



株式会社MIXIで
みてねは現在、1,500万人を超えるユーザに175の国と地域でサービスを提供しています(2022年8月現在)。そこで、より高い信頼性と可用性を担保するためにみてねのSREグループではオンコールエンジニア制度を設けています。
今回はこの
オンコールの定義
まず、どのような条件でアラートを設定しオンコールを実施するかの定義について簡単に触れておきます。
現在はさまざまなソースから多種多様な情報を収集することができます。
たとえば、みてねではKubernetes
これらすべてを監視対象とし、すべてに閾値を設定し、すべてをオンコールの対象として定義していては、とてもではないですが管理できないですし、オンコールエンジニアの負担がとても大きくなってしまいます。
そこでみてねではオンコールを定義する際に4つのゴールデンシグナルを基準にしています。
- レイテンシー
- トラフィック
- エラー
- サチュレーション
その他にもシステムを運用する上で絶対に必要なリソース
オオカミ少年にならないために
上記オンコール条件の定義に基づいて設定したとしても、時が経つにつれさまざまな要因からアラートの条件が風化しオンコールが意味をなさなくなってしてしまう場合があります。
- 例1)
エラー数を条件にアラートを設定したが、サービス拡大に伴うユーザ増加で頻繁に閾値を越えるようになった - 例2)
memory使用率を条件にアラートを設定したが、自動でスケーリングするように設定したためオンコール発生後も特にやることはない
このようにあまりにもオンコールが多発したり、発生してもとくに対処方法がないケースが多くなるとオンコールそのものが形骸化してしまい、本当に障害が発生しているか判断しづらくなったり、担当者が疲弊してしまったりと多くの悪影響がでてしまいます。
そのためオンコールに設定しているアラートの条件を定期的に見直す必要があります。
たとえば、先ほどの例1の場合であればエラー数ではなくエラー率に変更、例2の場合はそもそもアラート条件を削除してしまって良いかもしれません。
みてねではオンコール発生後の翌営業日のミーティングの場でアラートの内容をチームで確認しており、その際に
また、障害発生時にはポストモーテムを実施しており、ポストモーテム内の振り返りでアラート条件の見直しを実施することも多くあります。
みてねでの実際の運用
オンコールの定義を整理したので、次に実際の運用について紹介させていただきます。
オンコールエンジニアの条件
まず、入社してすぐのエンジニアがオンコールエンジニアになることはありません。GoogleのSRE本にもあるように、オンコールエンジニアには一定の能力が求められます。みてねでは基準を以下のように定義しています。繰り返しになりますが、この定義を満たすまではオンコールエンジニアになることはありません。
- 障害対応時に適切なコミュニケーションができること
- できるだけ早く反応できる
- 必要な連絡先を判断し円滑にコミュニケーションを行うことができる
- 対応ログを適切な箇所に残しながら作業ができる
- AWSや各種モニタリングツールの扱いに慣れていること
- 原因特定のためにモニタリングツールを利用しそのメトリクスを理解している
- ログの検索・
保全ができる - 適切な負荷対策ができる
- 自分のスキルに過度な自信を持っていないこと
- 個人で判断せずエスカレーションポリシーを遵守できる
トレーニング
これらの条件を満たせるようになっても実際のオンコールが発生した際は、ベテランエンジニアの経験や勘のほうが有用なケースがあります。
そこで新人のエンジニアがオンコールエンジニアを担当する前に、さらに
こちらは新しく担当になるエンジニアが、ベテランエンジニアが出題する問題に回答しフィードバックを受けるという流れでオンコール発生時の対応スキルを向上させることができる施策です。
簡単な流れは以下のようになります。
- 出題者と回答者に分かれて行う
- 出題者は発生した事象を回答者に説明する
- 回答者は出題者に質問しながら自分の考えを説明して原因と対策を回答する
- 可能であれば回答者は説明時に実際にメトリクスやログを検索して出題者に見せながら作業する
- 出題者は回答に対してフィードバックをする
以上の流れを何度か繰り返すことでより自信を持ってオンコール担当につけるようになります。
実際にやってみた感想としては、Chaos Engineeringのようにコストをかけなくとも実際の障害を想定したトレーニングができる点がメリットだと感じました。また、出題者や回答者は複数人いても良く、むしろその方が色々な角度からの回答を聞けたり、そのままディスカッションに発展することもあるのでおすすめです。
注意点としては回答者が試されるような形になるので、少しだけ不安になります。できるだけ明るい雰囲気で実施できるといいかもしれません。
運用方法
ここからは実際のオンコール対応の運用について紹介します。
前提として、勤務時間内に発生したオンコールは担当関係なく、チーム全員で対応します。
オンコールエンジニアは、発生したオンコールに可能な限り早く対応するため、以下のルールを遵守することとしています。
- 即時対応可能な状況でいること
- 電波がつながらない場所はできる限り避けること
- 深夜に睡眠中であっても起きて対応すること
中々負担が大きいですが、チームから1名をオンコールエンジニアとし1週間ごとにローテーションしていることと、オンコールエンジニアには振替休日と手当金が支給されることもあり、実際に感じる負担はそこまで大きくありません。
また、以下の場合はチーム全員が2次担当者となります。
- 1次担当者が一定時間内に対応できなかった場合
- 1次担当者がエスカレーションした場合
もちろん1次担当者がすべてのケースで即座に問題を解決できるに越したことはないですが、現実的にはそうはいきません。適切にエスカレーションしてチームの判断を仰いで対応した方が、担当者の精神的な負担が小さくなると言ったメリットがありますし、逆に相談できなかったがゆえにさらに大きな障害に発展してしまうなどと言ったリスクもあります。ですので可能な限りエスカレーションは実施したいのですが、実際の状況になると深夜や休日にチームメンバーを呼び出すことに抵抗を覚えてしまうことがあります。
そのために
「対応できる気がする。でも1%くらいダメな気がする。」
も必ずエスカレーションする。
とチーム内のドキュメントに明記しています。
加えて、長期連休に入る前などにはチーム内で
かなり些細な対策ですが、こう言った小さな積み重ねでチーム内の心理的安全性を構築していくことが、最適なオンコールを運用する上で大切です。
仕組み
次にオンコールが発生してから担当者に通知されるまでの流れを紹介させて頂きます。
みてねではオンコールに関連して以下の技術スタックを採用しています。
| 目的 | ツール |
|---|---|
| コンテナ基盤 | Amazon EKS |
| メトリクス収集 | Prometheus |
| アラート管理 | New Relic |
| 通知 | Slack, PagerDuty |
| IaC | Terraform |
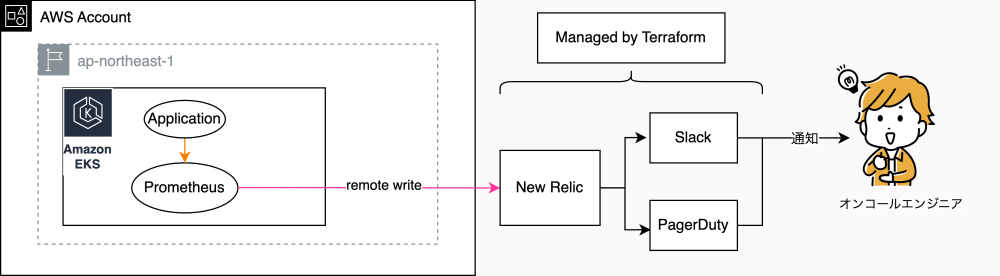
先ほども紹介いたしましたが、みてねではEKSを採用しており、各種メトリクスの収集にはPrometheusを利用しています。EKS上で起動しているPrometheusが各種メトリクスを収集し、収集したメトリクスからアラートの通知に必要なメトリクスをEKS上のPrometheusからNew Relicにremote writeします。
実際のアラートの通知にはNew Relic Alertsを利用しており、Prometheusからremote writeされたメトリクス以外にもNew Relic APMやNew Relic Browserなどを利用しアラート条件を設定しています。
さらに、IaCにTerraformを利用しているため実際のNew Relic Alertsの設定はWorkflowsを用いて定義しています。
オンコールに関連するほぼすべてのリソースがコード化されているので、閾値の変更やアラート条件の変更などの際にコードレビューを通してチームの合意を取ってから変更を実施できる点に大きなメリットがあると感じています。
マルチリージョンでのオンコール設定
最後に少しニッチな内容になってしまいますが、マルチリージョン化でのオンコールの設定について触れておきます。
リージョンを増やして運用するシステムが増えると、その分だけオンコールの設定を増やさなければなりません。また、ただ設定を増やすだけではなくどこのリージョンで発生した問題なのかも明確に通知しなければならないため、かなり複雑で煩雑になりそうですが、上記の構成ですと必要なalert条件に少し追加するだけで簡潔にオンコールの設定を追加することが可能でした。
各RegionごとにそれぞれにAPMを起動しているため、entitiesの配列に新しいRegionのAPMのidを追加するだけで設定が追加されます。
resource "newrelic_alert_condition" "mitene_apm_example" {
policy_id = newrelic_alert_policy.mitene_example.id
name = "Apdex"
enabled = true
type = "apm_app_metric"
entities = [data.newrelic_entity.mitene_web.application_id, data.newrelic_entity.mitene_web_use1.application_id]
metric = "apdex"
condition_scope = "application"
term {
duration = 10
operator = "below"
priority = "critical"
threshold = 0.90
time_function = "all"
}
}
NRQLを利用したアラートの場合はクエリの最後にFACET句を用いてグループ化するだけで、アラートはグループ化の結果それぞれで管理されます。
resource "newrelic_nrql_alert_condition" "mitene_nrql_example" {
account_id = var.account_id
description = "NRQL EXAMPLE"
fill_option = "static"
fill_value = 0
policy_id = newrelic_alert_policy.mitene_example.id
type = "static"
name = "mitene NRQL example"
enabled = true
violation_time_limit_seconds = xxx
aggregation_method = "event_flow"
aggregation_delay = xxx
expiration_duration = xxx
nrql {
query = "FROM Metric SELECT latest(mitene_example_alert) WHERE namespace LIKE 'mitene' FACET region"
}
critical {
operator = "equals"
threshold = 0
threshold_duration = xxx
threshold_occurrences = "ALL"
}
}
このようにNew Relic Alertsを利用することでマルチリージョンでもコピペなどの必要なく非常に簡潔にオンコールの設定を追加することができました。
最後に
みてねのSREグループ内でのオンコールエンジニア制度の取り組みについてご紹介させていただきました。
一言でオンコールといっても対応するべき箇所や考えるべき箇所は多くあります。この記事が少しでも悩んでいる方やこれから始めようと考えている方の参考になれば幸いです。