



はじめに
こんにちは! 逆瀬川
この連載では、OpenAIが提供しているChatGPTや、それらのAPIを用いてプログラミングに活かすことを目的とした内容を取り扱っていきます。これからChatGPTを使おうと思っている人、ChatGPTでサービスを作ってみたい人などの助けになればと思います。
ChatGPTとは?
はじめに、ChatGPTについておさらいをしていきましょう。
ChatGPTとはOpenAIが2022年11月にリリースしたGPT-3 (またはGPT-4) という言語モデルを使ったチャットサービスです。GPTは
なお、Transformerは2017年に発表された
GPT-3やGPT-4は、なにでできているの?
GPT-3はCommon Crawlという大規模Webクロールテキストなどからできています。Common Crawlはトレーニング時の重みとして実に60%を占めています。このうち各言語の含有率は英語が50%程度であり、日本語は5%です。
| データセット | データセットの規模 |
データセットの寄与度 |
|---|---|---|
| Common Crawl(filtered) | 410 billion | 60% |
| WebText2 | 19 billion | 22% |
| Books1 | 12 billion | 8% |
| Books2 | 55 billion | 8% |
| Wikipedia | 3 billion | 3% |
大量の文章から学習することで、多言語を取り扱う能力だけでなく、高度な推論能力まで手に入れました。
GPT-3.
ChatGPTの学習データを考えることはその能力を発揮させるときに極めて有効です。質問時も以下のように、


知ったかぶりをするChatGPT
ところで、ChatGPT

ChatGPTが答えてくれたように、ChatGPTに使われているGPT-4やGPT-3.
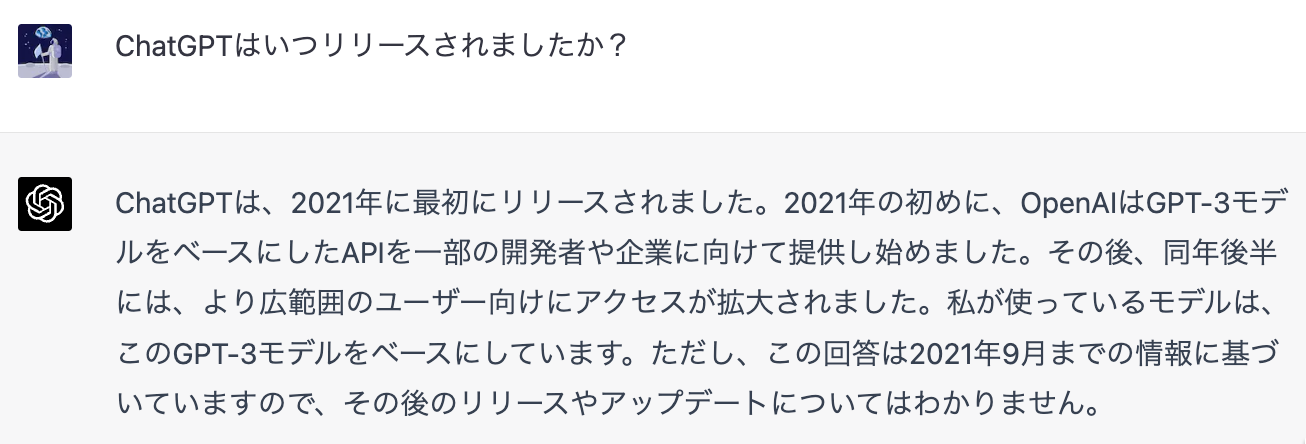
どうやら
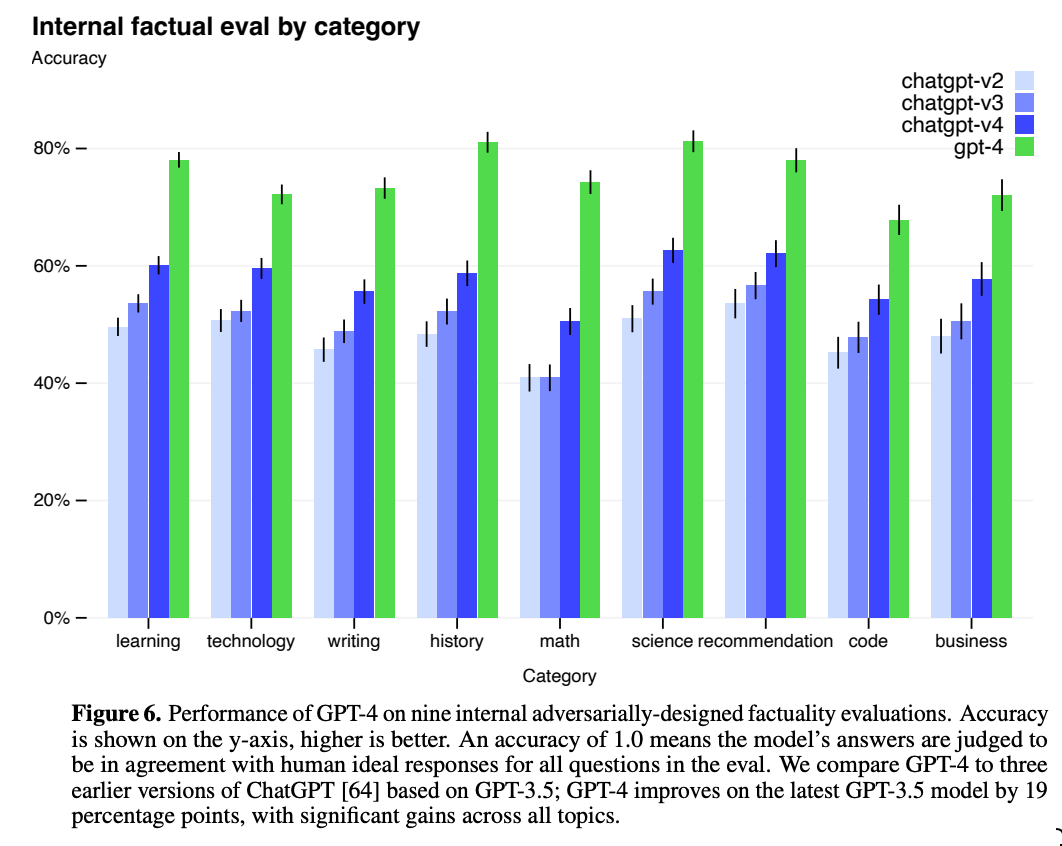
一方で、先の質問・
プロンプトエンジニアリング
ChatGPTに問い合わせをするときの文章を
ここでは軽く、すぐ使える便利な技法を紹介しておきます。
「あなたは○○です」
awesome-chatgpt-promptsで紹介されている技法です。たとえばUI/
-
UX/
UI開発者として活躍してほしい。アプリ、ウェブサイト、その他のデジタル製品のデザインについて詳細を説明します。ユーザー エクスペリエンスを向上させるための創造的な方法を考え出すのがあなたの仕事です。これには、プロトタイピング プロトタイプの作成、さまざまな設計のテスト、最適な設計に関するフィードバックの提供が含まれる場合があります。私の最初のリクエストは、 「新しいモバイル アプリケーション用の直感的なナビゲーション システムの設計を手伝ってほしい」 です。
Zero-Shot CoT
CoT (Chain-of-Thought) とは中間の推論ステップを用いて推論能力を向上させるための仕組みです。Zero-Shot CoTは質問文章に
X-Prompt
特定の概念に変数を定義して呼び出す手法です。論文で言及されているように、画像生成におけるTextual Inversion技法と似ています。最近のプロンプトデザイン等でもこの派生系が使われています。
ChatGPTがプログラミングでできること
次に、プログラミングの際にChatGPTを活用することを考えてみます。
ChatGPTのオプトアウト
まずはじめに、業務でもしChatGPTを使う場合はOpenAIのフォームからプロンプト
APIはデフォルトでオプトアウトですが、ChatGPT自体はデフォルトがオプトイン
どのように使うか
主要な使い方は以前わたしがQiitaに掲載した
エンジニアがChatGPTを使うときは大きく分けて以下の用途があり得るでしょう。
- 実装理解
- 実装説明生成
- アルゴリズム解説
- 設計
- 仕様書作成
- DB設計作成
- アーキテクチャ図生成
- 実装
- コード生成
- テスト生成
- ドキュメント
- コメント生成
- ドキュメント生成
- サービスへの活用
- インターフェースとしての対話システム導入
- モジュールとしての文章生成・
要約・ 選択処理
設計、実装、ドキュメント等ではすでに優れた記事が出てきているので他に譲り、ここでは特に有用である実装理解とサービス活用についてフォーカスして説明します。
実装理解
ChatGPTの能力のうち、実装の理解補助がもっともエンジニアの助けになるものだと思います。
たとえば、わたしは以前
-
あなたは優秀なソフトウェアエンジニアです。
以下のコードについて段階的にかつ論理的に考えて、実装の内容を説明してください。``` from moviepy import editor from moviepy.video. io. VideoFileClip import VideoFileClip import budoux def generate_ subtitle (vid, transcribe, max_line_ ): input_length = 14, max_ lines = 2 file_ name = video_ folder + f"{vid}.mp4" output_ file_ name = video_ folder + f"{vid}_subtitle. mp4" video = VideoFileClip(input_file_ name) annotated_ clips = [] last_ end = 0 for segment in transcribe['segments']: seg_ start_ sec = int(segment['start']) seg_ end_ sec = int(segment['end']) seg_ text = segment['text'] result = translator(seg_ text) seg_ text = result[0]['translation_ text' ] if last_end != seg_ start_ sec: print("skip: %s to %s" % (last_ end, seg_ start_ sec)) annotate_ seg = video. subclip(last_ end, seg_ start_ sec) annotated_ clips. append(annotate_ seg) seg_ all_ sec = seg_ end_ sec - seg_ start_ sec parsed_ text_ list = sentence_ parse_ and_ line_ parse(seg_ text, max_ line_ length, max_ lines) section_ per_ sec = int(seg_ all_ sec / len(parsed_ text_ list)) print("jimaku: %s to %s" % (seg_ start_ sec, seg_ end_ sec)) if section_ per_ sec == 0: section_ per_ sec = 1 for i, parsed_ text in enumerate(parsed_ text_ list): section_ start_ sec = seg_ start_ sec + section_ per_ sec * i section_ end_ sec = seg_ start_ sec + section_ per_ sec * (i + 1) if i == (len(parsed_ text_ list) - 1): section_ end_ sec = seg_ end_ sec print(" ketsu: %s" % section_ end_ sec) if section_ end_ sec >= video. duration: section_ end_ sec = None annotate_ seg = annotate(video. subclip(section_ start_ sec, section_ end_ sec), parsed_ text) print(" section start: %s, end: %s, text: %s" % (section_ start_ sec, section_ end_ sec, parsed_ text)) annotated_ clips. append(annotate_ seg) last_ end = seg_ end_ sec print(last_ end) print(f"last_ end is {last_ ) if last_end} and video.duration is {video. duration} "end != None and video. duration >= last_ end: print("skip: %s to %s" % (last_ end, video. duration)) annotate_ seg = video. subclip(last_ end, None) annotated_ clips. append(annotate_ seg) final_ clip = editor. concatenate_ videoclips(annotated_ clips) final_ clip. write_ videofile(output_ file_ name, audio_ codec="aac") ```
これをChatGPT
-
このコードは、与えられた動画ファイルに字幕を追加するPythonプログラムです。具体的には、次の手順で処理が行われます。
- 必要なライブラリとモジュールをインポートする。
generate_関数を定義する。この関数は、以下の引数を受け取ります。subtitle vid: 入力動画ファイルの名前(拡張子 .mp4を除く)transcribe: 字幕の情報が入った辞書型データmax_: 1行の字幕の最大文字数line_ length max_: 1つのセクションに表示する最大行数lines
- 入力ファイル名と出力ファイル名を生成します。
- 入力ファイルから
VideoFileClipオブジェクトを作成します。 - トランスクリプトの各セグメントについて、字幕を付け加えたクリップを作成し、
annotated_リストに追加します。clips - 最後のセグメントの終わりから動画の終わりまでの区間があれば、その部分のクリップも
annotated_リストに追加します。clips annotated_リストに格納されたクリップを連結して、最終的な動画を作成します。clips - 作成した動画を出力ファイル名で保存します。
このプログラムは、
moviepyライブラリを使用して動画を操作し、budouxライブラリを使用してテキストの改行処理を行っています。また、このコードは、与えられたトランスクリプトデータ( transcribe)から字幕を生成し、動画に追加する部分のみを示しています。実際に動作させるためには、トランスクリプトデータを生成する関数や、テキストを翻訳・ 改行するための関数、動画に字幕を追加する関数 ( annotate)などが必要です。
この威力を見ると、ドキュメントの未来も見えてきます。いままでわたしたちは老化していくドキュメントに悩まされていましたが[1]、これからはおそらくpull-request時にドキュメントは自動で更新され、それを確認し必要な箇所を修正するだけで良いというフローが生まれてくるでしょう。
サービスへの活用
ChatGPTを活用したサービスは無数に考えられます。特に、サービスのフローにおいて
また、awesome-chatgpt-promptsで見られるように、ChatGPTはなりきりチャットが得意です。そのため、アドバイザーやコンサルのような領域では専門家に相談する前の簡易相談相手として活躍してくれるでしょう。
さらにMakeやZapierなどのIPaaS系のサービスと連携して、モジュールとして活用するとより真価を発揮できます。アイデアに困ったら、Makeなどの対応モジュール一覧を眺めてみるのも良いでしょう。
まとめ
今回は、次の事柄を取り上げました。
- ChatGPTは大量のテキストを学習した言語モデル
- データセットにおいては英語が多く、またPythonのコードを大量に学習している
- エンジニアの活用手段としては実装理解の補助がとても強力
- サービス活用においては
「人間がいままで作業していた部分」 の置き換えを意識するとアイデアが出やすい
次回以降は、実際のサービス開発などを題材にしてChatGPTの活用の具体例を示していければと思います。また、参考文献を以下に示します。歴史順に並んでいるので、なぜ言語モデルがここまで上手くいっているのかもっと知りたいかたはぜひ読んでみてください。
参考文献:
- Attention Is All You Need
- Transformer論文
- Encoder-DecoderタイプのTransformer Modelが紹介されている (GPTはDecoder-Only)
- Language Models are Few-Shot Learners
- GPT-3論文
- Evaluating Large Language Models Trained on Code
- Codex論文
- GPT-4 Technical Report
- GPT-4のテクニカルレポート
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- CoT論文
- Large Language Models are Zero-Shot Reasoners
- Zero-Shot CoT論文
- Extensible Prompts for Language Models
- X-Prompt論文