目次
第1回 大規模Webサービスの開発オリエンテーション―全体像を把握する
Lesson 0 本書の源 ―本書で説明すること,しないこと
- 大規模サービスの開発に携わる ―大学生向けのはてなインターンシップ
- 本書で説明すること
- 本書で説明しないこと
- これから大規模サービスと向き合うみなさんへ
Lesson 1 大規模なサービスと小規模なサービス
- はてなのサービス規模
- はてなは大規模,GoogleやFacebookは超大規模
- 小規模サービスと大規模サービスの違い
- スケーラビリティ確保,負荷分散の必要
- 冗長性の確保
- 省力運用の必要
- 開発人数,開発方法の変化
- 大規模データ量への対処
Lesson 2 成長し続けるサービスと,大規模化の壁
- Webサービスならではの難しさ
- はてなが成長するまで
- 試行錯誤のシステム規模拡張
- データセンターへの移設,システムの刷新
- システムの成長戦略 ―ミニマムスタート,変化を見込んだ管理と設計
Lesson 3 サービス開発の現場
- はてなの技術チーム体制
- はてなでのコミュニケーションの仕方
- サービス開発の実際
- 開発に使うツール
- プログラミング言語 ―Perl,C/C++,JavaScriptなど
- おもなミドルウェア ―ミドルウェア/フレームワークも統一
- Webアプリケーションフレームワーク ―自社開発のRidge
- 手元のマシンのOSやエディタ ―基本的に自由
- バージョン管理はgit,BTSは独自開発の「あしか」
- 開発ツールに関して
- まとめ
第2回 大規模データ処理入門 ―メモリとディスク,Webアプリケーションと負荷
Lesson 4 はてなブックマークのデータ規模 ―データが大きいと処理に時間がかかる
- はてなブックマークを例に見る大規模データ
- はてなブックマークのデータ規模
- 大規模データへのクエリ ―大規模データを扱う感覚
- Column 日々起こる未知の問題 ―試行錯誤しながら,ノウハウを蓄積する
Lesson 5 大規模データ処理の難所 ―メモリとディスク
- 大規模データは何が難しいのか ―メモリ内で計算できない
- メモリとディスクの速度差 ―メモリは105~106倍以上高速
- ディスクはなぜ遅いのか ―メモリとディスク
- 探索速度に影響を与えるさまざまな要因
- OSレベルの工夫
- 転送速度,バスの速度差
- Column Linux単一ホストの負荷 ~『サーバ/インフラを支える技術』ダイジェスト(OSレベルの基礎知識:その1)~
Lesson 6 スケーリングの要所
- スケーリング,スケーラビリティ
- スケーリングの要所 ―CPU負荷とI/O負荷
- Webアプリケーションと負荷の関係
- DBのスケーラビリティ確保は難しい
- Column 二種類の負荷とWebアプリケーション~『サーバ/インフラを支える技術』ダイジェスト(OSレベルの基礎知識:その2)~
Lesson 7 大規模データを扱うための基礎知識
- プログラマのための大規模データの基礎
- 大規模データを扱う三つの勘所 ―プログラムを作るうえでのコツ
- 大規模データを扱う前に。三大前提知識 ―プログラム開発のさらに下の基礎
- Column ロードアベレージの次は,CPU使用率とI/O待ち率~『サーバ/インフラを支える技術』ダイジェスト(OSレベルの基礎知識:その3)~
第3回 OSのキャッシュと分散 ―大きなデータを効率良く扱うしくみ
Lesson 8 OSのキャッシュ機構
- OSのキャッシュ機構を知ってアプリケーションを書く ―ページキャッシュ
- Linux(x86)のページング機構を例に
- 仮想メモリ機構
- Linuxのページキャッシュのしくみ
- ページキャッシュの身近な効果
- VFS
- Linuxはページ単位でディスクをキャッシュ
- LRU
- (補足)どのようにキャッシュされるか ―iノードとオフセット
- メモリが空いていればキャッシュ ―sarで確認してみる
- メモリを増やすことでI/O負荷軽減
- ページキャッシュは透過的に作用する
- Column sarコマンドでOSが報告する各種指標を参照する~『サーバ/インフラを支える技術』ダイジェスト(OSレベルの基礎知識:その4)~
Lesson 9 I/O負荷の軽減策
- キャッシュを前提にしたI/O軽減策
- 複数サーバにスケールさせる ―キャッシュしきれない規模になったら
- 単に台数を増やしてもスケーラビリティの確保はできない
- Column I/O負荷軽減とページキャッシュ~『サーバ/インフラを支える技術』ダイジェスト(OSレベルの基礎知識:最終回)~
Lesson 10 局所性を活かす分散
- 局所性を考慮した分散とは?
- パーティショニング ―局所性を考慮した分散①
- リクエストパターンで「島」に分割 ―局所性を考慮した分散②
- ページキャッシュを考慮した運用の基本ルール
- Column 負荷分散とOSの動作原理 ―長く役立つ基礎知識
第4回 DBのスケールアウト戦略 ―分散を考慮したMySQLの運用
Lesson 11 インデックスを正しく運用する ―分散を考慮したMySQL運用の大前提
- 分散を考慮したMySQL運用,3つのポイント
- ①OSのキャッシュを活かす
- [補足]正規化
- インデックス重要 ―B木
- 二分木とB木を比べてみる
- MySQLでインデックスを作る
- インデックスの効果
- インデックスの効果の例
- [補足]インデックスの作用 ―MySQLの癖
- インデックスが効くかどうかの確認法 ―explainコマンド
- explainコマンドで速度に気を付ける
- Column インデックスの付け忘れ ―見つけやすいしくみでカバー
Lesson 12 MySQLの分散 ―スケーリング前提のシステム設計
- MySQLのレプリケーション機能
- マスタ/スレーブの特徴 ―参照系はスケールする,更新系はスケールしない
- 更新/書き込みをスケールさせたい ―テーブル分割,key-valueストア
Lesson 13 MySQLのスケールアウトとパーティショニング
- MySQLのスケールアウト戦略
- パーティショニング(テーブル分割)にまつわる補足
- パーティショニングを前提にした設計
- JOINを排除 ―where ... in ...を利用
- DBIx::MoCo
- パーティショニングのトレードオフ
- 運用が複雑になる
- 故障率が上がる
- 冗長化に必要なサーバ台数は何台?
- アプリケーションの用途とサーバ台数
- サーバ台数と故障率
- 第2回~第4回の小まとめ
第5回 大規模データ処理[実践]入門 ―アプリケーション開発の勘所
Lesson 14 用途特化型インデクシング ―大規模データを捌く
- インデックスとシステム構成 ―RDBMSの限界が見えたとき
- RPC,Web API
- 用途特化型のインデクシング ―チューニングしたデータ構造を使う
- [例]はてなキーワードによるリンク
- [例]はてなブックマークのテキスト分類器
- 全文検索エンジン
Lesson 15 理論と実践の両側から取り組む
- 求められる技術的な要件を見極める
- 大規模なWebアプリケーションにおける理論と実践
- 計算機の問題として,道筋をどう発見するか
- 第2回~第5回の小まとめ
第6回 [課題]圧縮プログラミング ―データサイズ,I/O高速化との関係を意識する
Lesson 16 [課題]整数データをコンパクトに持つ
- 整数データをコンパクトに持つ
- 出題意図 ―この課題を解けると何がいいの?
- 課題で扱うファイルの中身
Lesson 17 VB Codeと速度感覚
- VB Code ―整数データをコンパクトに保持しよう
- VB Codeの擬似コード
- アルゴリズム実装の練習
- ソート済み整数を「ギャップ」で持つ
- (補足①)圧縮の基礎
- (補足②)対象が整数の場合 ―背景にある理論
Lesson 18 課題の詳細と回答例
- 課題の詳細
- 評価基準
- (参考①)pack( )関数 ―Perl内部のデータ構造をバイナリで吐き出す
- 今回の課題におけるpackの使いどころ
- (参考②)バイナリのread/write
- (参考③)プロファイリング
- 回答例と考え方
- プログラム本体
第7回 アルゴリズムの実用化 ―身近な例で見る理論・研究の実践投入
Lesson 19 アルゴリズムと評価
- データの規模と計算量の違い
- 第7回,二つの目的
- アルゴリズムとは?
- 狭義のアルゴリズム,広義のアルゴリズム
- アルゴリズムを学ぶ意義 ―計算機の資源は有限,エンジニアの共通言語
- アルゴリズムの評価 ―オーダー表記
- 各種アルゴリズムのオーダー表記
- ティッシュを何回折りたためるか? ―O(log n)とO(n)の違い
- アルゴリズムにおける指数的,対数的の感覚
- アルゴリズムとデータ構造 ―切っても切れない関係!?
- 計算量と定数項 ―やはり計測が重要
- 実装にあたって気を付けたい最適化の話
- アルゴリズム活用の実際のところ ―ナイーブがベターなことも?
- はてなブックマークFirefox拡張の検索機能における試行錯誤
- ここから,学んだこと
- サードパーティの実装を上手に活用しよう ―CPANなど
- 実例を見て,実感を深める
- Column データ圧縮と速度 ―全体のスループットを上げるという考え方
Lesson 20 はてなダイアリーのキーワードリンク
- キーワードリンクとは?
- 当初の実装
- 問題発生! ―キーワード辞書が大規模化してくる
- パターンマッチによるキーワードリンクの問題点
- 正規表現➡Trie ―マッチングの実装切り替え
- Trie入門
- Trie構造とパターンマッチ
- AC法 ―Trieによるマッチングをさらに高速化
- Regex::Listへの置き換え
- キーワードリンク実装,変遷と考察
Lesson 21 はてなブックマークの記事カテゴライズ
- 記事カテゴライズとは?
- ベイジアンフィルタによるカテゴリ判定
- 機械学習と大規模データ
- はてなブックマークの関連エントリー
- 大規模データとWebサービス ―The Google Way of Science
- ベイジアンフィルタのしくみ
- ナイーブベイズにおけるカテゴリの推定
- 楽々カテゴリ推定の実現
- アルゴリズムが実用化されるまで ―はてなブックマークでの実例
- 実務面で考慮すべき点はそれなりに多い
- 守りの姿勢,攻めの姿勢 ―記事カテゴライズ実装からの考察
- 既存の手法を引き出しに入れておく
- Column スペルミス修正機能の作り方 ―はてなブックマークの検索機能
第8回 [課題]はてなキーワードリンクの実装 ―応用への道筋を知る
Lesson 22 [課題]はてなキーワードリンクを作る
- AC法を使って,はてなキーワードリンクを作る
- サンプルプログラム
- AC法の実装の仕方
- 実際の課題
- 出題意図
- テストを書こう
- Column アルゴリズムコンテスト ―Sphere Online Judge,TopCorderなど
Lesson 23 回答例と考え方
- 回答例
第9回 全文検索技術に挑戦 ―大規模データ処理のノウハウ満載
Lesson 24 全文検索技術の応用範囲
- はてなのデータで検索エンジンを作る
- はてなダイアリーの全文検索 ―検索サービス以外に検索システム
- 以前はRDBで処理していた
- はてなブックマークの全文検索 ―細かな要求を満たすシステム
Lesson 25 検索システムのアーキテクチャ
- 検索システムができるまで
- 今回の解説対象
- 検索エンジンいろいろ
- 全文検索の種類
- grep型
- Suffix型
- 転置インデックス型
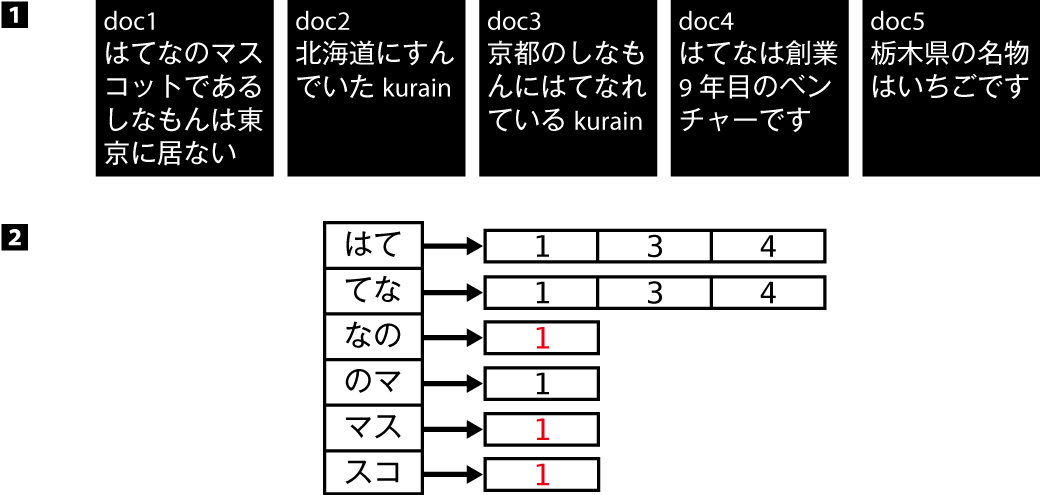
Lesson 26 検索エンジンの内部構造
- 転置インデックスの構造 ―Dictionary+Postings
- Dictionaryの作り方 ―転置インデックスの作り方1
- 言語の単語をtermにする2つの方法
- ①辞書とAC法を使う方法
- ②形態素解析を使う方法(形態素を単語とみなしtermにする)
- 検索漏れ
- n-gramをtermとして扱う
- クエリも同じルールで分割する
- n-gram分割の問題とフィルタリング
- 再現率(Recall)と適合率(Precision)
- 検索システムの評価と再現率/適合率
- ここまでの小まとめ
- Postingsの作り方 ―転置インデックスの作り方2
- 今回は出現位置を保持しない,文書IDのみを保持するタイプ
- スコアリングについて補足
- 参考文献
第10回 [課題]全文検索エンジンの作成 ―基本部分,作り込み,速度と精度の追求
Lesson 27 [課題]はてなブックマーク全文検索を作る
- 全文検索エンジンの開発
- 課題内容
- 課題が解けると何がいいの?
- サンプルデータの形式とデータサイズ
- 辞書の構成 ―Dictionary,Postings
- インタフェース
- 基本部分+作り込み
- 速度と精度で勝負
Lesson 28 回答例と考え方
- 回答例
- indexer.plの実装
- searcerh.plの実装
- 改善できるところは?
- Column Twitterのスケールアウト戦略 ―基本戦略とサービスの特徴に合わせた戦略
第11回 大規模データ処理を支えるサーバ/インフラ入門 ―Webサービスのバックエンド
Lesson 29 エンタープライズ vs. Webサービス
- エンタープライズ vs. Webサービス ―応用範囲に見る違い
- Webサービスの特徴 ―エンタープライズとの比較
- Webサービスのインフラ ―重視される3つのポイント
Lesson 30 クラウドvs.自前インフラ
- クラウドコンピューティング
- クラウドのメリット,デメリット
- はてなでのクラウドサービスの使用
- 自前インフラのメリット
- 自前インフラと垂直統合モデル
- はてなのサービス規模
- はてなブックマークのシステム構成図
第12回 スケーラビリティの確保に必要な考え方 ―規模の増大とシステムの拡張
Lesson 31 レイヤとスケーラビリティ
- スケーラビリティへの要求 ―サーバ1台で捌けるトラフィックの限界
- レイヤごとのスケーラビリティ
Lesson 32 負荷の把握,チューニング
- 負荷の把握 ―可視化した管理画面
- 負荷を測るための項目 ―ロードアベレージ,メモリ関連,CPU関連
- 用途ごとに合わせたチューニング ―ユーザ用のサーバ,ボット用のサーバ
- APサーバ/DBサーバのチューニングポリシーと,サーバ台数
- サービスの規模とチューニング
- スケーラビリティの確保
第13回 冗長性の確保,システムの安定化 ―ほぼ100%の稼動率を実現するしくみ
Lesson 33 冗長性の確保
- 冗長性の確保 ―APサーバ
- 冗長性の確保 ―DBサーバ
- マルチマスタ
- 冗長性の確保 ―ストレージサーバ
Lesson 34 システムの安定化
- システムを安定させるためのトレードオフ
- システムの不安定要因
- ①機能追加,②メモリリーク
- ③地雷
- ④ユーザのアクセスパターン
- ⑤データ量の増加
- ⑥外部連携の追加
- ⑦メモリ ・ HDD障害,❽NIC障害
Lesson 35 システムの安定化対策
- 実際の安定化対策 ―適切なバッファの維持と,不安定要因の除去
- 異常動作時の自律制御
第14回 効率向上作戦 ―ハードウェアのリソースの使用率を上げる
Lesson 36 仮想化技術
- 仮想化技術の導入
- 仮想化技術の効用
- 仮想化サーバの構築ポリシー
- 仮想化サーバ ―Webサーバ
- 仮想化サーバ ―DBサーバ
- 仮想化によって得られたメリットの小まとめ
- 仮想化と運用 ―サーバ管理ツールで仮想化のメリットを運用上活かす
- 仮想化の注意点
Lesson 37 ハードウェアと効率向上 ―低コストを実現する要素技術
- プロセッサの性能向上
- メモリ,HDDのコスト低下
- メモリ ・ HDDの価格の推移
- 安価なハードの有効利用 ―仮想化を前提としたハードウェアの使用
- SSD
- Column SSDの寿命 ―消耗度合いの指標に注目!
第15回 Webサービスとネットワーク ―ネットワークで見えてくるサービスの成長
Lesson 38 ネットワークの分岐点
- サービスの成長とネットワークの分岐点
- 1Gbpsの限界 ―PCルータの限界
- 500ホストの限界 ―1サブネット,ARPテーブル周りでの限界
- ネットワーク構造の階層化
- グローバル化
- CDNの選択肢
- Amazon Cloudfront
Lesson 39 さらなる上限へ
- 10Gbps超えの世界
- はてなのインフラ ―第11回~第15回のまとめ
特別編 いまどきのWebサービス構築に求められる実践技術 ―大規模サービスに対応するために
Special Lesson 1 ジョブキューシステム ―TheSchwartz、 Gearman
- Webサービスとリクエスト
- ジョブキューシステム入門
- はてなでのジョブキューシステム
- TheSchwartz
- Gearman
- WorkerManagerによるワーカーの管理
- ログからの分析
Special Lesson 2 ストレージの選択 ―RDBMSかkey-valueストアか
- 増大するデータをどう保存するか
- Webアプリケーションとストレージ
- 適切なストレージ選択の難しさ
- ストレージ選択の前提となる条件
- ストレージの種類
- RDBMS
- MySQL
- MyISAM
- InnoDB
- Mariaなど
- MyISAM vs. InnoDB
- 分散key-valueストア
- memcached
- TokyoTyrant
- 分散ファイルシステム
- MogileFS
- その他のストレージ
- NFS系分散ファイルシステム
- WebDAVサーバ
- DRBD
- HDFS
- ストレージの選択戦略
Special Lesson 3 キャッシュシステム ―Squid,Varnish
- Webアプリケーションの負荷とプロキシ/キャッシュシステム
- リバースプロキシキャッシュサーバ
- Squid ―基本的な構成
- 複数台で分散する
- 二段構成のキャッシュサーバ ―CARPでスケールさせる
- COSSサイズの決定方法
- 投入時の注意
- Varnish
Special Lesson 4 計算クラスタ ―Hadoop
- 大量ログデータの並列処理
- MapReduceの計算モデル
- Hadoop