


NVIDIAは2025年9月23日、日本における人口統計、地理的分布、性格特性の分布に基づいて合成的に生成されたペルソナのオープンソースデータセット
🚀 新データセット公開: Nemotron-Personas-Japan
— NVIDIA Japan (@NVIDIAJapan) September 24, 2025
日本の人口構成や文化に合わせて作られた、初のオープンな日本語合成データセットを公開しました。商用利用も可能です。 https://t. co/ cVnHcUGvns
Nemotron-Personas-Japanは、日本のモデル開発者が地域固有の人口統計や文化的背景を取り入れたAIシステムを開発することを支援するために生成された。同社ではすでに米国における名前、性別、年齢、背景、婚姻状況、学歴、職業、居住地などの統計に基づいて生成したオープンデータNemotron-Personasを公開しているが、Nemotron-Personas-Japanはその日本版にあたる。
データセットはNVIDIAの合成データ生成用マイクロサービスNeMo Data Designerを用いて構築され、生成には以下のモデルも活用されている
- Probabilistic Graphical Model
(PGM):統計的根拠付けのため - GPT-OSS-120Bモデル:日本語によるナラティブ生成のため
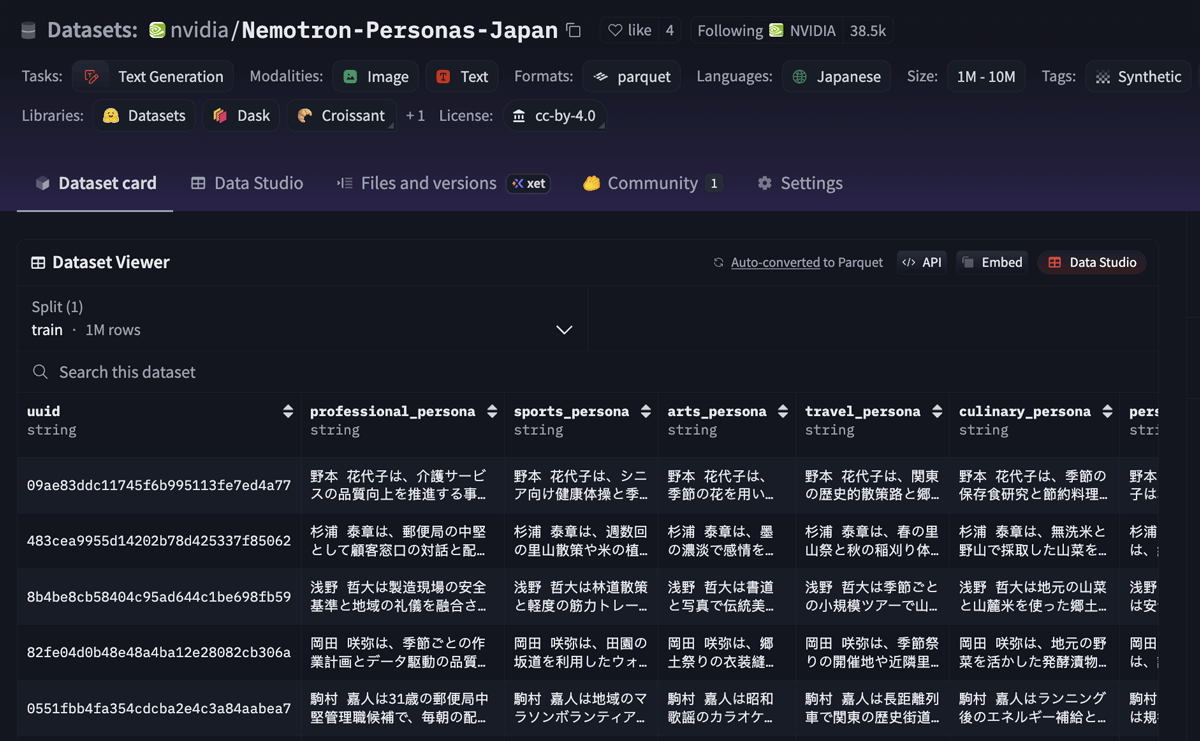
Nemotron-Personas-JapanはNVIDIA Llama NemotronモデルをはじめとするオープンソースLLMとシームレスに連携するように設計されており、チャットボットからドメイン固有のCopilotまで、日本のAIアプリケーションに合わせて容易に微調整ができるようになっている。データセットには以下のようなデータが含まれる。
- 日本語で記録された100万件のレコード
(1レコードあたり6つのペルソナ=合計600万ペルソナ) - 22フィールド/6つのペルソナフィールドと、公式の人口統計・
労働統計に基づく16のコンテキストフィールド - 約14億トークン
(うちペルソナ関連トークンが約8. 5億) - 人口統計・
地理・ 性格特性などの軸にまたがる包括的なデータ - 約95万件のユニークな名前
- 日本の労働人口を反映する1,500以上の職業カテゴリ
- プロフェッショナル、スポーツ、芸術、旅行、料理など多様なペルソナタイプ
- 文化的背景、スキルと専門性、目標と志向、趣味や関心といった自然言語のペルソナ属性
また、日本の人口統計や労働統計に加え、以下のような文化的コンテキストも考慮されている。
- 教育:国の統計では学位レベルが大まかに分類されているが、モデルが異なる教育経路を反映できるようより細分化
- 職業:自営業や専門職種などの追加カテゴリを取り入れ、学習に用いる職業スペクトラムを拡大
- ライフステージ:統計上はあまり表に出ない学生、退職者、失業状態といったシナリオをモデリングし、より現実的なペルソナを表現
- 文化的特性:日本の社会的・
文化的特徴を組み込み、AIシステムが地域固有の規範をより正確に反映できるように - デジタルデバイド:年齢層ごとのデジタルリテラシーの差を考慮し、日本における実際のテクノロジー利用状況を反映
なお、データセットには個人を特定できる情報は一切含まれていない。すべてのペルソナは完全に合成されているため、年齢、氏名、職業が実在の人物
Nemotron-Personas-JapanはCC BY 4.