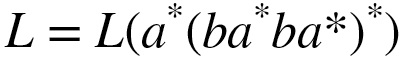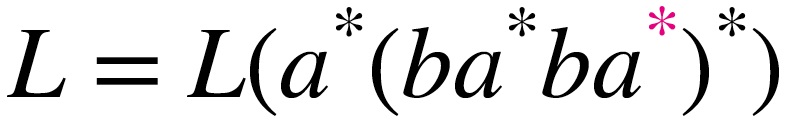補足情報
(2015年11月5日更新)
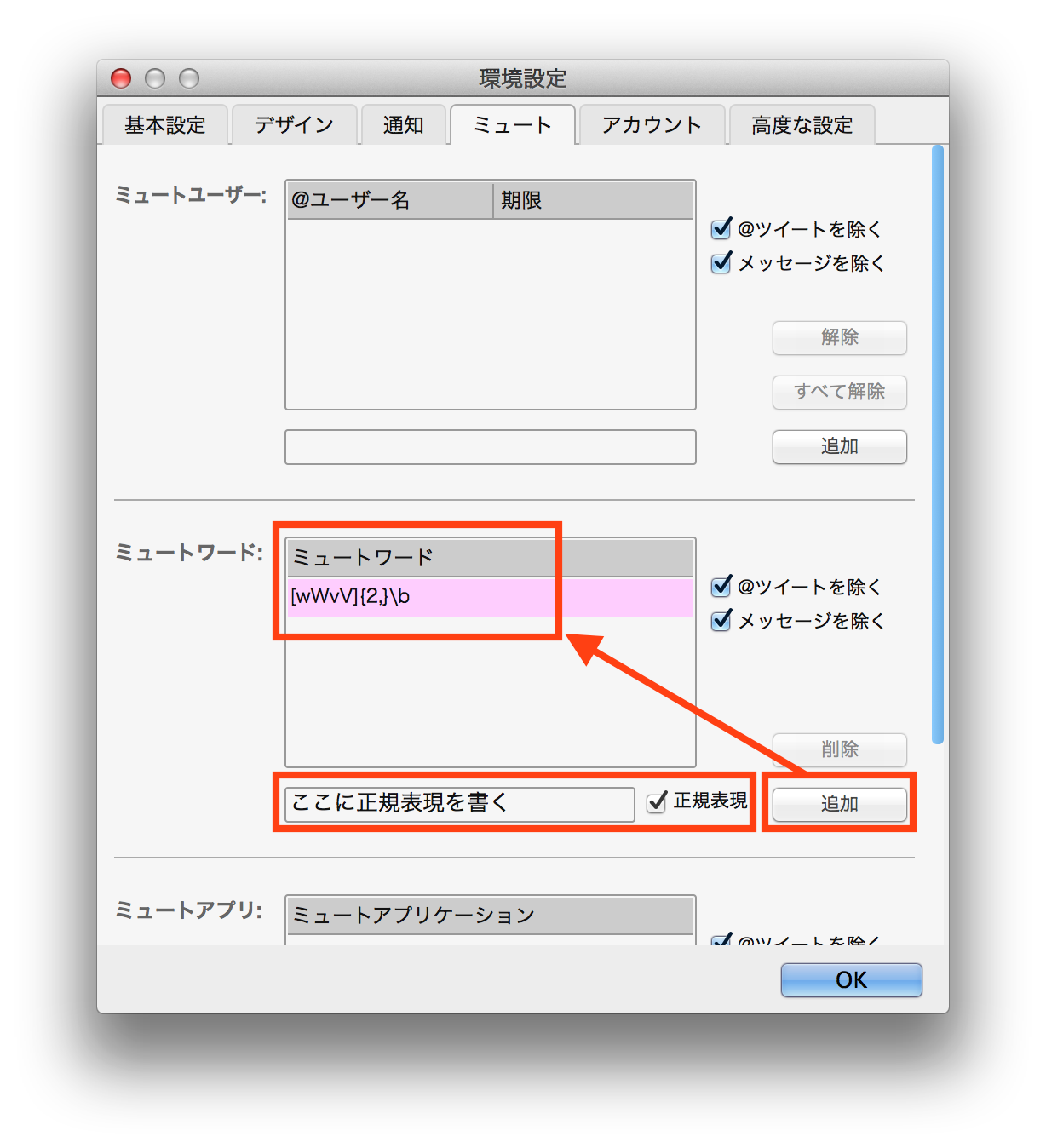
P.14 図1.4の補足
図1.4では、Twitterクライアントの正規表現によるフィルタリングの設定の様子を紹介しています。
画像をクリックすると大きく表示できます。
URL情報の更新(電子版では、以下のURLは更新済み)
P.70 注7
P.196 注e
P.196 注q
P.329 [18]
お詫びと訂正(正誤表)
本書の以下の部分に誤りがありました。ここに訂正するとともに、ご迷惑をおかけしたことを深くお詫び申し上げます。
(2019年10月16日最終更新)
P.32 本文上から3段落め
誤
たとえばPythonやJavaScriptの標準の正規表現では前方一致にmatchメソッドを
正
たとえばPythonの標準 の正規表現では前方一致にmatchメソッドを
JavaScriptのmatchメソッドは部分一致。
P.294 下から2段落め内
誤
正
P.297 上から4行め
誤
正
(以下、2017年8月31日に更新)
P.128 下方から始まるリスト
誤
# statesは状態の集合、deltaは文字と状態集合の辞書(遷移関数)
def expand(states, delta):
modified = true
while modified:
modified = false
for q in states:
if not states > delta[(q, EPSILON)]:
# 新しい状態にε遷移する場合は変更フラグを立てる
states |= delta[(q, EPSILON)]
modified = true
return states
正
# statesは状態の集合、deltaは文字と状態集合の辞書(遷移関数)
def expand(states, delta):
modified = T rue
while modified:
modified = F alse
for q in states:
if not states >= delta[(q, EPSILON)]:
# 新しい状態にε遷移する場合は変更フラグを立てる
states |= delta[(q, EPSILON)]
modified = true
return states
(以下、2017年8月22日更新)
P.126 上から12行め
誤
最後に、qsからfsにε遷移を追加します。
正
最後に、f sからq sにε遷移を追加します。
(以下、2016年2月15日更新)
P.42 半ほど 見出し「控え目な量指定子の活用例」の上、5行め
誤
(控え目な)希望が優先され、左側のサブパターンに
正
(控え目な)希望が優先され、右 側のサブパターンに
以下、電子版では更新済み。
現
新
P.97 表3.2 5行め
P.104 ページ上部、1つめのリスト 2行めと5行め
誤
$day = '14/11/1988';
if ($day =~ /( (\d{2})\/(\d{2})\/(\d{4})) /) {
print "$3 年 $2 月 $1 日";
}
#=> 11 年 14 月 14/11/1988 日
正
$day = '14/11/1988';
if ($day =~ /(\d{2})\/(\d{2})\/(\d{4})/) {
print "$3 年 $2 月 $1 日";
}
#=> 1988 年 11 月 14 日
P.104 ページ下方、黒丸数字付きの箇条書き1行め
誤
➊ ( (\d{2})\/(\d{2})\/(\d{4}))
正
➊ (\d{2})\/(\d{2})\/(\d{4})
P.104 ページ下方、3つめのリスト 2-3行め
誤
/
(\d{2}) # 日
(\d{2}) # 月
(\d{4}) # 年
/x
正
/
(\d{2})\/ # 日
(\d{2})\/ # 月
(\d{4}) # 年
/x
P.123 下から8行め
誤
ただ一つの初期状態qとただひとつの受理状態fをもつ、ここでpとfは異なる状態
正
ただ一つの初期状態qとただひとつの受理状態fをもつ、ここでq とfは異なる状態
P.179 下から1行めの末尾
誤
(図5.27(2))
正
(図5.11 (2))
P.217 図6.5の#error内
P.241 1行め〜4行め
誤
注意すべきは元の正規表現(¥D+|<¥d+>)*[!?]と強欲化した(¥D++|<¥ d+>)*[!?]は、バックトラックの詳細は異なるものの、正規表現としては同じものである点です。(¥D+|<¥d+>)*[!?]にマッチする文字列は(¥D++|<¥d+>)*[!?]にもマッチしますし、その逆も成り立ちます。
正
強欲化による余分なバックトラックの回避は便利ですが、正規表現の挙動を意図せず変えてしまうことがあります。たとえば強欲化した正規表現(¥D++|<¥d+>)*[!?]は文字列「enjoy?」には完全一致せず、「?」のみにマッチ(部分一致)します。これは元の正規表現(¥D+|<¥d+>)*[!?]の挙動と異なります。
P.241 「自動強欲化」項内の6行め
誤
(サブマッチの意味なども含め)等しい正規表現であることを即座に見抜ける人
正
(サブマッチの意味なども含め)異なる 正規表現であることを即座に見抜ける人
P.244 5行め
誤
のように括弧内の先頭に>? を
正
のように括弧内の先頭に?> を