはリアルタイムなデータ処理を実装する上で必要不可欠です。しかし、データウェアハウスやオブジェクトストレージ上のファイルを使ったバッチ処理による分析と比較すると、エラーハンドリングが複雑になる場合があります。また、データストリーム内を流れるデータに対してインデックスなどを作成する機能はないため、データストリーム内のデータを柔軟に検索することは困難です。特性やトレードオフを考慮したうえで、バッチ処理とストリーム処理を使い分けましょう。
複数データストアの併用
データストアは目的に応じて組み合わせて利用することが可能です。
データウェアハウスの中にはオブジェクトストレージ上のデータを直接分析する機能を持ったものがあります。オブジェクトストレージ上のデータを取り込む必要がないため、分析にかかる前準備の時間を短縮できます。また安価なオブジェクトストレージにデータを格納することで、コスト効率もアップします。
Amazon Redshiftも、Amazon S3に格納されたデータを直接分析することが可能です。ただし、先ほど説明したように、データウェアハウスはキャッシュや独自のデータフォーマットなどを採用しているため、オブジェクトストレージ上のデータの直接分析は、データウェアハウス上のデータ分析と比較して所要時間が長くなる場合があります。
このため、低レイテンシが要求されるデータ
また、アプリケーションやツールの制約により、データウェアハウスから直接データを取得できない場合もありえます。このような場合も、データウェアハウス上のデータをオブジェクトストレージにエクスポートしたり、データを二重で保持することにはなりますが、データウェアハウスとオブジェクトストレージ双方にデータを書き込むなどの併用が有効です。
なお、データストリームはデータの永続保管には向かないため、データストリーム内のデータを保存したい場合も他のデータストアと組み合わせることになります。
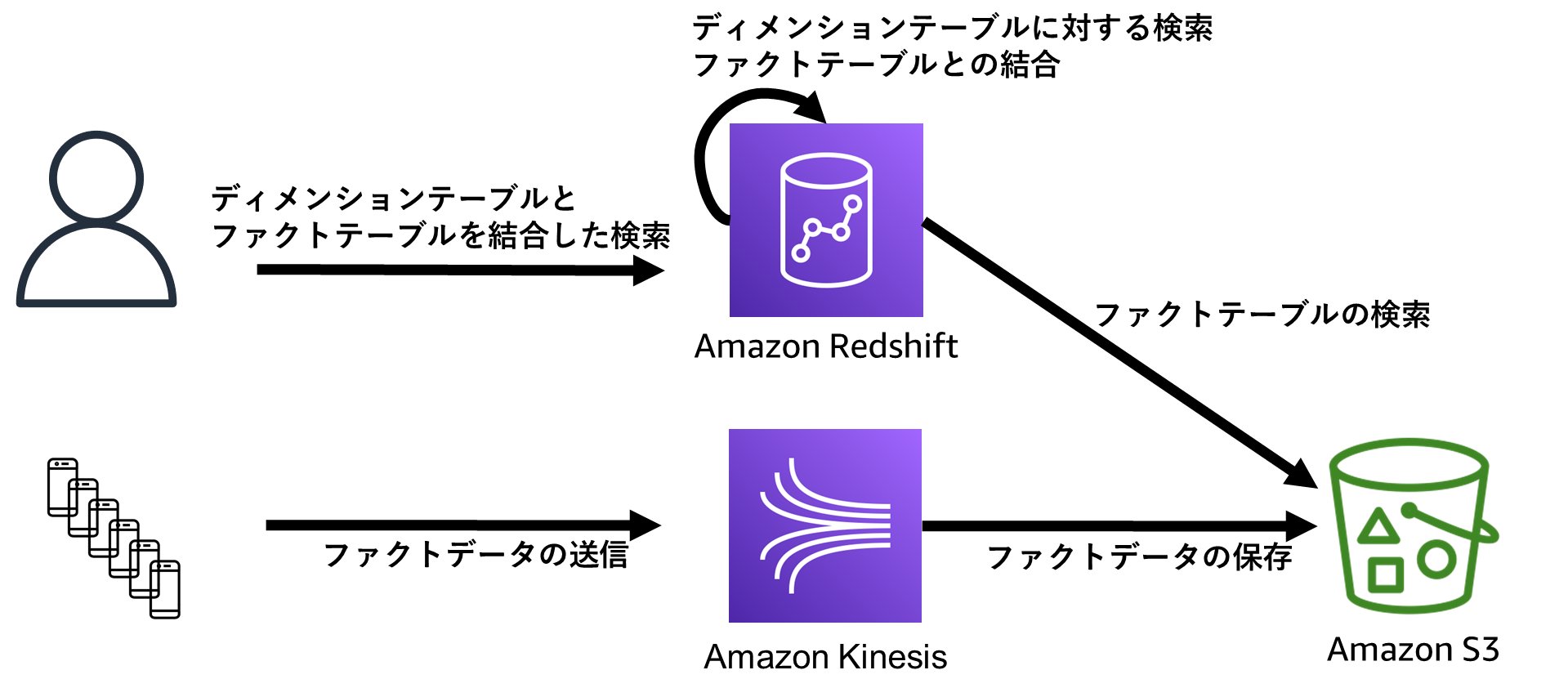
以下は複数のデータストアを組み合わせたアーキテクチャーの一例です。頻繁に参照されるディメンションテーブルはデータウェアハウスのローカルストレージ上に配置し、参照頻度が低いファクトテーブルのデータはオブジェクトストレージに格納することで、データウェアハウスのローカルストレージの使用量を抑えられます。また、リアルタイムに各デバイスから送信されてくるファクトデータはデータウェアハウスから検索するための加工処理が必要であるため、データストリームを使用しています。
データフローの設計
使用するデータストアが定まってきたところで、データソースとターゲットを結ぶデータフローを設計していきます。
なお、データソースによって使用するプロダクトやフローが大きく異なるため、いくつかのサンプルシナリオを使って説明します。
データベースのデータ収集
データベースからデータを取得する場合は、SQLによるデータの都度取得、もしくは変更データキャプチャ
SQLによるデータ取得
SQLによるデータ取得は、定期的にデータベースからデータを取得するバッチ処理で一般的に用いられる手法です。
対象テーブルのサイズが小さい場合は都度全てのデータを取得するのが簡単ですが、テーブルサイズが大きく、また更新頻度が高い場合は差分取得を検討しましょう。
テーブル内に更新日付を示すカラムが存在している場合は、以下のような形で差分のレコードだけを取得することもできます。
SELECT * FROM table WHERE updated_at >= 'YYYY-mm-dd HH:MM:ss'
SQLによるデータ取得は、JDBC/
- AWS Lambda:様々な言語のアプリケーションを実行可能。15分の実行時間制限あり。
- AWS Glue:Pythonアプリケーション、Sparkアプリケーションを実行可能。
- Amazon EMR Serverless:Spark 、Hiveアプリケーションを実行可能。
AWSにおける上記のサーバレスサービスは、アプリケーションの実行時間に応じた従量課金制となっているため、常時起動が求められないバッチ処理基盤で良好なコストパフォーマンスを発揮します。
変更データキャプチャ(CDC)によるデータ取得
変更データキャプチャ
CDCは、リアルタイムにデータを同期したい場合や、テーブルサイズが大きかったりまたは更新量が多くSQLによるデータ取得では更新処理が追いつかなかったりするケースで選択されます。
CDCは低レイテンシであることや、データ取得対象のテーブルが更新日付のカラムを持たないといった特徴から、SQLによる差分取得が難しい場面で有用です。しかし、以下の点には考慮が必要です。
- 初期データの移行:CDCで取得可能なデータは差分情報のみです。既にテーブルに格納されているデータについては、エクスポート&インポートなど、別の方法で予め移行しておく必要があります。
- データの変換処理:取得された差分情報には発行されたSQL、変更前後のデータの他様々なメタデータが含まれています。それらのデータの中から必要なデータのみ抽出し、処理する必要が出てきます。
- 既存データベースへの影響:CDCではソースデータベース側でトランザクションログを出力・
保持する必要があるため、トランザクションログを一定期間保持するための追加のディスク領域が必要となります。また、トランザクションログをこれまで出力してこなかったデータベースでは、トランザクションログを有効化するための設定変更・ メンテナンス作業が必要になる場合があります。そのほか、トランザクションログの出力を有効化することで、既存の更新系クエリのスループットが低下する場合があります。
CDCによるデータ取得は、継続的なデータ処理が発生するため、データストリームとの組み合わせが有効です。
CDCをOSSで実装する場合、以下のような組み合わせが利用できます。
- Apache Kafka + Debezium:Apache Kafkaをデータストリームとして利用します。Debeziumはプロデューサーに該当し、データベースから差分情報を収集するために使われます。コンシューマーはApache Kafkaに対応しているものであれば、Kafka ConnectやApache Flinkなど、任意のソフトウェアやライブラリを利用可能です。
- Apache Flink + CDC Connectors for Apache Flink:Apache FlinkのCDCコネクタを使用し、データベースから差分情報を取得します。データストリームやコンシューマーもFlink内で実行することも可能ですが、Flinkから一度Kafkaなどに格納し、任意のコンシューマーでデータを処理したほうが可用性が高まります。
AWSではAWS Managed Service for Apache Kafka (AWS MSK)、およびMSK Connectの2つのマネージドサービスを利用することで、DebeziumによるCDCの仕組みを素早く構築することが可能です。詳細はこちらのBlogをご覧ください。
また、CDCによるデータ連携をオールインワンで行うプラットフォームもあります。AWSでは、 AWS Database Migration Service (DMS)と呼ばれる異種データストア間のデータ同期を行うマネージドサービスを提供しています。DMSを利用することで、データベースからデータウェアハウスへの継続的なデータのレプリケーションを実行可能です。OSSでも、AirbyteなどがCDCをサポートしています。
ログファイルの収集
ログファイルの収集方法は、ファイルアップロード、またはデータ収集ソフトウェアの利用が代表的な手段です。
ファイルアップロード
ファイルのアップロードは、最もシンプルな手段です。アップロード先は、共有ストレージや外部のオブジェクトストレージなどが候補となります。
AWSでは、オブジェクトストレージであるAmazon S3が利用されています。Amazon S3へのデータアップロードは、AWSが提供するコマンドラインインターフェースAWS CLIを使用することで、aws s3 cpコマンドによる単一ファイルのアップロードや、aws s3 syncコマンドによるディレクトリ配下のファイルの一括アップロードが可能です。
データ加工など前処理を行ったうえでアップロードを行いたい場合は、embulkなどのオブジェクトストレージをサポートしている高度なデータロードツールも検討するとよいでしょう。
データ収集ソフトウェアの利用
ファイルコピーはシンプルな方式ですが、ログファイルにイベントが書き込まれてからアップロードまでのタイムラグがあります。したがって、リアルタイムにデータを収集したい要件には向いていません。
サーバー上のログをリアルタイムに収集する場合は、Fluent Bit、Fluentd、Vectorなどのソフトウェアを利用します。これらのソフトウェアは、ファイルへのデータ追記を監視し、追記されたデータだけを取得、データストアに転送します。ファイル内のデータをどこまで読み込んだかを記録するチェックポイント機能も持っているため、何らかの問題でソフトウェアが停止しても、停止した時点からログの取得を再開することが可能です。ログローテーションにより新規に作成されたログファイルの自動検出にも対応しています。
また、これらのソフトウェアはコンテナ上でも実行可能であり、コンテナアプリケーションのログ取得にも活用されています。多くのソフトウェアがデータストリームへのデータ送信をサポートしているため、アラートなどのリアルタイム処理にも活用できます。
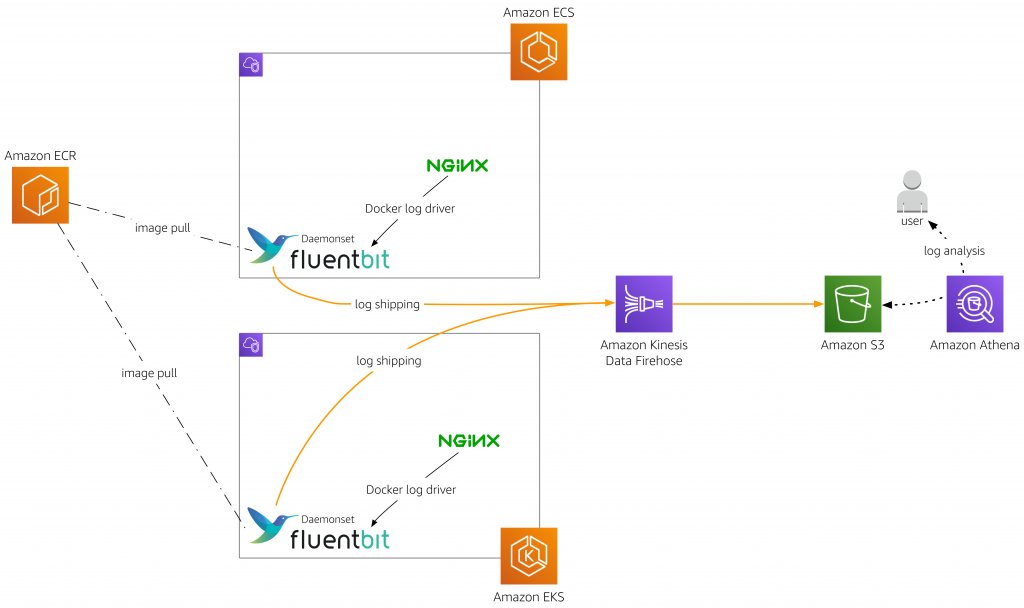
共有ストレージ上のファイル収集
ファイルサーバー等の共有ストレージに格納されているファイルを収集する場合、ネットワーク経由、オフラインのどちらの方式で収集するかを検討します。
ネットワーク経由でのファイル収集
ネットワーク経由のファイル収集は、rsyncやrobocopyなど、OSが提供する標準のツール、もしくは日常的に使用しているサードパーティー製のツールなどを利用できます。収集したファイルを外部のサービスに転送する場合は、ツールの実行端末がインターネットやVPN、専用線などを経由して対象サービスにアクセスできる必要があります。
ファイルサーバーなどの共有ストレージ上のファイルをAmazon S3にファイルを格納する場合は、先に紹介したAWS CLIを使う他に、データ移行サービスAWS DataSyncを利用することも可能です。AWS DataSyncはデータ暗号化、データ圧縮、帯域幅の制御、メタデータの同期、ファイルの変更検出による差分同期のスケジュール実行など高度な機能を備えており、大規模なデータ転送において有用です。詳細はAWS DataSyncの特徴をご覧ください。
オフラインでのファイル収集
ネットワークポリシーやネットワーク構成、帯域などの理由によりネットワーク経由でファイルを収集することができない場合は、オフラインでのファイル収集を検討します。オフラインでのファイル収集とは、例えば外付けのストレージなどにファイルを保存する方法が該当します。
オフラインでファイルを収集しAWSにデータを格納する場合は、AWS Snowballを利用できます。Snowballは大容量のハードディスクを搭載したアプライアンスを提供しています。AWSから配送されたSnowballアプライアンスにファイルを格納し、AWSに返送することで、AWSへのデータアップロードを行うことができます。
SaaSアプリケーションのデータ収集
SalesforceやSlackなどのSaaS
APIによるデータ取得
SaaSアプリケーションの多くはAPIを提供しています。サービスプロバイダが提供するAPIやSDKを使用することで、データ取得用のプログラムを実装し、実行環境で動作させることが可能です。プログラムの実装にあたっては、APIの単位時間あたりの呼び出し回数や、一度に取得可能なデータ量などの、サービス側の制限を確認しておきましょう。
自前でAPIを呼び出すプログラムを実装する他に、SaaSに対応したデータ連携サービスやツールを利用する方法もあります。AWSでは、Amazon AppFlowと呼ばれるデータ転送サービスを提供しています。
Salesforce、SAP、Zendesk、Slack、およびServiceNowなどのSaaSアプリケーション、Amazon S3やAmazon RedshiftなどAWSサービス間のデータの転送を、ノーコードで実装することが可能です。また、CDCの項で紹介したAirbyteのように、SaaSからのデータ取得もサポートしているOSSも存在します。CDataやtroccoのような、外部のデータ連携サービスも利用可能です。
イベント駆動/ストリーミングによるリアルタイム連携
SaaSアプリケーションによっては、イベント発生時に外部サービスにWebhook等の仕組みでイベント情報を連携できます。イベントをリアルタイムにやり取りすることで、データの即時分析を行うことが可能です。
AWSでは、こうしたイベントデータを受け取るサービスとして、Amazon EventBridgeを提供しています。EventBridgeを使用することで、様々なSaaSサービスからのイベント受け取りをノーコードで実装できます。日本国内のサービスでも、KarteなどがEventBridgeとの連携をサポートしています。
サービスによっては、Amazon KinesisやApache Kafkaなどのデータストリームへのデータ連携もサポートしています。AWSでも、多くのサービスがAmazon Kinesisへのイベント連携をサポートしています。例えば、CDN (Contents Delivery Network) サービスであるAmazon CloudFrontや、AWS WAF
ストレージへのデータエクスポート
ストレージへのデータエクスポート機能をSaaSアプリケーションが提供している場合もあります。エクスポート機能を利用することで、データ取得をノーコードで実装できます。
例えば、CDNサービスであるCloudFlareはAmazon S3へのログ配信機能を提供しています。AWSでも、これまでに紹介したAmazon S3、Amazon MSK、Amazon CloudFrontなどの様々なサービスがAmazon S3へのログ出力をサポートしています。
データ処理フローの設計
ここまでの説明で、どのようにデータを収集するか、収集したデータをどのデータストアに格納すべきかについて、イメージが湧いてきたのではないでしょうか。
データソースから得られたデータをそのまま分析に活用していけるようでしたら、次のステップに進んで行きましょう。データの活用方法や分析手法については、第5回にて詳しく解説します。
分析を行う中で以下のような課題が見えてきた場合は、追加のデータ処理を検討するとよいでしょう。
- 取得したデータがCSVやJSON形式で保存されているが、分析ツールがよりパフォーマンスを発揮できるParquetやORCといった列志向形式のファイルに変換したい
- ツール上で直接分析するにはデータ量が多いため、事前集計を行いたい
- 複数のデータソースから取得したデータを結合し一つにまとめたうえで分析を行いたい
- IPアドレスを元に地域情報を付与するなど、データのエンリッチを行った上で分析を行いたい
データ処理の詳細については、第4回で詳しく解説します。
なお、データ処理フローを設計検討するうえで、
例えば、
一方で、
バッチ処理はデータストアに格納されているデータが対象になるため、後から追加要件が出てもアーキテクチャーへの影響はありません。一方でバッチ処理しか無い前提で構築されたシステムに後からリアルタイム処理を追加する場合、データストリームを組み込んだシステムアーキテクチャーへの変更が必要となります。
技術選定時のポイント
さて、みなさんも機能要件を元にデータ収集フローの構成を描けるようになったのではないでしょうか。締めくくりとなる本項では、技術選定における機能要件以外の観点を紹介します。
AWSでは、高い安全性、性能、障害耐性、効率性を備えたインフラストラクチャを構築し、評価を行う際に有用なAWS Well-Architectedと呼ばれるフレームワークを提供しています。AWS Well-Architcted Toolを使用することで、Webコンソール上でアーキテクチャーレビューを実施することも可能です。
AWS Well-Architectedでは6つの柱を掲げていますが、今回はアーキテクチャー選定に大きくかかわる5つの柱から重要なポイントをピックアップします。
- セキュリティ:組織および業界のセキュリティ標準を満たす機能を備えているか。例えば、暗号化やユーザーベースのアクセス制御をサポートしているか。
- 運用の優秀性:障害検知やセキュリティイベント対応が素早く行えるようメトリクスやログの出力に対応しているか。アプリケーションのロジックを素早く、かつ既存サービスへの影響を最小限に抑えつつ変更できる仕組みを備えているか。設定をコード化し、テスト環境などを容易に構築することが可能か。
- 信頼性:単一障害に耐えうる仕組みになっているか。誤削除といったデータの論理障害に備えてバックアップからデータをリストアする仕組みが備わっているか。データ収集フローが何らかの障害で停止した場合、停止した箇所から、データの欠損がなく収集を再開できるか。
- パフォーマンス効率:ワークロードに応じて最適なリソースタイプを選択することが可能か。ニーズに応じて割り当てリソースの増減は可能か。
- コスト最適化:必要時のみリソースを起動・
実行するなど、待機リソースによる無駄な費用が発生しない仕組みになっているか。ワークロードごとにコストが追跡でき、費用対効果を明確にすることが可能か。
設計のシンプルさ、構築のしやすさという点も重要ですが、上記の観点が考慮されているかは後の運用フェーズに大きく影響してきます。そのため、AWS Well-Architected Tool等を活用し、事前にチェックしておくとよいでしょう。
まとめ
今回は、データ分析を開始するにあたって遭遇しうる問題と、その解決方法であるデータ収集について解説しました。次回は、今回詳しく取り上げなかったデータの管理に焦点を当てて解説していきたいと思います。