


前回は、cgroup v2から使うioコントローラの話題を取り上げました。今回も前回に引き続きioコントローラについて書こうかと思ったのですが、cgroup v2のioコントローラが持つ機能は想像以上に難解で、記事を書けるほどの理解が得られていないので、今回はcgroup v2から使うCPUコントローラの話をしたいと思います[1]。
この連載でCPUコントローラについて書いたのは、2014年に書いた第4回でした。このときはまだcgroup v2はありませんでしたので、cgroup v1[2]を使った説明でした。
このあと、cgroup v2が実装され、cgroup v2でしか使えない機能が多数実装されています。前回紹介したioコントローラとメモリコントローラの連携もそうです。
しかし、実はCPUコントローラはcgroup v1とv2で機能にはほぼ差がありません。cgroup v2がstableになったあとに追加された機能は、v1にもきちんと実装されています[3]。ただ、cgroup v2については、インターフェースとなるファイルが第49回で紹介した規約に従うようになっていますし、細かいところでは改良のためか仕様が変わっていたりします。
そこで、今回はcgroup v2からCPUの帯域幅制限を行う場合の操作を紹介し、その後追加された機能についても紹介していきたいと思います。そして、CPUコントローラから使う帯域幅制限機能について、少しだけ奥深く分け入ってみましょう。
CPUコントローラで行う帯域幅制限
まずは帯域幅制限を設定する方法と、帯域幅制限がどのように動くかを簡単に説明しましょう。
cgroup v2で、CPUコントローラを使って帯域幅制限を行う場合に使う主なファイルは表1のファイルです。v1での設定方法は第4回をご覧ください。
| パラメータ名 | 機能 | 操作 |
|---|---|---|
cpu. |
帯域幅制限を行う単位となる期間とその単位時間内での制限値。フォーマットは"max 100000" |
読み書き |
cpu. |
cgroup内のタスクが使用したCPUの統計値の表示 | 読み込み |
cgroup v1では、設定値ごとにファイルがわかれ、各ファイルに1つだけ値を設定していました。それに対して、v2では1つのファイルに2つの値を書き込みます。読み込んだ際も同じフォーマットで出力されます。第49回で説明したスペース区切りの複数の値に相当します。
cpu.には、期間と制限値を設定します。設定した期間の間に、制限値で設定した時間だけCPUが使用できます。これはv1のときと同じです。
デフォルト値は期間が100ミリ秒、制限値は設定されておらずmaxという文字列が設定されています。maxは無制限を意味します。
ここで設定する制限値はCPU 1つあたりの値です。複数のCPUコアを持っている環境で、期間100ミリ秒が設定されているときにで2CPU分の制限値を割り当てたい場合は、"200000 100000"という設定になります。
簡単に図で表すと図1のようになります。ここでは期間として100000が、1)50000が設定されています。
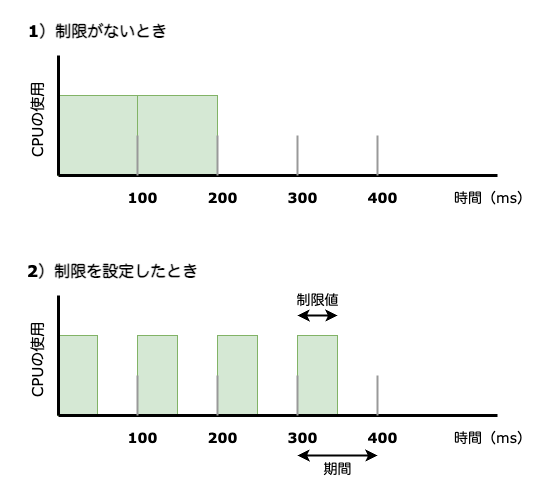
処理に200ミリ秒必要なタスクがあるとします。このタスクだけがCPUを使えるとして、制限値を設定していない場合は図1-1)
ところが、ここで制限値として50ミリ秒を設定したとすると、図1-2)
図1で帯域幅制限が効く様子を説明したところでcpu.ファイルの中身も見ておきましょう。
cpu.stat ファイルの中身| キー名 | 意味 | 出現 |
|---|---|---|
usage_ |
cgroup内のタスクが使用したCPU時間 |
cgroup v2のみ |
user_ |
cgroup内のタスクが使用したユーザCPU時間 |
cgroup v2のみ |
system_ |
cgroup内のタスクが使用したシステムCPU時間 |
cgroup v2のみ |
nr_ |
cgroup内のタスクが実行可能だった期間の数 | 常に |
nr_ |
cgroup内のタスクが制限値に達して制限された回数 | 常に |
throttled_throttled_ |
cgroup内のタスクが制限値に達して実行できなかった合計時間 |
常に |
nr_ |
cgroup内でバーストが起こった期間の数 | 5. |
burst_burst_ |
cgroup内でタスクが制限を超えて使用した合計時間 |
5. |
ここで表2の最初の3つは、cgroup v1ではcpu.ファイルに出現しません。これは、v1にはcpuacctコントローラが存在し、そちらで同じ統計値が取れるからだと思われます。ただし、v1のcpuacctコントローラで得られる値と、v2のcpu.ファイルから得られる値は単位が異なりますので注意が必要です。
その次の3つの項目はcgroupのバージョン、カーネルバージョンに関わらず表示されます。このうち、キー名がthrottoled_で始まる項目はv1とv2で単位が異なります。そのため、キー名が異なります。v1はナノ秒単位、v2はマイクロ秒単位になっており、v1ではキー名の最後が_timeとなっており、v2では_usecになっています。
nr_とburst_burst_)
それでは、nr_、nr_、throttled_で表示される3つの値について、図1-2)
nr_: 100msの期間4回分タスクがCPUを使っているので"4"periods nr_: 制限に引っかかったのは3回なので"3"throttled throttled_: 制限に引っかかって実行できなかった時間は、各期間の50msずつで3回のため3✕50msで"150"usec
このように値が入ります。
cgroup v2で設定する帯域幅制限
ここまでで、cgroup v2のCPUコントローラを使って、帯域幅制限を行う際に使うファイルについて説明しましたので、第4回で行ったように実際に制限値を設定して動きを見てみましょう。
ここからの実行例は、Ubuntu 22.
ここでは、"test01"というcgroupを作成し、期間を100ミリ秒、制限値を50ミリ秒に設定して、シェルのPIDを設定します。
$ sudo mkdir /sys/fs/cgroup/test01 (test01 cgroupの作成) $ echo "50000 100000" | sudo tee /sys/fs/cgroup/test01/cpu.max (期間100ms、制限値50msを設定) $ echo 5467 | sudo tee /sys/fs/cgroup/test01/cgroup.procs (シェルのPIDをtest01 cgroupに登録)
これでPID:5467のシェル上で次のコマンドを実行します。
$ while :; do true ; done
別にシェルを起動して、topコマンドを実行すると、次のようにCPUの使用率が50%になっており、設定した通りに制限が効いていることがわかります。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5467 tenforw+ 20 0 5044 4172 3504 R 50.0 0.1 0:05.24 bash
cpu.ファイルの内容がわかるように、簡単に試してみましょう。先の例と同様に"test01" cgroupを作成し、期間と制限値を"50000 100000"のようにcpu.に設定します。そして、シェルのPIDを"test01"に登録します。
$ sudo mkdir /sys/fs/cgroup/test01/ $ echo "50000 100000" | sudo tee /sys/fs/cgroup/test01/cpu.max 50000 100000 $ echo 5467 | sudo tee /sys/fs/cgroup/test01/cgroup.procs 5467
この状態でPID:5467のシェルで次のコマンドを実行してみます。
$ timeout 1 yes > /dev/null
1秒間CPUをフルに使います。実行直後に、すぐにシェルを"test01" cgroupからroot cgroupに移動させて、それ以上"test01"でカウントされないようにして、"test01"のcpu.を見てみます。
$ cat /sys/fs/cgroup/test01/cpu.stat :(略) nr_periods 17 nr_throttled 10 throttled_usec 495760
期間が100ミリ秒ですので、1秒間実行すると10回分です。その間、ずっと制限が効いているはずですので、制限された回数は10回となるはずです。確認すると、その通りの値がnr_に表示されています。1秒間で半分だけCPUを使うはずです。throttled_の値を見ると期待通りの値で、ほぼ500ミリ秒になっています。nr_については、cgroup作成直後からの値ですので10にはなっていません。
CPUへのクォータの割り当て
帯域制限が実際はどのように行われているかについて、ここから説明していきましょう。
制限は、使用量をカウントしていて、制限値を超えそうになったら制限するという方法で行われているわけではありません。制限するというよりは、制限値までCPUが使える権利を割り当てているというほうが適切です。この制限値までのCPU時間の割り当てを、ここではクォータと呼びます。
多数のCPUがあるような大規模システムの場合、使用量をカウントして制限しようとすると、CPUごとの使用量を集計しなければいけません。これを頻繁に行うとそれだけでかなりの負荷となります。あらかじめ制限値までCPUとは独立したところに割り当ておいて、そこからCPUに割り当てていくほうが、集計するための負荷から解放されます。
cgroupに割り当てたクォータは、cgroupごとにCPUとは独立したグローバルなクォータの
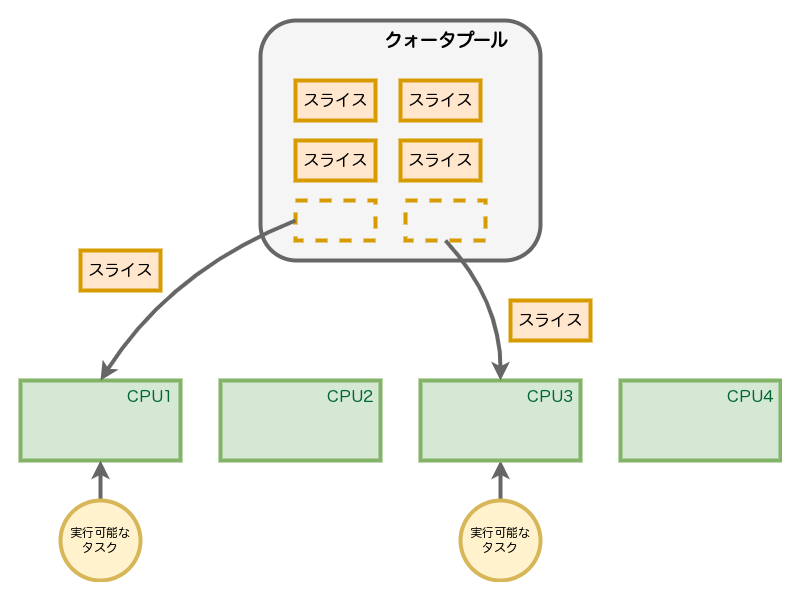
このスライスは、sysctlパラメータの sched_ で定義されています。
$ sudo sysctl -a | grep sched_cfs_bandwidth_slice_us kernel.sched_cfs_bandwidth_slice_us = 5000
上のように、デフォルトでは5ミリ秒が設定されています。つまり、5ミリ秒単位でクォータプールからCPUに割り当てられます。この値を大きくすると転送時のオーバーヘッドが減少します。また、値を小さくするときめ細やかな制御ができるようになり、ワークロードの性質に応じて、期間、制限値などと一緒に調整する必要があるでしょう。
先の例のように50ミリ秒を制限値として設定すると、図2のスライスが、期間ごとにグローバルなプールに10個割り当たるということです。そして期限をすぎるとリセットされ、また新たに設定値どおりの10個が割り当たります。
ここで、グローバルなクォータプールから複数のCPUにスライスが転送され、使われていく様子を説明してみましょう。
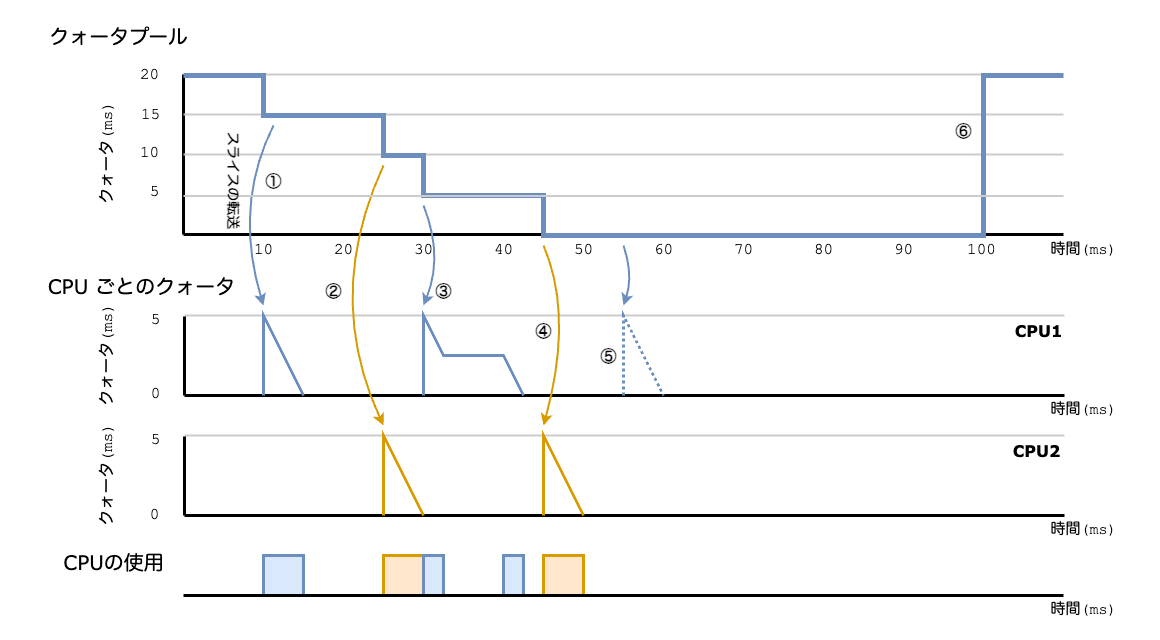
図3では、cgroupに対して20ミリ秒の制限値が設定されており、2つのCPUがが存在しています。
- ①でCPU1でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ②でCPU2でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ③でCPU1でCPUを使用するタスクから要求がありスライスが転送され、タスクは2.
5ミリ秒実行され、その後、再度CPU1でタスクからの要求があり、残っていたクォータを2. 5ミリ秒かけて使いました - ④でCPU2でCPUを使用するタスクから要求がありスライスが転送され、タスクは5ミリ秒間実行され、転送されたスライスを使いました
- ⑤でCPU1でCPUを使用するタスクから要求がありました。しかし、グローバルプールにはもうスライスが残っていませんので、この期間ではタスクは実行できません
- その後、⑥で100ミリ秒が経過し、次の期間に入ったのでクォータが20ミリ秒補充されました
CPUで要求があるたびに、グローバルプールからスライスが転送され、使われていく様子を説明しました。
もし、期間中に割り当てられたスライスを使い切らない場合は、期間終了時点でスライスはリセットされ、次の期間に新たに制限値分のスライスが割り当たります。
まとめ
ここまでで、CPUコントローラで帯域幅制限がどのように行われるのかについて、非常に簡単に、簡略化したケースを使って説明しました。
ここで
図3では、各タスクは与えられたスライスを使い切っていますし、いずれも5ミリ秒で処理をきっちり終えています。実際はそのようなことはなく、スライスを使い切ることなく処理が終わるケースもあるでしょうし、もっと長い処理時間が必要なケースもあることに気づいた方は多いのではないでしょうか。
実は帯域幅制限は今回の説明のように、単純にスライスをCPUに割り当て、期間が来るとそれまでの割り当てはリセットされ、次の期間に新たにスライスが割り当たるという処理ではありません。ただ、基本的な考え方は今回説明したとおりです。
次回は、このスライスの割り当てや返却と言った動きを説明し、帯域幅制限についてもう少し詳しく見ていきたいと思います。
参考
今回の記事を書くに当たって参考にした文書・
- CFS Bandwidth Control (カーネル付属文書)
- Control Group v2 (カーネル付属文書)
- スロットリング解除: クラウドにおける CPU の制限の修正 (Indeedエンジニアリング・
ブログ) - スロットリングの解除: 有効な修正が不具合の原因になってしまった理由 (Indeedエンジニアリング・
ブログ)