



前回はDiscordからメッセージを送信して、そのメッセージをEC2上で受け取るプログラムを作成しました。今回はAWSの生成AIであるBedrockを利用して文章生成を行い、生成結果をDiscordに送ることに挑戦してみます。
AWSの生成AIサービス「Bedrock」
AIのベースとなる基盤モデルを容易に利用するためのクラウドサービスの一つが、AWSが提供しているBedrockです。機械学習の専門知識がなくても、オリジナルのアプリケーションに簡単に組み込めるようになります。
Bedrockは、事前トレーニング済みのモデルを複数提供しています。テキスト生成・
Bedrockで用意されている基盤モデルの有効化
Bedrockで用意されている基盤モデルのうち、今回のアプリでは大規模言語モデルの一つである
AWS console homeで
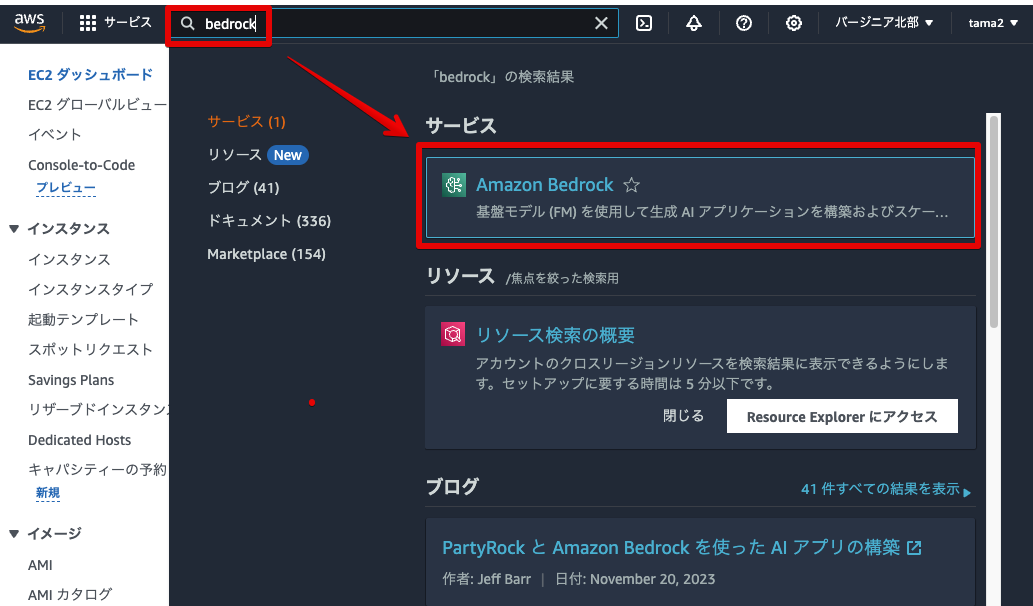
文章生成の基盤モデルであるClaudeは東京リージョンにあるのですが、画像生成に使用する基盤モデルStable Diffusionは東京リージョンにはまだ用意されていません。そこで今回はStable Diffusionが用意されているバージニア北部のリージョンで両方とも進めることにします。そこで画面右上のリージョン選択から
切り替え後、左上のメニューを押してメニューを開いてください。
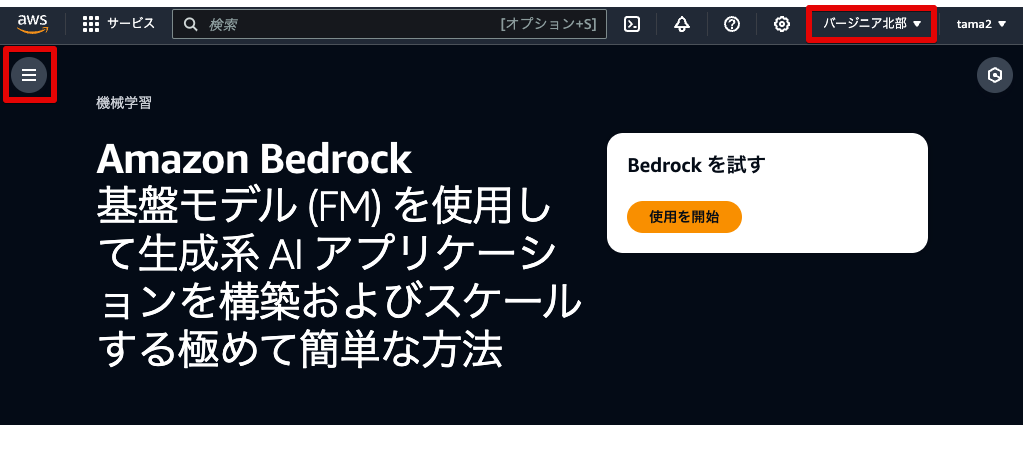
メニューを開いたら、
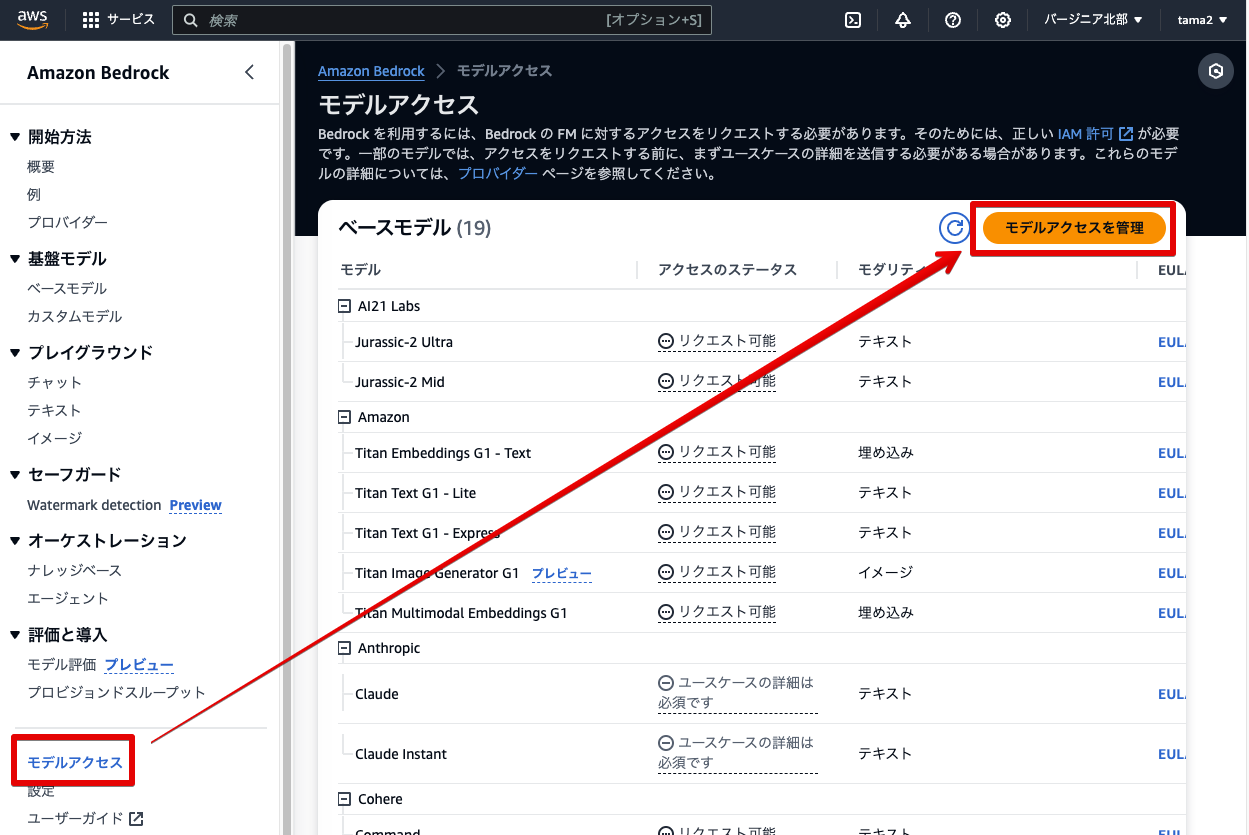
基盤モデルのClaudeを使うにあたり、その目的を申請する必要があります。
申請時、会社名を記載するようになっていますが、Claudeは個人でも利用が可能です。個人の場合は個人名で記載して申請します。
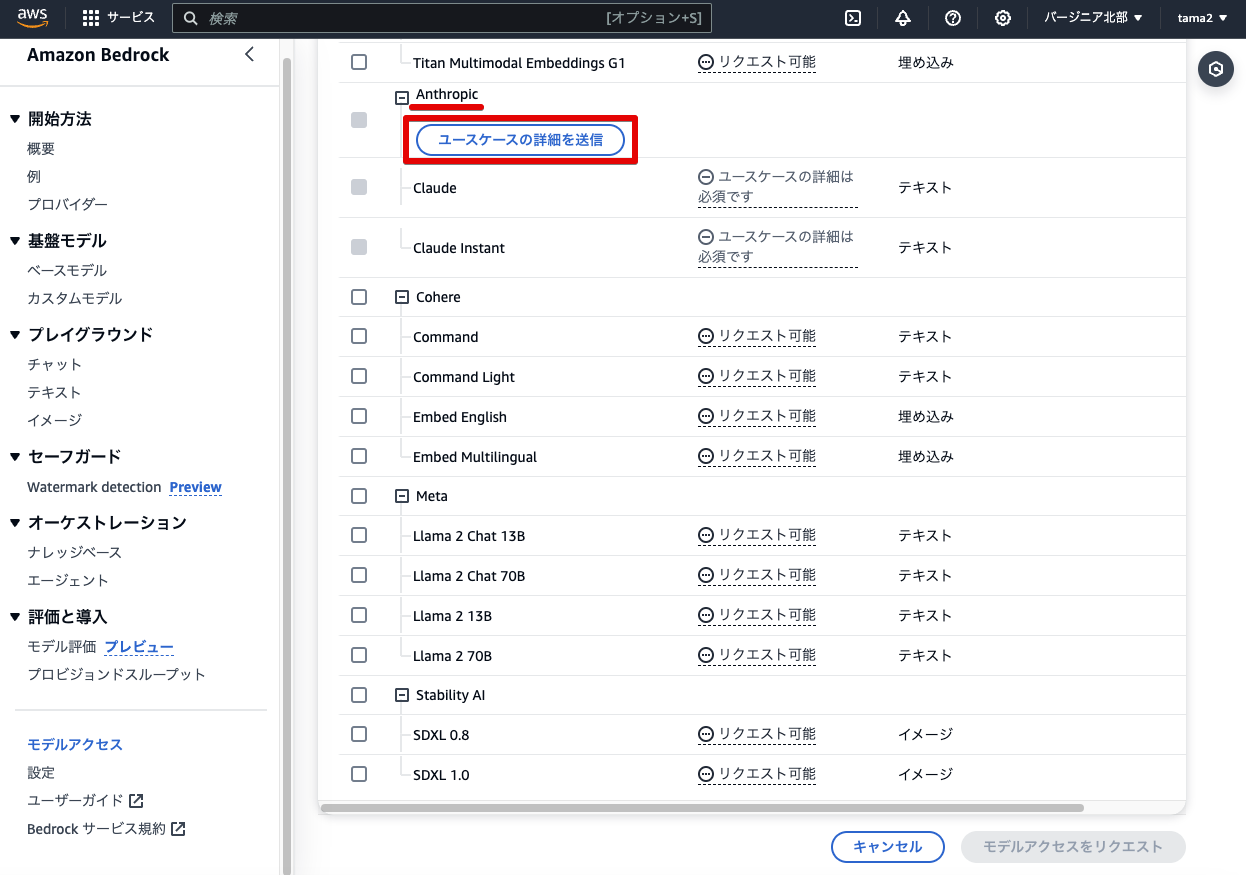
ユースケースを登録したら
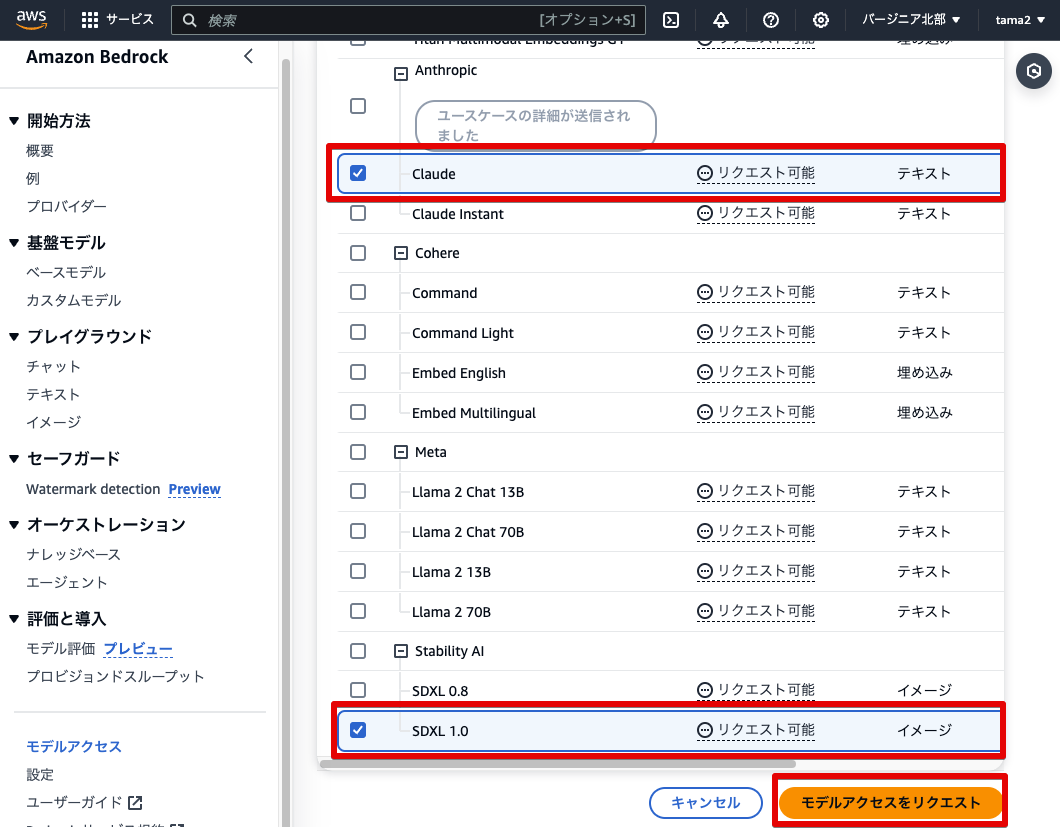
数分でリクエストが許可されます。成功している場合は画面を更新すると
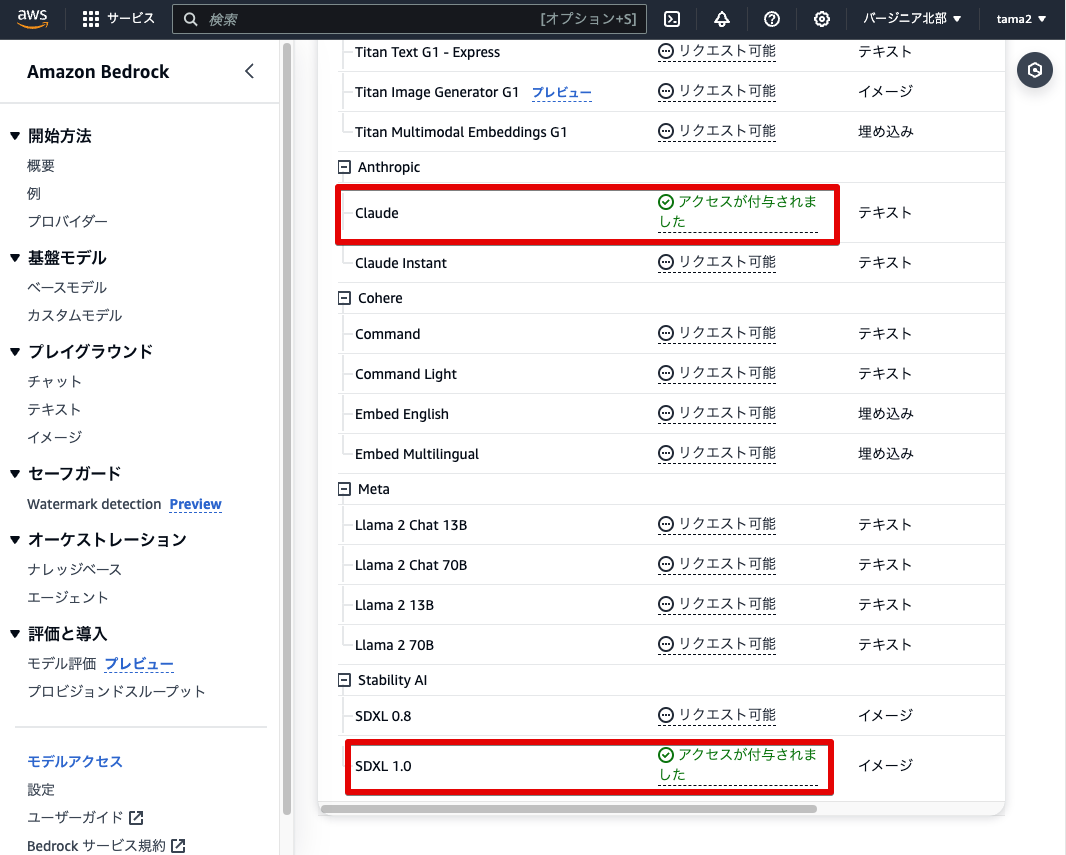
以上でBedrockにおける基盤モデルの有効化が完了しました。
ローカル環境でBedrockを動かす
今回はプログラムを説明する前に、ローカル環境でBedrockを動かしてみます。
使用するコードはローカルマシン上に用意したgihyo-torecaディレクトリ内のchapter-3ディレクトリに用意してあります。
cd gihyo-toreca/chapter-3
Bedrockと連携するために、前回のDockerイメージに手を加える必要があります。具体的には、PythonのプログラムでAWSのサービスを動かすにはライブラリとして
discord.py # 第2回で追加
boto3 # 第3回で追加
requirements.
docker-compose build --no-cache
また前回の起動からターミナルを閉じていた場合は、その際に発行していたBotトークンを再度設定します。
export DISCORD_BOT_TOKEN='あなたのBotトークン'
ここでもし前回説明している本番公開の作業をしていない場合は、第2回の
準備が整ったところでDockerを起動します。
docker-compose up
ターミナル上に
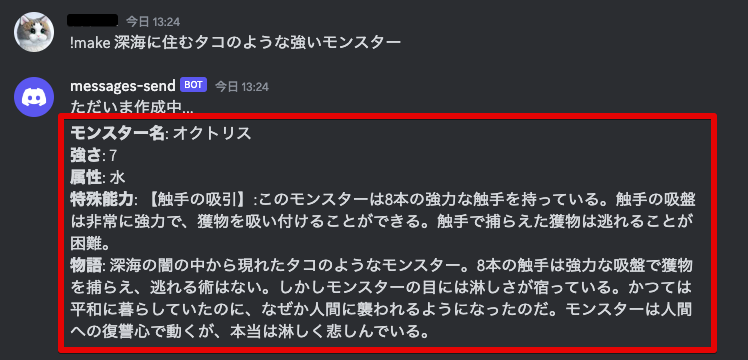
早速Discordから!make 深海に住むタコのような強いモンスターとメッセージを送信してみましょう。次のように生成結果が表示されたら成功です。
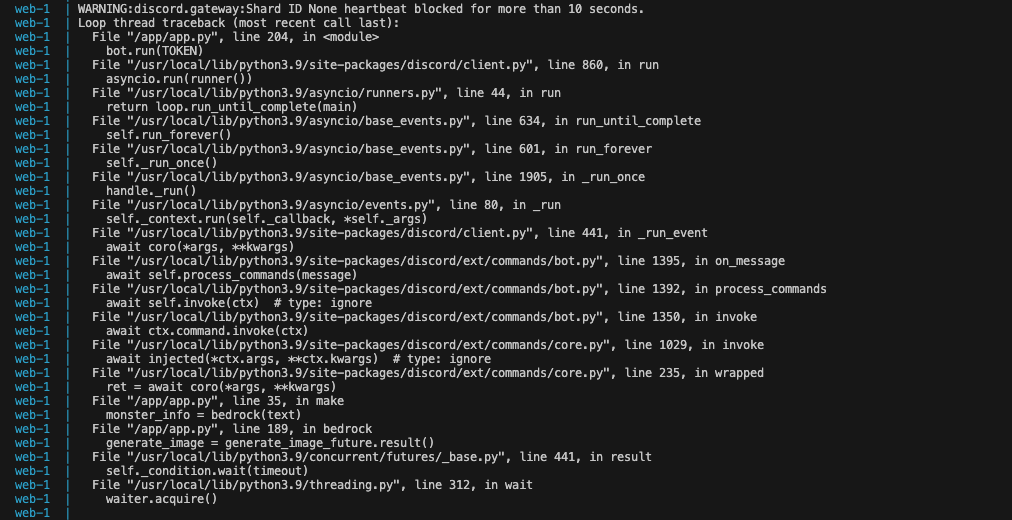
場合によっては、次の図のようにDiscord botがheartbeat blocked for more than 10 secondsという警告を出力するかもしれませんが、気にしなくても大丈夫です。この警告はDiscordのWebsocket接続が期待される時間内に送信できなかったことを示しています。通常、イベントループが長時間実行される処理によってブロックされていることが原因となります。
生成AI用のプログラムの確認
前項で生成してみた文章はどのように生成されているのでしょうか。このアプリでは、前回作成したメインのapp.
Bedrockとの接続
generate_
import boto3 #Boto3のライブラリをインポート
# AWSのBoto3クライアントを初期化して、Bedrock Runtimeサービスにアクセスする準備
bedrock_runtime = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
Boto3のインポートしたのち、boto3.で各AWSサービスと連携できるようになります。
service_にはAWSサービス名s3, ec2, dynamodbなど)bedrock-runtimeを指定しています。
region_には利用するリージョンを指定します。今回利用しているバージニア北部us-east-1)
Boto3についての詳しい情報は、AWS SDK for Python
メイン関数のgenerate_monster_bedrock
generate_generate_になります。次の流れで処理をしています。
-
プロンプト成形
ユーザーのざっくりとしたリクエスト
(user_ request) を、AIにとって理解しやすい具体的なプロンプトに成形させます。 プロンプト作成のために、各項目
(名前、強さ、属性、能力、物語) に対応する関数 (例: generate_、prompt_ for_ name generate_など)prompt_ for_ level を呼び出します。 -
Bedrockを使った文章の生成
成形したプロンプトを基に、文章生成関数
invoke_でテキスト生成を行っています。この関数では、指定した基盤モデルにプロンプトを渡し、モデルからテキスト応答を生成させます。text_ model また、モデルに渡すパラメータ
(例えば、生成の多様性を決定する temperatureやtop_)p があり、最適な結果を得るため、細かく調整をします。 -
結果のレスポンス
最終的に、生成AIから得られたモンスターに関する情報
(名前、強さ、属性、能力、物語) をPythonの辞書型データとして返します。
実際のgenerate_関数は次のとおりです。
# generate_ai.pyにおいてのメイン関数
def generate_monster_bedrock(user_request):
# 役割の設定 このあとのプロンプト成形の際に必要なテクニック
role_setting = "あなたはファンタジーに詳しいクリエイターです"
# 生成したい項目ごとに『generate_prompt_for_xxxx』としてプロンプト成形関数を用意している
# 下記はモンスター名をの生成するためのプロンプトを作成
prompt_name = generate_prompt_for_name(role_setting, user_request)
# 基盤モデルにプロンプトを渡し、生成されたテキストからモンスターの名前生成
monster_name = invoke_text_model(prompt_name)
# モンスターの強さを生成するためのプロンプトを作成
prompt_level = generate_prompt_for_level(role_setting, user_request)
# モンスターの強さを生成
monster_level = invoke_text_model(prompt_level)
# モンスターの属性を生成するためのプロンプトを作成
prompt_element = generate_prompt_for_element(role_setting, user_request)
# モンスターの属性を生成
monster_element = invoke_text_model(prompt_element)
# モンスターの能力を生成するためのプロンプトを作成
prompt_ability = generate_prompt_for_ability(role_setting, user_request)
# モンスターの能力を生成
monster_ability = invoke_text_model(prompt_ability)
# モンスターの物語を生成するためのプロンプトを作成
prompt_episode = generate_prompt_for_episode(role_setting, user_request, monster_level, monster_element, monster_ability)
# モンスターの物語を生成
monster_episode = invoke_text_model(prompt_episode)
# 呼び出し元(app.py)へ生成結果を返す
return {
"monster_name": monster_name,
"monster_level": monster_level,
"monster_element": monster_element,
"monster_ability": monster_ability,
"monster_episode": monster_episode,
}
Claude基盤モデルでのプロンプト作成
文章生成にはClaudeを使っていますが、Claudeでは一定のルールに則ってプロンプトを書く必要があります。
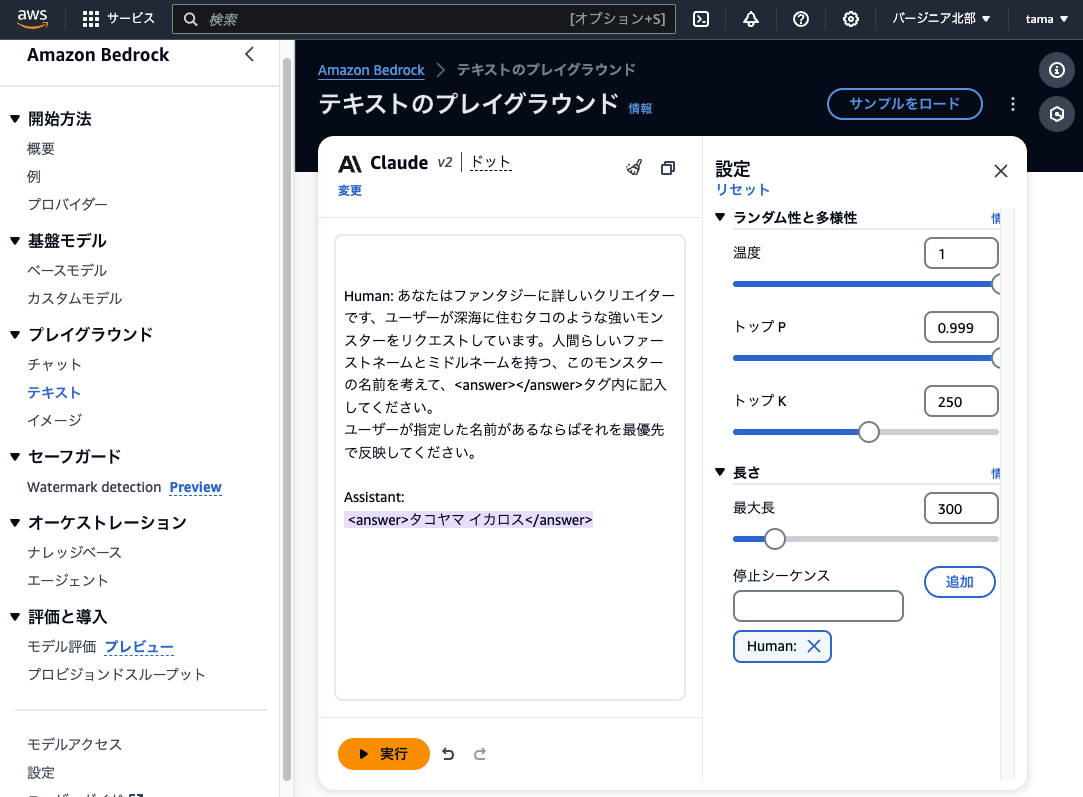
ClaudeではHumanが質問者、Assistantが生成AIという位置付けになっています。次のように、\n\nHuman: にはプロンプトの命令を書きます。\n\nAssistant: 以降は何も書きません。それぞれ:の直後に半角スペースが必要です。
また、Pythonでは f"{変数}"で囲むことにより、文字列の中に変数を埋め込むことができます。
今回のプロントは次のような形になります。
f"\n\nHuman: {role_setting}。ユーザーが{user_request}の物語をリクエストしています。"
"ユーザーが指定した物語があるならばそれを最優先で反映してください。"
f"モンスターの属性である{monster_element}、数値が大きいほど強い1~10段階ある強さの中でレベル{prompt_level}、特殊能力が{prompt_ability}であることを考慮してください。"
"このモンスターの不気味で悲しく謎に満ちた物語を<answer></answer>タグ内に100文字程度で記述してください。"
"\n\nAssistant: "
Assistant: までを用意することで、それに続く回答を得られるわけです。なお、\n\nは改行処理で、Humanのプロンプト前後には明確に改行する必要があります。さらに詳しい情報については、AWS Anthropic Claudeのサイトを参照してください。
さらに生成AIにgenerate_内で、共通の役割を設定した変数を用意して、各プロンプト成形関数に引数として渡しています。
role_setting = "あなたはファンタジーに詳しいクリエイターです"
# プロンプト成形時に役割を一緒に渡す
prompt_name = generate_prompt_for_name(role_setting, user_request)
回答フォーマットを指定し、文章の出力形式を一定にする
回答を特定のフォーマットで出力するよう指示することで、後の処理が容易になります。
次の例はプロンプト内で何もフォーマットを指定せずに結果を出力した際の例です。AIの受け答えも回答の一部となって出力されてしまいます。
# 生成結果の例
# 結果はBedrockからのレスポンスの`completion` の項に出力されます。
{
'completion': 'はい、わかりました。このモンスターの内容から考えて次の物語を考えてみました。~ 回答テキストが続く ~'
}
このように回答にAIの受け答えが混ざった場合、必要となる回答テキストを文章中から抜き出すことが難しくなります。
本当に欲しい部分である回答テキストだけを取得したい場合は、次のようにタグで回答を囲むようにプロンプトで指示をします。
"このモンスターの不気味で悲しく謎に満ちた物語を<answer></answer>タグ内に100文字程度で記述してください。"
生成AIの回答を<answer>タグで囲むように指示をすると、AIの受け答えを抑制し、<answer>タグで囲まれた状態で結果が返るようになります。
ちなみにタグは<answer>である必要はなく<result>などでも構いません。
# 生成結果の例
{
'completion': '<answer>回答テキスト</answer>'
}
回答テキストを取得後は、次のように正規表現処理を使って<answer>タグ内の情報を取り出します。
# <answer>タグで囲まれたテキストを抽出
match = re.search(r'<answer>(.*?)</answer>', response_body['completion'], re.DOTALL)
if match:
return match.group(1).strip() # タグ内の『回答テキスト』のみを返す
else:
return "" # マッチしない場合は空文字を返す
また、モンスターの能力を表示するgenerate_では、指定フォーマットを次のようにしています。
"このモンスターのユニークな特殊能力とその説明を<answer>【特殊能力】:説明</answer>タグ内に100文字程度で記述してください。"
これによって、次のような意図した結果を出力できるようにしています。
# 生成結果の例
{
'completion': '<answer>【怒りの一撃】:大地震を引き起こす一撃を〜〜</answer>'
}
文章生成関数のinvoke_text_model
Claudeを呼び出して、プロンプトから文章を生成するのがinvoke_関数です。
# テキスト生成モデルを呼び出し、指定されたプロンプトに基づいてテキストを生成する関数
def invoke_text_model(prompt):
# 文章生成に必要なパラメータを設定
body = json.dumps({
'prompt': prompt,
'max_tokens_to_sample': 200,
'temperature': 0.9,
'top_k': 180,
'top_p': 0.9
})
# 指定した基盤モデル『anthropic.claude-v2』でBedrockに生成をリクエスト
response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-v2',
body=body,
accept='application/json',
contentType='application/json'
)
# Bedrockからの応答を読み込み、JSONオブジェクトとして解析
response_body = json.loads(response['body'].read())
# 正規表現を使って、<answer></answer>タグで囲まれたテキストを抽出
match = re.search(r'<answer>(.*?)</answer>', response_body['completion'], re.DOTALL)
if match:
return match.group(1).strip() # タグ内の回答テキストのみを返す
else:
return "" # マッチしない場合は空文字を返す
この関数で重要なのは、次のパラメータ設定です。
# 文章生成に必要なパラメータを設定
body = json.dumps({
'prompt': prompt,
'temperature': 0.9,
'top_p': 0.9,
'top_k': 180,
'max_tokens_to_sample': 200,
})
promptは成形したプロンプトが入るところです。max_は出力文字数です。厳密な文字数ではないのですが、ほぼ同じ量となっています。予測の自由度を決めるtemperature、選択肢の広さを決めるtop_、候補の数を決めるtop_の各項目は直感的に分かりにくいですが、それぞれ数値が大きいほど、より多くの可能性が生まれ、結果にランダム性が増していきます。
Claudeの使い方としては、Claudeのサンプルが公式で用意されているので、これらのパラメータをいじるとどのようになるか試してみましょう。設定できるパラメータ数値の下限と上限もスライダー形式で直感的に分かりやすくなっています。微調整が必要な際に活用してみてください。
app.pyの変更点
app.generate_関数をapp.
# generate_ai.pyに作った『generate_monster_bedrock』を呼び出す
from generate_ai import generate_monster_bedrock
また、make関数内でDiscordから受信したテキストをgenerate_関数へ渡し、生成結果を取得します。
今回は動作確認として、Discordに生成した文章を表示してみます。生成結果を変数monster_に入れ、ctx.でDiscordにメッセージを送信しています。
@bot.command()
async def make(ctx, *, text: str):
logging.info(f'受信したメッセージ: {text}')
await ctx.send("ただいま作成中...")
# Discordから受け取った『text』のメッセージを『generate_monster_bedrock』関数に渡して、生成開始
monster_info = generate_monster_bedrock(text)
# 第3回では動作確認のため、生成したモンスターの情報をそのままDiscord上で表示してみます
# 以降のプログラムは第3回の動作確認用のプログラムなので、第4回以降は削除されます。
monster_details = (
f"**モンスター名**: {monster_info['monster_name']}\n"
f"**強さ**: {monster_info['monster_level']}\n"
f"**属性**: {monster_info['monster_element']}\n"
f"**特殊能力**: {monster_info['monster_ability']}\n"
f"**物語**: {monster_info['monster_episode']}"
)
# テキスト結果をDiscordに送信
await ctx.send(monster_details)
bot.run(TOKEN)
CDK環境からアプリを公開
アプリができたところで、前回と同じように本番公開してみます。
先にgihyo-torecaディレクトリ内のchapter-3で起動中の開発環境のDockerを
前回に続き、本番公開はcdk-gihyo-torecaのディレクトリで作業をします。
cdk-gihyo-torecaに遷移したら、PCの環境に合わせて次のどちらかのディレクトリに移動してください。
# macでm1およびm2を使っている場合 cd mac-m1-m2 # 上記以外の環境の場合 cd cdk
今回はBedrockをEC2から呼び出しているため、Bedrockを利用するポリシーをEC2のロールに追加する必要があります。このAWSに構築する設定は遷移先のapp.
# 第3回目に必要 Bedrockモデル呼び出し権限のインラインポリシーを作成しロールにアタッチ
ec2_role.add_to_policy(iam.PolicyStatement(
actions=["bedrock:InvokeModel"],
resources=["*"],
effect=iam.Effect.ALLOW
))
この権限許可の設定だけで、EC2からBedrockが利用可能になります。
AWS本番環境の構築の実施
本番公開する一連の流れは前回と同様なので、簡単に説明します。
本番公開
すでに上記の流れで次のディレクトリに遷移済みかと思いますが、自分のPCの環境のほうと間違いがないか確認してください。
# Dockerfileが置いていある場所へ移動 macでm1およびm2をお使いの方用 cd cdk-gihyo-toreca/mac-m1-m2 # Dockerfileが置いていある場所へ移動 上記以外の方用 cd cdk-gihyo-toreca/cdk
遷移後、Dockerfileが置いてあるディレクトリで次のコマンドを実行していきます。
# Dockerを起動して、コンテナ内に入ります docker-compose run --rm cdk # AWSへデプロイします 前回cdk destroyでAWS環境を削除していない方は、すでにAWS上に環境が構築されているので、すぐに処理が終わります。削除されている方は5分ほどで作成されます。 cdk deploy # AWS環境が作成後、EC2に接続します。 aws ssm start-session --target 作成したEC2のインスタンスID sudo su - ec2-user # GitHubよりアプリをクローンします。 git clone https://github.com/あなたのgithubアカウント名/gihyo-toreca.git # chapter-3に移動します。 cd gihyo-toreca/chapter-3 # DockerfileからDockerイメージを作成します。 docker build --no-cache -t gihyo-toreca . # Dockerイメージを起動します(コマンド内のボットトークンの指定も忘れずに)。 docker run --rm -it --name app-container -v "$(pwd)":/app -e DISCORD_BOT_TOKEN='あなたのボットのトークン' gihyo-toreca
公開停止・削除の方法
公開停止および削除の流れも、前回と同様です。
# EC2のDockerをCtrl + Cで終了します。 # その後、EC2とローカルとの接続解除します。 exit # AWS本番環境の削除します。 cdk destroy # ローカル環境のDockerを終了します。 exit
次回、Bedrockでの画像生成およびS3への画像保存
第4回目はBedrockで画像生成をし、HTMLとCSSを使ってレイアウトから保存するまでの方法に挑戦します。お楽しみに!