



はじめに
株式会社MIXIで
みてねの写真プリントサービスでは、ユーザが毎月アップロードした写真の中から、最適な11枚を自動的に選び出してプリント注文に適した写真を自動提案しています。
前回の記事では、従来のルールベースからMLベースへの移行について紹介しましたが、今回は、MLベースの自動提案の前後となるデータ収集部、データ配信部の紹介をします。
みてねの写真プリントサービスについて
みてねの写真プリントサービスは、大切な思い出の写真を高品質なプリントとして手元に残せる人気のサービスです。スマートフォンに保存されたままになっている写真を、実際に手に取って楽しむことができます。

このサービスのおもな特徴は以下のとおりです。
- 毎月11枚まで写真プリントが永続的に無料
- 月に3回まで送料のみで注文可能
- 家族全員がそれぞれ無料で注文可能
- アップロード済みの写真から自由に選択してプリント
- 毎月、前月アップロード分からおすすめの11枚を自動提案
とくに注目していただきたいのが、最後の
本記事では、大量のデータ生成において工夫したポイントや、MLに読み込ませるデータの準備方法などについてご紹介します。
写真プリントの自動提案とは
みてねの写真プリントのユーザ補助機能の1つであり、先月ユーザがアップロードした写真から毎月1回自動的におすすめの11枚を選択しユーザに提案します。
本システムで自動提案した写真群から、お好みの写真に入れ替える方も、提案した写真をそのまま購入される方もいます。
たくさんの写真の中からプリントする写真を探すのは楽しいものではあるものの、一方で多忙で時間のとれない方には手間のかかる作業となるため、自動提案の質を高めユーザの操作負荷を減らすことを目的としています。
自動提案データの特性
静的データである
みてねではリアルタイム生成ではなく、毎月1回の配信日に合わせてバッチ処理的に提案データを生成しています。
生存期間が長い
アプリ内のストアに
対象者が多い
約2,500万ユーザ
生成速度は速いほど良い
配信日を起点にして、生成速度が速ければ直前までアップロードされた写真を自動提案に含むことができます。逆に生成に数日かかる場合は、その差分の数日間の写真は提案データに利用できないため、提案品質が下がります。
2025年1月12日
— 家族アルバム みてね (@mitene_official) January 14, 2025(日) に、みてねの世界累計利用者数が2500万人を突破いたしました!
2015 年のリリース以後、お子さまが産まれたら使用するアプリとしてご愛用いただき、日本国内ではママやパパの半数となる約60%の方にご利用されています。 https://t. co/ C6bqXCNW61
写真プリント自動提案システムの概要
写真プリント自動提案システムは、以下のような構成で大規模データ生成を実現しています。
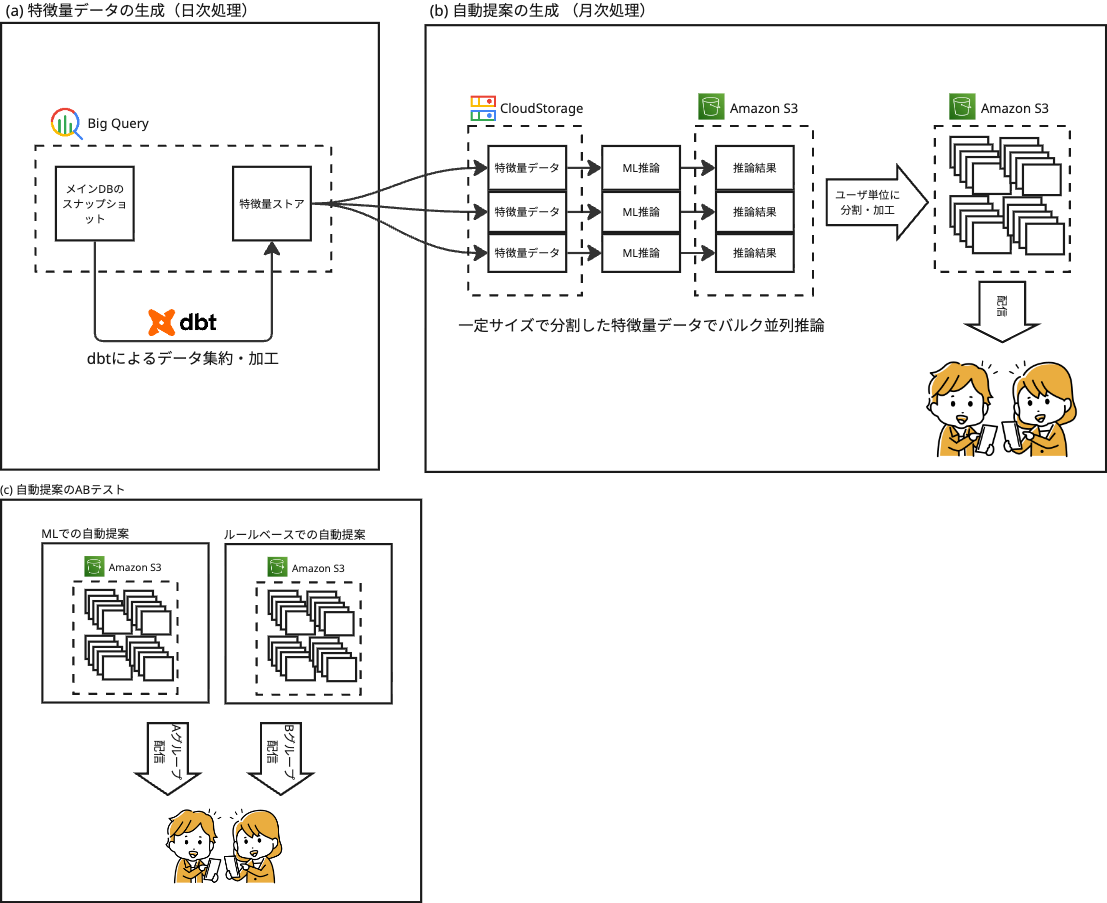
(a) 特徴量データの生成(日次処理)
①特徴量ストア更新:毎日アップロードされた写真から、dbt
(b) 自動提案の生成 (月次処理)
①ML推論をバッチ処理:特徴量ストアをBigQueryに持っているため、単純にユーザごとにクエリを投げてしまうと数千万回のクエリが発生してしまいます。
効率化のため、ある程度の人数分でバッチサイズを定め、特徴量データをまとめてBigQueryからGoogle Cloud Storageにエクスポートし、ML推論インスタンスで推論させています。バッチサイズはインフラで安定的に処理可能なサイズを実験検証した上で決定しています。
②結果受け取りと保存:ML推論結果を受け取り、所定の後処理を加えて各ユーザごとの提案データとして整形しS3に保存します。 ここでもSidekiqなどを用いて、DB負荷がかかりすぎないよう適度に流量をコントロールしています。
③配信:所定の配信日には、ユーザへPush通知を送信し自動提案をアプリ内に表示します。 配信時、ユーザから見えるデータとしてS3の提案データは古すぎる可能性もあるため、提案データとRDBの最新データを突き合わせて整合性をとりながら動的にレスポンスを生成しています。
④例外処理:図に記載していませんが、ステータス管理によって、何らかの理由で失敗したユーザには、ML推論を適宜リトライするように調整しながら運用しています
(c) 自動提案のABテスト
①従来のルールベース自動提案とMLベース自動提案のABテスト:前回の記事では、従来のルールベースからMLベースへの移行について紹介しましたが、 配信部分では、ルールベースの提案データと、MLベースの提案データのどちらを配信するのかを条件分岐し、ABテストで比較できるようにしています。
この仕組みにより、新しい自動提案システムが追加された場合でもABテストを実施しながら比較検証することが可能です。
システム概要のまとめ
数百万~数千万単位のユーザにおすすめ写真を提案するため、どのような構成にすると並列度を高められるかを重視した仕組みとなっています。
並列度を高めるためにGCS/
本記事で紹介したいテーマ
本記事ではdbtとS3の活用方法を掘り下げて紹介します。 なお推論で利用するMLモデルについては別記事にて詳しく紹介しています。
①BigQueryとdbtを活用したデータセット構築
MLモデルの学習や推論に仕様するデータは、みてねのRDBの情報やFirebase の Event Logなど、様々なデータソースから取得する必要があります。
そこで、今回データ参照先として、BigQueryを採用しました。みてねではBI
みてねのRDBやFirebaseのイベントログなどは、BigQueryで構築されたDataLakeに日次で同期され、そこからデータを加工して利用しています。
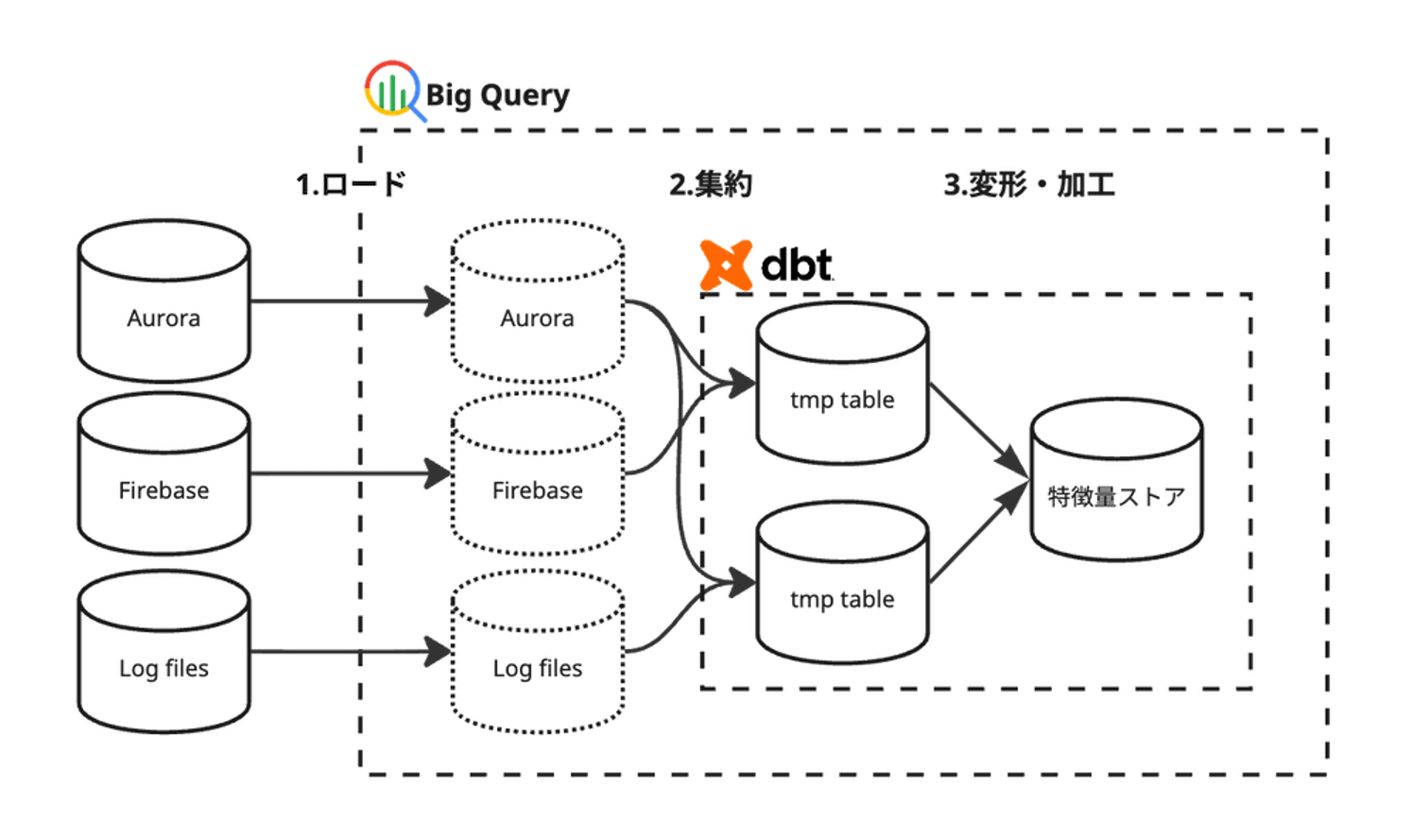
データの整形:ビッグデータの整形の難しさ
BigQueryにあるデータを整形し、モデルが効率的に学習・
一般的には、以下の2つのアプローチが考えられます:
-
BigQuery上での処理:クエリやその結果をView
(またはテーブル) として保存し、再現性を確保する方法 -
Python側での処理:BigQueryから特徴量をCSV等でエクスポートし、pandasやpolarsライブラリを使って結合・
整形する方法
しかし、メディアのメタデータや画像解析情報は膨大なレコード数があり、BigQueryにも大きな負荷がかかります。また、メディア情報、家族情報、イベントログなどさまざまなソースからデータを取得するため、クエリが複雑化し、メンテナンス性が著しく低下していました。全データをダウンロードする場合も、データ量が膨大となり、それらを一時保存してPythonで処理することは現実的ではありませんでした。
データの整形:DBTの導入
そこで、データセット作成にはdbt
MLレコメンドにdbtを選択した主な理由
-
データ変換処理をコードとして管理できるため、バージョン管理やCI/
CDとの連携が容易 -
テストやドキュメント生成機能が組み込まれており、データ品質の担保とナレッジ共有、データドリフトの検知が効率的に行える
-
汎用的な中間テーブルを作成・
キャッシュすることで、無駄な集計を避け、他のデータモデルとも共有でき、効率化が図れる -
将来的な特徴量追加が容易に実施できる
導入による効果
- 特徴量エンジニアリングのプロセスが標準化され、再現性の高いデータセット作成が実現
- メディア特徴量の集計処理を事前に実行することで、ML推論時の処理負荷を大幅に軽減
- データの依存関係が明確になり、新しい特徴量の追加やデータ更新がスムーズに
②S3を利用したスケーラブルなストレージ活用
写真プリント自動提案システムでは、ML推論結果および提案データの保存先としてS3を活用し、スケーラブルな基盤を構築しています。
将来的にユーザ数が5倍10倍になっても耐えられるような並列分散システムを目指しています。
RDB負荷対策
みてねのRDB
一方で自動提案データの性質を考えてみると、更新されることもなく、壊れても作り直せるような性質のデータであることから、なるべくS3にオフロードさせるのはRDBの負荷軽減に貢献すると判断して現在に至ります。
並列処理との親和性
「生成速度は速いほど良い」
一方でS3では高並列なWrite処理でも(ほぼ)無限の性能をもつため、どんなに並列書き込みしても大丈夫であるという安心感から心理的負担から解放されています。
S3を推論結果ストアとして採用することで、ストレージの負荷を意識することなく、並列度を高める運用が可能になります。
データ特性を活かした設計
「静的データである」
また、過去の提案データも長期間保持する必要があるため、データ量を気にせず使えるのは実装・
擬似APIサーバとしてのS3活用
静的データの特性を活かし、参照時にはS3自体を運用不要なAPIサーバのように扱っています。各ユーザへの提案データをJSONファイルとしてS3に格納し、都度必要になった場合に読み込むことで、安定したレスポンスタイム
今後の課題
運用を開始した直後で未整備な部分がまだ残っており、継続的な改善を実現するために整備していきたいと考えています。
MLモデル改善フローの構築
- MLモデルのアップグレードを容易に試せる環境の構築
- 複数モデル同士をABテストなどで結果検証する環境の構築
生成速度を高める改善
- 高速化することで月次処理ではなく日次処理で提案データのリランキングなどが可能に
最後に
この記事では、みてねData Engineeringグループにおける取り組みの1つとして、写真プリント自動提案の仕組みについてご紹介しました。
Data Engineeringグループでは様々な自動提案データを生成していますが、提案データをS3にストアするアーキテクチャは前例がなく、実験的なスタンスで始め、運用開始から2年ほど経ちますが大きなトラブルもなく稼働しています。
一方、dbtの活用開始は半年程度前ですが、こちらもトラブルなく順調に稼働しており完成度が高いなと感じています。dbtは他のチームメンバが導入を推進し、また他のチームメンバから特徴量ストアとしての活用を設計して頂き、本システムを実現できたことを非常に感謝しています。
みてねData Engineeringグループでは、連載のステッカー自動提案の記事でもご紹介したように、BigQueryの活用やバッチ処理の改善、インフラ構成やパイプラインの最適化、顔検出ロジックの改善など、さまざまな観点からシステムの改善に取り組んでいます。