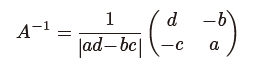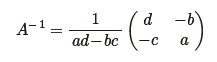概要
「データサイエンティスト検定 リテラシーレベル」の公式リファレンスブック第2版です。
2022年6月の試験から,出題範囲となる「データサイエンティストスキルチェックリスト」がver.3からver.4へ。
それにともなって計185個に増加したスキル項目について,要点と学習のポイントを基本から一つひとつ解説しています。
第一線で活躍する執筆陣が具体的なシーンにまで踏み込んで説明しているため,データサイエンティストとしての確かな力が身につきます。
さらに付録の模擬試験では,試験で出題される問題のイメージをつかむことができます。
「データサイエンティスト検定 リテラシーレベル」とは?
「データサイエンティスト検定 リテラシーレベル」(略称:DS検定)は,一般社団法人データサイエンティスト協会によって,2021年9月に始まった検定試験です。「リテラシーレベル」では,協会が定めたスキルレベルのうち最も基礎的な内容(見習いレベル)を問われるため,すでにデータサイエンティストとして活躍している方はもちろんのこと,データサイエンスに興味がある学生の方,ビジネスパーソンの方も挑戦することができます。
こんな方におすすめ
- データサイエンティスト検定(リテラシーレベル)に合格したい方
- データサイエンスの基礎素養を身につけたい大学生やビジネスパーソンの方
サポート
ダウンロード
第2版を購入された皆様へ
データサイエンティスト検定は,2024年6月から始まる第7回検定より,出題範囲が変更となります。2024年5月7日発売の第3版では新しい出題範囲をカバーしておりますが,その前に本書(第2版)を購入された皆様の便宜を図るため,新たに出題範囲となる項目の解説を作成いたしました。期間限定で公開いたしますので,下記フォームよりダウンロードしていただき,受験対策にご活用ください。
「書籍(第2版)掲載の模擬試験」 解説のダウンロード
書籍に掲載した模擬試験につきまして,45問すべての「解説」を追加で公開いたします。ぜひご活用ください。
- ダウンロード
- DS検定第2版_書籍収録模擬試験(45問)の解説_1104.pdf
「Web提供の模擬試験(2022年6月9日版)」 問題・解答のダウンロード
本書(第2版)のご購入者様向けの特典として,模擬問題をPDFで提供いたします。新たに作成した(誌面に掲載したものとは異なる)90問の問題と解答を収録していますので,ぜひご活用ください。
本書の下記の場所に記載されている文字を入力し,[ダウンロード]ボタンをクリックしてください。
ダウンロードしたPDFを閲覧する際にもパスワードの入力が必要です。ダウンロードの際に入力した6文字を再度入力してください。
※パスワードは大文字と小文字の間違いがないようにご注意ください。
「Web提供の模擬試験(2022年6月9日版)」 解説のダウンロード
読者特典の「Web提供の模擬試験(2022年6月9日版)」につきまして,90問すべての「解説」を追加で提供いたします。
本書の下記の場所に記載されている文字を入力し,[ダウンロード]ボタンをクリックしてください。
正誤表
本書の以下の部分に誤りがありました。ここに訂正するとともに,ご迷惑をおかけしたことを深くお詫び申し上げます。
第2刷訂正情報(第2版 第3刷で訂正予定)
P.106 本文の下から5行目
| 誤 |
3つの水準(駅前店、郊外店、郊外店)に対して、「店舗立地:駅前店」と「店舗立地:郊外店」の2つで表現するのは、この考え方に基づいています。3つの水準の変数であれば、2つのダミー変数があれば必要十分であり、2つのダミー変数がともに0のときが「店舗立地:郊外店」に対応することになります。 |
|---|
| 正 |
3つの水準(駅前店、郊外店、住宅街店)に対して、「店舗立地:駅前店」と「店舗立地:郊外店」の2つで表現するのは、この考え方に基づいています。3つの水準の変数であれば、2つのダミー変数があれば必要十分であり、2つのダミー変数がともに0のときが「店舗立地:住宅街店」に対応することになります。 |
|---|
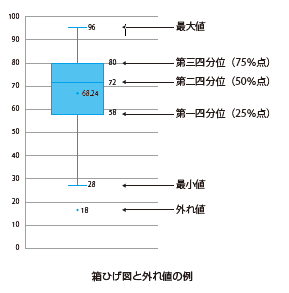
P.123 本文の下から4行目
| 誤 |
ひげの下限を「第1四分位数-3×四分位偏差」(下側境界点)、上限を「第3四分位数+3×四分位偏差」(上側境界点)とするグラフです。 |
|---|
| 正 |
ひげの下限(下側境界点)を「第1四分位数-3×四分位偏差」より大きい最小値、ひげの上限(上側境界点)を「第3四分位数+3×四分位偏差」より小さい最大値とするグラフです。 |
|---|
P.170 一番下の図
| 誤 |
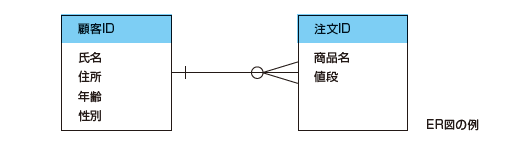
|
|---|
| 正 |
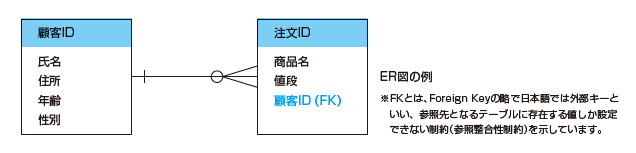
|
|---|
第1刷訂正情報(第2版 第2刷で訂正予定)
P.49 一番下の数式
| 誤 |
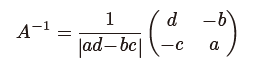
|
|---|
| 正 |
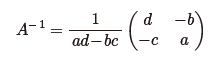
|
|---|
下の絶対値記号がなくなっています。
P.65 本文7行目
| 誤 |
「会員ごとに~描画したグラフとして,以下を受け取りました。 |
|---|
| 正 |
「会員ごとに~描画したグラフ」として,以下を受け取りました。 |
|---|
P.75 本文2行目
| 誤 |
予測に用いる変数を説明変数(従属変数),予測する変数を目的変数(独立変数)と呼び, |
|---|
| 正 |
予測に用いる変数を説明変数(独立変数),予測する変数を目的変数(従属変数)と呼び, |
|---|
P.90 本文下から4行目
| 誤 |
デンドログラム(樹形図)を作成する非階層クラスタリング |
|---|
| 正 |
デンドログラム(樹形図)を作成する階層クラスタリング |
|---|
P.106 本文の1行目
| 誤 |
量的変数(間隔尺度・比尺度) |
|---|
| 正 |
量的変数(間隔尺度・比例尺度) |
|---|
P.123 「箱ひげ図と外れ値の例」の図
| 誤 |
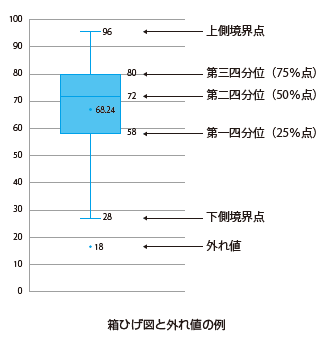
|
|---|
| 正 |
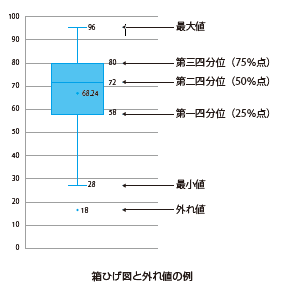
|
|---|
P.125 本文の下から5行目
P.140 本文の下から8行目
| 誤 |
損失関数の最小化を行うよう重み更新を繰り返す |
|---|
| 正 |
損失関数の最小化を行うよう重みの更新を繰り返す |
|---|
P.165 本文の下から7行目
P.217 本文の上から10行目
| 誤 |
バージョン管理ツールの、ドキュメントの格納領域をリポジトリといます。 |
|---|
| 正 |
バージョン管理ツールのドキュメントの格納領域をリポジトリといいます。 |
|---|
P.234 本文の上から10行目
| 誤 |
その販売を許諾するもので |
|---|
| 正 |
その販売の許諾を得るもので |
|---|
P.296 Q24の問題文
以下のテストケースの記載が設問文から漏れていました。
テストケース:入力データから何月かを特定するプログラムで、0を入力データとしてテストをした。
P.308 Q11の行
| 誤 |
Q11 a データ可視化 方向性定義 DS136 データの性質を理解するために、データを可視化し眺めて考えることの重要性を理解している 108 |
|---|
| 正 |
Q11 c 時系列分析 時系列分析 DS174 時系列分析を行う際にもつべき視点を理解している(長期トレンド、季節成分、周期性、ノイズ、定常性など) 125 |
|---|
P.308 Q12の「ページ」
P.310 Q32の答え