



データを活用していこうとする企業や組織の方たちと話をしていく中で、
こうした状況に対して私たちprimeNumberでは、一方で希少な人材を補完するものとしてデータ基盤の総合支援SaaSであるtroccoを提供していますが、他方で業界としての裾野を広げていくためにさまざまな教育活動にも取り組んでいます。
たとえば、gihyo.
そうした取り組みを進める一方で、教育領域でのデータエンジニアリングの普及には依然として難しさを感じています。データエンジニアリングは、データサイエンスを支える3つのスキルセットの1つとして取り上げられているにもかかわらずです。
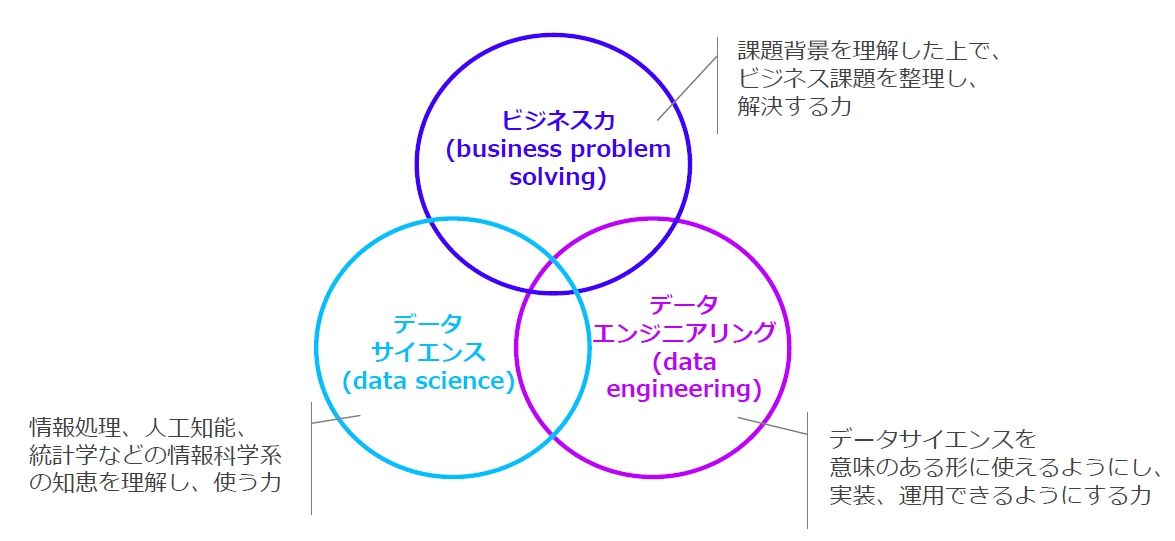
本記事では、教育におけるデータエンジニア育成の難しさと、その中でもどういった取り組みを進めていくのが良いのかについて、私見を述べてみます。
そもそも、なぜデータエンジニアリングが重要なのか
教育の話に入る前に、前提をおさえておきましょう。そもそも、なぜデータエンジニアリングは重要なのでしょうか。その理由は、データサイエンスに値するデータは、適切に準備しないと存在しないことにあると考えています。
とくに、下記のグラフで顕著なように、技術者が組織内部ではなく外部の開発会社に偏在している日本においては、技術を効果的に扱える人材が組織内部におらず、ましてやデータを効果的に活用できる状態にないことが多いと考えられます。
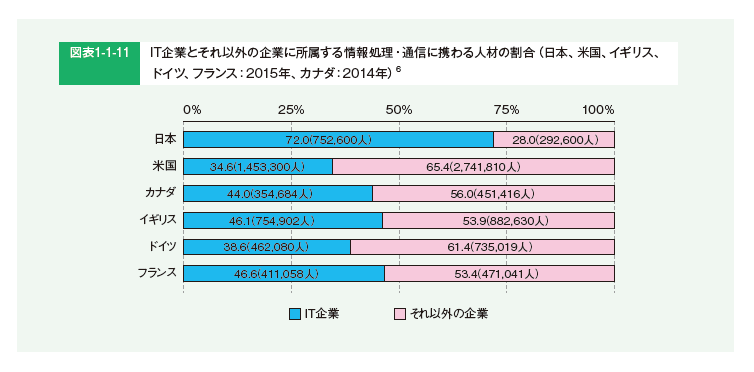
データは上手く使えば業務を劇的に改革するためのツールになり得るのですが、それは活用に値するだけのデータを整備できるかが土台になるものです。この点を踏まえると、データエンジニアリングの普及はデータサイエンスを社会実装していくうえでの大きな課題であると言えるでしょう。
大学生は何を学んでいるのか
まず、大学生がどのような学問分野を学んでいるのかについて見てみましょう。下記は学校基本調査での1~4年生の1学年あたりの学生数について、学科系統の大分類の内訳をみたものです。
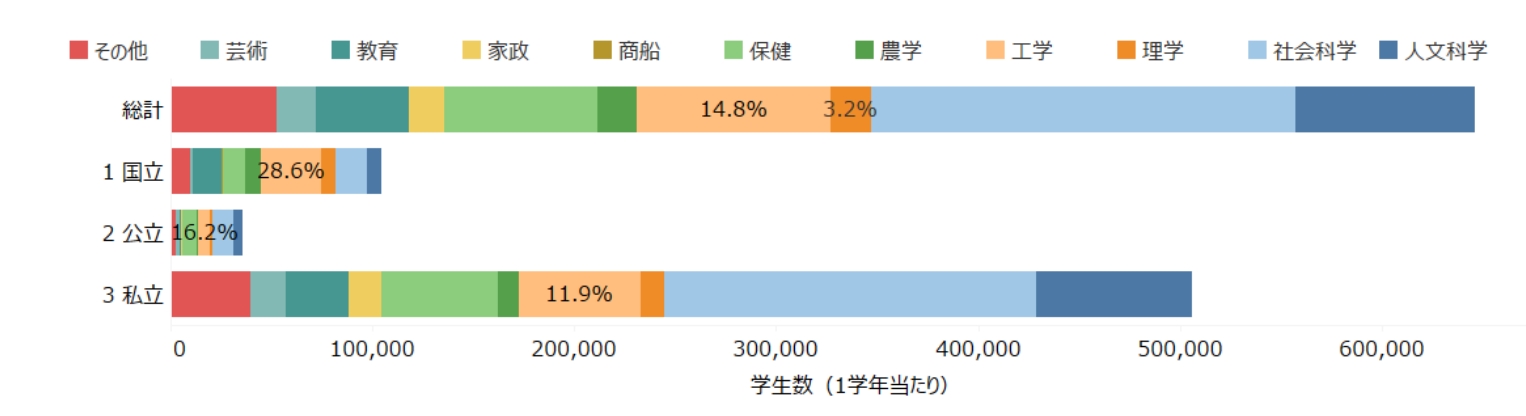
ここからわかるのは、理学と工学を学んでいる学生は、全体の2割弱しかいないということです。中でも国立大学では割合が大きく35%程度になりますが、私立大学では1割強しかいません。
次に、もう少し細かい学問分野について見てみましょう。以下のデータは私立大学がなく国公立大学に限定されますが、全体から中分類または小分類に
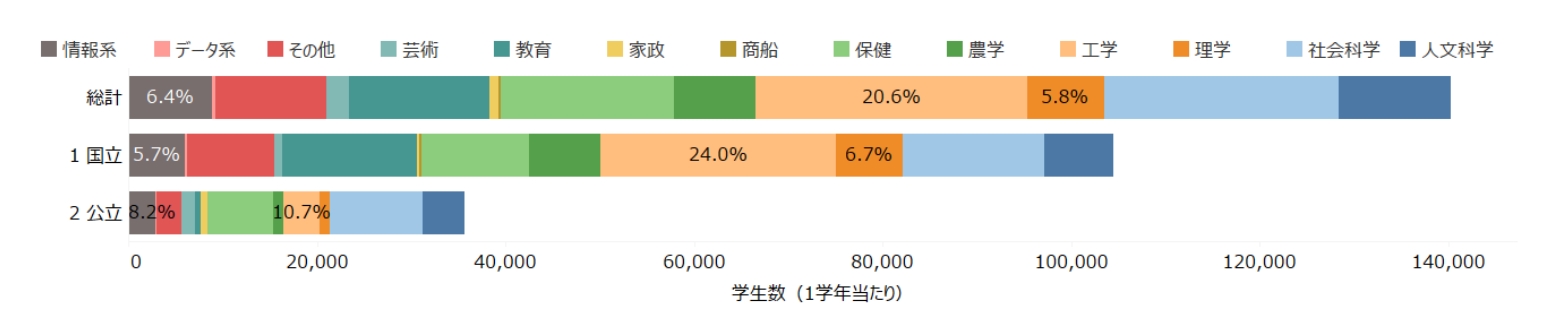
このデータを見ると、情報系
私立大学は人数規模が著しく大きい割に理工系の割合は小さくなるので、設置区分を問わない全学生で見ると情報系が3~4%というところでしょうか。データ系はもちろん、情報系でも全学生に対してかなり一部に限られることがわかります。
データサイエンス教育は大学で拡大するが……
学部学科単位では上記のようになりますが、専攻を問わずにデータサイエンス教育が行われるようになってきています。具体的には、
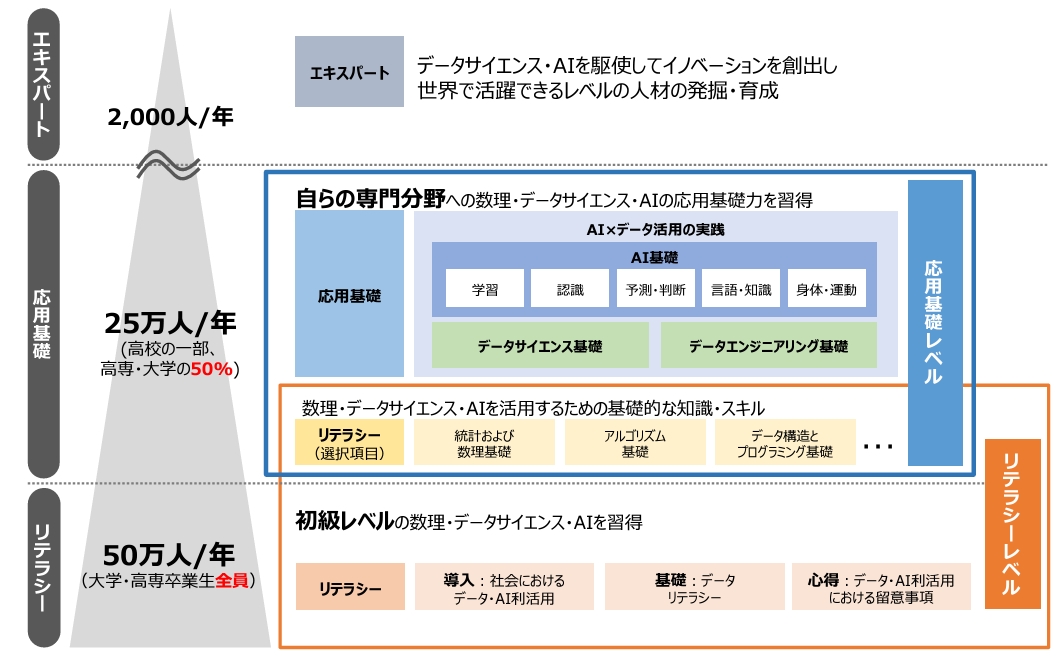
データエンジニアリングはデータサイエンス教育の3本柱の1つなので、このプログラムを通して教育が進んでいくと思われるでしょうか。しかし、そうとも言えないというのが難しいところです。
まず、リテラシーレベルについてはそもそもが大学・
次に、上位区分の応用基礎レベルについてはどうでしょうか。コンソーシアムで作成されたモデルカリキュラムが公開されているので、その内容をもとに見てみましょう。
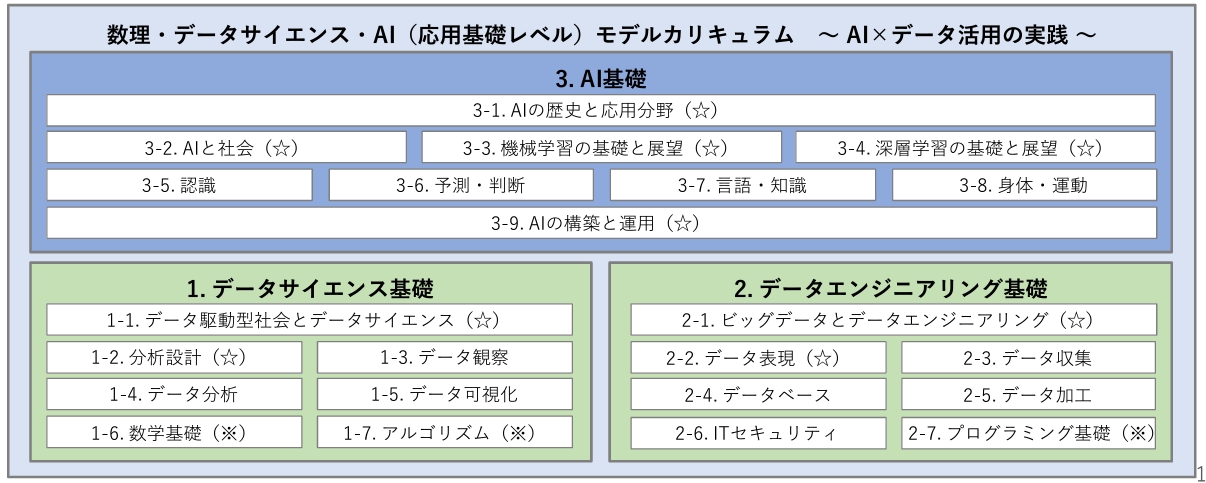
上記の図では、☆がコア学修項目、※が基盤となる学修項目になっています。ただし、実務のデータエンジニアリングの基礎となるデータ収集、データベース、データ加工はどちらにも当てはまらず、すなわち発展的な取り扱いになっています。
また、それぞれの項目に関する詳細な内容は下記のとおりです。
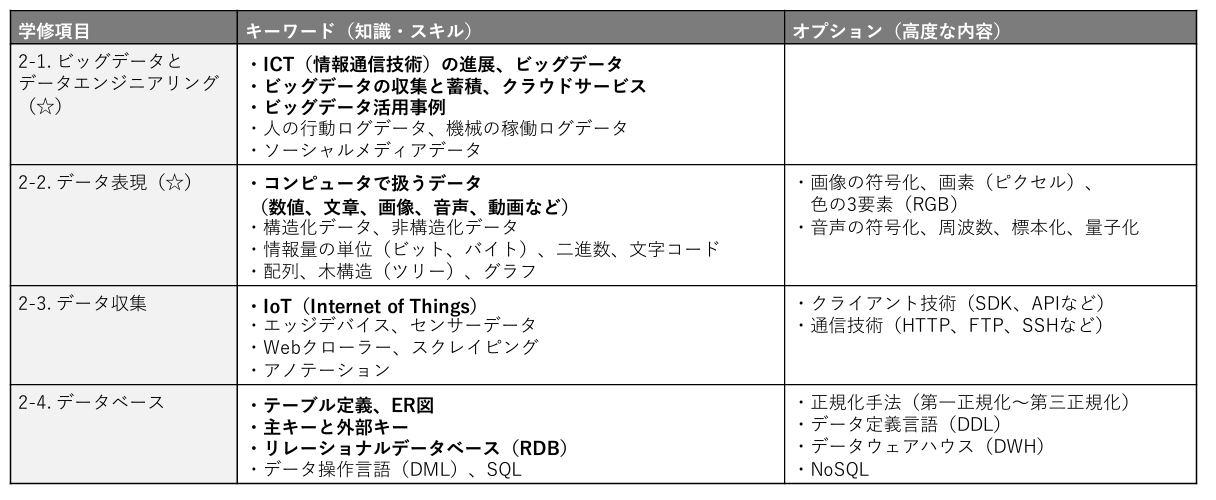
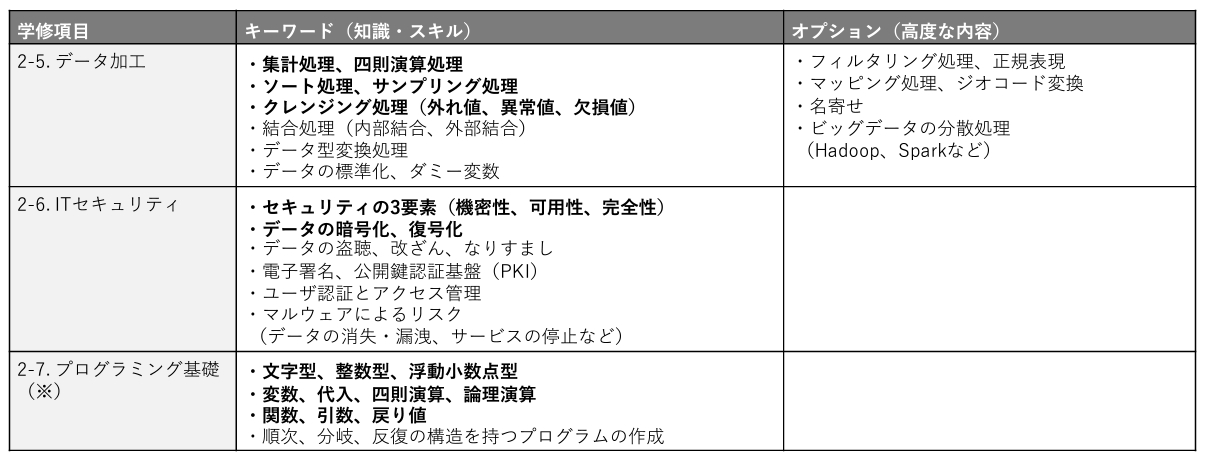
HTTP、API、データウェアハウスなどといったデータエンジニアにとっての基礎知識は、高度な内容として位置付けられていることがわかります。
これらをふまえると、
データサイエンス教育は個々の学問領域の学習と合わせて学ぶものであると位置付けられている以上、なかなか深いものまでは想定されていないということが想像されます。
データ系学部はどうか
近年、データを冠するような学部/
| ~2022年度 | 2023年度 |
|---|---|
| 滋賀大学データサイエンス学部 横浜市立大学データサイエンス学部 武蔵野大学データサイエンス学部 長崎大学情報データ科学部 立正大学データサイエンス学部 ※ |
一橋大学ソーシャル・ 名古屋市立大学データサイエンス学部 順天堂大学健康データサイエンス学部 東京都市大学デザイン・ 明星大学データサイエンス学環 京都女子大学データサイエンス学部 大阪成蹊大学データサイエンス学部 |
ただ、個々の大学で公開されているシラバスやカリキュラムを調べてみても、
なぜデータエンジニアリング教育が難しいのか
このような現状になっている背景を考えてみましょう。それは、データエンジニアリング教育が難しいことにあり、具体的には3つの要因があると考えます。
時間的余裕がない
まず、そこまで実施する時間的余裕がないというのが挙げられるでしょう。コンピュータとプログラミングの基礎を学ぶだけで時間はかかりますし、分析の中心となるモデリングは理論の理解と手を動かしての実践でその学習には大きな手間がかかるものです。
また、ある程度データを取り扱った経験がないと、データエンジニアリングはイメージが付きにくいものですから、学ぶ準備ができるまでに時間がなくなってしまうことも多いのでしょう。
教えられる人が少ない
次に、体制的に教えるのが難しいということがあります。そもそも民間でもデータエンジニアはたくさんいるわけではないですし、近年のデータエンジニアリングのプラクティスは2010年代以降のクラウドデータウェアハウスの発展に大いに影響を受けています。その中で、なかなか知見が体系的に整理されていないこともあるでしょう。
加えて、大学が新たな学部学科を設置するには設置認可や届け出を行う必要がある以上、既存の体制の組み換えになるということがあります。新設の母体として経済/
使えるデータがない
最後に、そもそも使えるデータがないというのがあります。データエンジニアリングは運用されているデータを生み出すシステムがある環境の中で、ドメインとデータを連動させていくことに価値があります。そう考えると、大学という場でデータエンジニアリングに使えるデータがどれだけあるかという壁に直面するのです。
産学連携で学ぶ場を提供する
大学の場だけで難しいのであれば、データがある外部と連携すればいいとも言えます。実際、データサイエンスを冠する学部学科では産学連携のPBLを看板の取り組みにするところは多いですし、最初に設置された滋賀大学などはその筆頭でしょう。
産学連携の取り組みは個別の詳細が外部に公開されるわけではないので、その内容については広く理解してはいませんが、先述の理由から分析が中心のことも多いのではという気もしています。
実際、私がインターンの学生を受け入れる際にも考えていたのですが、データ分析はスコープ切り分けてアドホックな取り組みがしやすいですが、データエンジニアリングは日常の運用の色が強いので、短期間で集中的な学習がしにくい性質だと思い悩んだ記憶があります。
弊社の取り組みの中では、データサイエンスとデータエンジニアリングのバランスを取るように設計していますが、基礎的なところから積み上げていくように教えることはなかなか骨が折れるものです。
とはいえ、データの取得から利用までデータ活用の一連の流れについてシステム的な観点を持つことは、データ領域で仕事をしていくにあたって確実に力になっているだろうという手ごたえもあります。いい方法については模索中ではありますが、その重要性は強く感じています。
先端的なインターンシップの取り組み
別の視点として、インターンシップとしてかなり深い内容が行われており、感心した取り組みがあります。例えば、dbtによるバッチパイプラインの実装を取扱ったLINE社の事例
いずれも実施期間が6週間、1か月強と長期間の取り組みにはなりますが、おそらく参加学生に取っては初めて取り組む技術スタックにも関わらず、非常に良い学びになっただろうと想像します。私自身もこの内容を見ながら、もう少しできることがあるかもしれないと刺激を受けました。
データエンジニアを育てていくために
過去にはデータ関連の教育があまり行われていなかったので、現在データエンジニアとして働いている人は、ソフトウェアエンジニアやデータアナリスト/
データエンジニアリング教育には先述したような難しさがありますが、データサイエンス教育が普及してきている今では、少なくともデータになじみがある人が増えるという点で以前よりもその難しさは緩和されてきているとも考えられます。
大学だけで進めるのは難しい内容だからこそ、産学連携やインターンシップなど、産学協働で学ぶ場を提供することが重要です。そのときに、幅広い対象に概論的な内容を伝えていくことと、優秀な層に深い取り組みをさせていくことの2つの方向性があるでしょう。みなさんにとって、何かできそうなことはあるでしょうか?
また、データ領域にはさまざまなコミュニティがあり、勉強会も非常に頻繁に実施されているため、そこに学生の参加を促すこともできるでしょう。私もこの記事を執筆しながら、改めてもっとそういった取り組みをした方が良いだろうと思い直しています。
データエンジニアリングを広く普及させていくことには多くの難しさがありますが、その中でもこの領域が重要だと思う人たちが、産学を超えて取り組みを進めていければいいと考えています。私も頑張っていきますので、ぜひ一緒にやっていきましょう!