日本電信電話株式会社(NTT)は2023年11月1日、軽量でありながら世界トップレベルの日本語処理性能を持つ大規模言語モデル(LLM)「tsuzumi」を開発、これを活用した商用サービスの提供を2024年3月に開始することを発表した。
ChatGPTに代表される対話型AIの基礎技術として注目を集めるLLMは、大規模なデータセットと計算リソースを使って学習される膨大なパラメータ数のモデルを用いるため、学習に要するエネルギーやコストがサステナビリティ、あるいは企業への経済的負担面で課題となっている。
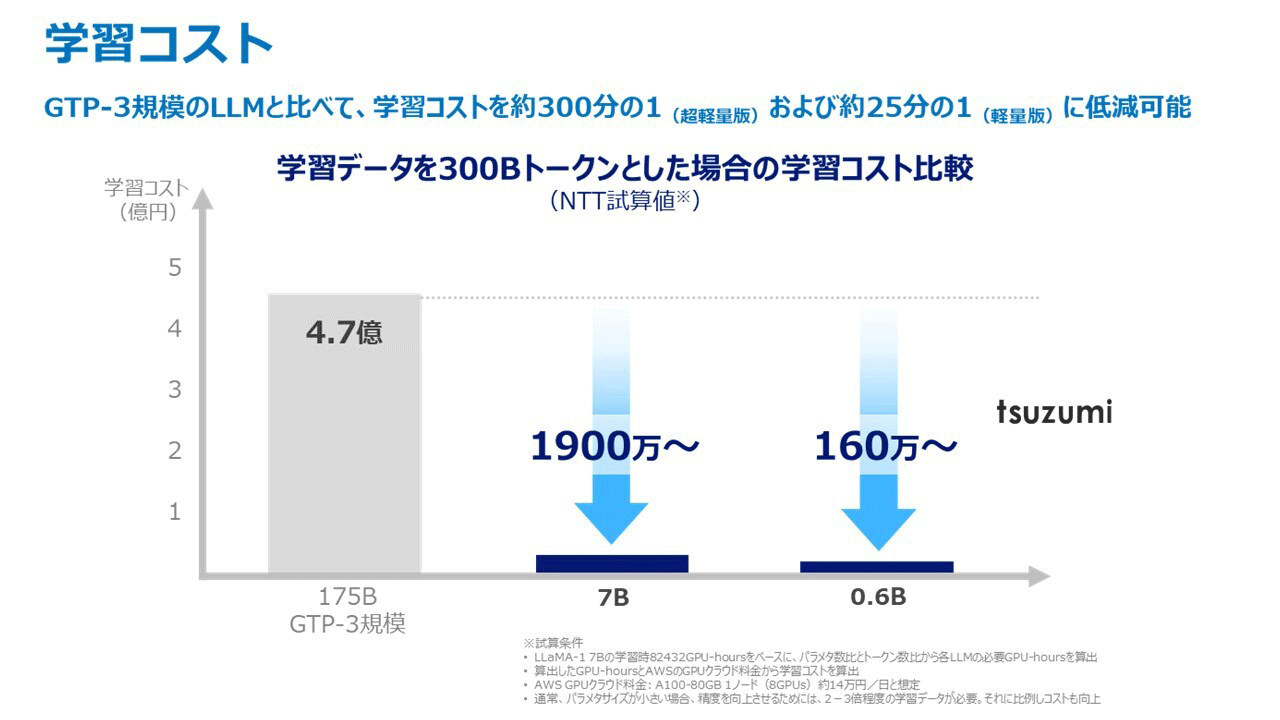
こうした課題に対応するため、NTTでは同社研究所が保有する自然言語処理研究の蓄積やAI分野の研究成果を活かし、軽量でありながら世界トップレベルの日本語処理性能を持つ大規模言語モデル「tsuzumi」を開発した。tsuzumiのパラメータサイズには6億の超軽量版と 70億の軽量版があり、Open AI製GPT-3の1750億パラメタと比べそれそれ約300分の1(超軽量版)および25分の1(軽量版)となっている。軽量版は1GPUで、超軽量版はCPUで高速に推論動作可能なため、チューニングや推論に必要なコストを抑えることが可能という。
tsuzumiとGPT-3の学習コスト比較(NTT研究開発の資料より)
また、tsuzumiは日本語と英語に対応しており、特に日本語処理性能についてはNTT研究所の長年の言語処理研究の蓄積を活かすことで、小さなパラメータサイズであっても各種のベンチマーク比較で高い精度が確認されている。
さらにLLMのチューニングで特定のタスクや目的に合わせてモデルを調整する齋に、tsuzumiでは効率的に知識を学習させることができる「アダプタ」と呼ばれる事前学習済みモデルの外部に追加されるサブモジュールを使うことで、たとえば特定の業界に特有の言語表現や知識に対応するようなチューニングを、少ない追加学習量で実現できる。
言語+視覚+聴覚のモーダル拡張も可能で、言語による質問に加え質問者の様子をふまえた回答を生成可能。音声認識では音声に含まれるニュアンスの情報も採り入れることができ、たとえば子どもが元気のない声で話しかけると「元気のない」「沈んだ」のような感情種別を内部で用いることなく子どもの「元気のない状況」をそのまま理解し、これに応じて温かみのある優しい声で励ましの声をかけてくれるような動作を実現できるようになる。これはカウンセリングやコールセンタなど、利用者の状況に応じた自動応答への活用が期待できるという。また聴覚だけでなくユーザ状況(位置情報、駐車場の混雑状況、疲労度、時間帯、ユーザの好み情報)の入力で、カーナビ、スマホナビなどのコンシェルジュ業務への適用も可能。


