この連載では、オープンソースの継続的インテグレーション(CI)サーバであるHudsonを利用した、ソフトウェア開発の生産性向上について解説しています。前回 の記事では、Hudson上に継続的ビルドを設定して、ソースコードに加えられた変更をいち早くビルドし、結果を開発者にフィードバックする方法に付いて見てきました。今回は、視野を少し広げて、規模の大きいソフトウェアプロジェクトの開発で、Hudsonを更に有効活用する方法についてみていきます。
テストを有効活用する
実行したテストの結果をHudson上に集計する方法については前回述べました。ビルドと同時にテストもやってしまうという手法は、小さなプロジェクトやライブラリ、もしくはテストの数も少ない場合にはとても有効です。ですが、プロジェクトが大きくなりテストの数が増えるにつれ、テストの実行時間が長くなり、この方法では迅速にフィードバックを得ることが難しくなります。プログラムの変更を加える際には、開発者は暗黙の内に、変更によって得られるメリットと、バグを混入させて混乱を引き起こす可能性とを天秤にかけています。大規模なテストを短時間で実行できれば、小さなメリットしか得られない変更でも着実に拾っていくことができます(リファクタリングなどは特にこのカテゴリに属する変更です) 。これが、中長期的にソフトウェアの品質の確保につながるのです。このため、大規模なソフトウェア開発においてはテストの実行時間を極力短くすることは非常に戦略的な重要性を持っています。テスト自体の書き方・実行の仕方で工夫することが第一ですが、その議論は本稿の範疇を外れるので、ここではHudsonをどのように活用するかを見てみます。
まず第一のステップは、ビルドとテストをHudson上で2つのプロジェクトに分離することです。Hudsonは異なるプロジェクトのビルドは同時並行で行ってくれますから、これによってテストとビルドを同時進行させることが可能になります。この様子はちょうどCPUが命令をパイプライン処理するのに似ています。変更が加えられてからそのテストが完了するまでの時間は同じなのですが、同時に2つを走らせる事でソースコードに変更が加えられてからビルドが開始されるまでの待ち時間を大きくカットできるわけです。
このようにセットアップするためには、ビルド側からテスト側へテストするべきバイナリを送る必要があります。これには永続リンクが大変有効です。すなわち、流れは次の様になります。
ビルド側が完了時にバイナリを保管 「ビルド後の処理」>「成果物を保存」を使います。 ビルドの完了後テストを自動的に開始 「ビルド後の処理」>「他のプロジェクトのビルド」を使います。 最新のビルド成果物をHudsonから取得 「最新成功ビルドの成果物」のリンクは永続リンクになっているので、これを利用しましょう。 テストを実行
上流・下流ビルド
上記のように、複数のプロジェクトの間に依存関係を設定してあるプロジェクトのビルドが完了した時に他のプロジェクトをビルドさせることができます。このような関係にあるプロジェクトを上流プロジェクト・下流プロジェクト、または上流ビルド・下流ビルドと呼びます。テストだけに限らず、Hudson上により多くの作業を移すにつれ、1つの巨大ジョブで全ての作業をやろうとすると1サイクルの実行時間が長くなりすぎてCIのメリットが薄れてきます。このような場合に、作業をいくつかのジョブに分解しそれらの間に依存関係を適切に設定することで、この問題を解決できます。
一方、複雑な依存関係を設定する場合には幾つか必要な注意もあります。まず、上流ビルドが完了した時に実際に行われている事は、下流プロジェクトに対する新規ビルドのリクエストだということです(これはちょうど「ビルド実行」リンクをクリックするのと同じです) 。この時、下流のプロジェクトのビルドが既に待ち行列に入っていれば新しいリクエストは単にこれに吸収されます。なので、一般的には(特に下流ビルドが上流ビルドより長い時間を要する場合には) 、上流ビルドと下流ビルドは一対一には対応しないことがあります。また、A→B,B→D,A→C,C→Dといったようなダイヤモンド依存関係がある時も、Bと Cの変更はDを個別にリクエストするので、従ってAのビルドが最終的には2つのDのビルドを生じる、というような事があります。
こういった問題を解決してより賢い依存関係を処理するという議論は、devリストで頻繁に行われていますが、残念ながら現時点では特に具体的な案はありません。
ファイル指紋を記録
こうして互いに依存する多くのプロジェクトを使い、1つのプロジェクトで作ったバイナリを他のプロジェクトで利用していると、どのビルドで作られたバイナリがどこでテストされているかをきちんと追跡することが重要になってきます。例えば、テストプロジェクトの#50でリグレッションが発見されたとしましょう。このテストがテストしたバイナリのビルド番号がわからなければ、どの変更が原因でこの問題が発生したのかをきちんと追跡できません。
この問題は、中間に入るプロジェクトの数が多くなるにつれて深刻化します。例えば、何とかテストの失敗はビルド#100に起因するとあたりをつけたとしましょう。さて、このビルド#100での変更は、社内の共通ライブラリを新しいビルドに更新したことによるビルドだったとします。となると、このテストの失敗の原因を特定の変更に結びつけるには、今度はこのライブラリに加えられた変更を追わなくてはいけません。このような作業は、正確に行うのは人間には向いていない作業です。
Hudsonにはこれを正確に行うために「ファイル指紋」という概念があります。ビルドの終了後、Hudsonは指定されたファイルのMD5チェックサムを計算し、そのファイルがビルドに登場したことを記録しておきます(さらにタイムスタンプを見ることで、ファイルがビルドによって作られたのか外部から持ち込まれたのかを推定します) 。これをビルド側とテスト側と両方で行うと、どのビルドで作られたバイナリがどのテストで利用されているのかの正確な情報がHudsonに蓄積され、この情報がUI上に色々な形で表示されるようになります。この仕組みは、ビルのあちこちに監視カメラを設置するのに似ています。ある人がビルの中をうろうろしていると、どのカメラに何時にその人が登場するのかを比較する事で、行動の様子に付いて多くの知識が得られます。これをビルドの成果物に大して行うのがファイル指紋の追跡です。
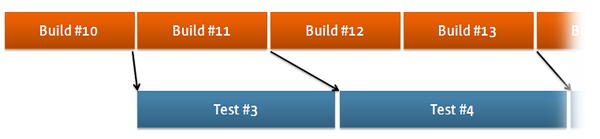
この機能の設定は「ビルド後の処理」>「ファイル指紋を記録」で行います。ビルド側では単に成果物の指紋を記録しておけばよいだけなので、テキストフィールドは無視して「保存された成果物の指紋を記録」をチェックしましょう。テスト側では、ダウンロードしたビルドの指紋を記録するので、テキストフィールドを使ってダウンロード先を指定します。このように設定しておくと、ビルドやテストを見ている時に、お互いの対応関係が下図のように表示されます。
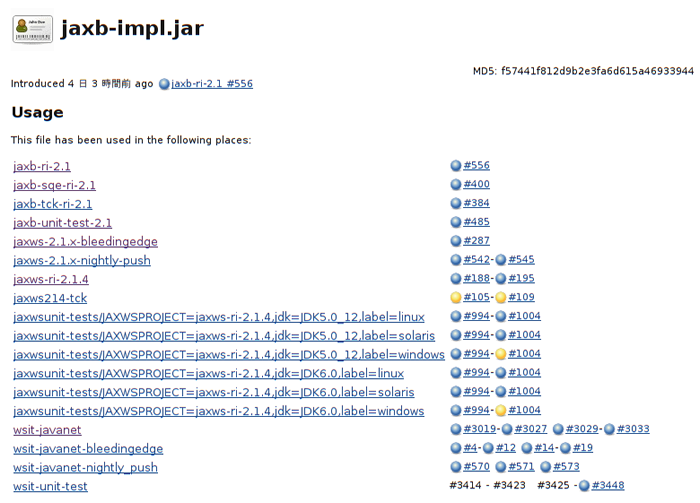
また、ファイルの右脇のアイコン(をクリックして、そのファイルがどこで使われているかの一覧を表示させる事もできます。下図の例では、JAXB RIがライブラリとしてJAX-WS RIとWSITで使われているのですが、JAXB RIビルド#556がJAX-WS RI及びWSITのどのビルドで利用されているのか表示されています。
さらに、ビルドページの左側から「指紋を見る」を選べば、このビルドで指紋が記録されたファイルの一覧と、それらに出自が表示されます。
例えば、この例では同じくJAXB RIビルド#556で使われているライブラリの出自などがわかります。
このようなトラッキングを利用することで、問題が見付かった時に原因をするのが容易になります。例えばこのJAXB RIのビルドでライブラリzephyrに関係ありそうなバグが見付かった時、この記録をみて、ああ、zephyrのビルドは#154だけれども、 zephyr #160でどうもこの問題は修正されているようだからzephyrチームに連絡する前に最新版に変更してみよう、などと判断することができます。あるいは、テストで新しいリグレッションが見付かった時に何か依存関係に変更はあったか調べることも出来ます。
テストの分割
先に、1サイクルの時間を短縮することがとても重要であるという話をしました。そこで、テストの見かけの実行時間をさらに短縮するために、ビルド・テストと2つに分けるだけでなく、テスト自体を複数のジョブに分割するようにしましょう。
例えば、筆者の職場では、開発チームが作ったテストを(実際にはユニットテストでなくても)ユニットテスト、テストチームが作ったテストをSQEテスト、 JCP規格との互換性をテストするのがTCKテスト、といった具合に、1つの製品に対して幾つかの全く異なったテストセットが存在することが普通です。このような場合には、これらのテストをそれぞれ別々のジョブとしてセットアップすれば、これらが全て同時並行に実行されるので、見かけのテスト時間が短縮されます。
また、テストがある程度以上の規模になると、1つのテストセットがより小さいテスト群から構成されているのも普通かと思います。このような場合にも、テスト群を全て連続して一気通貫に実行するのでは無くて、個別に実行することで並列度を増すことができます。また、同一のテストを複数の条件下(例えばサポートしているデータベースそれぞれで、あるいは対応しているJDKバージョンそれぞれで、など)でテストする場合も、分割が容易です。このようにしてテストを分解して実行する場合は、フリースタイルプロジェクトを使うと、ほとんど似たりよったりのプロジェクトが沢山できてしまって管理が面倒になるので、このような状況に特化したマルチ構成プロジェクトを使うと便利です。マルチ構成プロジェクトの詳細については連載の後の方で解説する予定です。
テスト結果の集計
実行時間の向上のためにテストを分割すると、今度はテスト結果が複数のジョブに散らばってしまって、結果を一覧するのが大変になります。こうした場合向けに、Hudsonには下流のプロジェクトのテスト結果を自動的に集計する機能があります。上流・下流プロジェクトの関係が既に構築されていて、ファイル指紋のトラッキングが既に行われていれば、これは設定画面から「下流プロジェクトのテスト結果を集約する」を選ぶだけです。
分散ビルド
Hudsonの利用が進み、多くのビルドやテストがHudsonに移ると、一台のコンピュータで全てのビルドを賄うのは困難になります。実際、ビルドもテストもCPUやI/O帯域をごっそり消費するので、数個のアクティブなビルドがHudson上に存在するだけでこの問題は顕著になってきます。ビルドの待ち時間が伸びるとCIの効果は薄れますし、所詮一台のコンピュータができることはたかがしれています。この問題を解決するために、Hudsonはビルドを複数のコンピュータに分散させる機能を持っています。これによって、ジョブの数が増えても大きな性能低下を招かずにビルドの実行が行えます。
Hudsonの分散ビルドの仕組みはマスター・スレーブ方式です。hudson.warのウェブアプリケーション自身がマスターとなり、HTTPリクエストのハンドリング、データの保存、及びスレーブの管理を行います。マスターは1台だけで、また大規模なHudsonではHTTPリクエスト処理だけでそれなりのパワーが必要になりますから、一番良いコンピュータを割り当てましょう。一方、スレーブは、マスターの指示によってビルドを行うだけの存在です。ビルド自体に必要な計算機資源の他には特に必要なものはありません。筆者の職場では、同僚達の使っていないコンピュータや廃品回収されたPentium4 PCを中心にスレーブ30台以上のクラスタが、Sun Blade 2500 のマスターに接続されて稼働しています。
Hudsonはスレーブを制御するために「スレーブエージェント」という小さなプログラムをスレーブ上で走らせる必要があります。このプログラムは、配備・更新が簡単なように100K弱の小さなjarファイル1つにまとめられています。起動方法によって厳密な仕組みは異なりますが、何らかの方法でマスターと双方向の通信チャンネルを確立すればOKで、スレーブエージェントは残りのプログラムをon-demandでマスターからダウンロードして処理を進めます。
スレーブ起動方式
スレーブがマスターとの接続を確立するには主に2つの方式があります。
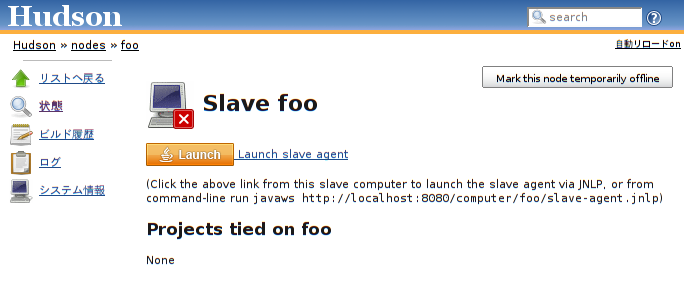
マスターがスレーブエージェントを起動する方法: これが通信チャンネルになります。この方法はsshなど既存のリモートログインメカニズムが必要ですが、スレーブ側で別途デーモンプロセスを管理する必要がない点が優れています。sshが標準で入っているUnixシステム向けの方法です。 Java Web Startを使ってスレーブエージェントを起動する方法: 下図のようにボタンをクリックしてスレーブエージェントを起動します。この仕組みはJava Web Startを利用していて、マスターとの間にTCPソケットを使った通信路を確立します。この方法はsshのような仕組みが必要ありませんが、GUIが必要です。また、自動的にスレーブエージェントを起動させるためには、オートログインとスタートアップグループなどを組み合わせてプログラムが自動的にスタートするようにする必要があります。
そもそもは前者がUnixシステム/大規模Hudson向け、後者がWindowsシステム/小規模Hudson向けに作られているのですが、 Cygwinを使ってWindows上にsshをインストールしたり、Java Web StartをUnixデーモン/Windowsサービスとして起動する仕組みが開発されたりと、現在では様々な形態で運用することが出来るようになっています。
スレーブを追加してみる
それでは、実際にスレーブを一つ追加してみましょう。ここでは、Windows/Unix共に利用可能な、sshを利用した方法を紹介します。繰り返しますが、ここで解説する形態以外で運用することも出来るので、ここで触れるのは一つの方法に過ぎません。
まず、マスターとなるコンピュータ上に「hudson」ユーザーを作成しましょう。Hudsonに専用のユーザーIDを割り当てることで、複数の人間がHudsonの管理者として作業するのが簡単になりますし、ビルド中に間違って生成されたファイルや、綺麗にシャットダウンされなかったデーモンプロセスをkillするのも簡単になります。
このユーザーIDを使って、Hudsonを起動しましょう。Hudsonはスーパーユーザーではないのでそのままでは80番ポートでは動作できませんが、AJPやmod_proxyを使ってapacheと接続することで、この問題を解決することができます。
スレーブとなるコンピュータを選び、このコンピュータ上にも「hudson」ユーザーを作成しましょう。この時、管理を簡単にするために、ホームディレクトリの位置を「/home/hudson」なり「/export/home/hudson」なり、マスターと同じものを選びます。また、ビルドはファイルアクセスが多いので、ホームディレクトリがNFSではなくローカルディスク上に配置されるようにしましょう。
sshの公開鍵認証を設定し、マスター上のhudsonユーザーがスレーブ上のhudsonユーザーにパスワードなしでログインできるようにしましょう。公開鍵認証の詳細は本稿の範囲を越えますが、インターネット上に沢山のリソースがあるので、それらを参考にしてください。
hudson.war内に含まれているslave.jarを取り出して、スレーブ上に配置します。
マスターのシステム設定画面に移動し「スレーブ」セクションに新しいスレーブを追加します(下図参照) 。ここでは、最大同時ビルド数を2にして、データファイルがHudsonのホームディレクトリ上に展開されるようにしてあります。
設定を更新してしばらくすると、スレーブがオンライン状態になるはずです。これで準備が完了です。もしオンラインにならなければ画面左の「ビルド実行状態」からスレーブへのリンクをクリックして、ログを確認してエラーの状況を調べます。
この状態で同時に沢山のビルドが必要になると、Hudsonは自動的にスレーブを活用し始めます。この調子で、任意の数のスレーブをセットアップする事ができます。スレーブの数が増えて、ビルドやテストのために、異なる環境のスレーブを用意する場合、新しいスレーブの追加や古いスレーブの廃棄に対応しやすくするために、スレーブに「windows」「 linux」などのようなラベルを割り当てましょう。ジョブはラベルに依存させ、個別スレーブへの依存を避けるようにすれば、クラスタの管理が容易になります。
おわりに
Hudsonには、開発チームを跨ってより多くの人々に使われるようになった時に真価を発揮する機能がたくさんあります。連載3回目の今回は、こうした機能に着目して、ファイル指紋によるトラッキングや、分散ビルドを使った大規模なHudsonの運用について簡単に紹介しました。次回は、主だったプラグインのいくつかを紹介します。





 )
)