



門脇
ワークフロー・フレームワークとは何か
データを扱う現場では、定期的に実行する処理が必ず存在します。たとえば、指定した時間やタイミングでデータを集計したり、データがアップロードされたら自動でデータベースに反映したりするなど、一定のルールに基づいて処理を行うことがよくあります。
こうした処理は、最初はローカルでのスクリプト実行やLinuxであればCronジョブで十分に運用できます。また、AWSなどのクラウド基盤を利用している人は、Lambdaのようなイベント駆動による実行環境を作成して運用する事例も多いのではないかと思います。
しかし、シンプルな処理ではそれで十分でも、業務が成長し処理が複雑化すると次のような問題が起こることがあります。
- 実行タイミングや順序がわかりにくく、全体を把握しづらい
- 実行時のログが分散してしまい実行履歴がわかりにくい、失敗時の原因特定が困難
- 再実行に手間がかかる
(途中から再開できず、全部やり直しなど) - 処理の依存関係が複雑
(前の処理が終わらないと次に進めないなど)
このような背景から、複数の処理を順序や依存関係に従って自動で実行・
- 処理の可視化:ワークフロー全体をグラフやダッシュボードで見える化
- 失敗時の自動再実行:条件に応じて再試行や失敗時の処理を定義
(エラー通知など) - 依存関係の管理:処理の順序を定義し、自動的に実行順を調整
- スケジューリング:特定の時刻やイベントで自動実行
従来のCronでスクリプトを実行する運用と大きく違うのは、ただ動かすだけでなく、
Pythonで利用できる代表的なワークフロー・フレームワーク
Pythonで利用可能なワークフロー・
- Airflow - airflow.
apache. org - DAG
(有向非巡回グラフ) ベースでワークフローを定義 - 実績豊富でプラグインが多く、UIも充実
- インフラ構築が重く、学習コストは高め
- DAG
- Luigi - luigi.
readthedocs. io - 軽量でシンプル、依存タスク管理に特化
- バッチ処理など小規模な用途に向いており、導入も容易
- UIが弱く、中〜大規模化には不向き
- Prefect - prefect.
io 「Airflowをモダンに作り直した」 フレームワーク - Pythonコードで直感的に書け、柔軟で開発者体験が良い
- SaaS版の Prefect Cloud もあり、クラウドでの運用が容易
- Dagster - dagster.
io - 型安全やデータ品質を強く意識した設計
- Web UIが優秀で、開発から運用までを統合的にサポート
- 機械学習やデータパイプラインと相性が良い
- 単純なバッチ処理にはややオーバースペック
- Kedro - kedro.
org - データサイエンスや機械学習向けに特化したフレームワーク
- プロジェクトテンプレートを備え、データサイエンスに必要な再現性を高められる
- 汎用性は低く、データサイエンス以外では使いづらい
- restate - restate.
dev - Pythonだけでなく複数言語に対応したイベント駆動型フレームワーク
- ステートフルなタスク管理を前提とし、耐障害性に強い
- APIとして組み込める柔軟さを持つ
Pythonでよく使用されるワークフロー・
Prefectとは
Prefectは、近年注目を集めているPython製のワークフロー・
主な特徴としては次のような点が挙げられます。
- Pythonコードで記述可能
- ―デコレータを使ってタスクやフローを定義できる
- UIによる可視化と監視
- ―OSS版やクラウド版のダッシュボードで実行状況を確認できる
- ローカルからクラウドへの移行が容易
- ―開発環境で試したものをそのまま本番運用に適用可能
- 動的なワークフロー構築
- ―条件分岐やフローの動的生成にも柔軟に対応
「ローカルで書いて試し、必要に応じてクラウドに載せる」
Prefectのコアコンセプト
実際にPrefectでワークフローを動かしてみる前に、Prefectの主要なコンセプトを理解しておくと、全体像がよりわかりやすくなります。Prefectで使用される主な用語について簡単に説明します。より詳しく知りたい方は、以下の公式ドキュメントにも目を通してみてください。
| 用語 | 説明 |
|---|---|
| Task | 1つの関数 |
| Flow | Taskを組み合わせて処理全体の流れ |
| Deployment | Flowを実際に動かすための設定。いつ、どこで実行するかを定義する |
| Work Pool | 動的な実行環境を設定/管理するための仕組み |
| Variable | 実行時にTaskやFlowから参照できるパラメータ |
| Block | 接続情報や認証情報などのシークレットを管理する機能 |
| Automation | 条件に応じた自動アクションを設定できる仕組み |
| Event | Prefect内で発生したイベントなどを時系列に記録したもの |
| Concurrency | 同時実行数を制御する仕組み。システム全体またはTaskごとに指定可能 |
Prefectのインストールとサーバーの起動
それでは実際にPrefectをインストールして試してみましょう。執筆時点でのバージョンと筆者の利用環境は以下のとおりです。
- Python仮想環境: uv 0.
8.12 - Pythonバージョン: 3.
13. 7 - Prefect: 3.
4.13
Prefectの開発はかなり活発に行われており、執筆時点でもマイナーバージョンが上がっています。また、Prefectのバージョンについては2系も開発が続いていますが、本記事ではバージョン3系を使用しています。
Prefectのインストールは、pipコマンドを実行するだけです。
$ uv pip install -U prefect # Pythonのvenvを使用する場合は `pip install`
Prefect Serverの起動
続いてPrefect Serverを以下のコマンドで起動します。
$ prefect server start
___ ___ ___ ___ ___ ___ _____
| _ \ _ \ __| __| __/ __|_ _|
| _/ / _|| _|| _| (__ | |
|_| |_|_\___|_| |___\___| |_|
Configure Prefect to communicate with the server with:
prefect config set PREFECT_API_URL=http://127.0.0.1:4200/api
View the API reference documentation at http://127.0.0.1:4200/docs
Check out the dashboard at http://127.0.0.1:4200
Prefect Serverは、ワークフローの実行状況を管理・prefect server start を実行すると、内部的にAPIサーバーやデータベース [2]、Web UIなどが起動します。
起動後にブラウザからhttp://にアクセスすると、Web UIを利用できます。Web UIではワークフローの一覧や実行結果、スケジュールの状態を確認することができます。
実際にアクセスしてみると以下のような画面が表示されます
Prefectでモダンなワークフローを体験
それでは実際に簡単なスクリプトを使用してPrefectによるワークフローを試してみましょう。前述のとおり、Prefectでは各種クラウドサービスとも連係できますが、本記事ではローカルで起動したPrefect Serverを利用して基本的な流れを体験します。
ローカルで簡単なFlowを作る
ここでは簡単なサンプルとして以下の2つのTask
- 文字列を整形するタスク
- 文字列を逆順にして出力するタスク
タスクとフローの定義はとても簡単で、@taskと@flowデコレータを使うだけで簡単に定義できます。
from prefect import task, flow
# 文字列を整形するタスク
@task
def get_title(text: str) -> str:
return text.strip().title()
# 文字列を逆順にして出力するタスク
@task
def hello(title_text: str):
reversed_text = title_text[::-1]
print(f"Hello, {title_text}! (reversed: {reversed_text})")
# フローを定義する
@flow
def hello_flow():
# 実行する順番にタスクを呼び出す
title_text = get_title(" prefect flow ")
hello(title_text)
if __name__ == "__main__":
hello_flow()
動作確認のため、スクリプトを実行してみましょう。
$ python3.13 hello_flow.py 01:56:42.664 | INFO | Flow run 'spectacular-goose' - Beginning flow run 'spectacular-goose' for flow 'hello-flow' 01:56:42.665 | INFO | Flow run 'spectacular-goose' - View at http://127.0.0.1:4200/runs/flow-run/f8b520bc-a6a6-4ae0-af9c-d5465ec4b082 01:56:42.695 | INFO | Task run 'get_title-340' - Finished in state Completed() Hello, Prefect Flow! (reversed: wolF tceferP) 01:56:42.719 | INFO | Task run 'hello-6b0' - Finished in state Completed() 01:56:42.733 | INFO | Flow run 'spectacular-goose' - Finished in state Completed()
出力内容を見ると、最初にspectacular-gooseというフローの実行ごとにPrefectが自動的に生成した名前がつけられています。その後、フロー名やログを確認できるURLと合わせて、各タスクの実行ステータスや実行結果 (Hello, Prefect Flow! (reversed: wolF tceferP))Flow run 'spectacular-goose' - Finished in state Completed()と表示されてフローが正常終了していることが確認できます。
実行結果はWeb UIにもこの時点で反映されています。出力されたURL http://にアクセスしてみてください。以下のようなタスクの実行経過やログが確認できるはずです。
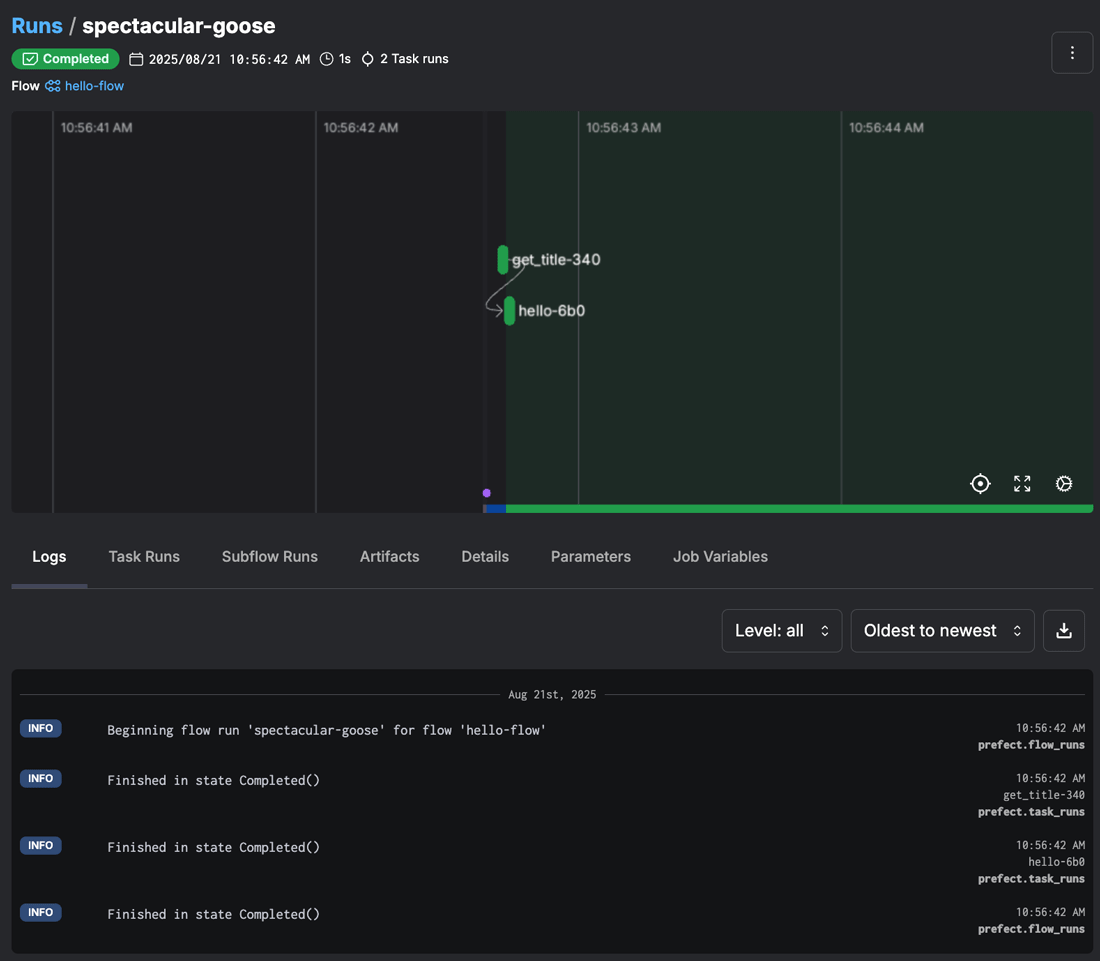
たったこれだけでWeb UIと連携したワークフローが作成できるなんて、とても便利ですね!
ただ、1つ気になることがあります。文字列出力に使用したprint関数はコマンドライン上の出力には表示されていますが、Web UIには表示されていません。print関数は、Pythonの標準出力に送られるのみで、Prefectのログシステムには送られないようです。
Prefectでフローの実行ログを残すには、以下のように専用のget_関数を使用してロガーを取得し、そのロガーを使って出力します。get_関数は、並列や分散実行されたタスクのログもフロー単位にまとめてくれるなどのメリットもあるため、最初に覚えておくとよいです。
from prefect import get_run_logger
# 文字列を出力するタスク(ロガーを利用)
@task
def hello(title_text: str):
logger = get_run_logger()
reversed_text = title_text[::-1]
logger.info((f"Hello, {title_text}! (reversed: {reversed_text})"))
Deploymentを定義
ローカル実行でフローを確認したら、次のステップは
デプロイメントを作成するには以下のようにします。最初にprefect initコマンドで
出力画面は内容を一部割愛しています。選択項目のリストからはlocalを選択して、ローカル環境でそのまま動作確認させるための設定をしていきます。
$ prefect init # プロジェクトの直下で初期化(prefect.yaml ができる) ? Would you like to initialize your deployment configuration with a recipe? [Use arrows to move; enter to select; n to select none] ┏━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ Name ┃ Description ┃ ┡━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ │ git │ Store code within git repository │ │ │ docker │ Store code within a custom docker image alongside its runtime environment │ │ │ s3 │ Store code within an S3 bucket │ │ > │ local │ Store code on a local filesystem │ │ │ │ No, I'll use the default deployment configuration. │ └────┴──────────────┴───────────────────────────────────────────────────────────────────────────────────────────────┘ Created project in /...(省略).../source/2025/202508 with the following new files: .prefectignore prefect.yaml
出力されたprefect.
name: 'Python Monthly Topics August' # ← プロジェクト名を任意に変更
prefect-version: 3.4.13
build: null
push: null
pull:
- prefect.deployments.steps.set_working_directory:
directory: /...(省略).../source/2025/202508
deployments:
- name: "hello_flow" # ← デプロイメント名を任意に設定
version: null
tags: []
description: null
schedules:
- cron: "0 14 * * *" # ← JST 9時に実行するスケジュールを追加
slug: "tokyo-9am" # ← スケジュールを識別する一意な名前
timezone: "Asia/Tokyo" # ← タイムゾーン(JSTで設定)
active: true # ← スケジュールが有効
- cron: "0 12 * * *" # ← UTC 正午のスケジュールを追加(無効化)
slug: "utc-noon"
timezone: "UTC" # ← タイムゾーン(UTCで設定)
active: false # ← スケジュールが無効
flow_name: "hello_flow" # ← フロー名
entrypoint: hello_flow_1.py:hello_flow # ← 実行ファイルと関数名を指定
parameters: {}
work_pool: # ← 実際のワークプールに合わせて設定する(今回は割愛)
name: null
work_queue_name: null
job_variables: {}
デプロイメントの登録は、prefect deployコマンドで行います。引数に--name hello_のようにフロー名を指定するだけですが、このコマンド実行時にprefect.
実行すると、対話モードでWork Poolsyを入力し、ここでは実行環境をローカルのサブプロセス実行とするprocessを指定しますWork pool name:の入力を促されるので適宜入力hellow_)
$ prefect deploy --name hello_flow
? Looks like you don't have any work pools this flow can be deployed to. Would you like to create one? [y/n] (y): y
? What infrastructure type would you like to use for your new work pool? [Use arrows to move; enter to select]
┏━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ Type ┃ Description ┃
┡━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ > │ process │ Execute flow runs as subprocesses on a worker. Works well for local execution when first getting started. │
├────┼──────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ │ docker │ Execute flow runs within Docker containers. (省略) │
├────┼──────────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ │ kubernetes │ Execute flow runs within jobs scheduled on a Kubernetes cluster. Requires a Kubernetes cluster. │
└────┴──────────────────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
? Work pool name: hello_flow_pool
Your work pool 'hello_flow_pool' has been created!
╭───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Deployment 'hello-flow/hello_flow' successfully created with id '5e07e9a9-6b1f-438d-b37d-6933194bf43f'. │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
View Deployment in UI: http://127.0.0.1:4200/deployments/deployment/5e07e9a9-6b1f-438d-b37d-6933194bf43f
To execute flow runs from these deployments, start a worker in a separate terminal that pulls work from the None work pool:
$ prefect worker start --pool None
To schedule a run for this deployment, use the following command:
$ prefect deployment run 'hello-flow/hello_flow'
ここで1つ注意点があります。Prefectのフロー名は内部的にスラッグ化hello_はhello-flowに変更されていることがわかります。
実際に作成されたデプロイメントの状態をWeb UIから確認してみると、以下のスクリーンショットように作成されていることがわかります。
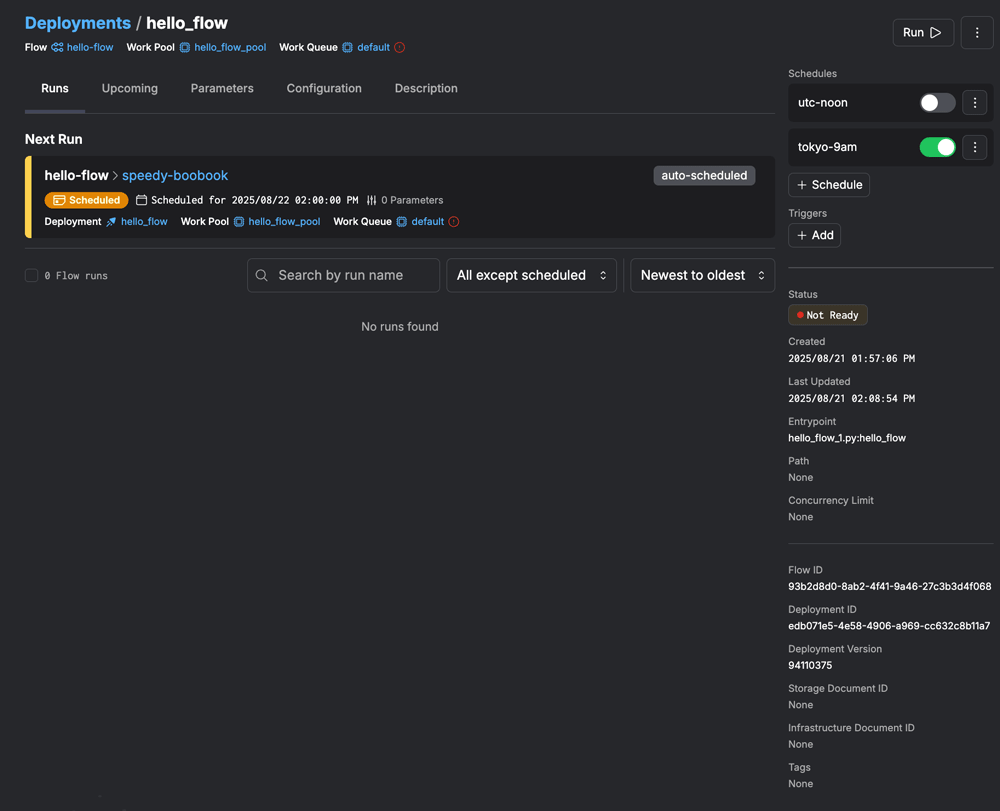
Web UIからもわかるように、指定したフローがprefect.
続いてWork Poolsも見てみます。すでにフローがデフォルトで3回分
しかし、Work Poolsの状態としてはNot Readyになっており、このままでは実行環境がない状態であることがうかがえます。
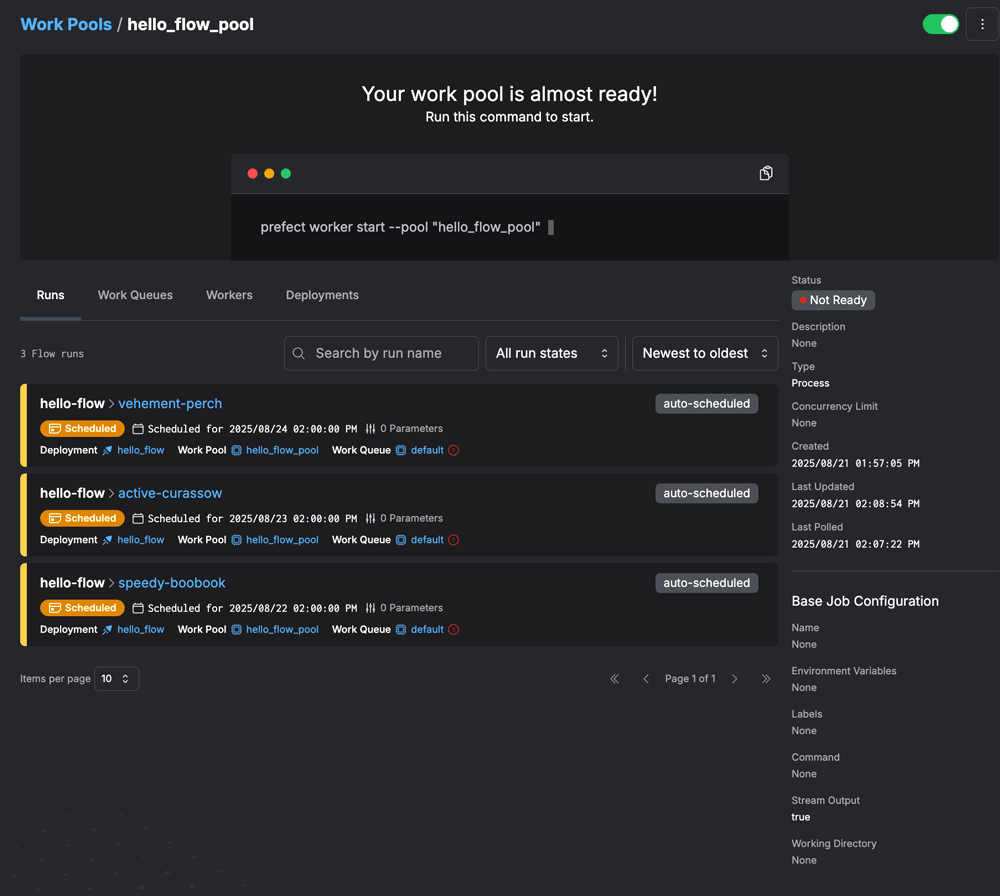
実行環境であるWork Poolを起動するには、Web UI上に表示されているprefect worker start --pool "hello_を実行する必要があります。このコマンドの実行によってProcessWorkerが起動し、Work PoolsがReady状態になります。
$ prefect worker start --pool "hello_flow_pool" Discovered type 'process' for work pool 'hello_flow_pool'. Worker 'ProcessWorker ecb4a774-f753-4cb3-a97a-2be4a9790c9e' started!
Work Pools がReady状態になったことで、ようやくフローを実行できる準備がすべて整いました。試しにデプロイメント画面から

ここで改めて、全体の流れを確認してみましょう。Prefectの実行は以下のような流れで進みます。
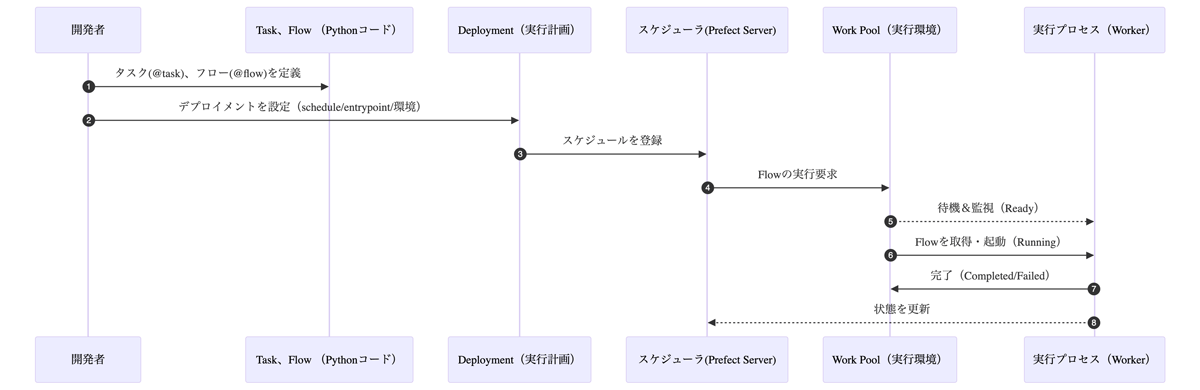
前述のReady状態」
それぞれの役割を整理すると、以下のようになります。
- Task/
Flowで実行する処理をPythonで定義 - Deploymentで
「いつ・ どこで」 Flowを実行するかを設定 - Prefect ServerがDeploymentに基づいてFlowスケジュールを生成
- 実行要求をプールしておく環境
(Work Pool) で待機/監視/実行 - 実行プロセス
(Worker) でスクリプトの結果をPrefectサーバに返す
ここまで見てきたように、Prefectはほんの数行のPythonコードから始めることができ、Web UIによる実行管理やスケジュール実行まで、ひととおりをあっという間に体験することができました。最初のセットアップさえ済ませてしまえば、従来のCronや単純なスクリプト実行よりもはるかに
まとめ
今回は、Pythonで利用できるワークフロー・
まずは簡単なタスクをつないでフローを作成し、UIで可視化・
みなさんも普段使っているちょっとしたスクリプトで、ぜひPrefectを試してみてください。また、Pythonでは、その他のワークフロー・