



こんにちは、Amazon Web Services Japan ソリューションアーキテクトの林田です。昨今のデータ収集、蓄積、分析ツール技術の発達に伴い、企業などの組織においては膨大なデータセットが作られるようになりました。このため、収集されたデータをいかに安全かつ使いやすい状態で保管すべきかが注目されています。そこで連載第3回では、収集されたデータに対する
データ活用の広がりとともに起きるデータ管理の課題
AWSのSAとして、日頃さまざまなお客様のデータ基盤構築の相談を受けますが、データユーザ
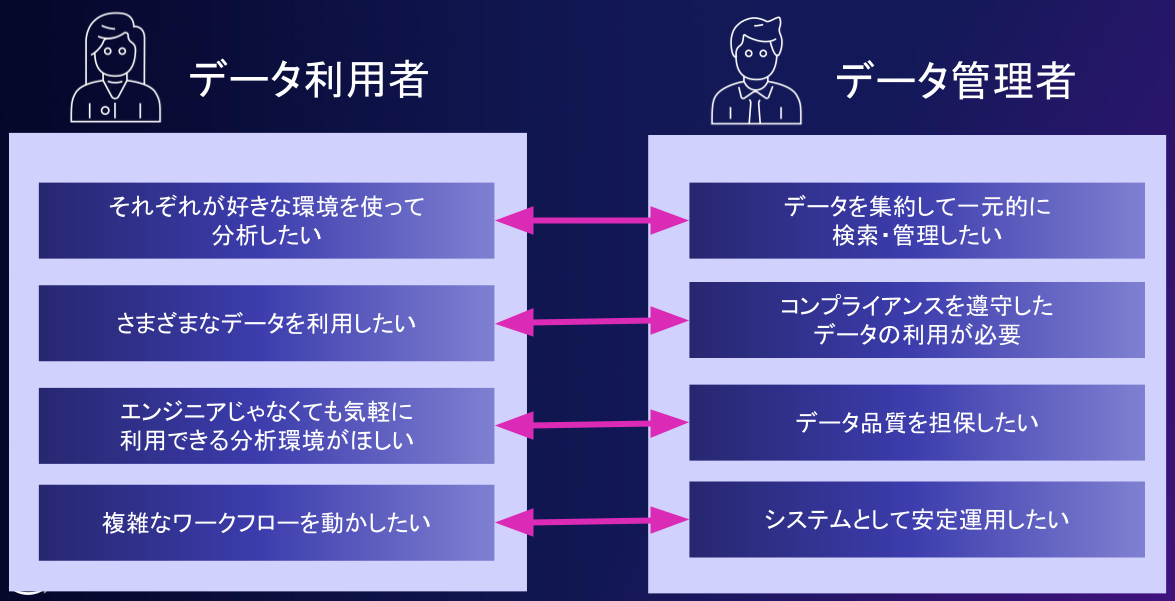
使われるデータ基盤を構築するためには、データ利用者の要件を満たす必要があります。一方で、データ管理者側の要件を満たさないと、データ分析基盤のコストが増大したり、セキュリティやメンテナンス性、パフォーマンスといった非機能要件を満たせなくなります。そのためデータ管理では、これらを両立するための技術をつかいこなすことが重要になります。
データ管理のコンポーネント
この課題を解決するデータ管理のコンポーネントとして、次のものがあります。
- データのカタログ化と検索
- データプライバシー
- データ品質管理
- データ共有
- データパイプラインの管理
- コスト管理
以降では、それぞれのコンポーネントについて1つずつ、その内容を説明します。その後にこの課題を解決するAWSでのソリューションについて紹介します。なお、データパイプラインの管理については、後の回にて別途紹介予定ですので今回は扱いません。
1. データのカタログ化と検索
データのカタログ化と検索について紹介します。
メタデータのカタログ化
組織のデータ基盤構築においてよくある失敗として、
テクニカルメタデータとビジネスメタデータ
メタデータは、大きくテクニカルメタデータとビジネスメタデータに分けることができます。尚、この部分に関して、例えば
テクニカルメタデータ
テクニカルメタデータとは、ETLツールやデータウェアハウスなどのクエリエンジンがデータにアクセスするために必要なメタデータのことです。例えば次のようなものが挙げられます。
- データが保存されている場所
(ファイルシステムにおけるディレクトリやデータベースのテーブル名など) - 列の名称やデータ型
- データのフォーマット
(CSV、JSON、Parquet、icebergなど) - 圧縮コーデック
(gzip、zstdなど) - ビジネスメタデータ
ビジネスメタデータ
一方で、ビジネスメタデータは、データ分析を行うために便利な属性情報を指します。これらの情報が適切にメンテナンスされることで、データサイエンスチームではナレッジ共有や分析結果の確認がやりやすくなり、正しい洞察結果を素早く得られるようになります。例えば次のようなものが挙げられます。
- データの作成者、所有者
- データの作成日時、更新日時
- どのデータ・
ETLプログラムで作成されたか - データが何を示すか
(数値データの単位など) - データの統計情報
(データサイズ、null行の数など) - PII情報の有無
データの検索
データの検索は、データ分析者が必要なデータをいち早く発見したり、データ管理者がデータ整理を行うために重要な機能です。分析の現場においては、テーブル名やデータベース名を検索するだけでなく、上記に挙げたメタデータに含まれるキーワードから、関連度を考慮して表示できることが望ましいです。
2. データプライバシー
データプライバシーについて紹介します。
データプライバシーとコンプライアンス
なぜデータプライバシーを考慮する必要があるのかについて説明します。組織におけるデータ基盤では、管理するデータセットの中に、個人情報や組織の機密データを含む場合があります。その場合はコンプライアンスにしたがって、アクセス制御を行う必要があります。
特に個人情報については、GDPR
こうした法律では、個人情報の定義
日本における改正個人情報保護法を考慮した個人情報の扱いについては
データプライバシーを考慮したデータ管理
このように、特にエンタープライズ・
- どのデータを機密データとして扱うか
- 機密データをどのような条件・
用途で利用を許可するか - 機密データに誰がアクセス可能とするか
- 機密データにどこからアクセス可能とするか
データプライバシー機能は、セキュリティやコンプライアンスを守るために重要ですが、厳しく設定するとそれだけデータ利用用途が制限されます。そのため、データ利活用のしやすさとプライバシー保護のための制限のバランスを考慮して行う必要があります。この要件を決めるためには、データを生成したり更新を行うデータの所有者、セキュリティ・
データプライバシーを考慮したデータのライフサイクル
データプライバシー機能の要件が決まったら、実装を行っていくことになります。特にデータ管理の面では、データプライバシー要件に応じたライフサイクルをどのように管理するかはひとつの検討ポイントになります。
よくある要件として、
3. データ品質管理
データ品質管理について紹介します。
データ分析におけるデータ品質の重要性
データ品質とは、データ分析者が目的とする分析を実施しやすいように、データの内容がそうなっているかどうかを指します。
データ品質は、そのまま分析結果の品質とインサイトを得るまでのスピードに直結します。例えば、欠損値が多いデータを用いた分析では、欠損の少ないデータを使った分析よりも精度が劣ります。また、一つの列に、数値の1, 2と文字列の"1", "2"が混じっているといったことも発生しえます。この場合、文字列と数値のどちらかに合わせるための前処理が必要となり、分析が複雑になるため結果を得るのに時間がかかります。
これら2つの場合は、一応は正しい結果が得られるので良いかもしれませんが、もっと悪い例としては、実はその分析用途としては適さないデータとなっていて、分析結果が間違っていることにあとから気づいてしまうことでしょう。この場合、その分析結果を利用するビジネスに悪いインパクトを与えてしまうことにもなりかねません。よって、データ分析や活用、データの品質管理を行うことは重要です。
データ品質管理
オープンソースのデータ品質管理基盤を開発する米国企業Great Expectations社は同社のブログにおいて、データ品質には次の6つの観点があると言及しています。
- 正確性:データは現実を正確に反映しているか
- 完全性:ユースケースに必要なデータがすべて揃っているか
- 一意性:データに不要な重複がないか
- 一貫性:データに矛盾がないか
- 適時性:必要なユースケースに対して、データが十分に新しいか
- 妥当性:データは期待された形式を守っているか
データ品質管理ではこれらの観点に基づいて、要件に対するデータのプロファイリングを行い、問題がある場合は速やかに検知して修正を行う仕組みが必要となります。
なお、大きなデータ基盤では、テーブル数が数十万以上など膨大であり、そのそれぞれのデータに対して品質チェックの条件を手動で設定することは現実的ではない場合があります。そのため、データ品質管理基盤ではそのデータの傾向から、ある程度品質チェック項目をレコメンドしてくれる機能があることが望ましいといえます。
4. データ共有
データ共有について紹介します。
データサイロ化とデータ共有の課題
データ活用のニーズが増えるにつれ、さまざまな場所にあるデータを横断分析したいという要求が増えてきます。例えば、部署ごとに異なるデータ基盤を構築している場合、目的別にデータレイクやデータベースを使い分けている場合、グループ会社間で特定データをやりとりしたい場合、データを一般公開したり売りたい場合です。
このようなニーズに対応するにあたり、他の環境にデータを転送する方法と、自分の環境にある元データに対する権限を他の組織のメンバに与える方法が検討できます。
データを転送する方法とは、あるデータ基盤上のデータを他のデータ基盤にコピーして利用することを指します。中には、Federated Queryといって、クエリエンジンから他のクエリエンジンに対してサブクエリを実行することで、必要なデータを透過的に転送する方法もあります。
データ転送はシンプルな方法ですが、大きなデータの場合転送コストがかかりますし、データ転送のためのパイプライン管理も必要になります。
データ転送を行い、転送されたデータを転送先で管理する場合、データ生成元は転送されたあとにデータが誰にどう使われているのかを把握できないという問題があります。そのため、データ転送を行わずに共有したいデータそのものに対して権限付与するほうが都合がいい場合があります。
データ転送と権限付与によるデータ共有について、それぞれの手法のメリットとデメリットは次のようにまとめられます。
| メリット | デメリット | |
|---|---|---|
| データ転送による共有 | コピーしたデータに対して所有権をもち、自由に使うことができる。権限管理は組織内で完結できる | データをコピーしたあとに誰がどういう用途でアクセスしたかについて、元のデータ所有者がモニタリングしにくい |
| 権限付与による共有 | 誰がデータを利用したのかをデータ所有者がモニタリングしやすい | 共有先のユーザはデータの所有者になれない。組織をまたいだ複雑な権限管理が発生する |
データメッシュ
データ共有の進んだ形として、データメッシュがあります。データメッシュでは、ドメインごとにデータ基盤を構築・
統一的なデータ基盤に集約する場合と比べ、データメッシュを使うことでデータの所有権や責任を分離できるため、ドメインごとのコスト管理を実現できます。また、障害時の責任範囲を明確化しやすい、他組織の影響を受けずに効率的にスケールしやすいといったメリットがあります。
5. データパイプラインの管理
記事冒頭で述べたとおり、データパイプラインの管理については、後の回にて別途紹介する予定です。
6. コスト管理
データ基盤のコスト管理について紹介します。
データ基盤のコストの定義
データ基盤に置かれるデータ容量やデータの利用者が増えるにつれ、そのデータ基盤にかかるコストが課題になりやすいです。ここでのデータ基盤のコストは、データ基盤の利用料金とその運用にかかる人的コストに大別されます。この記事では人的コストは扱わず、データ基盤の利用料金に着目します。
クラウドにおけるデータ基盤では、コンピュートとストレージが分かれている場合が多いでしょう。この場合の利用料金は、クエリ実行にかかるコスト、データ保管にかかるコスト、ネットワーク転送コストに分けることができます。
コスト管理の単位
このうち、クエリ実行にかかるコストの制限方法として、1クエリにかかるコストの制限、ユーザやグループごとのクエリコストの制限、組織全体でのクエリコストの制限が考えられます。
また、データ保管にかかるコストの制限方法としては、あまり使われないデータを安いストレージに移動、または削除する、ユーザやグループごとに利用できるスペースを制限するといった方法が考えられます。
ネットワーク転送コストについては、ユーザ単位などで細かく制限することは難しいため、全体でのコストを監視し、問題があれば調査するという方法をとることになります。
コスト管理のタスクと自動化パターン
コスト管理では、定期的なモニタリングと最適化を繰り返す必要があります。また、何らかの閾値を定義しておいて、それを超えたらアラートを出すことも行われます。クラウドのメリットの一つとして、このモニタリングと最適化のサイクルを自動化する機能が豊富であることが挙げられます。
自動化のパターンとしては、次のものが考えられます。
- 定期的なモニタリングの自動化
(ダッシュボード生成、アラート通知等) - オートスケール
- コスト最適化のアドバイス機能
AWSにおけるデータ管理
ここまで
AWS Glueデータカタログ
AWSでは、AWS Glueデータカタログというメタデータ管理機能が存在し、テクニカルメタデータとビジネスメタデータの両方を管理できます。AWS Glueデータカタログは、Apache Hiveというオープンソースのプロジェクトの一部である、Hive Metastoreをベースとして作成されたマネージドメタデータカタログです。
実際にAWS Glueデータカタログコンソールのサンプルを見てみましょう。上段の検索窓ではデータの検索を行うことができ、その下にテーブル一覧が表示されています。

この中から一つのテーブル名をクリックすると、そのテーブルの詳細を見ることができます。以下はテーブルの詳細画面の例です。データ型や入力・

テーブルプロパティを利用したビジネスメタデータの管理例を挙げるとすれば、次のようなものが考えられます。
- データオーナ情報
-
- あるデータのオーナにデータの詳細について問い合わせ
- ある到底の人が管理するデータを一覧化
- データのトピック情報
-
- ある分析をしたいときに必要なトピックのデータを簡単に発見
- データの有効期限
-
- 期限切れデータの発見・
削除 - 古いデータの利用による誤ったインサイトを防ぐ
- 期限切れデータの発見・
- 生成元データソース
-
- あるデータに異常があったときに影響範囲を確認
AWS Glueデータカタログの特徴
AWS Glueデータカタログの特徴について説明します。
AWS Glueクローラにより自動メタデータ登録が可能
メタデータカタログにおいて、データソースの追加やデータ型等の検出は、データソースが増えるほど管理が煩雑になります。AWS Glueデータカタログでは、これを自動化する機能として、AWS Glueクローラがあります。
AWS Glueクローラは、指定したタイミングでデータソースにアクセスし、列名、データ型、接続情報といったテクニカルメタデータを自動で収集してAWS Glueデータカタログに登録します。これにより、新しいデータソースの登録や定期的なメタデータのチェック及び更新を自動的に実施し、常にデータカタログを最新の状態に保つことができます。
多様なデータソースやファイルフォーマット対応
メタデータカタログでは、データの収集、保存、加工、分析の一連の流れで利用するすべてのデータソースのメタデータを管理できることが理想的です。しかしデータ基盤が大規模になればなるほど、さまざまなデータソースを扱うことになり、管理は複雑になります。
AWS Glueデータカタログは、Amazon S3上に置かれた、CSV、JSON、Parquet、AVRO、Delta Lake, Apache Iceberg, Apache Hudi[1]などのファイルフォーマットのデータを登録できます。また、Amazon S3上のデータだけでなく、Amazon Redshift、Amazon RDS、JDBC接続可能なデータベース、Apache Kafka等のさまざまなデータソースに対してAWS Glueクローラを利用してカタログ化できます。また、AWS Glueカタログはクロスリージョン、クロスアカウントでのメタデータ管理や、オンプレミスや他クラウド上のデータも登録できます[2]。
ストリームデータにおけるSchema Enforce
AWS Glueには、Schema Registryという、ストリームデータのメタデータの管理およびスキーマを強制するSchema Enforceの機能があります。Schema Enforceがあると、決められたスキーマ以外のデータが入ってきた場合に、それをエラーデータとして検知できます。データソースとしては、Apache Kafka、Amazon Managed Streaming for Apache Kafka、 Amazon Kinesis Data Streams、 Amazon Kinesis Data Analytics for Apache Flink、 AWS Lambdaに対応しています。これにより、ストリームデータに対するメタデータも他のデータソース同様に管理を行うことができ、スキーマの異なるデータが流入した際に検知できるようになります。
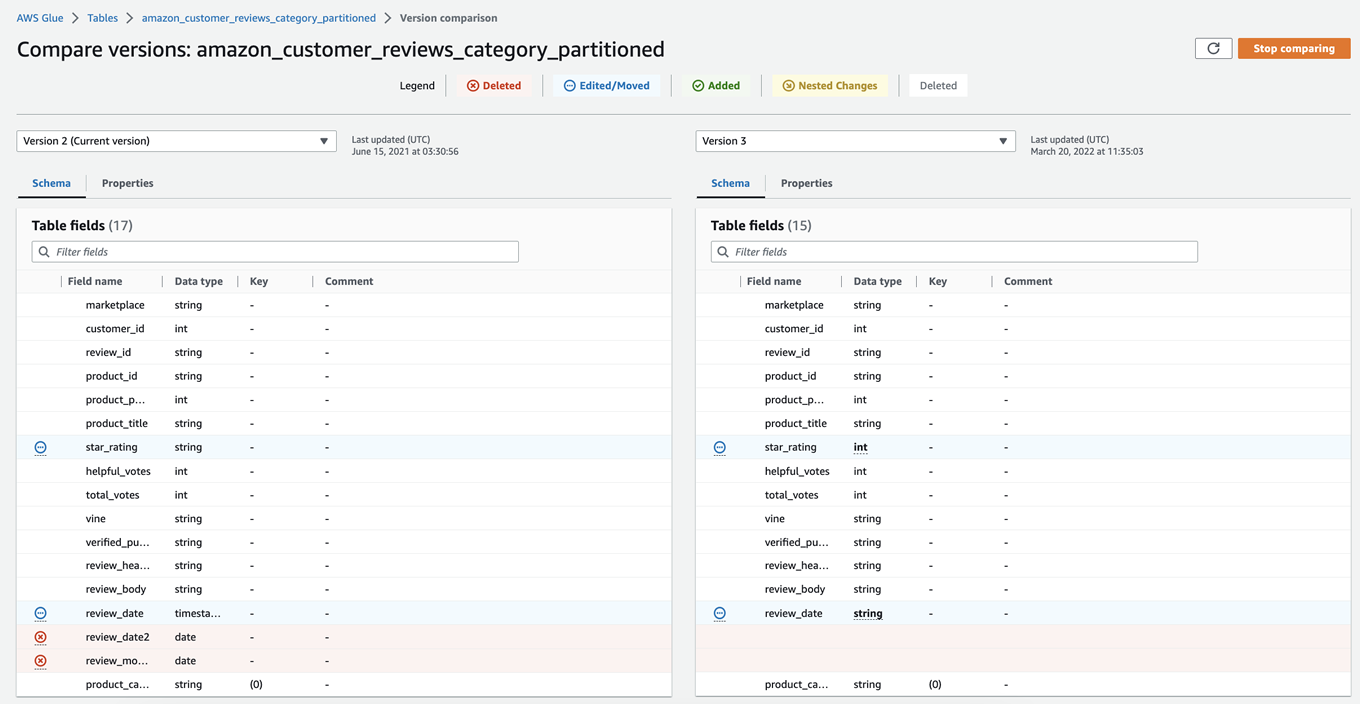
カタログのバージョニング
カタログ情報を変更した際、変更前と変更後の内容をあとで比較する必要があります。AWS Glueカタログでは、カタログの変更はバージョニングされ、あとで任意のバージョン間の違いを比較できます。以下はAWS Glueカタログのバージョン履歴です。
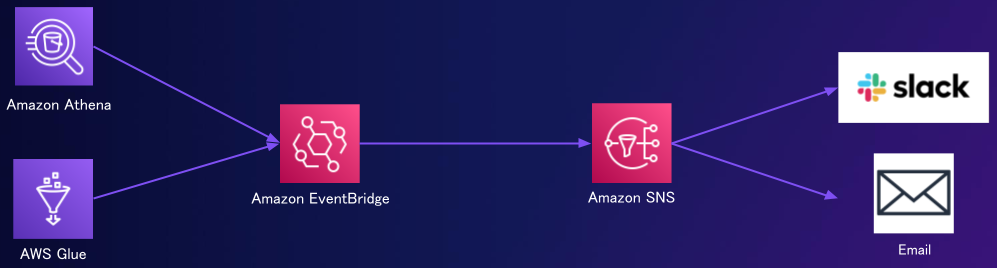
メタデータのモニタリング
データによっては、頻繁にスキーマ変更が起こる場合もあります。そうした場合は、Amazon Event Bridgeというサーバーレスイベントバスサービスと、Amazon SNSという通知サービスを利用して、Slackやメールなどで通知できます。
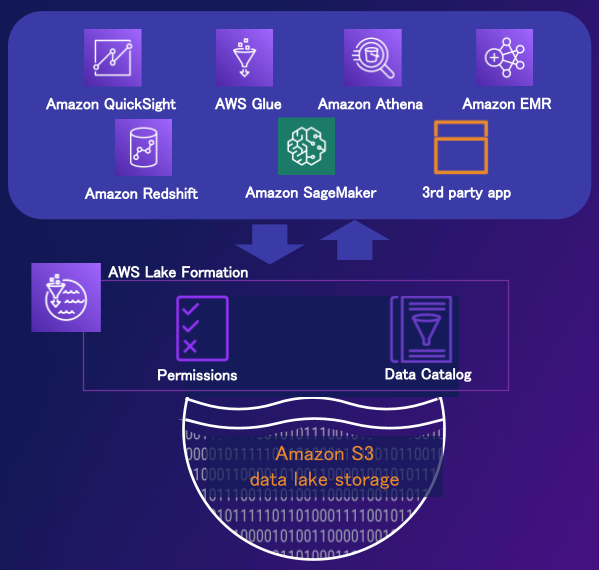
AWS Lake Formationによるデータ権限管理とデータメッシュ
データプライバシーと権限管理の機能として、AWSには、AWS Lake Formationがあります。AWS Lake Formationは、AWS Glueカタログに登録されたAmazon S3上のデータに対して、ファイル単位ではなく、データベース/テーブル/列/行単位でのきめ細やかな権限管理を実現します。
また、リソースごとに権限管理をする場合、ユーザやテーブルが増えると指数関数上に管理対象の権限の組み合わせが増えてしまいます。しかしAWS Lake Formationでは、より楽に権限管理を行えるように、以下のようにタグベースの権限管理をサポートしています。
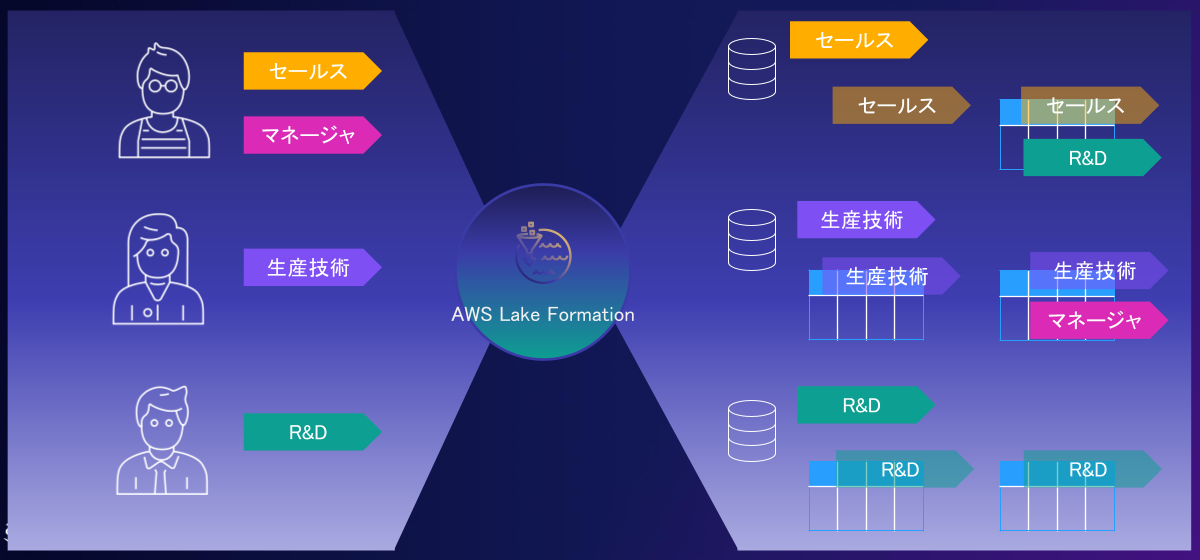
AWS Lake Formationを用いたデータメッシュの実現
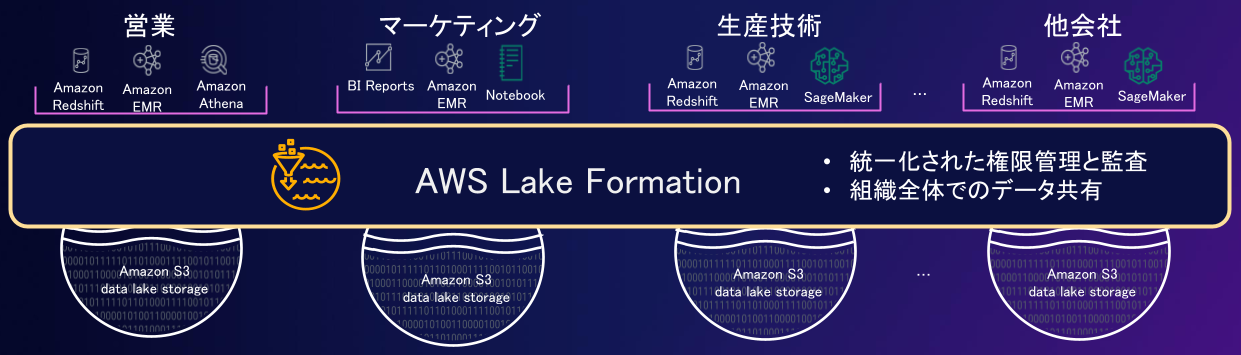
AWS Lake Formationは、単一のAWSアカウント上での権限管理の他に、クロスアカウントでの権限管理をサポートします。このため、このAWS Lake Formationを利用してドメインごとにセルフマネージドなデータ基盤間のデータメッシュ環境を構築できます。
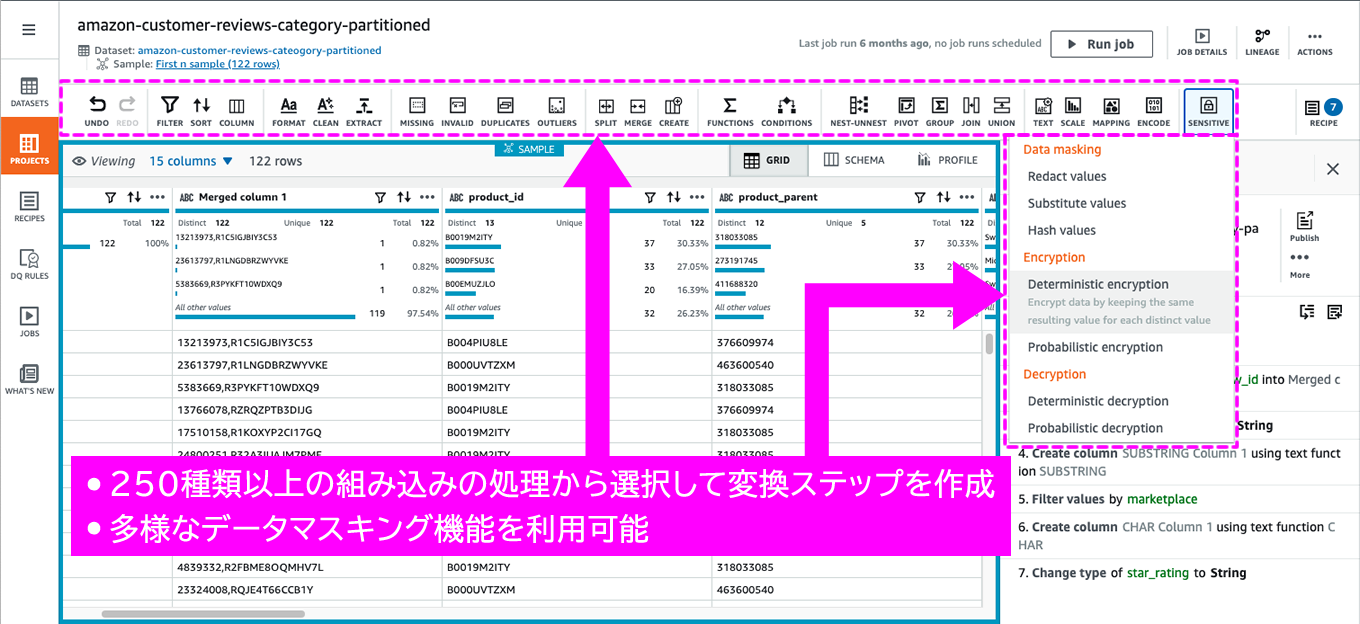
AWS Glue DataBrewによるデータマスキング
AWS Glue DataBrewには、
AWS Glue DataBrewを利用したデータ品質管理
AWS Glue DataBrewのもう一つの機能として、データプロファイリングがあります。このデータプロファイリングでは、データの分布といった一般的な内容のほか、ユーザが指定したルールに従ってデータ品質チェックを行うことができます。
ユーザが指定するルールには、例えば欠損値がX%以下であること、ある列の値がX以上であることなど、さまざまなバリエーションを指定できます。
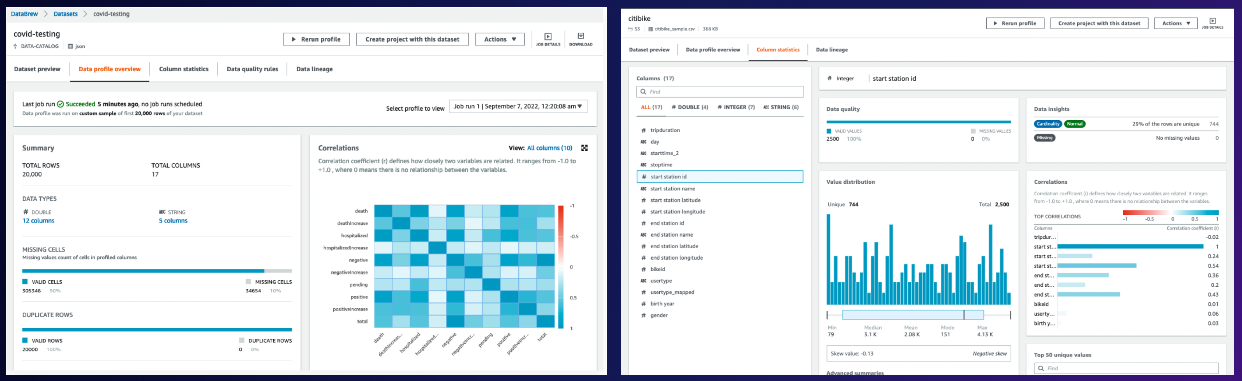
また、PIIデータの検出もこのプロファイリングできます。AWS Glue DataBrewはデータの内容から、ルールのレコメンドも行ってくれます。プロファイリング結果はS3上にJSONファイルとして格納され、Amazon EventBridgeと組み合わせてメールやSNSなどでアラートを発出することも可能です。
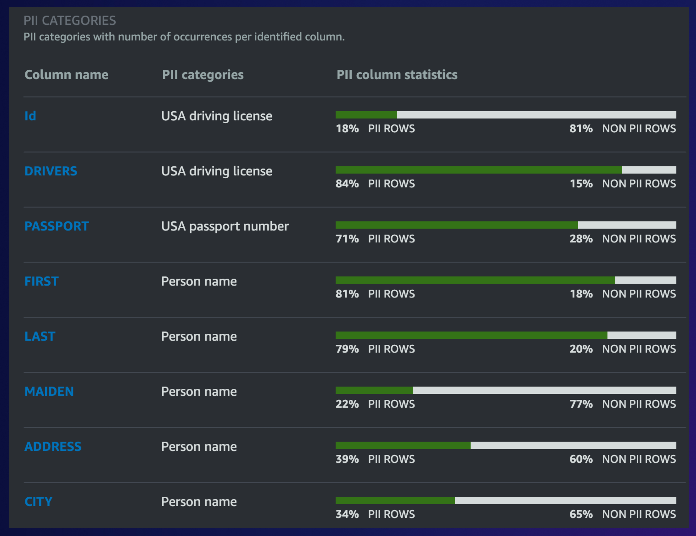
なお、re:Invent 2022で、AWS GlueのData Quality機能
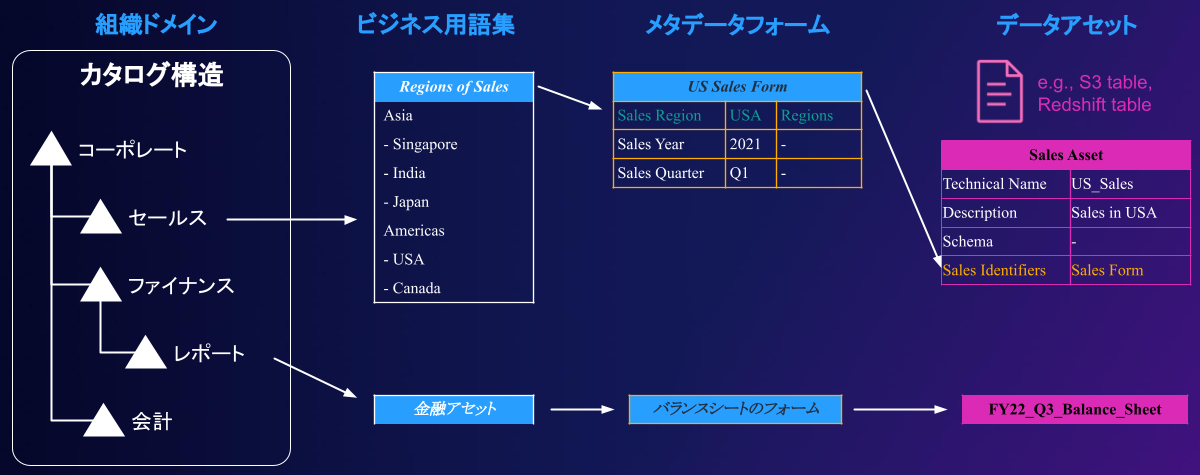
Amazon DataZoneによるビジネスデータカタログの提供
re:Invent2022において、ビジネスデータカタログとして、Amazon DataZone
Amazon DataZoneは、以下のようにAWS Glueカタログに登録されたデータ及びAmazon Redshift上のデータに対して利用できます。
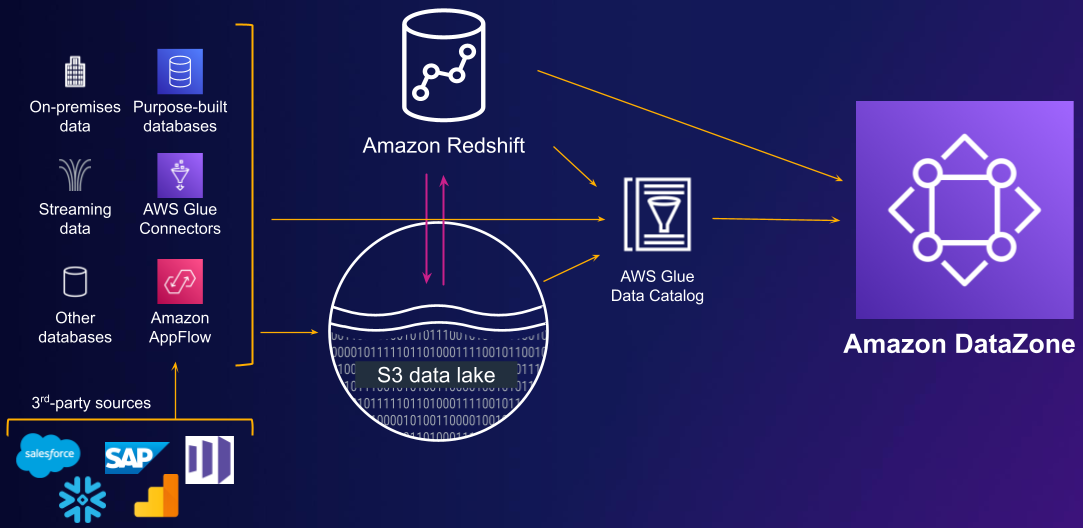
Amazon DataZoneは、クロスアカウント環境のデータを一つのデータポータルで管理できます。また、AWSおよびサードパーティのコネクタやソリューションと組み合わせることで、様々な形でデータ共有を行うことができます。
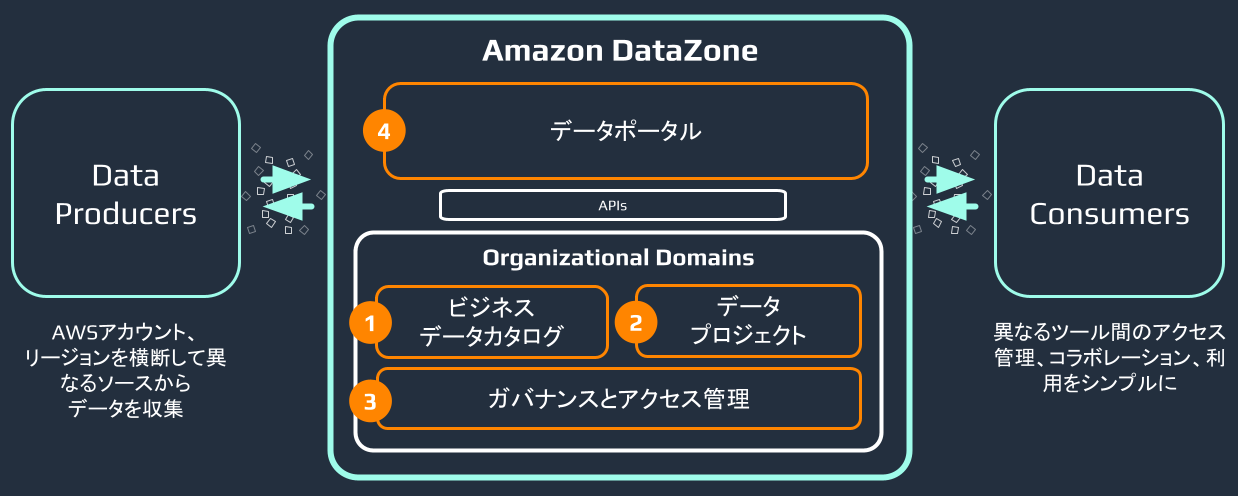
AWS Clean Roomsによる他組織へのセキュアな分析環境の提供
re:Invent2022では、もう一つ、AWS Clean Rooms

AWSにおけるコスト管理ソリューション
AWSでは、AWS Cost Explorerを利用して、クラウド利用コストの分析を行うことができます。日毎、月ごとといった分析のほか、サービスによってはタグによる分析なども可能です。また、サイズ適正化、Savings Planの利用などの推奨事項の提案も行います。
より細かな分析を行いたい場合は、定期的にAmazon S3にExportして、Amazon AthenaやAmazon Quicksightを利用した分析も可能です。
まとめ
今回は、データ管理とはなにかについて説明し、AWSのアナリティクスサービスを利用してデータ管理を実現する方法について述べました。
次回はデータパイプラインの管理についてお届けします。