



株式会社primeNumberでChief Product Officerを務めている小林寛和と申します。
私は新卒から今までデータエンジニアとしてキャリアを歩んできました。新卒で入った事業会社ではデータ分析基盤の新規構築をリードし、現在ではtroccoというデータエンジニアのためのサービスを立ち上げてプロダクトの責任者を務めています。
キャリアの大半をデータエンジニアとして過ごし、さらに現在ではそれらの方に向けてサービスを提供している立場として、これからデータエンジニアになろうとしている方に最初に学んでほしい3つのポイントをまとめてみました。
なお、本記事では以下のような方を想定しております。
- これからデータエンジニアになろうとしている
- これからデータ分析基盤を新規に立ち上げようとしている
データエンジニアリングの必修科目とは
データエンジニアリングの必修科目を考えるために、まずはどのようなデータ分析基盤を作ることになるのかをイメージしてみます。
その中で、最初に学ぶべきものと、あえて最初は学ばないものを区別します。ここは筆者の経験により判断していますが、
そして学ぶべき3つの技術要素については記事の後半で詳細に実装方法などをご紹介していきます。
データ分析基盤のアーキテクチャイメージ
まず、最小構成でデータ分析基盤を構築した際に必要な技術をまとめたイメージを作ってみました。
もちろん用途や目的によってアーキテクチャは大きく変わってくるとは思います。この図では、弊社がtroccoを提供していく中で見えてきた、一般的な事業会社でデータ分析基盤を作った場合に必要となる技術スタックを組み合わせてアーキテクチャ図としています。
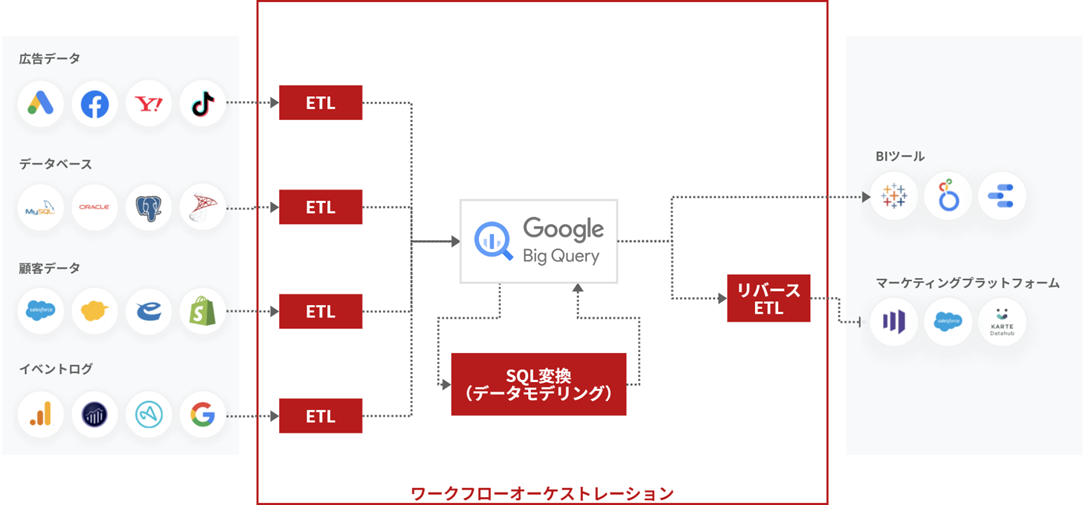
左から、社内に分散している分析データソースが各種あり、それらをETLジョブでDWH製品
最初に学ぶべき3つの技術=ETL(データ統合)+データモデリング+ワークフロー
2023年時点で、データエンジニアの必修科目を3つ挙げるとしたら、それはETLとデータモデリングとワークフローだと考えます。
1つ目の理由としては、先ほどのアーキテクチャ
2つ目の理由としては、今後データ分析基盤の利用が進んでいった場合、この3つの箇所は最も追加・
また、作業をこなせるだけでは意味がなく、将来的な拡張を見据えた仕組み化にも取り組む必要があります。例えば、開発の効率化のためにCI/
一方、前章のアーキテクチャ図の中に出現したBIツールやDWHについては
DWHとBIツールは、最初に学ばなくて良い理由
DWHとBIツールに関しては、あえてデータエンジニアが最初に学ばなくて良い項目として挙げさせていただきました。
DWH製品は一昔前まではサーバー
それゆえにエンジニアがチューニングやメンテナンスを行う必要があり、エンジニアはその領域で専門性を獲得する必要がありました。
ところがBigQuery、Snowflake、Redshift Serverlessなど、マネージドの範囲が広い製品が増えてきたため、2023年現在ではDWHの管理についてはほとんど専門性を要求されないレベルまで来ていると考えています。
もちろん基盤が成長してデータ量が増えた場合にパーティショニング・
BIツールについては、そもそも製品の種類が多く、比較検討が大変だと思います。そういった意味では知識量を要求されるのですが、どちらかというと学ぶというより、しっかりと利用者のニーズを汲み取って意見をまとめるプロジェクトマネジメント的なスキルが必要とされます。また、高機能な製品も多く存在する一方で、Looker StudioやRedashといった初級者にもおすすめの製品を検討すると良いかと思います。まずはそういったシンプルな機能のものからスモールスタートし、基盤の成長とともに利用者のニーズに合わせたツールを選ぶのが良いように思えます。
フルスクラッチ vs OSS vs SaaS
このあとはETL・
それぞれの技術について触れていく中で、具体例を挙げていきますが、大きく分けて以下の3種類に分けられると思います。
- フルスクラッチ開発
- OSS利用
- SaaS利用
以下に特徴をまとめてみました。選定の際の参考になれば幸いです。
| 開発・ |
料金コスト | 運用・ |
こんな人におすすめ | |
|---|---|---|---|---|
| フルスクラッチ開発 | 必要 | 小 | 大 | エンジニア人材が豊富で、SaaSやOSS利用ができない環境の方 |
| OSS利用 | 必要 | 小 | 中 | エンジニア人材がアサイン可能で、料金コストを抑えたい方 |
| SaaS利用 | 不要※1 | 中~大 | 小 | エンジニア人材のアサインが難しい方や、運用保守の工数を抑えたい方 |
※1 利用自体にエンジニアは不要だが、サービス自体がエンジニアレベルの専門性を必要としていることもある
どれが最適な選択かは、組織のリソース状況やフェーズによるかと思います。一方でデータエンジニア初学者の方は、学ぶべきことがそもそも多いため、ここはSaaSを選択して
ETL(データ統合)詳細
ETLとは
ETLはExtract Transform Loadの略ですが、類似語として以下のようなものがあります。
- データローダ、データロード
- データ統合、データ集約
- データ転送
これらは概ね同じ意味を示しており、要するに組織内に分散している分析データソースを、1ヵ所
また、

Extractでは、分析データソース側のAPIを利用してデータを取得します。この際APIから渡されるデータは、データソース側に依存しているため、ファイル形式や圧縮形式は、データソースによって異なる点に注意です。
Transformのプロセスは最も複雑で、まずはExtractで取得されたデータをETLシステムで扱える形式に変換します。データが圧縮されていたら解凍し、CSVやJSONのデータをETLシステムで扱えるフォーマットに変更します。変更するフォーマットは、なんのETLシステムを採用するかによって変わります。PySparkを選定したのであればPythonのDataFrameにしますし、フルスクラッチ開発するのであれば、利用しているプログラミング言語で扱える行列形式のデータ型に変換する必要があるでしょう。
次に、データ変換処理を行います。行や列の絞り込みや、値の変更、集計処理を実施します。
その後、Load処理を行うためにデータのフォーマットや圧縮を行います。どのようなフォーマット・
最後にLoadですが、DWH製品のAPIをコールし、Transformプロセスで生成されたデータをアップロードします。
最近のトレンドはELT?
また、昨今ではETLではなくELTというアプローチが主流になりつつあります。
ETLとELTの違いを図にすると図3のようになります。
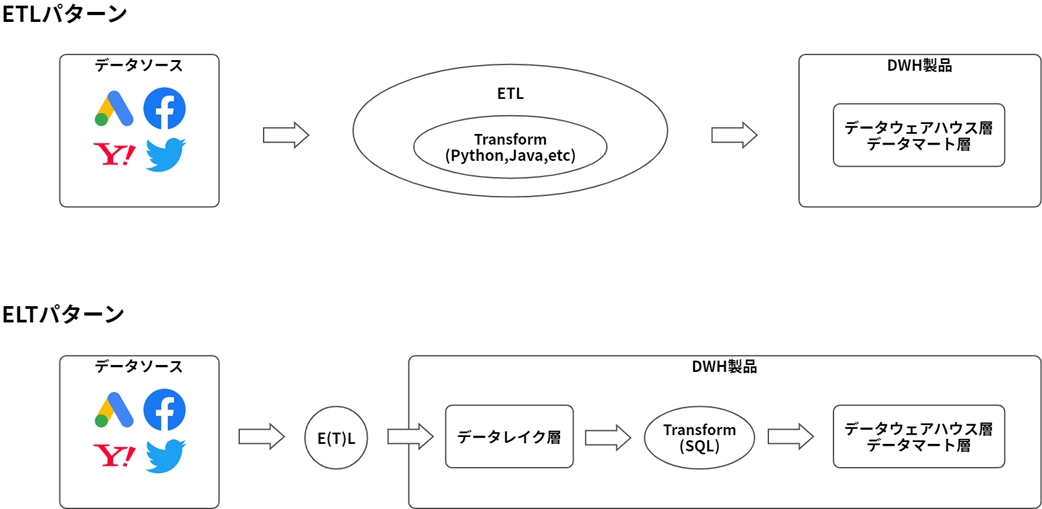
分析データソースからデータを取得し、DWH製品に集約するという点ではどちらも共通していますが、その過程が異なります。特にTransformの過程が大きく異なる点に注目です。
ELTパターンでは、データソースのデータをそのままの形で変換せずにDWH製品に取り込みます。この時に生成されるDWH上のテーブルを
そしてTransform処理はDWH製品上で、SQLを用いて行います。
SQLを用いて変換を行うため、実装難易度が低い点がメリットになります。そのためアナリストの方でも実装ができたり、Transformのためのシステムを必要としません。
その一方で、SQLで表現するのが難しい処理には向いていないというデメリットも存在します。たとえば、外部APIをコールするような処理や、複雑な文字列変換などです。
詳しくは私が執筆したQiitaの記事でも解説しているので良かったら参考にしてください。
ETLの実装方法紹介(OSS/SaaS)
ETLを実現するための技術は数多く存在しており、ここではほんの一部ではありますが、ピックアップしてご紹介します。
| タイプ | 名前 | 一言解説 |
|---|---|---|
| OSS | Spark | 並列分散処理フレームワーク。大容量データの処理を高速に行うならば最適。 |
| OSS | Embulk | 国産OSS。プログラミングが必要がなく、YAML形式の設定ファイルだけでデータ転送が可能。 |
| OSS/ |
Airbyte | 海外OSS。Embulkとコンセプトは似ていて、海外サービスの対応が豊富。ホスティング版のSaaSも存在。 |
| SaaS | trocco | 国産SaaS。主にEmbulkを処理エンジンに採用し、ブラウザでETLを実現できたり、その後のデータマネジメントも可能にする。 |
| IaaS/ |
AWS Glue | AWSが提供している、Sparkのホスティング環境。Sparkを利用する際に課題となるクラスタ管理などをマネージドサービスとして提供している。 |
データモデリング詳細
データモデリングとは
データモデリングとは、分析データの整備方法を考えることです。DWH製品上にあるデータを、高品質かつビジネス活用しやすい形で整備することです。データモデリングをもう少し要素分解すると、以下の2つの項目をそれぞれ考える必要があります。
- モデリングの設計
- モデリングの実装
モデリングの設計では、最終的にどのような粒度・
また、0ベースで考えるのではなく、3層構造・
モデリングの実装の話では、モデリングの設計に基づき、実際にどうやってテーブルを作るかを検討します。
DWH製品上でSQLを実行することによってテーブルを作るという点ではどの手法も共通しているのですが、その抽象度や提供形態
これらはデータ分析基盤を立ち上げたタイミングである程度考える必要があると考えます。
データモデリングの実装に必要な構成要素
データモデリングを実装する際、まずはじめに検討すべきは、シンプルにSQLのみを利用してすべて実装する方法です。DWH製品はSQLを実行するためのAPIを提供していますし、管理画面からSQLを実行する方法を提供していることも多く、もっとも簡単な実装方法と言えるでしょう。
しかし、この方法ではSQLやテーブルの管理に悩まされることになります。実際にデータ分析基盤を提供してみると、ETLで作られたデータレイク層よりもSQLによって変換・
そこで昨今では、dbtやDataformといったデータモデリングツールが注目を浴びています。データモデリングツールは、こういった悩みを解決するために、以下のようなSQLを管理しやすくするための仕組みを提供しています。
- SQLの可読性・
再利用性を高めるテンプレートエンジン・ マクロ機能 - SQLから生成されるデータの品質を担保するためのテスト機構
- SQL・
テーブルの依存関係を解決するための仕組み
データモデリングをリードできるエンジニアがいる場合や、アナリストが積極的にデータを活用し始めたタイミングでこういったツールを検討するのが良いでしょう。
データモデリングの実装方法(スクラッチ開発/OSS/SaaS)
以下に、データモデリングを実装する際に利用できる技術をまとめました。
最低限の要件としては、SQLを定期的ないしイベント駆動で実行できる仕組みです。
| タイプ | 名前 | 実行方式 | 一言解説 |
|---|---|---|---|
| OSS/ |
dbt | 定期実行 CIツールからトリガー APIからトリガ |
データモデリングツールの筆頭格。SaaS版のdbt CloudにはIDEも実装されており、SQLの開発・ |
| OSS/ |
Dataform | Cloud Schedulerから定期実行 | dbtとともにデータモデリングツールの筆頭格。コンセプトは似ている。2020年にGoogleが買収し、2023年5月にGCP上でGA版が公開された。 |
| SaaS | trocco | 定期実行 APIからトリガー ワークフローエンジンから実行 |
国産SaaS。シンプルにSQLを実行するモードと、dbt連携機能が存在。 |
| SaaS | 各種DWH製品 | 定期実行 | 各種DWH製品でもSQLを定期実行する仕組みを提供している。最小構成ではあるが、すぐにSQL自体の管理やETLとの連携が課題に。 |
ワークフロー詳細
ワークフローとは
ワークフローも類似語として以下のようなものがありますが、概ね同じ意味を持っています。
- (ワークフロー)
オーケストレーション - ワークフローエンジン
- ジョブ管理
- 依存関係
- DAG
このセクションまでにETLとデータモデリングについて触れてきましたが、これらの技術を
ETLやデータモデリングを動かす際に、大きく分けて以下2通りの方法があります。
- ETL・
データモデリングツール側の実行機能を使う - ETL・
データモデリングツールをAPIでキックし、実行制御は外部ツールを使う
ETLやデータモデリングのツールは、それぞれのツールで定期実行の仕組みが提供されていることが多くありますが、データ分析基盤が大きくなってくると、後者の方法を使わざるを得なくなります。
これは、ETL→データモデリングは処理の連動関係があることが多いためです。例えば前日分の広告データをETLし、ETLが終わってからデータモデリング
このような連動関係のことを依存関係といい、依存関係を解決するための仕組みがワークフローです。
ちなみにこの依存関係の中には、
また、ワークフローを作った後は実行・
- 定期実行
- トリガー実行
(イベント駆動)-- Pub/ SubやSNSをSubscribeする-- 外部システムからワークフローをAPI経由でキックする - アドホックな実行
定期実行はその名の通り、決められたスケジュールに沿って実行する方法です。
トリガー実行も一部の用途で必要となることが多く、例えばS3にファイルが置かれたらS3 Event+SNS+Lambda経由でワークフローを動かすなどの連携はよく見かけます。
アドホックな実行は、システム移行などの目的で単発で実行する場合や、エラー時の再実行・
ワークフローの実装方法(スクラッチ開発/OSS/SaaS)
以下に、ワークフローを実装する際に利用できる技術をまとめました。
ワークフローに求められる要件としては、DAG
| タイプ | 名前 | ワークフローエンジン | 一言解説 |
|---|---|---|---|
| OSS | Airflow | Airflow | Airbnb社が開発した、世界的に最も利用されているワークフローエンジンのOSS。 |
| OSS | Digdag | Digdag | Treasure Data社が開発したOSS。Embulkと共に利用されることが多く、国内企業での導入事例が多い。 |
| OSS/ |
Dagster | Dagster | 近年名前をよく聞くようになってきたOSS。Cloudホスティング版も存在。 |
| SaaS | Astronomer | Airflow | Airflowをエンジンに採用したSaaS。 |
| PaaS | Cloud Composer Amazon Managed Workflows for Apache Airflow |
Airflow | GCPやAWSもAirflowをホスティングしたサービスを提供している。 |
この先に学ぶべきこと
そもそもデータエンジニアが学ぶべき技術領域が非常に多岐に及ぶということは、前回の記事にて説明してまいりました。
今回ご紹介したETL、データモデリング、ワークフローは、最初の1歩として学ぶべき技術領域としてご紹介してきましたが、まずは実際にデータ分析基盤を作ってみてください。大小は問いませんので、データを分析できる環境を作り、ビジネスに活用する部分を実践してみていただきたいです。
するとデータ分析基盤で
そうして広く使われるデータ分析基盤に成長してくると、
たとえば以下のような課題領域です。
- データの民主化
(メタデータの蓄積、データカタログの構築) - データの品質を担保する
(データオブザーバビリティ、データ品質モニタリング)
ここで学べる技術は非常に専門性が高く、なおかつビジネスドメインに依存しにくい汎用的なものです。
重い一歩かもしれませんが、踏み出してみる価値があるのではないでしょうか。