



10月15日、
※今回のレポートは全セッションを回れておりません。ご了承ください。

Daisuke Makiさん「Welcome Speech」
JPAの牧さんより、
また、
最後に、

Larry Wallさん「That Goes Without Saying (or Does It?)」
最初のトークは、

次にRMS(Root Mean Square)のロジックを各言語別に取り上げ、

Larry Wallさんのセッションでは日本語も随所に登場し、

Kazutake Hiramatsuさん「Modern Perl Web Development on Amazon EC2」
Kazutake Hiramatsuさんによる、Amazon EC2上でPlack/
Plackを使ったPSGIなWebアプリの作り方
まずはPlack/

daemontoolsを使ったwebサーバの運用
続いてdaemontoolsを使ったサーバの運用について解説されました。server_
cpanmを使ったCPANモジュールのインストール
モジュールのインストールに関しては標準のcpanコマンドは使わずにcpanmコマンドを使うのがおすすめだそうです。-lオプションを指定することでインストール先の変更も簡単に行えるそうです。
Amazon EC2上でのWebアプリ構築、運用
Amazon EC2については、普通にアプリケーションを開発する上では大きな違いはないとのことです。ただし、インスタンスを停止するとデータが失われる点や、IPアドレスが変わるケースなど注意点もあるようです。そのあたりはEBSやS3、Elastic IPといった周辺サービスで補う必要があるそうです。それでもオートスケールするのはやはり便利であるとのことで、CPI使用率などのしきい値を設定しておくと、自動的にインスタンスの追加/

リクルート メディアテクノロジーラボさんによるセッション
このセッションでは、
石橋利真さん「最近のPerlな物作り事例」
まず最初に登壇された石橋さんのトークは、
メディアテクノロジーラボさんでは
質疑応答も非常に活発で、

kawanetさん「Mashup Awards 6」
kawanetさんが紹介をしたのは、
多数あるAPIのうち注目のAPIの紹介が行われ、
Tokuhiro Matsunoさん 「モダンな Perl5 開発環境について - Modern Perl5 Development Environment - 2010年代を生きのびる Perl5 活用術」
tokuhiromさんによる開発環境構築ノウハウの紹介トークです。
まずはperlの自体のインストールの話から。OSに標準ではいっているperlは一般的な設定となっているためthreadが有効になっているなどWebアプリケーションとして使うには不要な設定が入っていたりします。perlではthreadをoffにするだけでインタプリタの実行速度が10〜15%程度高速化されるそうで、WEBアプリケーション環境として使う場合には1からインストールしなおすことを進められていました。続いてどのバージョンを使うかという話ではperl-5.
perl環境を構築するうえでの便利なツールとして、様々なバージョンのperlを簡単に切り替えられるperlbrewや、標準のcpanコマンドの軽量版であるcpanm、インストールされているモジュールの更新をチェックするcpan-outdated、使わなくなったモジュールをアンインストールするpm-uninstallなどのツールの紹介がありました。そうやって構築したperl環境を本番環境に配置するときは、単純にrsyncするのがおすすめとのことです。
CPANモジュールの選び方についても紹介されました。CPANには現在8万以上のモジュールが登録されており、初心者がその中から必要なものを選ぶのはとても困難です。そんな中よいモジュールを選ぶにはやはり人に教えてもらうのが一番で、気楽にIRCチャンネルの#perl-casual@irc.
質疑応答では、リリース後更新されたCPANモジュールはどうアップデートするかという質問がありましたが、tokuhiromさんは開発中はどんどん最新化しているが、リリース後は気になったものだけをチェックして手動でアップデートされているそうです。
本トークは今回から導入されたセッション投票システムにおいて、Best talk賞を受賞されました。


Kensuke Kanekoさん「30days Albumの裏側 後日談」
昨日の前夜祭にも登場した、
最初に紹介されたのは、
Perlbalに関しては、


Hiroki DaichiさんInside Mixi - ソーシャルネットワークを支える技術
Hiroki Daichiさんにより、mixiシステムの内部について
Performance : アクセス数の増加や変動に耐える
mixiではmemcahcedをキャッシュ機構として利用しているそうです。memcachedは揮発性KVS、汎用キャッシュ機構、LRUといった特徴をもったプロダクトです。 キャッシュをする上で考慮する点として、キャッシュ方式とキャッシュ対象レイヤについて解説されました。キャッシュの方式は大きく分けてリードスルー方式とライトスルー方式があります。リードスルー方式では、データソースから読み込み時にキャッシュに書き込む方式で、実装が簡単という特徴があります。Perlで実装する場合は、Moose::RoleやClass::Method::Modifierを使えば、データ取得ロジックに手を加えずにキャッシュ機構が実現できるそうです。ライトスルー方式はデータソースへの書き込み時にキャッシュに保存する方法です。ただしデータソースへの保存粒度とキャッシュの粒度を合わせる必要があるなど実装上すこしハードルが上がりがちのようです。またmemcachedの場合はキャッシュが揮発するので、リードスルー方式と併用する必要があると述べられていました。続いてキャッシュ対象レイヤの話では、キャッシュの粒度についての説明がありました。データベースレコードの1カラムデータをキャッシュするレベルから、レコード単位、ドメイン単位、サービス単位など、様々な粒度でのキャッシュを使い分けているそうです。
Development : 機能追加や他人数開発に耐える
開発面でのスケーラビリティについては、MVCの重要性について述べられていました。特に様々なデバイスでサービスを展開する場合、コントローラが肥大化した作りだとうまくいかないケースが多く、MVCの真価が問われるとのことでした。また凝集度を高く結合度を低く保つことも重要です。ライブラリは 基礎ライブラリ、フレームワーク、サービス、アプリケーションというレイヤに分割し、レイヤごとの依存関係の制限や、品質基準などを設定されているということでした。またModelのCRUD操作にフックを定義されていて、それによりモデルの深い事情をしらなくても連携するサービスが作れるようになっているそうです。イイネ機能などはその仕組みにより実装されているとのことでした。
まとめ
最後にまとめとして、パフォーマンス面でも開発面でもスケーラビリティを保つためには負荷の分散構成と責務の分散構成が必要だが、それらは構成的には共通点が多いということをおっしゃっていました。


Tatsuro Hisamoriさん「ソーシャルアプリ向け システム監視運用の勘所」
このセッションは、Social Applicationの開発者を対象としたレスポンス時間に関する不具合を調査する方法についてのトークでした。DeNAのHisamoriさんより、実際に問い合わせが発生した事例に基づいて現象の切り分けていくHow Toが紹介されました。
Social Applicationでは、コンテンツ提供サーバがレスポンスをする際に、タイムアウトが規定されています。今回の事例では、規定の時間内にコンテンツを返しているのにタイムアウトになってしまう、という問い合わせが発生したというものでした。結論としては、GadgetServerの計測する時間とプロバイダー側が計測していた時間にブレがあるのが原因でした。前者は問い合わせを行うPerlコード内でalert関数での割り込みが発生する時間であったのに対し、後者はリクエストラインを受け取ってからの応答時間であったというものです。この調査に利用した道具として、tcpdumpとwiresharkが紹介されていました。
HisamoriさんはSocial Application開発者に意識して欲しいものとして、

Lyo Katoさん「DataPortability and SocialWeb Protocols」
まずは最近のソーシャルウェブ界隈の様々なプロトコルが紹介された後、OpenIDとOAuthによってサービスはIDの提供者(IdP:Identity Provider)とサービスの提供者(SP:Service Provider)をわけて考えることができるようになってきたと述べられました。それまでは各サービスごとにIdPとしての機能とSPとしての機能を実装する必要あったが、それらを他のサービスから借りてくるというエコシステムが形成されてきています。OpenIDとOAuthの相違点については、一般的にOpenIDはIdPの部分を移譲するための仕組みであり、OAuthはSPの部分を移譲するための仕組みとなっていますが、実際にはOpenIDでも拡張機能でユーザのプロファイル機能が取得可能であったり、OAuthでも認証をIdPに移譲していると言えなくもないなど、似通っている部分も多いとのことでした。
続いてOAuth2.
iPhone, AndroidなどでOAuthを利用するためのtipsなどが紹介されました。例えばAndroidではAccount ManagerというOSがアカウント情報を統合管理する仕組みを持っているそうです。その他xAuthを使うときなどはパスワード情報の保存を平文でおこなってしまうと漏洩リスクが高いので、扱いに注意を促されていました。
最後にOAuthはそろそろ必須技術になってきているとして締めくくられました。


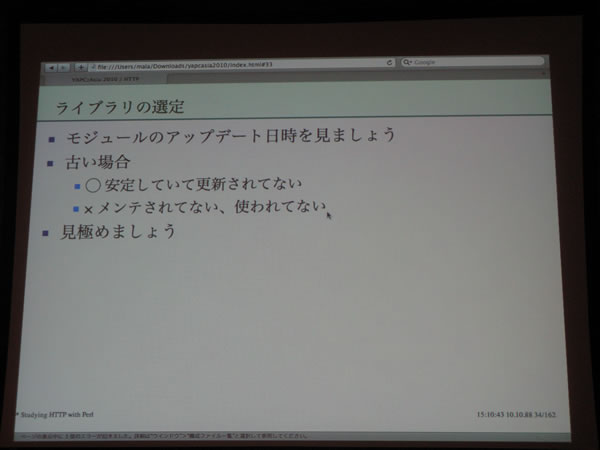
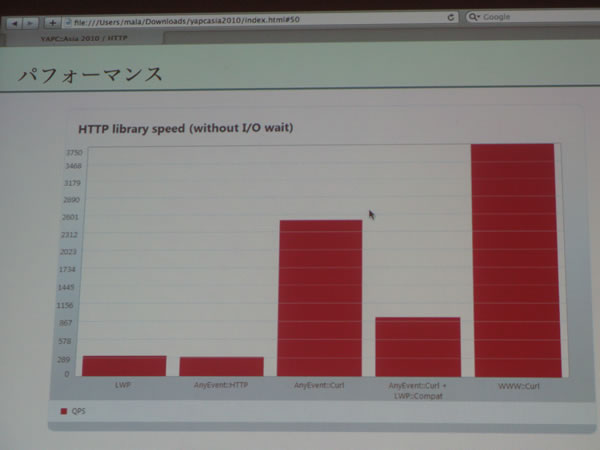
malaさん「Studying HTTP with Perl」
本セッションは、
非同期なものに関してはAnyEvent::HTTPが有名ですが、
その後、
話の最後には、
Jiro Nishiguchiさん「Write Good Parser in Perl」
Jiro NishiguchiさんによるPerlでのパーサモジュールの紹介と、その実装方法についての解説でした。
まずはパーサとはなにかというところから始まりました。パーサとはなんらかの意味をもったテキストを、その後の処理に適した形にするためのものです。 そんなパーサのPerlでの実装例として、HTML::Parser、XML::LibXML、JSON, JSON::XS、HTTP::Parser::XS、Template-Toolkitといった定番モジュールの紹介がありました。またCache::Memcachedモジュールも紹介されていて、こちらはパーサモジュールではないが、内部でmemcachedプロトコルを解析するためにパース処理を行っており、その点でパーサ実装例として挙げられていました。
これらのモジュールの実装はXSを使ったものが多いようです。特に1文字ずつ処理していくようなタイプの処理はPerlで書くよりもCで書いたほうが高速に動作することが多いのがその理由のようです。とはいえPerlの正規表現でもかなり高速に動作するので、書き捨てのパーサなどを作る場合には正規表現は有効な手段として紹介されていました。また正規表現を最適化してくれるRegexp::Assembleについての紹介もありました。
続いて実装パートではRagelの紹介がありました。Ragelとは正規表現に似た文法を用いて比較的わかりやすく宣言的に書けるのが特徴のパーサジェネレータです。ただし、perlはサポートしていないため、利用するにはCで書いてXSで呼び出すなどひと工夫する必要があるそうです。XSといってもデータ構造を作って返すだけで複雑な処理は必要ないので恐れることはないとのことでした。実際にログ解析プログラムを書いたところ、正規表現と比べて5倍程度高速な物ができたそうです。ログ解析のようにフォーマットがあまり変わらなそうなところについては、パーサジェネレータとXSで高速化するのもお勧めとのことでした。


Seiji Haradaさん「mixi チェックインの裏側」
mixiチェックインの裏側に関するトークです。スポット絞り込み検索機能を実現するための方法と、高速化するために行っている工夫について発表されました。
mixiチェックインでは現在の位置情報からスポットを検索する際に、geohashという手法を用いているそうです。geohashとは経度緯度の範囲を文字列で表現したもので、先頭からたどっていくと範囲が絞り込めるように表現されています。その性質により一定長さの文字列で前方一致検索をすることにより、高速に現在位置周辺の検索が実現できるそうです。実際のサービスではGeo::Hash::XSを使用されていて、とても高速に動作するそうです。ベンチマークをとったところ、Geo::Hashと比較して140〜200倍程度高速だったとのことです。
また高速化の手法としてmysqlまわりにも触れられていました。スポットの情報はそれほど頻繁には更新されないので、6文字のgeohashをキーにしてmemcachedにキャッシュしているそうです。ただし全ての地域についてキャッシュしてしまうとキャッシュ容量的に無駄が多くなってしまうため、特にスポットの多い関東、関西地区に限定している人のことでした。また検索範囲に関しては半径250mを規準にしているそうですが、これは厳密に指針があるわけではなく、実際に外にでて実機で検証したところGPSの最大誤差が250m程度だったので、それを規準にしたそうです。デバイス周りの開発ではコードの検証だけではなく、現実の世界での検証が重要だということを認識させられる一例だと思いました。
最後に位置情報サービスは難しくないので楽しみましょうと締めくくられていました。

伊藤直也さん「Perl/PHPと大規模Web開発」
最近PerlからPHPへシフトをしたことでPerlプログラマからもPHPプログラマからも注目されている伊藤直也さんのセッションは、
まずLLのWeb Application Frameworkについて最近の流行として、
また、
最後に、


keroyonnさん「非同期タスクの通知処理 with Tatsumaki」
Hokkaido.
まずは簡単な通知の方法として、CGIベースによるブロッキング&ストリーミングの解説がありました。perlだと$|=1を設定して少しづつprint文などでコンテンツを出力していく手法です。この方法は手軽なのですがブラウザがずっと読み込み中になってしまいます。
続いてクライアント側を非同期化するためにmultipart/
しかしノンブロッキングなサーバには、同期IOを使えないため処理が複雑になる、CPUを占有するような処理も好ましくないといった欠点があります。それらを解決する手段としてTatsumaki, Gearman, WebService::Asyncの3モジュールが紹介されました。まずTatsumakiを使うと、ノンブロッキングなストリーミング処理を簡潔に記述することができます。続いてGearmanはノンブロッキングなサーバが苦手とするCPU負荷が高い処理を補うジョブキューサーバで、ストリーミングしているプロセスから処理を移譲するために使います。ジョブを登録するときにブロックしては意味が無いので、クライアントから呼び出すときはAnyEvent::Gearman::Clientを使うとよいそうです。最後にkeroyonnさんが作成されているWebService::Asyncが紹介されました。TatsumakiにはHTTPClientというモジュールも付いていますが、結果のパースなどは自分で実装しないといけません。WebService::Asyncを使うと非同期でWebサービスを呼び出して結果のパースまでをシンプルに行えるとのことです。
セッション中は


吉見 圭司(walf443)さん「Webサービスのページング処理について」
吉見 圭司(walf443)さんによるページング処理のトークです。Webサービスでよく行われるページング処理について、いろいろな手法の紹介トークとなりました。
まずは一般的な方法の説明で、mysqldでのlimit offsetを使って1ページ分の結果を取得する処理と、limit句をつけないcount(*)文を発行してトータルの件数を取得する処理の二つを行ってページングを実現する手法を紹介されました。この手法は大抵の場合うまくいきますが、count処理が重いなど非効率な面もあります。
続いてmysqlの機能であるCALC_
吉見さんはこれらのページングロジックを必要に応じて切り替えられるようにDBIx::Skinny::Pagerというモジュールを開発されているそうです。
質疑応答では、ページング処理中にデータが増えた場合表示位置がずれる可能性があるがどう対処するかという質問がありました。それに対してページング処理をタイムスタンプなどを規準に行えばよいのではないかと回答されていました。


Lightning Talks
初日のLTを紹介します。
西林拓志さん「学生PHPプログラマーがPerlな会社に就職した!」
Perlを使ってみての感想のLTでした。実際に使ってみるまではいい印象を抱いていなかったそうですが、

Fumiko Kuranoさん「Inside webcast of Gozan-no-Okuribi in Kyoto」
京都送り火の中継の舞台裏について、

Yappoさん「Happy AnySan Hacking」
今年はtsudaさんのコスプレで現れたYappoさん。AnySanというメッセージングフレームワークを紹介して下さいました。実装を意識することなくメッセージングを実現できるのが特徴で、
Naoki Tomitaさん「OFPM」
朝から会場を沸かせていた忍者の正体は、

Kamipoさん「MySQLのPluginいろいろ」
MySQLのUDF、

issmさん「「名古屋でPerlをゆるく語る会」をはじめました」
ロールプレイングゲーム風の画面でプレゼンしたissmさんは、

吉川 毅さん「RubyプログラマがPHP大規模開発の会社に入って」
CTOの代わりに登壇することになったと語る吉川さん。図説で非常にわかりやすく壇上での心境を説明して下さいました。SinatraやPSGIにインスパイアを受けてPHPでViciousとPhackと名付けたモジュールを作ったとのことですが、

bayashiさん「YAPC::EU 2010 Reports」
ヨーロッパ最大のYAPCに参加されたbayashiさん。質疑応答の活発さと、

峰松 浩樹さん「基幹システムがperlでどうしてこうなった」
汎用機を2013年までになくすという無謀な計画を実施することになった峰松さん。JCLはPerlで自動変換し、

zentoooさん「Test::QUnit - QUnit test via prove」
ブラウザでのテストは面倒くさいけど、

Karen Pauleyさん「10 Things to Do with a conference T-shirt」
YAPCに20回以上出ていると語るPauleyさん。出席するたびに手に入るTシャツは女性のPauleyさんには巨大過ぎて着こなせず、

Yoshinori TAKESAKOさん「all your base16 are belong to us.」
一日目の大トリを飾ったのはTAKESAKOさん。PythonではUnicodeの

懇親会
1日目のプログラム終了後、



※ブラッシュアップする前にあったメモ書きの一部は、