本連載では、
しかし、
RIAで特に重要となるのが、
このような通信はローカルのアプリケーションに比べると多大な時間が必要です。そのため、
JavaFXはAWTやSwingと同じようにイベント駆動でアプリケーションが動作します。通常は、
たとえば、
なお、
HTTPを用いたドキュメントの取得
まずはじめに単純にリモートにあるドキュメントを非同期に取得してみましょう。とはいうものの、
プロトコルにHTTPを使用した、
次に簡単なRemoteTextDocumentクラスを使ったサンプルを示します。
var document: String;
var remoteText = RemoteTextDocument {
// ドキュメントのURL
url: "http://gihyo.jp/dev/serial/01/javafx"
// HTTPのメソッド
method: "GET"
// 取得したドキュメント
document: bind document with inverse
// ドキュメントを取得した後にコールされるコールバック関数
onDone: function(result: Boolean) {
println("DONE");
// onDoneがコールされた後、documentにアクセスできる
println(document);
}
}
Stage {
title : "Dummy"
scene: Scene {
width: 200
height: 200
content: [ ]
}
}RemoteTextDocumentクラスのurlアトリビュートがリモートにあるドキュメントのURLを表します。ここでは、
同様に、
RemoteTextDocumentクラスはオブジェクトを生成すると非同期にドキュメントを取得しにいきます。ドキュメントの取得は非同期に行われるため、
ドキュメントの取得が完了すると、
なお、
では、
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title>騾」霈会シ壹▽縺?↓繝吶?繝ォ繧定┳縺?□JavaFX?徃ihyo.jp 窶ヲ 謚?。楢ゥ戊ォ也、セ</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<<以下、省略>>
なんと、
そこで、
HttpRequestクラスを使用した通信
javafx.
では、
ar charset: String;
var request: HttpRequest;
request = HttpRequest {
location: "http://gihyo.jp/dev/serial/01/javafx"
onResponseHeaders: function(headerNames: String[]) {
for (headerName in headerNames) {
if (headerName == "content-type") {
// HTTPヘッダの content-type から文字コードを取得
var contentType
= request.getResponseHeaderValue(headerName);
var index = contentType.indexOf("=");
charset = contentType.substring(index+1);
}
}
}
onInput: function(stream: InputStream) {
var reader: BufferedReader;
if (charset != null) {
// 文字セットを指定してリーダを生成
reader = new BufferedReader(
new InputStreamReader(stream, charset));
} else {
reader = new BufferedReader(
new InputStreamReader(stream));
}
while(true) {
var text = reader.readLine();
if (text == null) {
break;
}
println(text);
}
stream.close();
}
}
// リクエストをキューに入れる
request.enqueue();
Stage {
title: "Dummy"
scene: Scene {
width: 200
height: 200
content: [ ]
}
}RemoteTextDocumentクラスを使ったサンプルよりもずいぶん長くなってしまいました。
HttpRequestクラスでは接続するサーバのURLはlocationアトリビュートで設定します。ここでは、
HttpRequestクラスではonXというアトリビュートが多く定義されています。X の部分にはConnectingやReadingなどHTTPの状態を表した言葉が入ります。これらのアトリビュートには、
上記のスクリプトでは、
onResponseHeadersアトリビュートでは引数としてヘッダの名前の一覧が与えられます。もし、
次にonInputアトリビュートでボディの読み込みを行います。onInputアトリビュートでは引数としてInputStreamオブジェクトが与えられます。そこで、
後は、
なお、
では、
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title>連載:ついにベールを脱いだJavaFX|gihyo.jp … 技術評論社</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<<以下、省略>>
RemoteTextDocumentクラスを使った場合と異なり、
パーサを使って解析
今までのサンプルでドキュメントを取得できることがわかりました。しかし、
そこで、
FlickrのAtomはリスト3のようになっています。
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:flickr="urn:flickr:"
xmlns:media="http://search.yahoo.com/mrss/">
<title>Uploads from yuichi.sakuraba</title>
<<省略>>
<entry>
<title>Entremet Montebello, Pierre Hermé, Nihonbashi Mitsukoshi</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/skrb/3224086417/"/>
<id>tag:flickr.com,2005:/photo/3224086417</id>
<published>2009-01-25T07:08:47Z</published>
<updated>2009-01-25T07:08:47Z</updated>
<dc:date.Taken>2008-12-22T20:39:03-08:00</dc:date.Taken>
<content type="html"> ... <img src="http://farm4.static.flickr.com/3531/3224086417_896092041b_m.jpg" ... </content>
<<省略>>
</entry>
<<省略>>
</feed><feed>タグの中に複数の<entry>タグがあり、
ここでは、
以下にAtomの読み込みとパースを行うAtomReaderクラスのAtom読み込み部分を示します。
public class AtomReader {
public-init var url: String;
public function read(): Void {
var request = HttpRequest {
location: url
// 入力の解析はparse関数で行う
onInput: parse
// エラー処理
onException: function(ex: Exception) {
println("exception: {ex.getMessage()}");
}
};
request.enqueue();
}read関数では、
では、
// 処理が終了した後にコールするコールバック関数
public var onDone: function(:PhotoInfo[]): Void;
// サムネイルのURLを取り出すための正規表現
def pattern = java.util.regex.Pattern.compile("http://farm.*_m.jpg");
// Atomのパース
function parse(stream: InputStream) {
var infos: PhotoInfo[];
var info: PhotoInfo;
var inEntry: Boolean;
var parser = PullParser {
documentType: PullParser.XML;
input: stream
onEvent: function(event: Event) {
if (event.type == PullParser.START_ELEMENT) {
if (event.qname.name == "entry") {
// <entry>の開始
// 新たなPhotoInfoオブジェクトを生成する
inEntry = true;
info = PhotoInfo {};
}
}
if (event.type == PullParser.END_ELEMENT) {
if (event.qname.name == "entry") {
// </entry>の場合
// 作成したPhotoInfoオブジェクトをシーケンスに追加
inEntry = false;
insert info into infos;
} else if (inEntry and event.qname.name == "title") {
// </title>の場合
// PhotoInfoオブジェクトのtitleを設定
info.title = event.text;
} else if (inEntry and event.qname.name == "content") {
// </content>の場合
// 正規表現を用いて、サムネイルのURLを取り出し、
// PhotoInfoオブジェクトのthumbnailUrlに設定
var matcher = pattern.matcher(event.text);
if (matcher.find()) {
var url = matcher.group();
info.thumbnailUrl = url.replaceAll("_m", "_t");
}
}
}
}
}
// パースの開始
parser.parse();
if (onDone != null) {
// パースが終了したら、コールバック関数をコールする
onDone(infos);
}
stream.close();
}PullParserクラスはイベント駆動型のパーサで、
PullServerオブジェクトがパースするドキュメントの種類はdocumentTypeアトリビュートで指定します。ここには、
パース時のイベントはonEventアトリビュートに設定した関数で行われます。引数としてjavafx.
ここでは、
そして、
ここで取得できるURLはhttp://
_mの場合イメージの長辺が240ピクセルと少し大きいので、
<entry>要素のEND_
パースが終了したら、
では、
// リストで表示する項目
var items: SwingListItem[];
var rssReader = AtomReader {
url: "http://api.flickr.com/services/feeds/photos_public.gne?id=57085156@N00&lang=en-us&format=atom"
onDone: function(infos: PhotoInfo[]) {
// パースが終了したら、HTMLでリストの項目を表示する
for (info in infos) {
var item = SwingListItem {
text: "<html><p>{info.title}</p><img src='{info.thumbnailUrl}' /></html>"
}
insert item into items;
}
}
}
rssReader.read();
Stage {
title: "FlickrAtomReader"
scene: Scene {
width: 400
height: 600
content: [
// リストをスクロールペインで表示する
SwingScrollPane {
width: 400
height: 600
view: SwingList {
items: bind items
}
}
]
}
}ここではjavafx.
なお、
実行結果を図3に示します。
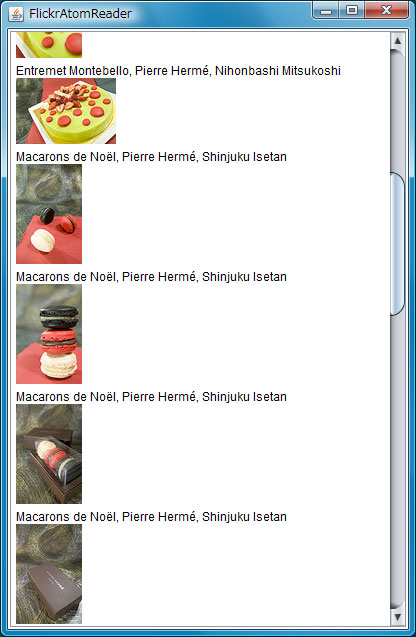
ここではAtomを題材にしましたが、
なお、
このため、
このようにHttpRequestクラスは、
実をいうと、
FlickrAtomViewerではSwingWorkerクラスを使用して非同期にパース処理やサムネイルイメージのロードを行っています。スクリプトの解説は行いませんが、
なお、
- rt15.
jarを入れ替える - profileの設定を変更する
rt15.
はじめの方法は、
後者の方法は、
JavaFX SDKをインストールしたディレクトにprofilesというディレクトリがあります。そのディレクトリの中にあるdesktop.
このファイルの中に以下に示したとおりcompile_
compile_bootclasspath="${javafx_home}/lib/shared/javafxc.jar;${javafx_home}/lib/shared/javafxrt.jar;${javafx_home}/lib/desktop/rt15.jar"この行の最後の${javafx_
これはJava SE 6u12の場合ですが、
もう1つの非同期処理用クラス
RemoteTextDocumentクラスもHttpRequestクラスも通信を非同期に行うためのクラスでした。では、
非同期に処理を行うには、
AbstractAsyncOperationクラスは名前からもわかるようにアブストラクトクラスなので、
AbstractAsyncOperationクラスは、
Java側ではcom.
JavaのAbstractAsyncOperationクラスはConcurrency Utilitiesに含まれるCallableインターフェースを実装しています。しかし、
Javaで非同期処理を行う場合、
そのため、
あまり意味はないのですが、
public class LongLongTaskImpl extends AbstractAsyncOperation<Date> {
public LongLongTaskImpl(AsyncOperationListener<Date> listener) {
super(listener);
}
// 非同期にコールされるメソッド
@Override
public Date call() {
try {
// 10秒スリープ
Thread.sleep(10000L);
} catch (InterruptedException ex) {
// 非同期処理のキャンセルが行われると、
// InterruptedException例外が発生する
// このため、InterruptedException例外が発生した時に
// 速やかにcallメソッドを抜け出る必要がある
}
// 現在時刻を返す
return new Date();
}
}LongLongTaksImplクラスのコンストラクタの引数であるAsyncOperationListenerインターフェースは、
非同期処理はcallメソッドに記述します。callメソッドの戻り値はクラス定義のジェネリクスパラメータと同一にします。ここでは、
callメソッドでは10秒間スリープした後、
重要なのはInterruptedException例外の扱いです。非同期処理がキャンセルされた場合、
では、
public class LongLongTask extends AbstractAsyncOperation {
// 非同期処理の結果
public var result: Date;
// 非同期処理を行うJavaクラス
var task: LongLongTaskImpl;
ublic override function start(): Void {
// 非同期処理の開始
task = new LongLongTaskImpl(listener);
task.start();
}
public override function cancel(): Void {
// 非同期処理のキャンセル
task.cancel();
}
public override function onCompletion(value: Object): Void {
// valueがLongLongTaskImpl#callメソッドの戻り値
result = value as Date
}
}JavaFXのAbstractAsyncOperationクラスはstart関数、
start関数はJavaのAbstractAsyncOperationクラスのサブクラスを生成して、
最後のonCompletion関数は非同期処理が完了した後にコールされるコールバック関数です。onCompletion関数の引数には、
LongLongTaskImplクラスのコンストラクタで指定したAsyncOperationListenerインターフェースは、
非同期処理を開始するのはAbstractAsyncOperationクラスのstartメソッドです。そこで、
キャンセル処理はそのままLongLongTaskImplオブジェクトのcancelメソッドをコールするだけです。onCompletion関数ではcallメソッドの戻り値であるDateオブジェクトをアトリビュートとして保持させています。
このLongLongTaskクラスを使用するスクリプトを以下に示します。
var result: Date = new Date();
Timeline {
repeatCount: Timeline.INDEFINITE
autoReverse: true
keyFrames: [
KeyFrame {
time: 0s
action: function() {
// 非同期処理クラスを生成し、非同期処理を開始する
def task: LongLongTask;
task = LongLongTask {
// 非同期処理後にコールされる関数
onDone: function(flag: Boolean) : Void {
result = task.result;
}
}
}
},
KeyFrame {
time: 5s
}
]
}.play();
var ball = Circle { <<省略>> }
<<省略>>
Stage {
title: "Long Long Task"
scene: Scene {
width: 300
height: 200
content: [
ball,
Text {
font : Font {
size: 20
}
x: 10,
y: 100
content: bind "{result}"
}
]
}
}ここでは、
AbstractAsyncOperationクラスのサブクラスは生成するだけで自動的にstart関数がコールされます。したがって、
非同期処理クラスを使用するスクリプトが非同期処理が終わった後にコールバック関数を設定したい場合、
実行結果を図5に示します。図5はアプレットページにリンクにしていますので、
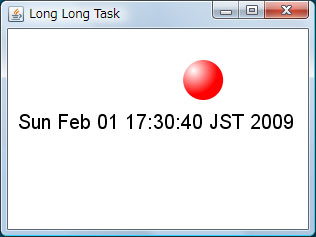
このようにAbstractAsyncOperationクラスを用いれば、
しかし、
ここではソースの解説は行いませんが、
キューとはリストやマップなどと同じようにデータのコンテナの一種です。キューにはデータを追加するメソッドと、
キューはイベント駆動のアプリケーションや、
アプレットページにソースも示しましたので、