


Googleは2025年11月18日、最新AIモデル
Gemini 3 ProとGenerative UI
Gemini 3 Proの推論能力や画像や動画、音声といったソースへの理解力、エージェントとしてのコード生成・
Our first release is Gemini 3 Pro, which is rolling out globally starting today.
— Google DeepMind (@GoogleDeepMind) November 18, 2025
It significantly outperforms 2.5 Pro across the board:
🥇 Tops LMArena and WebDev @arena leaderboards
🧠 PhD-level reasoning on Humanity’s Last Exam
📋 Leads long-horizon planning on Vending-Bench 2 pic.twitter. com/ XsAG9RmiEi
Gemini 3自体がもっている知識はモデルカードによると2025年1月までのものだが、ツールとして検索も使えるため最新情報へのアクセスもできる。安全性については同社のFrontier Safety Frameworkや評価に加え、外部の専門家・
Gemini 3 Proを使うときには、入力プロンプトは明確で簡潔にすることが望ましく
また、ユーザーのプロンプトに応じた画面構成やUIインタラクションをコードとして生成する能力を高めるために、Googleはツールアクセス・
Geminiアプリでの利用
Geminiアプリでは、Gemini 3 Proプレビューがすでに提供開始されている
モデルの選択は
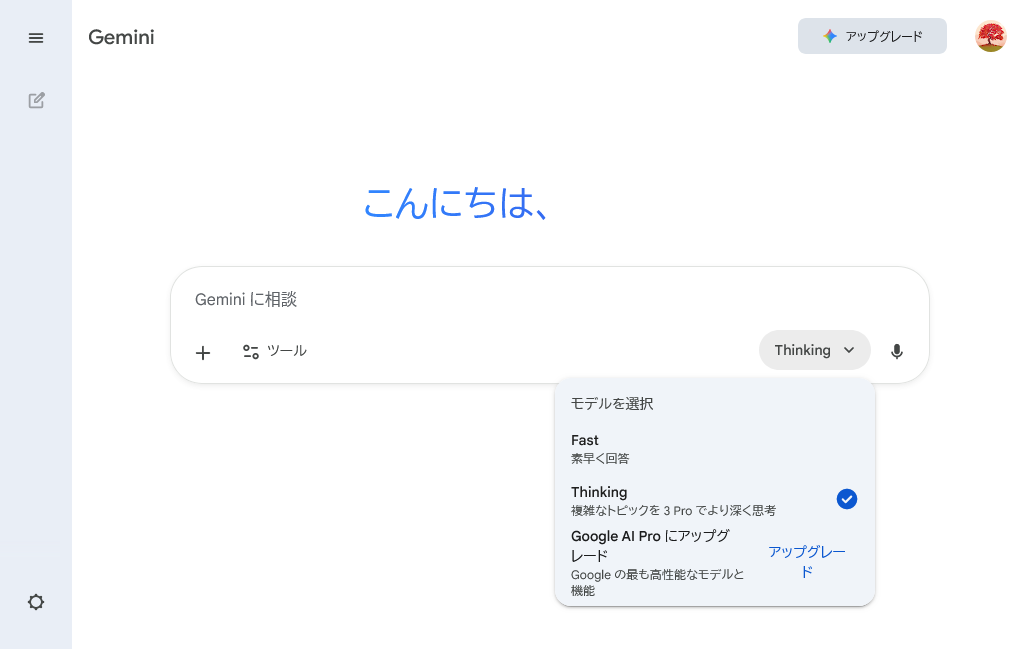
Fastはスピードを重視して設計された強力で効率的な主力モデルと説明されているが、具体的なモデル名の言及がされていない。なお、Google AIプラン
2/ Gemini 3 advances multimodal reasoning by combining state-of-the-art reasoning with vision and spatial understanding
— Sundar Pichai (@sundarpichai) November 18, 2025
So it can analyze your long-form sports videos to give you a performance audit, identifying specific technical issues and providing the exact drills to fix… pic.twitter. com/ IHvy5sHKVc
Geminiアプリの回答において、Generative UIを使ったジェネレーティブインターフェース
4/ Visual layout moves beyond text with an immersive, magazine-style view (photos + modules) that you can interact with to further customize your response.
— Sundar Pichai (@sundarpichai) November 18, 2025
Ask it to “plan a 3-day trip to Rome” and you get an explorable itinerary tailored to your preferences👇🏻 pic.twitter. com/ pSJ3z9lNvQ
In dynamic view, Gemini designs and codes a custom user interface in real-time, perfectly suited to your prompt. In our evaluation, raters strongly preferred dynamic view’s personalized assets over standard LLM output. pic.
— Google Research (@GoogleResearch) November 18, 2025twitter. com/ 0HNB6CVAEW
米国のGoogle AI Ultra加入者向けには、Geminiアプリで
5/ We're introducing Gemini Agent: It uses Gemini 3's advanced reasoning to break down complex tasks, like booking local services or organizing your inbox, into actionable steps.
— Sundar Pichai (@sundarpichai) November 18, 2025
It can then propose actions like drafting your replies or archiving emails, all using deeper… pic.twitter. com/ MELURXImWd
Google WorkspaceにおけるGemini 3についてはGoogle Workspace Updatesを、Gemini Enterpriseについてはそのリリースノートを参照のこと。
Google検索のAIモード
Google検索のAIモードにGemini 3が統合され、米国のGoogle AI Pro/
Gemini 3の推論能力を用いることで、1回の質問を内部で複数のサブトピックに分解し、それぞれに関連する検索を並列におこなう
Thinkingを選択した際、Gemini 3とともにGenerative UIが使われるため、回答によっては画像などが組み込まれたレイアウトやインタラクティブなツールの埋め込みがおこなわれるようになる。
AI Mode in Search dynamically creates the ideal visual layout for responses, tailored to your query. When the model detects that an interactive tool will help you better understand the topic, it uses its generative UI capabilities to code a custom simulation or tool in real time… pic.
— Google Research (@GoogleResearch) November 18, 2025twitter. com/ IdJafAZ2nh
さらに米国のGoogle AI Pro/
Gemini API、Gemini CLI、開発環境
Gemini 3 Proプレビューのコーディングの能力は、Genmini 2.
Gemini CLIでは現在、Google AI Ultraプランユーザーと有料のGemini APIキー契約者がGemini 3 Proプレビューを利用できる。
AI StudioやAndroid StudioでもGemini 3 Proプレビューが利用可能になっている。それぞれ無料のデフォルト枠が設けられている。またFirebaseでは、AI Logic client SDKを通じてGemini 3を利用できるようになった。BlazeプランであればGemini API経由でGemini 3 Proプレビューに直接アクセスできる。
Gemini 3とは直接は関係しないが、GeminiアプリのビジュアルレイアウトにFlutterが活用されたことから、これに触発されてFlutter向けのGenUI SDKを開発したことが報告されている。このGenUI SDKは、GoogleのA2AチームとGoogle LabsのOpalチームとの協力のもと、近々リリース予定のA2UIプロトコルをベースに構築されているという。これを使うことでGeminiアプリのビジュアルレイアウトと同じような動的でインタラクティブな生成が可能になる。
Google Antigravity
GoogleはGemini 3の発表にあわせて、Agentic development platformとして新しいIDE
Meet Google Antigravity, your new agentic development platform.
— Google Antigravity (@antigravity) November 18, 2025
An evolution of the IDE, it's built to help you:
- Orchestrate agents operating at a higher, task-oriented level
- Run parallel tasks with agents across workspaces
- Build anything with Gemini 3 Pro. pic.twitter. com/ GCwHVJSU1O
Antigravityは、複数のワークスペースで動作するエージェントをまとめて扱えるようにし、開発者が
またエージェントは、エディタ/
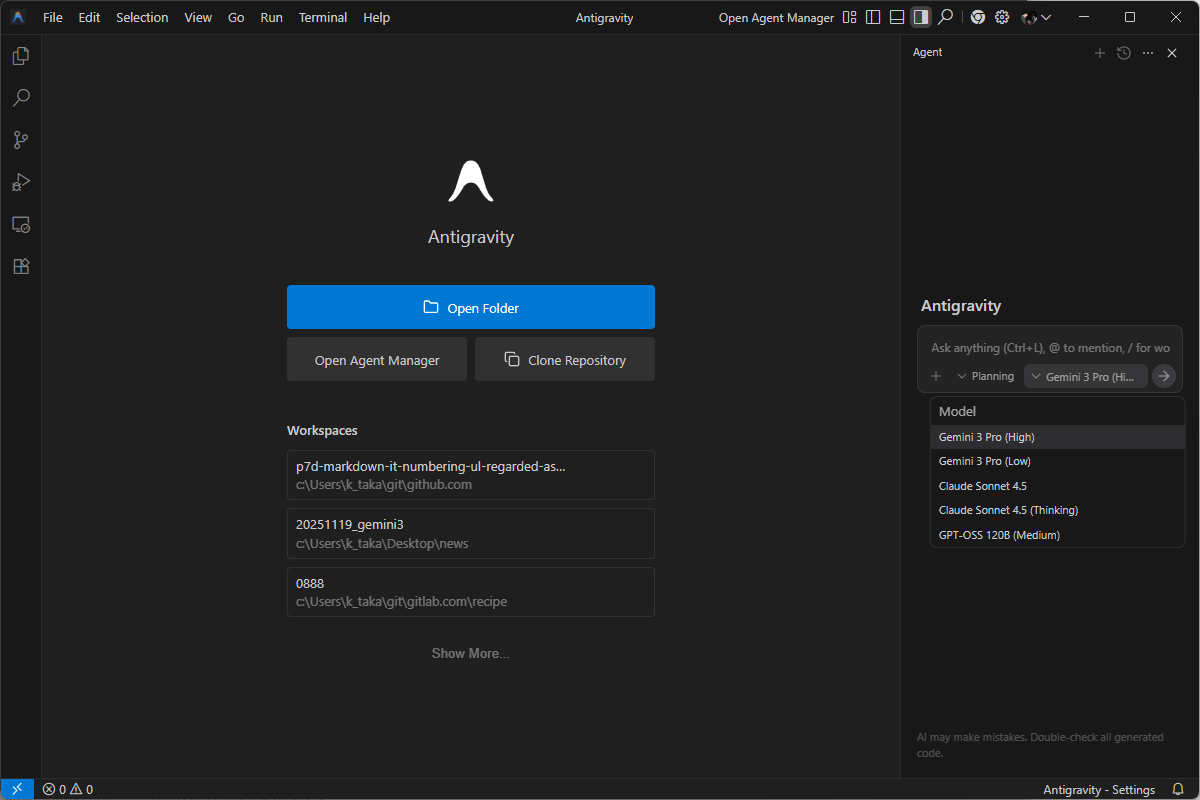
Google Antigravityの利用にはGoogleアカウントが必要で