NTTデータグループは2023年11月6日、10月10日に発生した全国銀行データ通信システムの障害に関する記者説明会を実施、現時点で判明している障害の概要について説明を行うとともに、再発防止策に向けたタスクフォースの設立などについて明らかにしました。会見の冒頭、NTTデータグループ 代表取締役社長 本間洋氏は、今回の障害により全国の預金者や金融機関をはじめとする社会全体に大きな混乱をもたらしたことを謝罪し、今後の原因究明と再発防止に向け、全国銀行試験決済ネットワーク(以下、全銀ネット)とともに全力をかけて取り組むことを明言していました。
本記事では会見の内容をもとに、現時点で判明している10月10日の事故の原因についてレポートします。
2023年10月10日 ―なにが起こったのか
全銀システムとは国内金融機関どうしの内国為替取引(銀行振込や送金為替など国内で日本円で行う為替取引)をオンライン処理するシステムで、日本国内の預金取扱金融機関のほとんど(1,000行以上)が参加する超巨大システムです。この全銀システムの運営を行っているのが全銀ネットで、NTTデータは全銀システムの開発/運用を担当してきました。
全銀ネットの概要。利用金融機関数は1133機関/2万9456店舗、取り扱い件数と金額は年間約22億件/約3456兆円、1営業日平均で約911万件/約14兆円という、日本の経済基盤を根底から支える巨大システム

全銀システムは以下の3つの主要システムから構成されています。
- 平日日中の処理を行う「コアタイムシステム」
- 平日夜間および休日の処理を行う「モアタイムシステム」
- 各金融機関をつなぐ「中継コンピュータ(RC)」
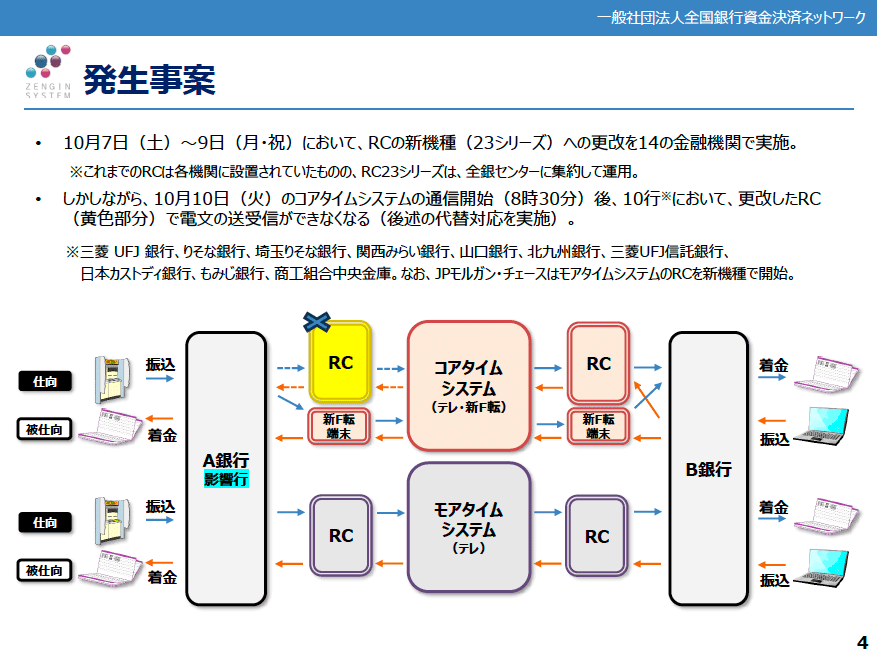
10月10日の障害はコアタイムシステムと連携するRC上で発生しました。RCは現在、現行の「RC17」(2017年更改)から新機種の「RC23」に移行されることが予定されており、三連休の10月7日(土)~10月9日(月)にかけて14の金融機関が更改を実施します。
しかし10月10日(火)の午前8時30分にコアタイムシステムの通信が開始すると、10の金融機関[1]においてRCでの電文の送受信ができなくなるという通信障害が発生しました。具体的にはこれら10行から他行への振込処理ができなくなり、バックアップ手段(RCを使用せずテープ媒体などでやりとり)で対応するも、障害発生により銀行間手数料(内国為替制度運営費)の設定が必要になったり、影響があった金融機関(仕向)の取引金融機関(被仕向)がテープ媒体やデータファイルを用意しなければならなくなるなど想定以上の手間と時間がかかってしまい、最終的な障害復旧(暫定エラー処理)は翌10月11日まで完了しませんでした。なお、後述しますが現時点でも暫定対処は継続しており、RC23への切り替えは行われていません。
三連休明けの10月10日に起こった事案の概要。各金融機関を中継する「RC」を新機種の「RC23」にアップデートした10の銀行において、コアタイム通信開始直後に障害が発生した。旧機種の「RC17」は各金融機関に設置されていたが、RC23は全銀センタに集約して運用する。それぞれのシステムは東京と大阪において冗長化(二重化)されているが、今回の更改では両系のRCを交換し、両系ともに障害が発生した
原因究明とその後の経過
新システムに切り替えたとたんに障害発生という大アクシデントに見舞われた全銀システムですが、1973年の初稼働以来、顧客の利用に直接影響が出た障害は初めてです。なぜこのような不名誉な事故が起こったのか、現時点で判明しているのは以下のような事実です。
更新予定の14行のうち10行に障害が発生した理由は?
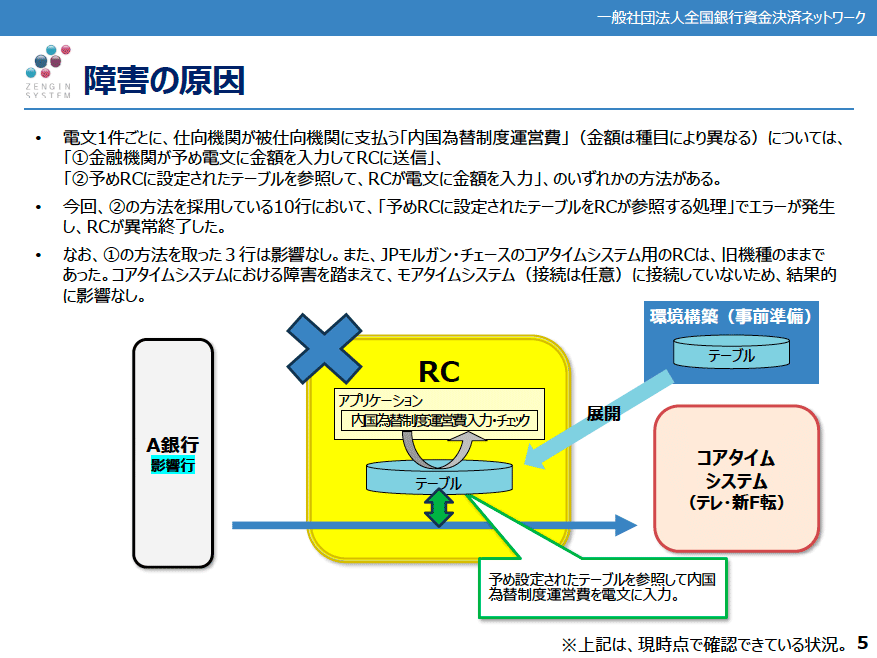
振込処理などの電文1件ごとにA銀行(影響行、仕向)がB銀行(被仕向)が支払う手数料(金額が種目ごとに異なる)については
- 金融機関があらかじめ電文に金額を入力してRCに送信
- あらかじめRCに設定されたテーブルを参照して、RCが電文に金額を入力
という2つの方法があります。今回影響が出た10行は後者の方法を取っており、「あらかじめRCに設定されたテーブルをRCが参照する処理」でエラーが発生し、異常終了しています。なお、前者の方法を採用した3行は影響を受けていません。また残りの1行(JPモルガン・チェース)はコアタイムシステムではなくモアタイムシステムのRCを更新しましたが、今回の障害発生を踏まえてモアタイムシステムに接続していないため、結果的に影響はありませんでした。
障害の直接の要因となったのはNTTデータが事前に開発したテーブル(図中の青で囲まれた“テーブル”)の一部が破損した状態のままRCの共有メモリ上に展開、RCが参照を行うとエラーが発生し、異常終了となった。なお、障害が発生しなかった3行はRCのテーブルを参照する方法ではなく、直接金額を入力してからRCに送信していた
なぜRCのデータ参照でエラーが発生したのか
説明を行ったNTTデータ 取締役副社長執行役員 鈴木正範氏によれば、NTTデータが環境構築のために事前に準備したテーブルのデータの一部が破損しており、データが破損した状態のままRCの共有メモリ上に展開され、RCがテーブルを参照した際にエラーが発生してしまったとのこと。なお、環境構築用のプログラムはスクラッチから開発したのではなく、旧機種のRC17で使用したプログラムをベースにしたものでした。
RC17では問題なく動いていたプログラムが、なぜRC23では異常終了したのか、報道陣からは「32ビットのRC17から64ビットのRC23に変わったことが影響しているのか」という質問が出ましたが、これに対して鈴木氏は「その変更による影響の可能性はあるが、現時点での断定は避けたい」と回答しています。このRCのバージョンアップが今回の障害にどのように影響を与えたのか、今後の検証ポイントのひとつといえるかもしれません。なお、障害直後の一部報道では「物理メモリの不足が原因」と伝えられていましたが、鈴木氏は「そういった事実(物理メモリの不足)はない」としています。
環境構築テーブルのどこが破損したのか
鈴木氏は「現時点では全銀ネットとともに検証を行っているところであり、詳細は申し上げられない」としながらも、テーブルを構成する「金融機関名テーブル」と「インデックステーブル」のうち、インデックステーブルに不具合があったことを認めています。「インデックステーブルは振込や手数料処理などにおいて効率的に振込先の金融機関名と(金融機関ごとに異なる)手数料の金額を参照できるようにするものだが、それが壊れてしまった。直接的な原因となった箇所はほぼ特定できているが、再発防止の取り組みを発表できるまでは詳細は控えさせてほしい」(鈴木氏)
製造段階で混入したバグをなぜテストで検出できなかったのか
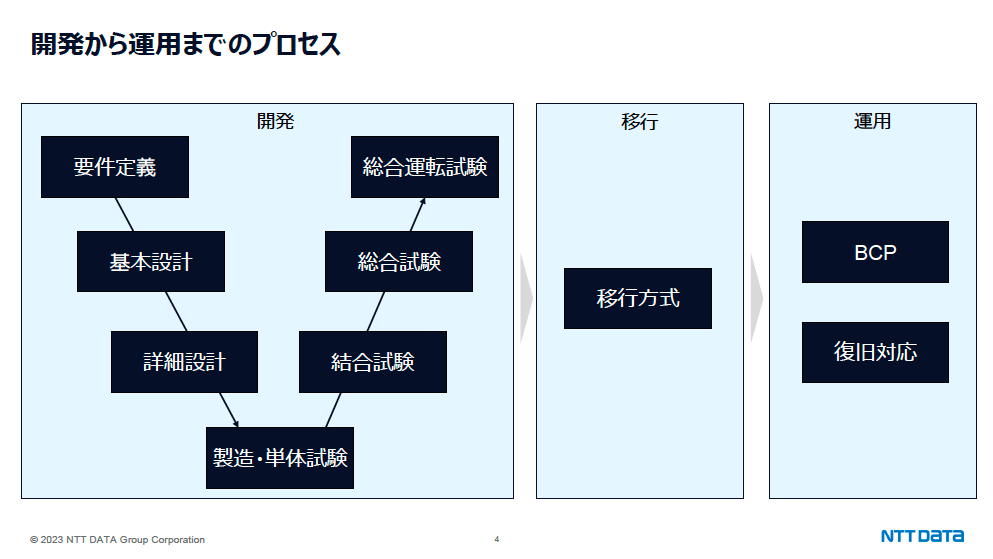
おそらく今回の障害における最大の検証ポイントとなるのがここです。国内トップのシステムインテグレータであり、全銀システムをはじめとする国の重要インフラをいくつも手掛けるNTTデータは当然ながら開発からテスト、移行、運用に至るまで、ひとつひとつのプロセスに非常に厳格なKPIを定めています。仮に開発段階で不具合が織り込まれてしまっても、単体試験→結合試験→総合試験→総合運転試験というテストの過程で、あるいはテスト環境から本番環境への移行の段階において、バグのすり抜けを防ぐための仕組みが何重にも用意されていたはずでした。
NTTデータにおける開発から運用までのプロセス。それぞれのプロセスにおいては厳密なKPIが存在し、そのKPIに則ることが要求される。決済系や勘定系などの重要インフラでは、数千ものパターンで試験することも多い。にもかかわらず、今回の障害を引き起こした不具合を検出することはできなかった
鈴木氏は「テストは網羅性が大事なので、結合試験では数千種類のパターンを試し、総合運転試験ではRC23の実機を使って、実データに近いデータを使い、全銀センタ側でも検証を行った。我々だけでなく、全銀ネットや金融機関にも参加してもらっている。にもかかわらず、今回破損した箇所にアクセスするパターンは検証できていなかった」と語っており、あらためて“網羅する”ということの難しさを実感させます。「試験の過程に問題があったのは事実。プログラムの構造的な問題よりも、不具合をすり抜けさせてしまった、そのことが(NTTデータにとって)非常に大きな課題となる」(鈴木氏)
障害発生後の暫定対処は現在も継続中なのか
10月10日の障害発生を受け、全銀ネットとNTTデータは最初の前提処理として「RCがテーブルを参照せずに、取引の種目を判別して金額入力する」方法に修正しました。しかしこの修正処理は複雑で、試験時にエラーが発生、翌営業日(10/11)のRC起動時刻までに対応することが困難と判断し、この暫定対処は中断されます。そして翌10月11日では前日の状況を踏まえ、「RCが内国為替制度運営費(銀行間手数料)の入力欄に一律0円を入力する」という方法に切り替えたことでエラーは解消し、障害からの復旧を果たしました。
障害発生後の復旧対応の概要。10月10日の暫定対処は試験時にエラーが発生したり、金融機関の準備に時間がかかるなどから対応を中断、翌10月11日に行った暫定対処(RCが銀行間手数料に一律0円を入力)により障害は復旧したが、この暫定処理は11月時点も継続中

この暫定対処は2023年11月の現時点も継続しており、「RCがテーブルを参照して正しい値の銀行間手数料を入力する」という本来意図していた運用には至っていません(金融機関どうしの手数料の受け渡しにかかる処理なので、一般顧客に対する直接的な影響はない)。この点について鈴木氏は「一刻も早く改修したプログラムを適用したいという思いはあるが、プログラムの修正だけではなく、試験の見直しや再発防止策の策定が優先されるため、現時点では新しいプログラムがいつから稼働するかについて明言することはできない」と説明しています。
再発防止に向けて600名規模のタスクフォースを設置
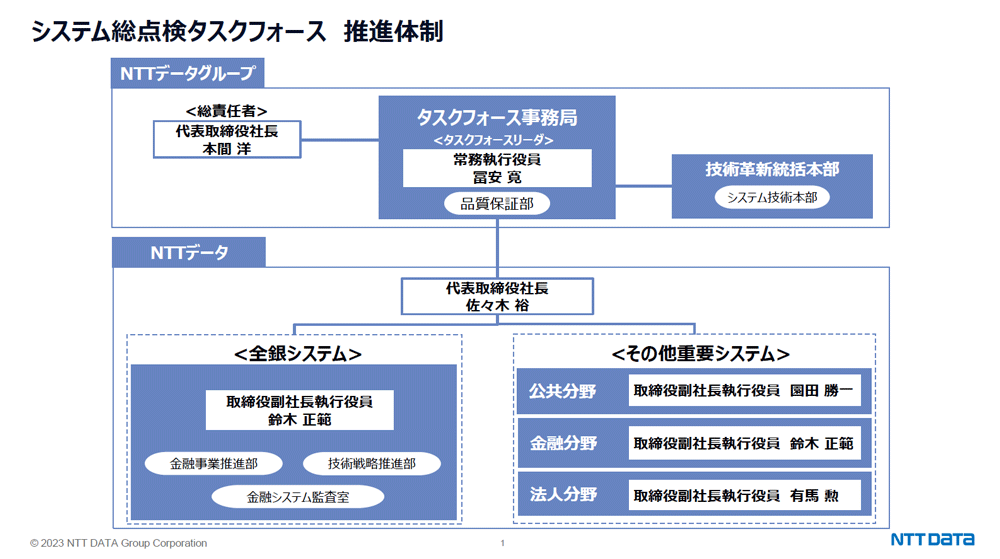
今回の障害発生を受け、金融庁は全銀ネットとNTTデータグループに対して報告徴求命令を出しており、両者は2023年11月末までに本件に関する事実認識や発生原因の分析、障害対応、再発防止策などについて中間報告を含めて報告予定となっています。NTTデータグループは現在、この報告書作成に「全銀ネットと一体となって全力をかけて取り組む」(本間社長)とともに、NTTデータグループ内に本間社長を総責任者とする約600名規模の「システム総点検タスクフォース」を設立、全銀システムのほか、NTTデータが担当する100~200の社会的に重要なインフラシステムを対象に、開発からテスト、移行、運用(BCP含む)に至るまでのプロセスを点検、2023年度中にこの作業を完了させるとしています。
「すべてのプロセスが当社が定めている厳格なKPIに則っているか、さらにそのKPIじたいが適切なものなのかを徹底的にをチェックしていく。点検内容の公開は現状では予定していないが、対象システムの顧客や関係各所にはもちろん報告する」(本間社長)
今回の全銀システムの障害発生を受けてNTTデータグループが設立した「システム総点検タスクフォース」の推進体制。本間社長の直下にタスクフォース事務局を置き、総勢600名の社員から構成、NTTデータグループ常務執行役員 冨安寛氏がタスクフォースリーダーを務める。全銀システムはもちろんのこと、金融系や決済系、公共分野などNTTデータが手掛ける100 ‐ 200ほどの重要インフラを総点検を行う。全銀システムの点検責任者は今回の会見で技術的な説明を行った鈴木氏。完了予定は2023年度中とのこと
ここまでの内容からわかるように、現時点では障害発生の直接の原因となったプログラムの不具合はほぼ特定できており、今後の最大の検証ポイントは「なぜ試験の過程でバグを検出できなかったのか」に尽きると思われます。鈴木氏は会見で「開発期間は十分にいただいており、相応の時間を費やして開発/試験を行った」と語っており、時間的に切迫した状況にあったわけではないようです。
十分な開発期間と膨大な試験を経たにもかかわらず、本番稼働の直後に障害発生という事態に至った“すり抜け”はなぜ起こったのか、そして本当に再発を防ぐことは可能なのか ―全銀システムというほぼすべての国民が利用する日本の最重要インフラで発生した事故だからこそ、これを重要な教訓とするためにも今後の検証が待たれます。
記者説明会の模様。左からNTTデータ 代表取締役社長 佐々木裕氏、NTTデータグループ 代表取締役社長 本間洋氏、NTTデータ 取締役副社長執行役員 鈴木正範氏




