9月18日~20日、広島国際会議場にて「RubyKaigi 2017」が開催されました。3日目の基調講演は、RedHatのトロントオフィスで働くGCCの開発者であるVladimir Makarovさんです。
Vladimirさんは、Ruby 2.4で導入された新しいハッシュテーブルの実装者であり、20年以上に及ぶGCCの開発経験を持つ、コンパイラ開発のスペシャリストです。今回、Vladimirさんは「Towards Ruby 3x3 performance」と題して、発表しました。

Stack machineをRTLへ
MRI(Matz' Ruby Interpreter、以下 Ruby)では、1.8.7まで作者のまつもとゆきひろさんが開発していたインタプリタが使われていました。そして、バージョン1.9でささだこういちさんが開発したYARV(Yet Another Ruby VM)に置き換えられました。YARVはstack machineを採用したVMですが、Vladimirさんはまず、このstack machineをRTL(Register Transfer Language)へ置き換える変更を実装しました。
Stack machineとRTLではそれぞれ優位な点が異なりますが、命令数が短くなること、JITコンパイラとコードを共有することが可能になること等、RTLには今後の実装上で好ましい点が多くありました。そこで、まずはRTLへの移行を実装しました。

現在のRTLの実装の段階としては、make testによるテストはすべて通っているという段階です。make testは、Ruby本体のテストを実行するコマンドで、リポジトリにおけるtest/以下のテストを実行します。RubySpecは実行されませんが、最初のステップとしては非常に良いスタートであると言えるでしょう。また、マイクロベンチマークでは、既に最大110%のパフォーマンス改善を達成しています。しかしながら、RTLの難点であるコードサイズが大きくなってしまうこと、また、オペランドデコーディングのオーバーヘッドが依然として大きいことがこれからの課題として存在します。そのほかにも、Rubyプロセスを実際に長時間起動させた場合の安定性については検証されておらず、これについても今後の課題となっています。

JITの実装比較
次に発表では、JITの実装方法をいくつか紹介し、比較検討しました。JITを使ってパフォーマンスを改善するには、大きく分けて3つの方法があります。
- フルスクラッチでJITコンパイラを実装
- 最適化コンパイラを利用
- 既に広く使われているJITコンパイラを利用
1のフルスクラッチJITコンパイラを採用しているのは、LuaJIT、JavaScript V8等があります。特定の言語に対する最適化を自由に実装できるため、最もパフォーマンスを改善しやすい手法です。しかしながら、JITコンパイラをフルスクラッチで開発することは非常にコストと時間がかかり、メンテナンス性もよくありません。
2のGCCやLLVMに代表される最適化コンパイラを利用する方法では、GCCでは300以上の最適化パターンが実装されているためパフォーマンスを改善しやすく、Rubyのコンパイルでは既にGCCを使っているため、新しい依存関係を追加する必要もありません。現在の実装を大きく変更する必要もないので、メンテナンス性にも優れています。しかし、すべての最適を施そうとすると、コンパイル時間が非常に長くなってしまうという問題があります。
3のJVM、GraalVMに代表される、既に広く使われているJITコンパイラを利用する方法では、安定していて、かつ、信頼のおける最適化を適用できます。しかし、主要な既存JITコンパイラは、既にJRubyやTruffleRuby等のRuby実装で使われています。

開発リソースに乏しいRuby coreチームでは、フルスクラッチでJITコンパイラを実装することは現実的ではありません。また、JVMやGraalVMは、先述のような別の実装が開発されており、現在のMRIの実装を大きく変更する必要もあります。一方、GCCやLLVMにおけるコンパイル時間が長くなってしまう問題に対しては、パフォーマンスに貢献しない最適化を無効にすることで対処可能です。これらを総合して考えると、2の最適化コンパイラを使うのが、Rubyプロジェクトにとって最も適切な選択だと判断しました。
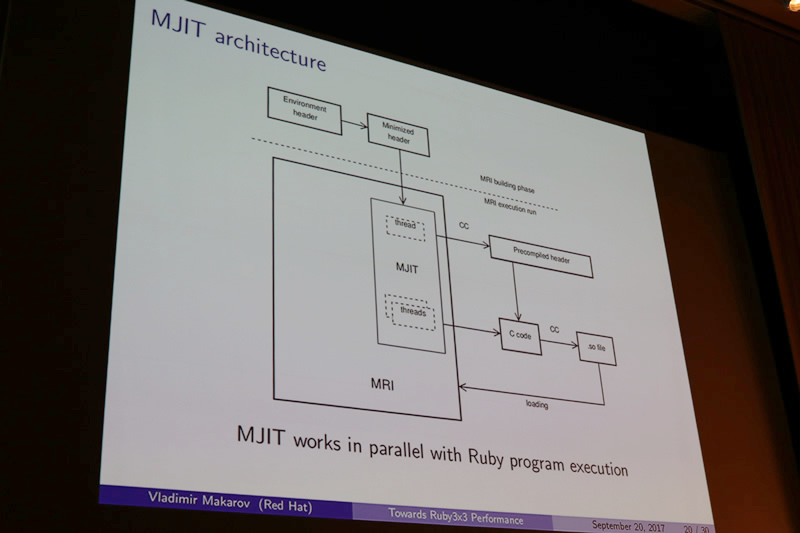
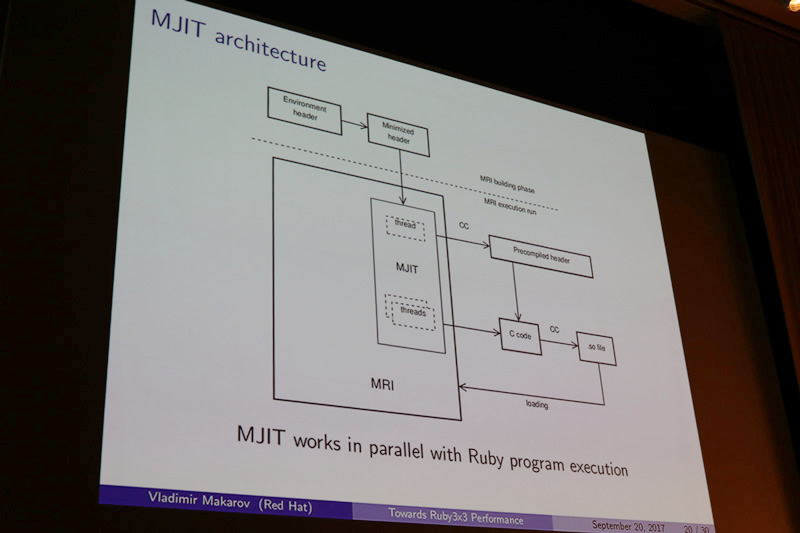
MRI JIT(MJIT)
では、MRI JITがどうやって最適化を施しているかをみていきましょう。MJITの実装を簡潔に言うと、Cコードを動的に生成し、それを実行、さらにそのCコードに対しても最適化を施す、という手法を採用しています。
Cコードを動的に生成して最適化を図る手法は、処理が重く、筋の悪いジャンキーな手法であると考えられていることもありますが、注意深く実装することで効率的な最適化を行うことができます。また、新しい依存関係の追加も必要なく、デバッグも容易に行うことができます。

ベンチマーク
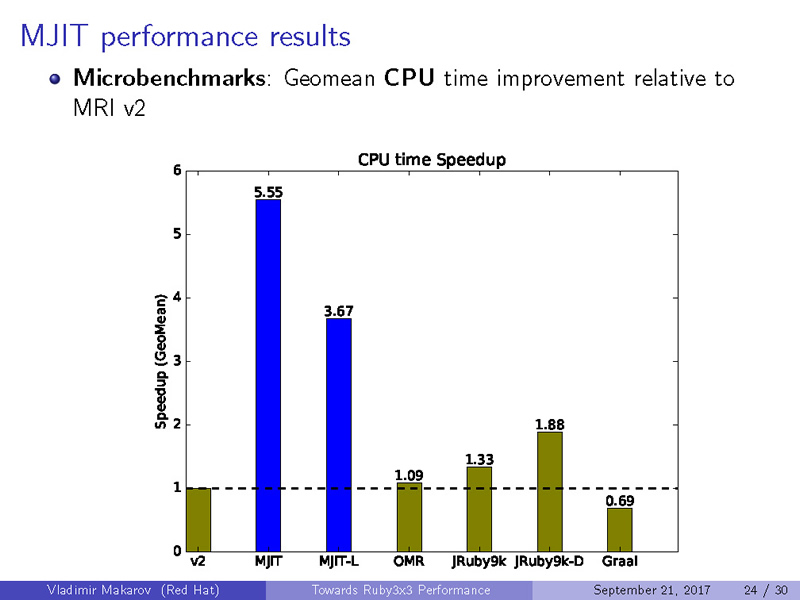
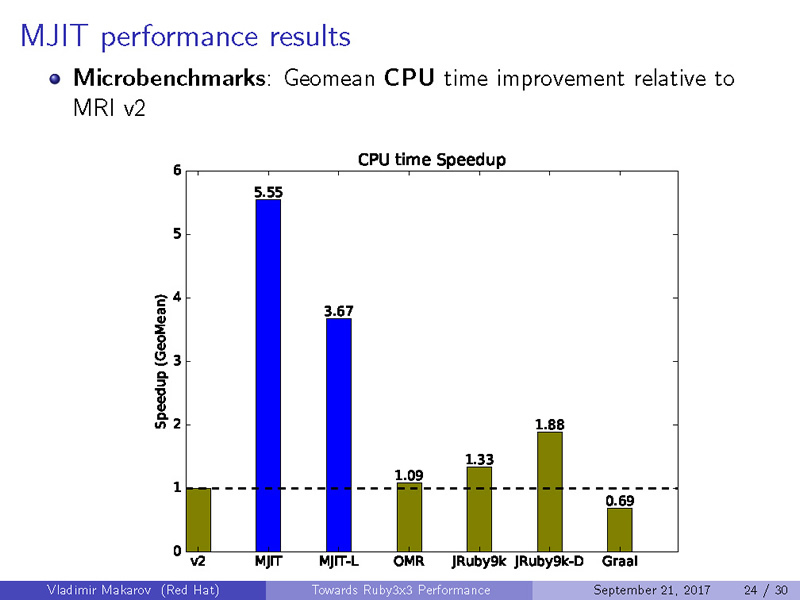
MJITのパフォーマンスを計測するため、様々なマイクロベンチマークの結果から得られた数値と、Octcarrotを用いて、パフォーマンスがどのくらい改善されたかを計測しました。なお、本発表時点ではGraalVMのベンチマークを取ることができなかったため、未掲載となっています。
CPUの比較(Higher is better)
|
ベンチマーク
|
v2
|
MJIT GCC
|
MJIT LLVM
|
OMR
|
JRuby 9k
|
JRuby 9k-D
|
Graal
|
|
Geomean Wall Time
|
1
|
6.18
|
4.02
|
1.09
|
1.59
|
2.48
|
1.83
|
|
Geomean CPU Time
|
1
|
5.55
|
3.67
|
1.09
|
1.33
|
1.88
|
0.69
|
|
Octcarrot FPS
|
1
|
2.83
|
2.94
|
1.20
|
1.14
|
2.38
|
-
|
|
Octcarrot CPU time
|
1
|
1.53
|
1.45
|
1.13
|
0.79
|
0.76
|
-
|
ご覧のとおり、Ruby 2.0だけでなく、既にJITが導入されているJRuby等と比較しても、MJITの最適化が非常に優れていることが分かります。また、興味深いことに、単純なマイクロベンチマークではGCCのコンパイラが優れていたものの、Octcarrotを用いた、より現実的なベンチマークではLLVMのほうが優れた結果が得られています。
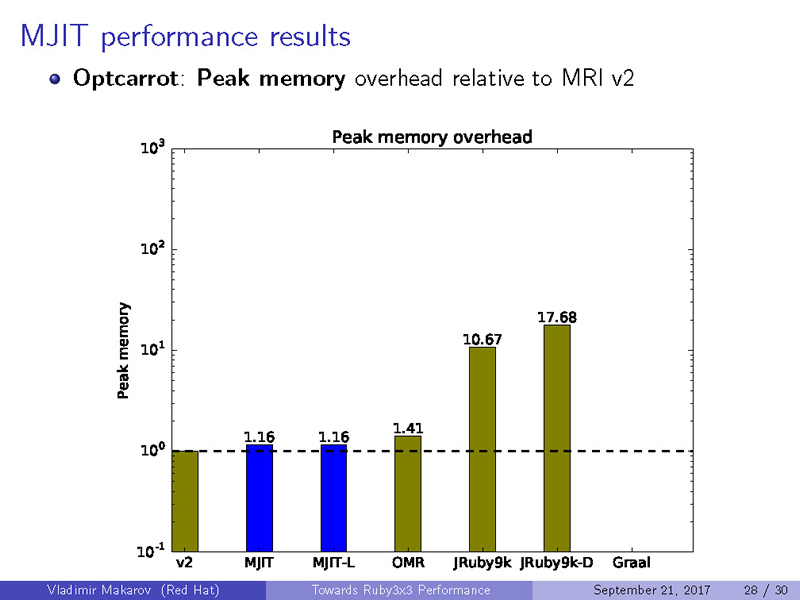
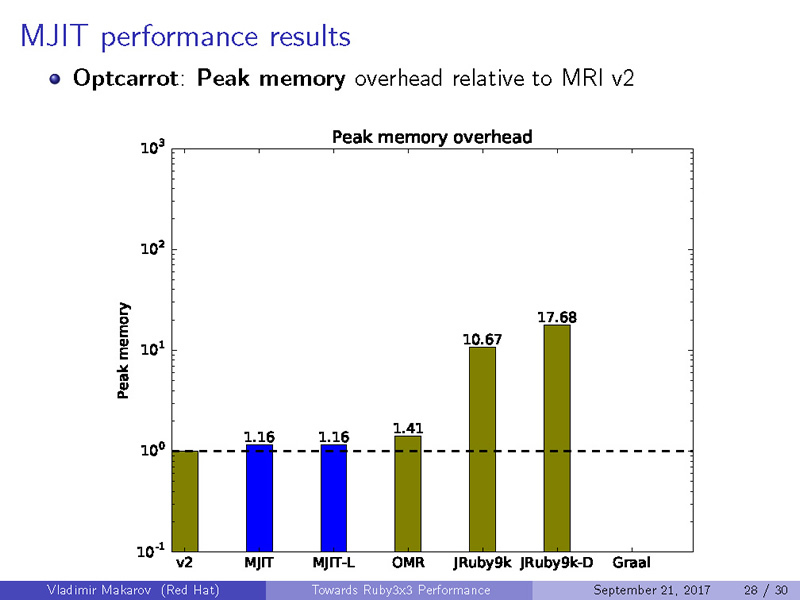
メモリ使用量の比較(Lower is better)
|
ベンチマーク
|
v2
|
MJIT GCC
|
MJIT LLVM
|
OMR
|
JRuby 9k
|
JRuby 9k-D
|
Graal
|
|
Geomean Peak Memory
|
1
|
4.15
|
6.44
|
2.54
|
161.76
|
198.86
|
79.65
|
|
Octcarrot Peak Memory
|
1
|
1.16
|
1.16
|
1.41
|
10.67
|
17.68
|
-
|
コードを実行時に動的最適化するというJITの特性上、メモリ使用量が大きくなってしまうことは避けられません。したがって、いずれのケースでもJITが実装されていないRuby 2.0が最も省メモリで動作するという結果になっています。しかしながら、JITが実装された処理系の中では、MJITが非常に良い数値を残していることが分かります。
まとめ
このプロジェクトはまだ始まったばかりです。make testを実行した場合はすべての結果が通るものの、RubySpecやmake checkはまだすべて通りません。また、Windowsでの動作も保証していません。このような事由から、Vladimirさんは「実装として成熟するにはあと1年ほぼかかるだろう」と述べていました。また、最も重要な最適化として、Cコードのインライン化(Ruby コードのインライン化でないことに注意)があります。これを将来的に実装する予定です。