



本連載は分散型マイクロブログ用ソフトウェアMisskeyの開発に関する紹介と、関連するWeb技術について解説を行っています。
Misskeyでは、新機能の追加や改修・
今回はそういった最近のMisskeyのパフォーマンス改善の取り組みについて紹介します。
Fan-out Timeline
Misskey v2023.
Note:MisskeyではこのPush型アーキテクチャ実装を
従来のPull型の場合、ユーザーが投稿を行うとデータベースの投稿テーブルに投稿レコードが挿入され、タイムラインを取得する際はデータベースに都度クエリを発行するという一般的かつシンプルな処理になります。
この場合、投稿作成時
しかし、タイムライン読み取り時
特に、フォローしているユーザーが少なく、タイムラインを埋めるための投稿がなかなかデータベースに見つからないようなシチュエーションだと負荷が顕著に高まります。
そこで、投稿テーブルのスキャンの必要性をなくしてパフォーマンスを向上させようというのがPush型タイムラインの発想です。
Push型タイムラインはFan-out Timelineとも呼ばれ、ユーザーが投稿を行うと、投稿テーブルにレコードも挿入するのですが同時にフォロワー全員のタイムラインにも投稿を追加するというアーキテクチャです。X
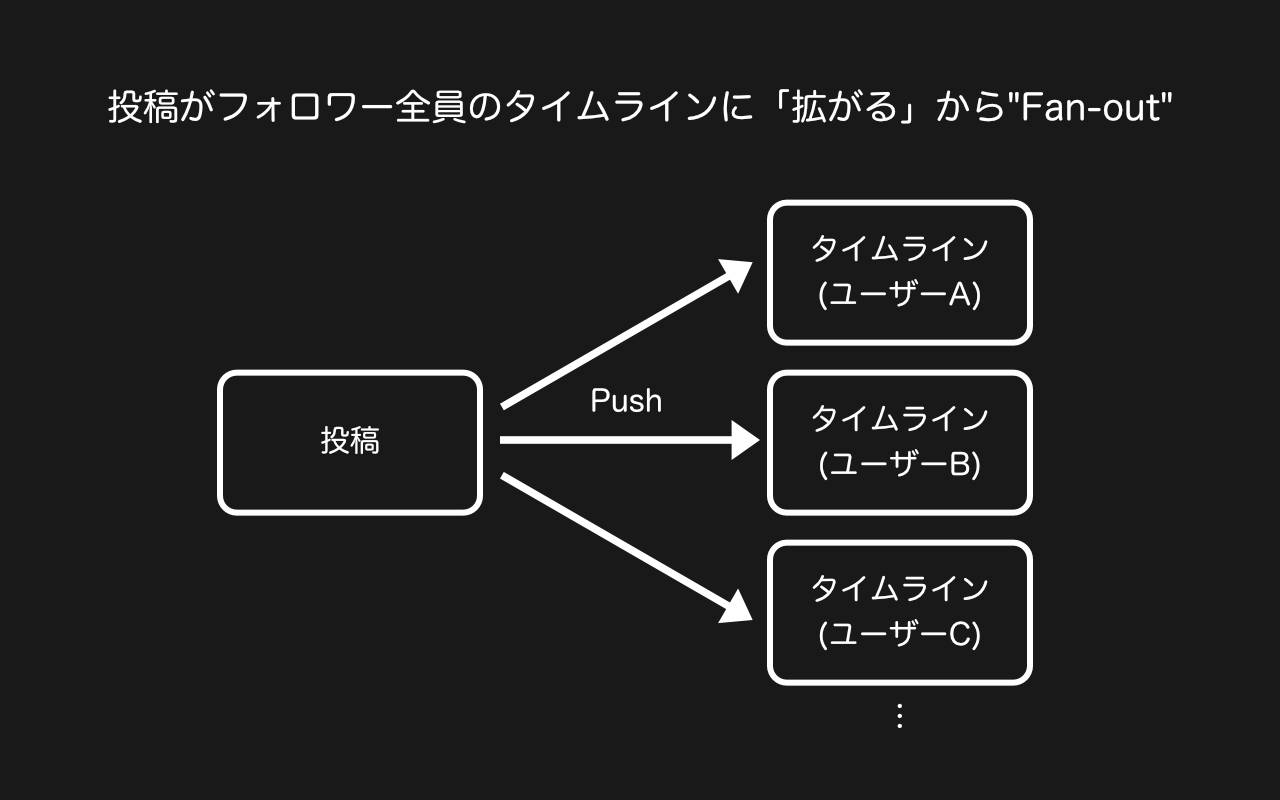
「フォロワーのタイムライン」
投稿されるたびに休眠ユーザー、およびリモートユーザー除くすべてのフォロワーのタイムラインに対して投稿の追加処理が発生するため、投稿時の負荷は高まりますが、MisskeyのようなSNSにおける負荷は:
「投稿が作成される数 <<< タイムラインが読み込まれる数」
であり、圧倒的にWriteよりReadのほうが実行される数が多いです。
そのため、Writeのパフォーマンスが悪化してもReadのパフォーマンスが改善するのであれば大きな価値があります。
このPush型タイムラインの実装は、Redisにタイムラインがキャッシュされていなかった場合のデータベースへのフォールバック処理、タイムラインが肥大化しないようにするトリム処理、write時の負荷低減のため休眠ユーザーの判定を行い、当該ユーザーには配信をスキップする処理など、考慮すべきことが多いです。比較的難しい作業でしたが無事リリースすることができ、実際に
この場を借りて、ベータテストに参加してくださったサーバー管理者の皆様、利用者の皆様に改めて感謝申し上げます。
MFMパース処理の削減
Misskeyでは投稿本文はMFM
しかしそのために必要なMFMのパース
そこでv2023.
nyaizeに関してはもともとユーザーを困らせることが目的のひとつとして実装されたものです。今回処理をサーバーサイドからクライアントサイドに移すことでnyaize処理を迂回することが可能になり
ハイライトシステム刷新
Misskeyにはハイライトという機能があります。簡単に言うと最近の人気の投稿
今までの実装方法は、まず投稿レコードごとにスコアというカラムを持っておき、リアクションやリノートが行われた際に当該投稿のスコアを1加算するなどして、
そしてハイライト取得の際は、取得する期間を絞った上で、その範囲内の投稿に対してスコアで降順にソートを行い、上位にある投稿を切り出してハイライトとして提供するという愚直な実装でした。
この方法の問題点は、投稿の数が多いとそれに比例してソートの負荷が高くなることです。
また、似たような機能にハッシュタグトレンドという直近で人気のハッシュタグを一覧できる機能もあり、こちらも投稿数が多い場合負荷が高いことが以前から問題になっていました。
そこで、それら人気のものを集計するシステムを統合し、データベースを酷使する実装ではなく、Redisを活用することでパフォーマンスを大幅に向上させる改修をv2023.
具体的には、RedisのSorted Setと呼ばれるデータ構造を利用し、投稿IDとそのスコアの組をメモリ上に保持しておきます
このランキングを用いるとスコアによるソートが非常に高速に行えるため、データベースに負担がかからずパフォーマンスが向上します。
さらに、スコアを変動させるべきイベントが発生した際、従来は律儀にどんな場合でも加算もしくは減算処理を行っていましたが、これをサンプリングするようにし、一定の確率でスコアの変動処理が行われるように変更しました。これによりスコアの操作回数を減らせるため、負荷の低減になります。
サンプリングをしたとしても、人気になるような投稿であれば
また、ランキングはそのままだと無限に肥大化してしまいますし、過去の投稿が延々とランキングに載り続けてしまいますので、定期的にリセットする必要が生じます。
しかし、単にリセットするとリセット直後にハイライトを取得した場合、十分なデータが蓄積されていませんので結果が不正確なものになってしまいます。

そこで、ランキングは
ハイライトシステムが軽量になったことで、ユーザーごとのハイライト機能などの新機能の実装も行うことができました。
ハッシュタグトレンド(チャート)
ハッシュタグトレンド機能もRedisを活用した実装に統合されたことは説明しましたが、ハッシュタグトレンドについては実はもう一つ負荷の高い処理があります。
それはハッシュタグの使用状況をグラフ
そこでチャート表示機能に関しても、Redisを活用することで大幅にパフォーマンスを向上させる改修をv2023.
具体的には、Redisに標準実装されているHyperLogLogと呼ばれる確率的データ構造
HyperLogLogに関しては数学的な話になりますのでここでは詳しく解説しませんが、簡単に言うと一定のメモリ使用量で集合内の要素数をカウントできるものになります。
ハッシュタグは、トレンドの精度を高めるため同じユーザーが何回そのハッシュタグを使ったとしても
しかし、愚直にハッシュタグごとに
そこでHyperLogLogが活躍します。HyperLogLogではメモリ使用量を増やすことなく、一覧内にユーザーを追加していくことが可能です。魔法のように聞こえますが、実際には
Misskeyの場合、
Note:このHyperLogLogは、Misskey以外ではアクセスカウンターなどの実装に用いられることも多いようです。
このように、
HyperLogLog の他にはBloom Filterといったアルゴリズムがあり、Misskeyでも活用できる場所がないか検討しています。
リアクションキャッシュ
リアクション機能はMisskeyの大きな特徴のひとつですが、Xのような
タイムラインを取得する際は、取得したすべての投稿に対して
リアクションは下手すると投稿よりも多い数がデータベースにレコードとして作成されますので、投稿ひとつひとつに対して自分のリアクションを取得するのはパフォーマンスに影響してきます。
そこで、統計的にMisskeyにある投稿のうちほとんどはリアクションが全くないか、あっても10個以下にとどまる
こうすることで、投稿を取得した際にその投稿へのリアクション数が16以下であれば、データベースに追加で問い合わせずとも自分がその投稿にリアクションしているか、そしてしているならば何のリアクションかという情報を得ることができます。
筆者のタイムラインでは、体感的に90%以上のケースで取得した投稿のリアクション数がそれ以下なので、ほとんどのケースでデータベースへのクエリ発行の必要性がなくなりパフォーマンスを向上させることに成功しました。
まとめ
今回は最近のMisskeyのパフォーマンス改善の取り組みを紹介しました。
Redisを上手く活用することで、従来のデータベースでは負荷の高い処理も高速に行うことが可能です。Redisでは操作ごとにどれくらいの計算量なのかという情報がドキュメントに記載されていますので、そこに注目して利用すると良いでしょう。
コンピュータに例えると、データーベースはCPUでRedisはGPUだと思っています。データベースはCPUのように、オールマイティに様々な処理を行えますが、速度は遅くなります。一方RedisはGPUのように、できる処理が限られますがその分高速です。
また、確率的なアルゴリズムやサンプリング処理を行うことで、精度を犠牲にする代わりにパフォーマンスを向上できるケースもあることを紹介しました。高い精度が必要ないユースケースではそれらの手法を取り入れることを検討してみてください。
ここで紹介した以外にも、細かなパフォーマンス改善は常に行っています。
今後もMisskeyのパフォーマンス改善について特筆すべきものがあれば紹介していきたいと思います。