



本連載は、Google Cloudのアプリ開発とDBプロダクトにおけるスペシャリスト達が、Google Cloudプロダクトを利用した、クラウドネイティブな開発を実践する方法を解説しています。
第4回では、アプリケーション開発でも欠かすことのできないデータベース製品の活用について、クラウドネイティブなマネージドDBである、Cloud Spanner
主に対象となる読者は、クラウドを利用してアプリケーションを開発するエンジニア、またはその基盤を構築するエンジニア、サービス開発に携わるプロダクトマネージャーを想定しています。
Google CloudのリレーショナルDBとSpanner
Spannerの話に入る前に、Google Cloudが提供しているリレーショナルDBのサービスを見てみましょう。リレーショナルDBのマネージドサービスは、以下の3つを提供しています。

Cloud SQL
Cloud SQLは、OSSのMySQLやPostgreSQL、商用のSQL Serverを、マネージドDBとして提供しているサービスです。EnterpriseとEnterprise Plusの2つのエディションを提供しており、それぞれ提供しているマシンタイプや構成が異なります。Enterprise Plusエディションを利用することで、最大99.
AlloyDB
AlloyDBは、PostgreSQLとの完全な互換性を保ちつつ、ストレージ層をクラウドに合わせて独自に設計開発したことにより、性能面や機能面での向上が行われたデータベースです。この観点ではAlloyDBもクラウドネイティブなDBと言えるでしょう。99.
Spanner
Spannerは、Google自身が自社利用するために設計開発し、現在もGoogleの多くのサービスを支えている分散DBです。地理位置の離れた複数のデータセンターにデータや処理を分散させることができ、それを単一のデータベースとして透過的に扱えます。Google Cloudの利用者はこのSpannerを簡単に使うことができ、最大99.
Spannerが解決する課題
それではSpannerを選ぶことによって解決する課題とは何でしょうか? 前項で説明した各マネージドDBの特徴を見ると、多くのユースケースではCloud SQLやAlloyDBで十分なことが多いようにも見えます。
連載第1回で触れているように、
まず、書き込み性能のスケールアウトが挙げられるでしょう。リレーショナルDBでは、読み取り性能はリードレプリカにて増やせることがほとんどですが、書き込み性能はライターとなるプライマリインスタンスの最大マシンサイズで頭打ちになってしまうことがほとんどです。Spannerは処理ユニット
次に、さまざまな場面でゼロダウンタイムを実現できる高可用性が挙げられます。可用性の高さはどのマネージドDBもうたっていますが、Spannerはそれを複数のリージョンを活用して実現できることころに強みがあります。ビジネス要件で、東京大阪でDRサイトを構築するといったものがある場合はよく見かけると思います。Spannerでは標準で東京大阪2つのサイトを使った構成をサポートしており、しかも東京大阪の片リージョンが障害になたっとしても、データ欠損なし、ダウンタイムなし、すなわちRPO = RTO = 0を実現[1]できます。結果として99.

これらはSpannerのどのような仕組みによって実現しているのでしょうか?
Spannerのスケーラビリティの仕組み
Spannerは書き込み性能のスケールアウトが可能ですが、これは以下のような仕組みによって成り立っています。
インスタンスと処理ユニット
Spannerの構成要素としては、まずSpannerインスタンスがあります。1つのインスタンスの中には複数のデータベースを作成できます。そしてSpannerの処理性能は、インスタンスに割り当てる処理ユニット

組み込みのオートスケーラー
Spannerには組み込みのオートスケーラーがあります。2023年12月時点ではまだプレビュー機能ですが、すでに試すことができる状態です。オートスケーラーによって負荷状況に応じて自動的にSpannerの処理ユニット
自動シャーディング
計算処理するためのリソースを柔軟に割り当てられることを説明しましたが、Spannerの各テーブルは自動的に複数のシャードに分割されます。Spannerのドキュメント上ではこの分割のことをスプリットと呼んでいますが、ここでは初見の方にわかりやすくするために、DBで一般的に用いられるシャーディングで説明することにします。Spannerのドキュメントを読む際は
MySQLなどのDBでシャーディングを行うには、通常はアプリ開発者が手動でシャーディングを行います。各シャードは単一のDBですので、たとえばシャードをまたいだテーブルのJOINはアプリで行う必要がありますし、シャードをまたいだトランザクションは非常に困難です。また運用途中で再度シャーディングをやり直すのは、運用上の負担がとても大きく、またサービスのダウンタイムを伴いビジネスに影響を与える可能性があります。
Spannerのスケーラビリティの仕組みもこのシャーディングに他なりませんが、それを透過的に全自動で行うところが特徴になります。Spannerはテーブルの主キーの範囲で自動的にシャーディングを行います。たとえばIDが1〜1000はシャード1に、1001〜2000はシャード2に、それ以上はシャード3にデータを格納といった具合に行います。この分割範囲はSpannerがテーブルサイズや負荷状況を動的に判断しながら、必要に応じて随時変更します。アクセスが集中して負荷

単一エンドポイントと自動ルーティング
Spannerの各シャードは、実際にはユーザーからは見えません。アプリからは全シャードを透過的に単一DBとしてアクセスすることが可能です。
アプリからSpannerへは、グローバルで共通のspanner.SELECT * FROM table WHERE id = 1;というクエリが実行されたとすると、id = 1のレコードが格納されているシャードに自動的にルーティングされます。
さらにシャードをまたいだクエリや、シャードをまたいだトランザクションも実行可能です。たとえばSELECT COUNT(*) FROM table;といったクエリが実行された場合はどうなるでしょうか? その場合はすべてのシャードでカウント処理が実行され、各シャードのカウント結果が最終的に1つに合算されてアプリに返されます。内部的には異なるシャードにあるテーブル同士をJOINすることもできます。シャードをまたいだ処理も強い整合性を保ったまま実行可能です。
透過的に分散トランザクションができることは便利ですが、シャードはリージョン内に分散配置されているため、1つのゾーンにライターとなるプライマリインスタンスが配置される一般的なリレーショナルDBと比べると、通信のためのネットワークレイテンシが乗ってきてしまいます。Spannerは個々のクエリやトランザクションのごと性能ではなく、並列でたくさんのリクエストを受けたものを自動的なシャーディングにより処理する、スループット重視のデータベースになります。
Spannerの可用性の仕組み
さまざまな場面でゼロダウンタイムを実現できる高可用性とは、どのような仕組みによって実現できているのでしょうか?
異なるゾーンへの同期レプリケーション
まず単一リージョン構成の場合の仕組みを見てみましょう。Spannerの各シャードはリージョンの各ゾーンに分散して配置されています。そして各シャードは異なるゾーンに裏で同期レプリケーションを行っています。これによりシャード自身のプロセスに障害が起こったり、配置されているゾーンに障害が起こった場合、速やかにレプリカが昇格しトランザクションを継続できます。結果として障害時であってもデータ欠損もダウンタイムなくサービスを継続できます。
単一リージョンではシャードごとに3つのレプリカで構成されており、これらは読み書きレプリカと呼ばれています。その3つのうち1つがリーダー
なおこの読み書きレプリカは、書き込みは必ずリーダーで処理する必要がありますが、読み込みだけならばどれからでも読めます。つまりMySQLなどでいうリードレプリカのような活用もできるのです。Spannerは読み書きと、読み取り専用でエンドポイントは分かれておらず、共通のものを使えます。アプリでトランザクションを実行する際に、読み取り専用トランザクション

異なるリージョンへの同期レプリケーション(DR対応)
Spannerは先述した同期レプリケーションの仕組みを、そのまま他のリージョンのゾーンに拡張できます。これにより東京リージョンと大阪リージョンにまたがって1つのSpannerデータベースを構築することができるのです。片方のリージョンに障害が起こった場合、速やかにもう1つのリージョンにあるレプリカが昇格しトランザクションを継続できます。結果として例えリージョン障害であっても、データ欠損もダウンタイムもなくサービスを継続できます。これがマルチリージョン構成と呼ばれるものです。
自動ルーティングの仕組みにより、アプリからはどのリージョンに接続しているかを気にする必要はありません。一点、単一リージョン構成のときと異なるのは、書き込みを担うシャードは片方のリージョンに集まるようになっていることです。たとえば東京と大阪にまたがってSpannerデータベースを作成した場合、東京または大阪のどちらかをリーダー
マルチリージョン構成の注意点としては、同期レプリケーションを行いますので、データ欠損が起こらない一方で、書き込み

ゼロダウンタイムのメンテナンス
マネージドサービスであっても、内部的なコンポーネントの各種メンテナンスは避けて通れないものです。とくにステートレスなアプリと異なりデータベースは状態を持っているため、再起動にも一定の手順が必要です。各種マネージドDBでも、DB自身のマイナーバージョンの更新や、セキュリティパッチの適用など、さまざまなメンテナンスが発生します。Google Cloud上で動作するVMはライブマイグレーションが実施できるため、ハードウェアメンテナンスの影響を受けません。しかしソフトウェア自身の更新はそうはいきません。
前項で説明した通りSpannerはゾーン障害に耐えられる仕組みになっています。これを利用してローリングアップグレードを行うことで、Spannerはアプリからみたらゼロダウンタイムでメンテナンスを実行できるのです。またアプリからの接続もSpanner APIのフロントエンドで終端されているため、内部的なメンテナンスでも接続が切れることがありません。
DDLはすべてオンラインで実施可能
ゼロダウンタイムを実現する仕組みは他にもあります。アプリ開発を進めていくと、インデックスの追加やテーブル定義の変更
Spannerはアプリから簡単に使える
ここまでで、スケーラビリティと可用性の仕組みの話を紹介しましたが、それらを実現するために運用が大変であっては本末転倒です。フルマネージドDBであるSpannerは運用の手間がなく、アプリから簡単に使うことができます。
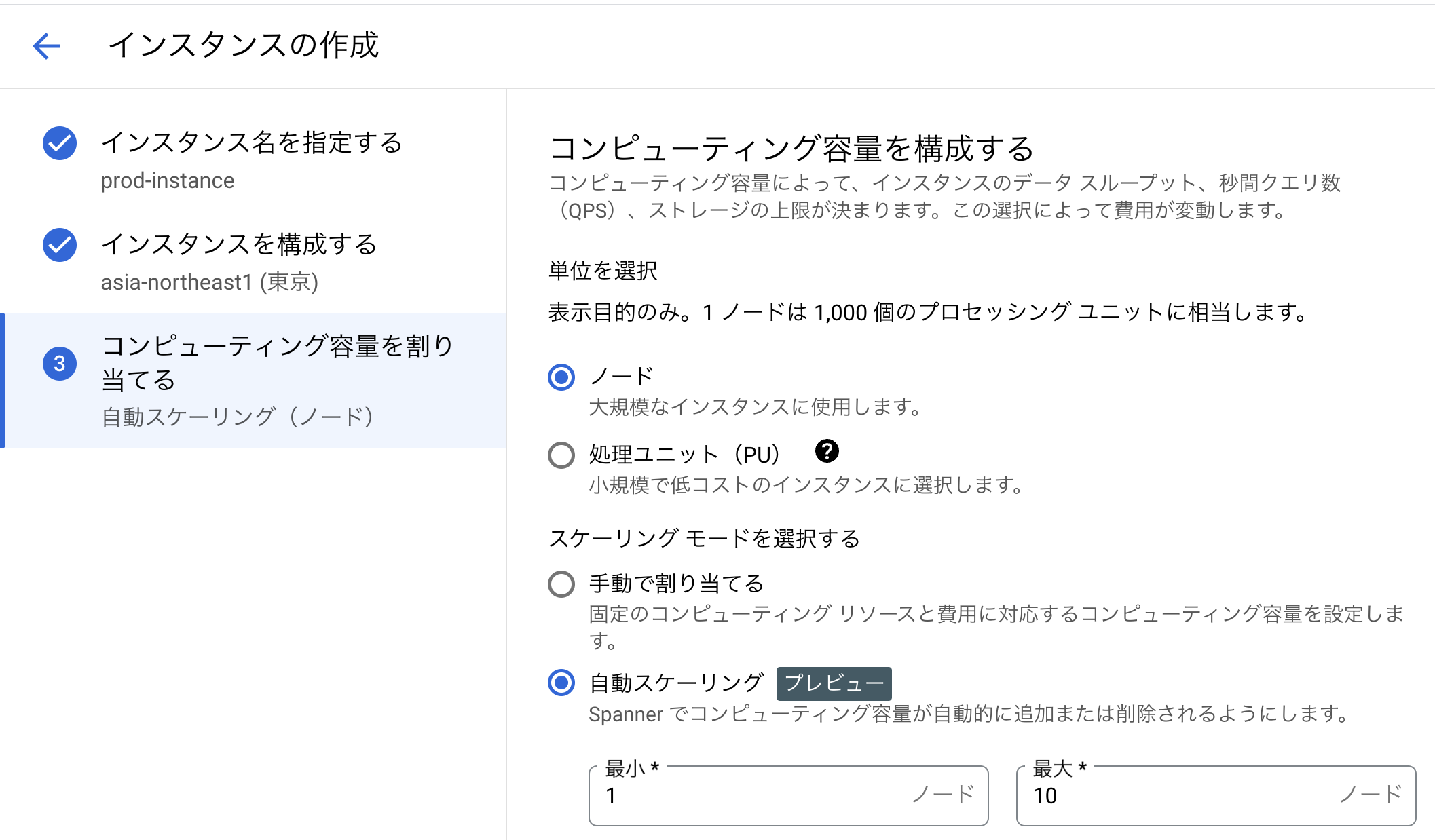
インスタンス作成に必要な項目はわずか3つ
データベースというと設定のパラメーターがたくさんあったりして難しいイメージがありますが、Spannerはシンプルに運用できるようになっており、煩雑なパラメーターは一切ありません。インスタンスを作成する際に入力する情報はわずか3つで、インスタンス名、インスタンスの構成
インスタンスの構成とは、どのリージョンを使うかを選ぶ項目です。単一のリージョンを選択すれば99.
インスタンスの性能値は、インスタンス作成時点で割り当てる処理ユニット数
アプリからのSpannerへの接続
アプリからSpannerへの接続は、単一のエンドポイントに接続するだけだという説明してきましたが、具体的な接続方式についてはまだ触れていませんでした。Spannerも、MySQLやPostgreSQLといったDBと同様に、プログラミング言語ごとに用意されているクライアントライブラリ、ドライバー、O/
言語ごとのクライアントライブラリは、C++、C#、Go、Java、Node.
Spannerでは2種類のSQL方言が利用できます。1つはSpannerが元々サポートしているGoogleSQLです。これはBigQueryでも使われているSQL方言です。もう1つがPostgreSQL方言です。Spannerの各種クライアントライブラリやドライバーからは、GoogleSQLもPostgreSQL互換SQLもどちらも使えますが、この場合通信プロトコルはSpannerのものを使っています。PostgreSQLのCLIであるpsqlコマンドや、PostgreSQL用のJDBCを使って接続したい場合はどうすればいいでしょうか? その場合はPGAdapterというプロトコル変換用のプロキシがあり、これを利用することでプロトコルの変換を行ってくれます。

トランザクションの自動リトライ
アプリからの接続に関して、ここにも簡単に利用できるようにするための仕組みがあります。それがトランザクションの自動リトライです。
高可用性の話をしてきましたが、Spannerデータベース全体としては稼働しているものの、紹介したゼロダウンタイムのメンテナンスのように、ある瞬間をみると特定ゾーンや特定シャードが一時的に処理を受け付けられない状態というのは起こり得ます。処置中のトランザクションでこの状態に陥るとどうなるでしょうか? 処理を継続できないためABORTするしかありません。分散DBであるSpannerはトランザクションのABORTが一般的なリレーショナルDBと比べると起こりやすいのです。もちろん一般的なリレーショナルDBのいずれでもABORTは起こり得ますし、そのような場合はアプリ側でABORTをハンドリングして、再実行などを行うと思います。
Spannerでは、このようなABORT時のリトライを自動的に行う仕組みが、Spannerに接続するためのドライバーに組み込まれています。トランザクション競合が発生してABORTした場合でも、自動的にリトライが行われます。
Spannerのその他の特徴クラウドネイティブならではの特徴
クラウドネイティブなDBであるSpannerは、Google Cloudの各種サービスとのシームレスな連携も、クラウドネイティブDBならではと言えるでしょう。
BigQueryとの連携
BigQueryはGoogle Cloudが提供するフルマネージドのデータ分析プラットフォームです。読者の中にはBigQueryに情報を集約してデータ分析を行ってる方も多いのではないでしょうか?
連携クエリ
Spannerに対する連携クエリは、クエリを処理をするための計算リソースが必要です。通常はSpannerインスタンスのリソースを使って行いますが、本番環境のSpannerに負荷をかけることを避けたい場合もあるでしょう。SpannerのData Boostという仕組みによって、サーバーレスかつオンデマンドで提供される計算リソースを用いて、本番のSpannerデータベースに負荷をかけることなく、Spannerデータベース上の最新のデータにアクセスが可能です。

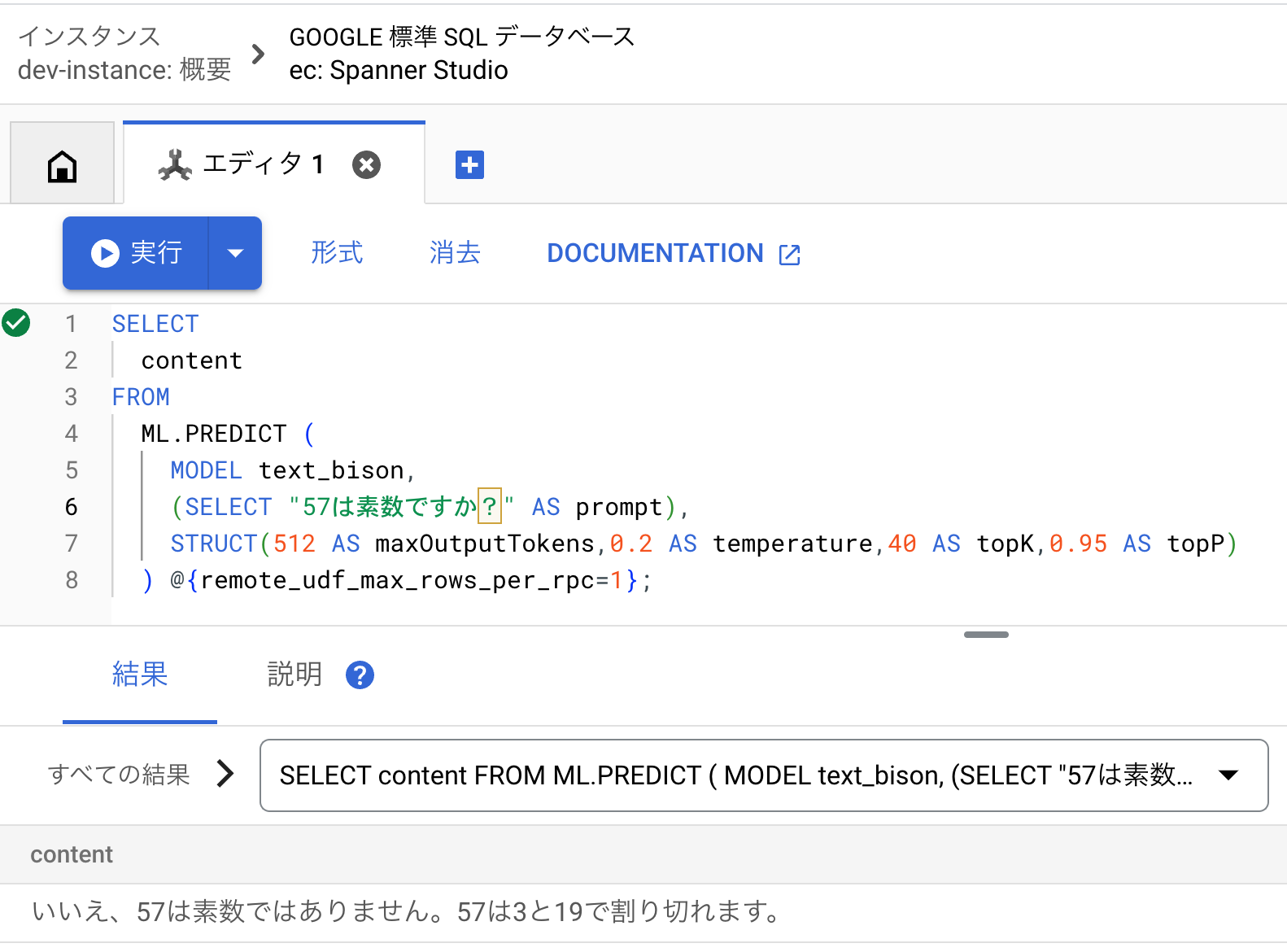
Vertex AIとの連携
Vertex AIはGoogle Cloudが提供するフルマネージドのAI/
たとえば、Spannerが何かしらの決済処理で使われているとします。そのときSpannerの中のデータ
最近はDBでのベクトル検索が流行りつつありますが、SpannerからVertex AI Embeddings for textの生成AIモデルを呼び出すことで、DB内のテキストデータを簡単にエンベディング
まとめ
本記事では、Google CloudのクラウドネイティブDBであるSpannerについて紹介しました。
Spannerは多くの特徴を持ってますが、とくに自動シャーディングによる書き込みのスケーラビリティと、ゼロダウンタイムを追求する高い可用性を持っています。そしてこれらを運用の手間なく簡単に利用できます。
またオートスケーラーが組み込まれたことにより、アプリからの負荷に応じて自動的に処理ユニット数
次回は、Google Cloudのサーバーレス製品を活用したアーキテクチャについてです。