



Preferred Networksという企業
Preferred Networks社
筆者は2023年の12月にPFNを訪問し、土井裕介氏
本稿ではソフトウェアの会社であるPFNが、高い性能・
MN-Core 2モジュール
PFNは2017年からNVIDIA GPUを用いたクラスタシステム
そしていま第2世代のチップMN-Core 2が完成し、これを用いた大規模クラスタ計算機を2024年内に構築してクラウド提供が行われる予定です。
取材はこの新しいチップが載ったモジュール

- 安田: これがMN-Core 2のモジュールなんですね。
- 土井: はい。本番は緑の基板で、赤い基板は試作品なのですが、これはもう出来ていて先程通った廊下の先でも、JAMSTEC でも動いています。
- 安田: 「サーバー試験稼働中」
と書いてあった部屋ですか? - 土井: そうです 。チップは完成してプロダクションにも入っていて、あとは最終的に運用場所に運んで組み上げ、つまりサーバーベンダーさんから届いて我々の方でラックに入れてケーブルを入れて、といった工程です。2024年中には動きます。
- 安田: モジュールの背面を見ると、バックプレーンに差すような形をしていますね。バックプレーンも合わせて作っているのですね ?
- 土井: そうです。 今回、サーバベンダーさんの協力をいただいて、フロントロードの形にしました。接続はPCIeで、コネクターも活線で抜き差しできるものにしてあります。
- 安田: (持ってみると)
最近のGPUのモジュールなどもヒートシンクがものすごく重いのですが、これは比較的軽いですね。 - 土井: 1世代目のMN-Coreが無茶苦茶に重かったんです。厚さが普通のPCIスロットの4つぶんで、高さも倍なんですよ。
- 安田: えっ。そんなにあったんですか。熱の問題ですか?
- 土井: はい。チップにどう電源を供給するかで結構試行錯誤していました。定格で言うとワンチップが0.
55ボルトで500Wぐらい食います。つまりおよそ1キロアンペアという世界で。 - 安田: しかし外から与えるときはもっと電圧上げるんですよね?
- 土井: はい、そこからDC/
DC変換で下げて渡すんですが、ASICは、とくに (MN-Coreは) SIMDですから突然動くわけです。するとそこにある電子が足りないんです (はいはい)。
そこで銅箔の電源層を増やしたり、部品の配置を調整したり。ぶっちゃけて言うとそこを最適化する知見がまだなかったので、基板も大きく分厚くなり、ボード全体の600Wを冷やすためにヒートシンクも巨大なものがついて、という状態でした。 - 安田: レギュレータが周りを囲んでキャパシターが……
- 土井: ドッサリ載って、何とかかんとか動かした、という状態ですね。
「これは無理があるね」 とダウンサイジング版としてMN-Core 2を作りました。そのため性能としてはMN-Core 2は初代のMN-Coreからそんなには上がっていないのですが、電力性能では上がっています。
従来のMN-3は7Uのサーバにボード(チップ) は4つしか載りませんでした [1] 。それでも半精度で2ペタFLOPSなので、かなり速いんですけれども、今回は5Uのサーバに8つ乗るので ( 写真2 )、体積あたりの効率としては非常に高くなりました。MN-3ではMN-Coreを192基使っているのですが、MN-Core 2でいま構築中のシステムは256基となります。

行列計算のためのSIMDプロセッサ
先にMN-Core 2のアーキテクチャについて、ホワイトペーパーを簡単に見てみましょう。
MN-Coreは行列演算器
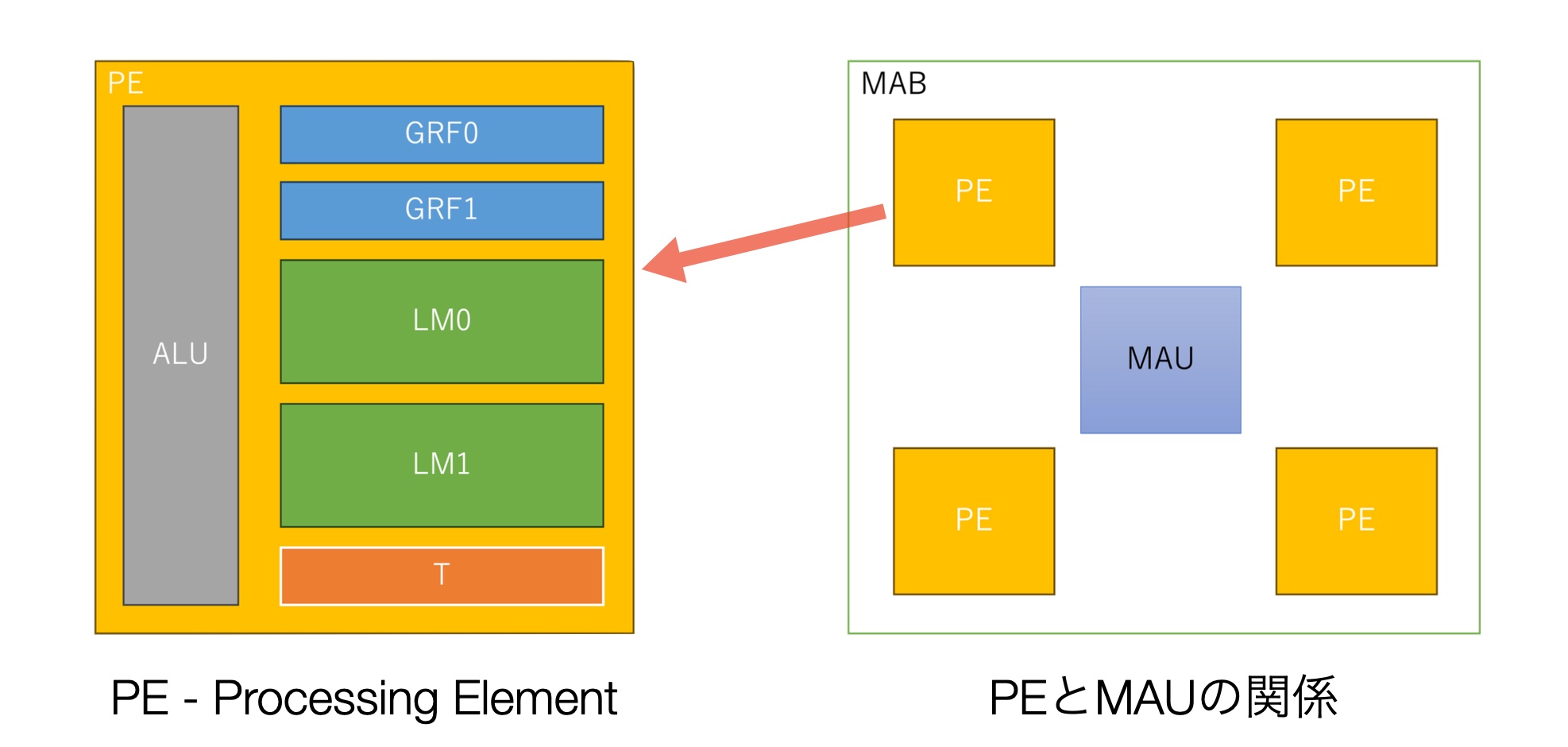
MN-Coreは深層学習の行列演算処理に集中し、その実行効率を最大化するための設計を追求したものです。
PFNの安達氏によると
取材ではまずこのあたりの工夫について伺いました。
- 安田: 各PEはプログラムカウンターを持たない、つまり命令用のメモリを持ってないのですよね?
- 土井: はい。ホストCPUからインストラクションをひたすら流し続ける仕組みになってます。
- 安田: 外から低レベルの命令を流している、と。
- 土井: はい。VLIWのような感じで、ALUの命令と、
(L1B、L2B間のデータ移動のための) データの縮約とか放送などの命令を同じタイミングで流します。 だから1回の命令受け渡しで1000bit以上のインストラクションが飛んでいきます。 - 安田: 僕にとってのこのアーキテクチャの謎は、行列演算器
(MAU) がほとんどのデータを処理しそうなのに、それが4つのPEでシェアされていることです。つまりPEはあまりMAUを使わないように見えます。 - 土井: あれ、逆なんですよ。行列演算器はPEが4つつながっているように見えますが、そうではなく行列演算器の1/
4のデータを各PEからくべてもらえる、という感じです (あ、そっちでしたか)。
逆に言うとPE1個にMAU1個だと帯域が足りないのです。MAU1個使い切るのにPEが4つ必要なのです。 - 安田: 1対1のものを4セット入れるより、この方が良かったんですか?
- 土井: そこは牧野先生にコメントいただかないと……
(笑)。このアーキテクチャは牧野先生が最初に作られたものですね。 - 安田: まあ
(MAUの1/ 4のデータを各PEからもらう形なら) 物理構成がこうなる (前出 図1) のはわかります。多分この絵は論理構成というよりは物理構成に近いのでしょう。 - 土井: そうですよ。もう本当にこうなっています。 実際のところ4つ別々に制御できるわけではないですし。
- 安田: なるほどよくわかりました。 ところで同一命令でみんなシンクロして動くということですが、L1Bの放送メモリの16セットでシンクロして動くような作りでしょうか?
- 土井: いえ、もう全部シンクロして動きます。インストラクション・
ストリーミングは1個しかないので (えっ) チップまとめて、全部同じインストラクションで動きます。 - 安田:そうなのですか……
(ちょっと驚き) - 土井: 結局ディープラーニングの世界だと、そんな小さな行列を相手にしていないんですよ。
データの動きを完全にコントロールする
議論は命令の与え方とデータの移動に進みます。
- 土井: MN-Coreではスケジュールに合わせて、コアの中のデータを全部入れ替えていきます。コアの脇についているDRAMとの入れ替えをずっと走らせています。そのためにインストラクションには必ずMV命令、つまりデータを動かす命令が付いていて、計算をしている時に次の計算に必要なデータをDRAMからフェッチ
(取り込み) してくるなどします。
つまり、コンパイラは各階層のSRAM上のどのデータがいつまで必要か、そのライフタイムを全部管理していて、どんどん上書きしながら実行していくという作り方になっています。 - 安田: VLIW では昔から静的解析を掛けてローレベルの命令を最適配置して流し込む、ということをやってきましたが、それをこの巨大な領域でやる、ということですね。
- 土井: そうですね。VLIWとはつまりハードウェアが露出しているわけですよ
(そうですそうです)。
それを細かく使ってプログラムをできるだけ早く実行して下さい、という仕組みですね。そしてそれができるのは、やはりディープラーニングに絞っているからです。基本的には大規模な行列演算をするわけですが、その計算の単位が大きく、メモリのアクセスに対する負荷が低いということがあります。
あとはahead of time scheduling(予定された通りに前もってスケジューリングする) が可能なことですね。FORTRAN とかで書かれたコードに比べて抽象度が高く、CやFORTRANのプログラムを静的解析するよりもはるかに高い精度で、そのデータのライフタイムなどを最適化して命令を詰め込むことができます。 - 安田: おもしろいです。VLIW的なものを作って、自分たちが全部ソフトで制御してチューニングするんだ、というのは
(プロセッサ屋の) 1つの夢だと思います。 - 土井: そしてMN-Coreならどう動かせば、どれぐらいの速度で動くか、がコンパイラを通せばわかります。つまり出てきたコードのサイズがそのまま実行サイクル数なので
(ああ!)、別にハードがなくても最適化できちゃうんですよね。 - 安田: ああそうか。おもしろいですね。
- 土井: つまり最適化の過程といってもコンパイルしているだけで、実行はしていないんです。どこで時間が掛かっているかがハードウェア的に露出しているので、その意味で最適化しやすいですし。牧野先生も
「このほうが最適化しやすい、性能出すの簡単だよ」 と言っています。 - 安田: コンパイルして出たコードを解析すると、ここ遅いじゃないの、とわかるんですね。
- 土井: はい。これとこれを重ねれば良いよね、ということがすぐわかっちゃうんです。
デザインチョイス
お話を伺うほどに、これはプロセッサどころかコンパイラを含めてシステムを丸ごと設計する状況であるとわかってきました。
- 安田: そういった設計では多くのデザインチョイスがあったと思うんですね。その中で土井さん的におもしろかったものはどれでしょう。
- 土井: ソフトウェアに頼る構成そのものでしょうか。結局のところ、ハードが見えているかどうかで最適化の懐って変わってくるんですね。ハードウェアをできるだけシンプルに作って、あとはソフトウェアに任せる構成が取れていたのは、振り返ってみると一番大きかったかなと思います。
MN-Coreはある種の専用プロセッサなのですが、ニューラルネットワークはそれ自体がある意味汎用性がありますから「ニューラルネットワーク専用」 は 「単目的」 ではないんです。プロセッサとしては単目的 (シングルパーパス) だが、アプリケーションとしてはシングルパーパスではない、と。だから専用化をしても大丈夫だよね、という判断が2016年当時できていました。
今はもう皆そう考えていますが、あのころにそこまで判断して動いていたのはおもしろかったと思います。 - 安田: ターゲットを深層学習のラーニングに絞ったとしても、ASIC焼くまでが早いなあ、と思います。
- 土井: ディープラーニングに賭けるぞ、ということで会社がスタートしているのと、そこは
(CEOで創業者) 西川の 「えいやっ」 て感じですね。私が決断しろと言われたらできなかったと思います。また西川は学生時代、 (牧野教授の) GRAPE-DRに関わっていたので、石を焼くことに関しては肌感を持っていたのですね。
GRAPE-DRをもとに行列演算と深層学習のための回路を追加して、 PFNのコンパイラを載せて、カーネルについてはどのようなものでも組める。たとえば複数のカーネルならメモリ移動や計算のスケジュールをうまく組めばバラバラに実行するより速くなる。そんな読みがあって、実際にやってのけた、というのがPFNと「牧野イズム」 がくっついた最大の面白さかなと思います。
将来のアーキテクチャ
議論は現在のハードウェア進化のトレンド、つまりメモリのデータ移動が非常に重い、ということについて進みました。
- 土井: 牧野先生との議論でもあったのですが、メモリをグローバルなアドレス空間1本で扱うというプログラミングパラダイム自体がもはや限界なんですよ。
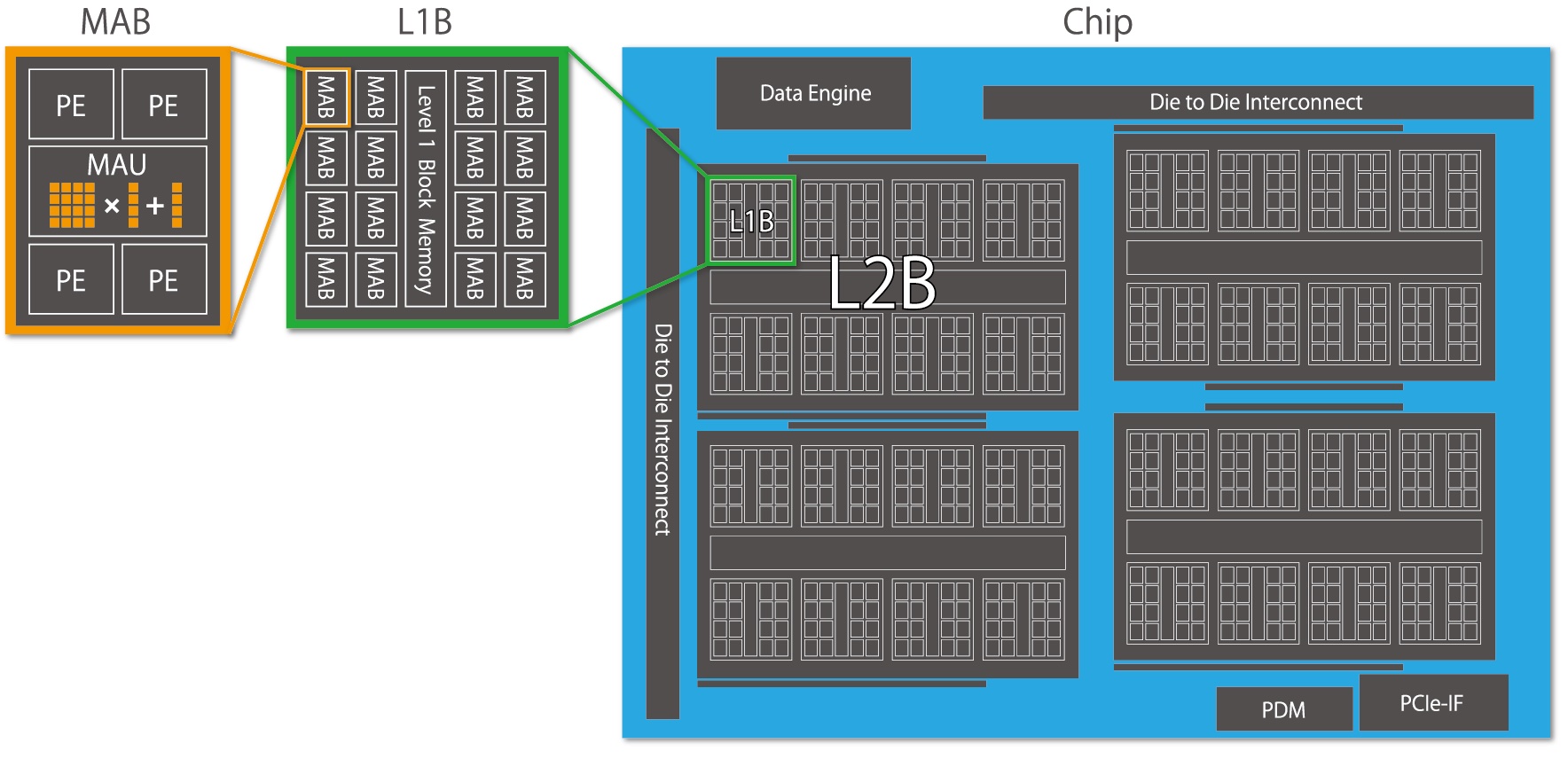
MN-CoreはメモリのL3、L2、L1、MABという、それぞれのメモリ階層をプログラマが陽に扱わなければいけない、という制約を課しています。そうすることで逆にハードウェアが簡単になって、データ移動の最適化をソフトウェアレベルでできるようになりました。
ハードウェアのこのあたりの仕組みが隠蔽されていると、ハードウェアの中でのデータ移動がどうしても最適化しきれません。そういう仕組みは既存のプログラムを動かすという立場からは良いのですが、そのためのコストというのは3nm、2nm、1.5nmと進んでいくにつれ、どんどん上がっていくんじゃないか、というのがPFNの立場です。 - 安田: アプリケーションソフトウェアに対して透過的なハードウェアを作ってチューニングする、というのはコストフルだ、ということですね。
- 土井: はい。そこでシリコンの無駄をしているところも多く、またロジックも複雑になってコストが上がります。CPUのロードマップはあるけれど、その通り出てこなかったりします
(ありますね)。
最近、ハードウェアが複雑になっているので、どうしてもハードウェアのデバックがかかって、リスピン[3]を何度も掛けて、みたいな話が伝え聞こえてくると、なるべくシンプルな方がいいよねと思います。
- 安田: Intelのような、頑張ってハードウェアを積み重ねた従来的なプロセッサに対して、その逆のポジションに
(MN-Coreは) 行った、ということですね。 - 土井: はい。とある方に
「このシステムは最もシンプルなハードウェアを最も複雑なソフトウェアでドライブするんだね」 と言われました。 - 安田: たしかにそうですね。それでもこれだけニューラルネットに絞ってこうなったわけですから、もし用途を変えていくとまた大きな苦労が出てしまうでしょうね。
- 土井: まあソフトに苦労が出ているのなら、それはやれば良いんですよ。でもハードはもうできないじゃないですか
(たしかに)。
CPUベンダさんは何度もリスピンして出しますけど、はっきり言ってしまうと我々のような会社にそんなお金はないですよ(笑)。

ソフトウェア会社が作るプロセッサ
土井さんは、MN-Coreができたのは
- 土井: PFNはソフトウェアというかアルゴリズム屋さんが多いんですね。Kaggleであるとか、プログラミングコンテストとかデータ分析コンテストなどに挑戦してきたメンバーが多いのです。創業者もそうでしたし。ICPC
(国際大学対抗プログラミングコンテスト) とかのメンバーが揃っています。
それで社内のCIのダッシュボードでは、たとえば、ResNet-50は今、何ミリセカンドでワンサイクル実行できます、といったものが表示されているんですよ。PR(Pull Request) が飛んでくればまた回って、それで良くなった悪くなったというのが如実にわかって、コンパイラのチームはそれをベースに開発しています。
このPR入れるとこのアプリケーションだと速くなるけど、こっちは悪くなった、といったことも当然起きます。そういうのを見ながらイテレーティブな改善を繰り返すことができる、そんなソフトウェア的な開発ができるようになっていますね。
PFNという組織からこのアーキテクチャが出てきたのは、たまたまかもしれないし狙ったのかもしれないです。 私、実はアーキテクチャを作る最初の時には計算基盤の担当で、チップは作ってなかったんです。だからそのときどこまで考え抜いてこういう「ソフトに任せることによって性能が出る」 アーキテクチャにしたのかは伝聞でしか知らないのですけど、後から見るとソフトが強い会社としてのPFNが作るチップとしてはまったくもって正解だったな、と思います。
筆者にとってPFN取材の興味はMN-Coreチップにありました。しかし取材を通して、全体アーキテクチャと彼らの設計アプローチを知り、PFNがソフトウェア会社であることを強く感じました。
また、今の先端プロセスではリスピンは大問題で、そうならない方向に行かなければ、というのは他のプロセッサ開発企業からも聞きます。PFNと同様の設計アプローチで次世代の先端プロセッサに挑むところが増えていくかもしれません。
筆者は2004年のTransmeta[4]を初めとして、先進的な設計のプロセッサをいくつも取材してきました。どれも設計思想がクリアで、それをストレートに実装したものでした。そうして作られたモノはどれも美しい。
MN-Coreも間違いなく、そうしたプロセッサの1つであり、今後のプロセッサ開発におけるソフトウェアとハードウェアの分界点のようなものについて考えさせられる取材となりました。土井さんはじめ、PFNの皆さまに感謝します。
追記
ちょうど本稿を書き終えたころに
筆者は参加できませんでしたが、以下URLから資料、講演ともにアクセスできます。
https://
アーキテクチャ関連の話題もあります。ぜひこちらもどうぞ。