



第1回では過負荷対策におけるリスクマネジメントの全体像、そして
少ないエンジニアリソースで複数のサービスのボトルネックを解析し、キャパシティプランニングを行うのは非常に難しいことです。そのため、私たちはボトルネックを解析する代わりに、ボトルネックを設計することにしました。具体的には、ほぼすべてのAPIサーバーにおいて、CPUリソースが最初に枯渇するようにチューニングしています。これにより、サーバーのキャパシティプランニングではCPUリソースの枯渇具合のみを気にすればよくなります。今回はこの具体的な手順をご紹介します。
そもそも、アクセス過多時のボトルネックを設計するためのもっとも単純で効果的な方法は、実際にストレステストを行い、その結果を細かく分析することです。しかしながら、ストレステスト環境を準備したり、実際のユーザーのリクエストを再現したシナリオを準備したりすることには大きな労力が必要です。特にキャッシュ機能があるサービスでは、同じようなリクエストを繰り返すと理想的すぎる試験結果になってしまいますし、ランダムにリクエストパラメータを分散させると、逆にキャッシュヒット率が悪くなりすぎて参考になるデータを取得できません。また、私たちは複数のマイクロサービスを管理しているため、すべてのマイクロサービスでストレステストと分析、そしてチューニングを行うことは限られたエンジニアリソースでは現実的にできません。
そのため、私たちはより少ない労力で致命的なボトルネックを見つけることを目標に、
カオスエンジニアリングによるボトルネックの検出
ユーザーアクセスを再現するシナリオをマイクロサービスごとに作成して実行するのは非常に手間がかかるため、実際のユーザーアクセスを特定のサーバーへ集中させて過負荷を発生させることにしました。このように本番環境で実際に障害を注入して行う実験は
カオスエンジニアリングの3段階
カオスエンジニアリングにおいては、まず
「定常状態における振る舞いの仮説」
「何が発生したら?」
以上より、本番環境でサーバーダウンの障害を再現する実験を行い、障害発生時の挙動が事前に立てた仮説を採択するか棄却するかを検証することになります。
実験と検証の実施
実際にサーバーをいくつも落としていくと、トラフィックが生き残ったサーバーに集中し、CPU使用率が増えていきます。その際のエラー率やレイテンシを注視しつつ、
この実験をすべての主要なマイクロサービスで実施していきます。今回の事例では、1つのマイクロサービスあたりおよそ1〜2時間ほどの時間がかかりました。この際、なるべく他の障害と本実験のタイミングがぶつかることがないように、アプリケーションのリリースがないタイミングで実施しています。万が一実験の途中で予期せぬエラーやレイテンシ上昇が発生した場合は、すぐさま実験を中止し、ダウンしていたサーバーを復帰させます。
実験の結果を見てみると、リクエスト数が増えるに従いCPU使用率が上昇し、最終的にはCPU使用率が70%に到達していることがわかります
また、この結果からCPU使用率70%時のサーバー単位のクエリ/秒
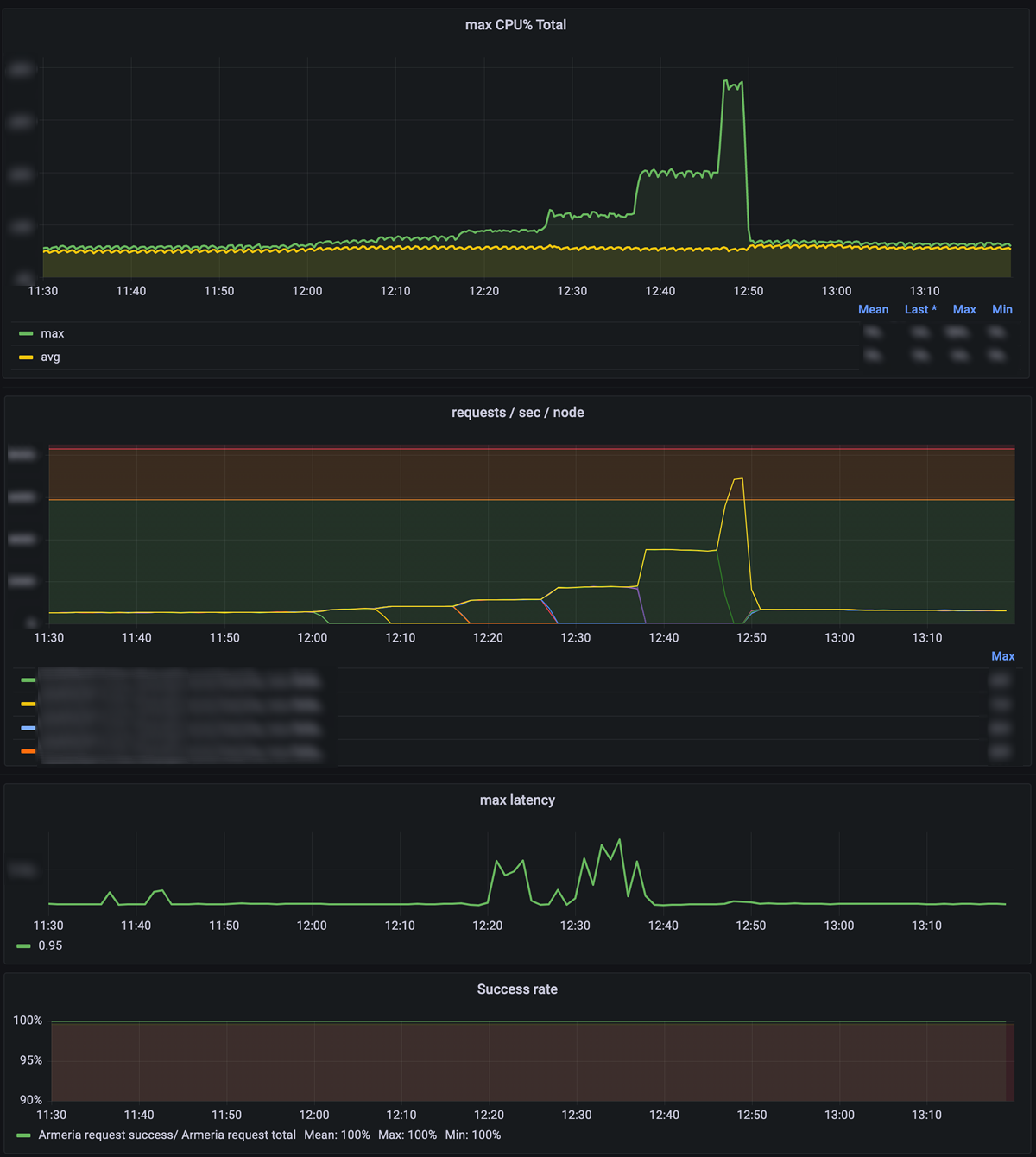
そして、こうして得られた結果の中から、仮説が棄却された
なお、仮に仮説が採択された場合でも、より詳細な調査を必要とすることがあります。たとえば、CPUより先にヒープメモリが枯渇しているケースではGCの頻度が上がり、CPUリソースの消費が加速します。そういった場合は、CPU使用率が70%を超えるまで問題なくともチューニングすべきケースといえます。
平常時のアクセスが小さすぎるマイクロサービス
サーバーを落としていき、負荷を集中させる実験を行っていくと、サーバーが残り1台になってもCPU使用率が70%に届かないサービスがあることに気がつきます。
今回の事例においては、スタンプを購入する際の決済に関するマイクロサービスがそうでした。このマイクロサービスはキャンペーンのタイミングでアクセスが増える一方で、平常時はそこまで集中したアクセスがありません。そのためサーバー台数を1台にしてもCPU使用率が70%に届かなかったのです。
そういったサービスでは無理に70%を目指さずに終了することもあります。しかし、処理キャパシティの見積もりをより正確にしたいケースでは、積極的にサーバースペックを落としていくようにしています。たとえば、8vCPUのサーバー4台から4vCPUのサーバー8台へ変更するなどです。これにより、より精緻な見積もりが可能となり、過負荷の障害発生リスクを減らすことができます。
Zスコアによる外れ値判定を用いた問題のある可能性があるマイクロサービスの抽出
ここまでの実験でボトルネックがCPUでないサービスの検出は完了しています。しかし前述のとおり、GCによってCPU使用率が上昇するようなケースではCPU使用率70%までエラーなく到達することが多く、先ほどの実験だけではこれを検出できません。
担当するサービス数が少なければ、さまざまなグラフをすべてのサービスで確認し、GCの頻度やメモリプレッシャーについても総合的に判断して分析する価値があるでしょう。しかし、私たちは多くのサービスを管理しているため、すべてのサービスで多角的な分析を行うことはエンジニアリソースの観点から困難です。そのため、詳細な分析をするべきサービスを絞り込むために統計的な処理を用いています。
たとえば、クエリ/秒とCPU使用率の関係は、定数1で比例している状態が理想です。アクセス数が2倍になったとき、CPU使用率も2倍となっているのが理想ということです。前述のカオスエンジニアリングを通じて、すべてのマイクロサービスについてクエリ/秒とCPU使用率の最小値および最大値を取得できています。そこでこの数値を利用し、すべてのマイクロサービスに対して下記の計算を行い、比例定数を算出することにしました。
今回は例として9つのサービスを対象に、詳細な分析をするべきサービスを絞り込んでみましょう
| サービス | min (CPU 使用率) |
max (CPU 使用率) |
CPU 変化率 |
min (QPS) |
max (QPS) |
QPS 変化率 |
CPU変化率/ QPS変化率 |
|---|---|---|---|---|---|---|---|
| サービスA | 8 | 16 | 2. |
1100 | 2900 | 2. |
0. |
| サービスB | 15 | 70 | 4. |
260 | 5660 | 21. |
0. |
| サービスC | 18 | 74 | 4. |
100 | 1540 | 15. |
0. |
| サービスD | 2 | 9 | 4. |
17 | 110 | 6. |
0. |
| サービスE | 15 | 82 | 5. |
500 | 1500 | 3. |
1. |
| サービスF | 19 | 80 | 4. |
1600 | 5050 | 3. |
1. |
| サービスG | 10 | 74 | 7. |
1500 | 2015 | 1. |
5. |
| サービスH | 10 | 64 | 6. |
130 | 2800 | 21. |
0. |
| サービスI | 13 | 71 | 5. |
450 | 2950 | 6. |
0. |
表1の
ただしこのとき、
こういった問題を避けるため、私たちは簡易的な方法で外れ値を判定しています。この外れ値の判定はおおよそ人の直感と一致しますので、わざわざ行うべきか疑問に思う方もいるかもしれません。筆者の意見としては、外れ値の判定を明確な基準値として利用するかどうかはサービスやエンジニアの規模によって判断すればよく、特に必須の作業ではありません。
Zスコアを用いた外れ値判定の実施
ここで紹介する外れ値判定の方法は
まずは、表1の
そして各値がどれだけ平均から離れているかを計算します。具体的には、
サービスBの
この方法によって、今回の例ではサービスGのみが外れ値であったことがわかりました。ここでこの方法を終了させてもよいですし、まだエンジニアリソースに余裕がある場合は、サービスGを取り除いたうえで改めて平均と標準偏差を計算しなおし、この方法で他に外れ値がないかを確認してみるのもよいでしょう。
分析とチューニングを行う
前述の方法によって、9サービスあるうち1サービスについてのみ、より詳細な分析とチューニングを行うべきということがわかりました。あとはサービスの特性によって、必要な分析やチューニング、負荷試験などを実施しましょう。
私たちも実際に今回の紹介した方法を用いて高負荷時にヒープメモリが不足するサービスを発見し、より大きなメモリのサーバーにリプレイスすることでサーバー台数を半減させられました。
今回のまとめ
今回は、過負荷による障害の発生可能性の低減のために、処理キャパシティの計測およびボトルネックの設計について紹介しました。
もちろん、すべてのサービスに対して十分なエンジニアリソースを投資して負荷試験を行い、パフォーマンス改善や性能上限の確認を行えることが理想でしょう。しかし現実的には、コストや時間の制約のなかでベターな結果を得る必要があります。今回紹介したのはそのために私たちが行なっている工夫であるとも言えるでしょう。
次回は、同じく